The preceding chapters have covered the process of making a program run faster in a single CPU. This chapter focusses on running the optimized program concurrently on multiple CPUs, expecting the program to complete in less time when more CPUs are applied to it. Parallel processing introduces new bottlenecks, but there are additional tools to deal with them. This chapter covers the following major topics:
“Understanding Parallel Speedup and Amdahl's Law” introduces the mathematical rule that limits the ultimate gain from parallel processing.
“Compiling Serial Code for Parallel Execution” discusses taking a one-CPU program and running it on multiple CPUs, without changing the source code.
“Explicit Models of Parallel Computation” contains a survey of the different types of parallel programming you can use to gain direct control of parallel execution.
“Tuning Parallel Code for SN0” discusses general bottlenecks that can affect any parallel program.
“Scalability and Data Placement” discusses the effect of data placement on performance in the SN0 distributed shared memory system, and how to tune data placement without changing program source.
“Using Data Distribution Directives” reviews the compiler directives you can use to specify data placement in the source of programs using the MP library.
“Non-MP Library Programs and Dplace” discusses data placement for programs that do not use the MP library for parallel execution.
There are two ways to obtain the use of multiple CPUs. You can take a conventional program in C, C++, or Fortran, and have the compiler find the parallelism that is implicit in the code. This method is surveyed under “Compiling Serial Code for Parallel Execution”.
You can write your source code to use explicit parallelism, stating in the source code which parts of the program are to execute asynchronously, and how the parts are to coordinate with each other. “Explicit Models of Parallel Computation” is a survey of the programming models you can use for this, with pointers to the online manuals.
When your program runs on more than one CPU, its total run time should be less. But how much less? What are the limits on the speedup? That is, if you apply 16 CPUs to the program, should it finish in 1/16th the elapsed time?
You can distribute the work your program does over multiple CPUs. However, there is always some part of the program's logic that has to be executed serially, by a single CPU. This sets the lower limit on program run time.
Suppose there is one loop in which the program spends 50% of the execution time. If you can divide the iterations of this loop so that half of them are done in one CPU while the other half are done at the same time in a different CPU, the whole loop can be finished in half the time. The result: a 25% reduction in program execution time.
The mathematical treatment of these ideas is called Amdahl's law, for computer pioneer Gene Amdahl, who formalized it. There are two basic limits to the speedup you can achieve by parallel execution:
The fraction of the program that can be run in parallel, p, is never 100%.
Because of hardware constraints, after a certain point, there is less and less benefit from each added CPU.
Tuning for parallel execution comes down to doing the best that you are able to do within these two limits. You strive to increase the parallel fraction, p, because in some cases even a small change in p (from 0.8 to 0.85, for example) makes a dramatic change in the effectiveness of added CPUs.
Then you work to ensure that each added CPU does a full CPU's work, and does not interfere with the work of other CPUs. In the SN0 architectures this means:
Spreading the workload equally among the CPUs.
Eliminating false sharing and other types of memory contention between CPUs.
Making sure that the data used by each CPU are located in a memory near that CPU's node.
If half the iterations of a DO-loop are performed on one CPU, and the other half run at the same time on a second CPU, the whole DO-loop should complete in half the time. For example, consider the typical C loop in Example 8-1.
The MIPSpro C compiler can automatically distribute such a loop over n CPUs (with n decided at run time based on the available hardware), so that each CPU performs MAX/n iterations.
The speedup gained from applying n CPUs, Speedup(n), is the ratio of the one-CPU execution time to the n-CPU execution time: Speedup(n) = T(1) ÷ T(n). If you measure the one-CPU execution time of a program at 100 seconds, and the program runs in 60 seconds with 2 CPUs, Speedup(2) = 100 ÷ 60 = 1.67.
This number captures the improvement from adding hardware. T(n) ought to be less than T(1); if it is not, adding CPUs has made the program slower, and something is wrong! So Speedup(n) should be a number greater than 1.0, and the greater it is, the more pleased you are. Intuitively you might hope that the speedup would be equal to the number of CPUs—twice as many CPUs, half the time—but this ideal can seldom be achieved.
You expect Speedup(n) to be less than n, reflecting the fact that not all parts of a program benefit from parallel execution. However, it is possible, in rare situations, for Speedup(n) to be larger than n. This is called a superlinear speedup—the program has been sped up by more than the increase of CPUs.
A superlinear speedup does not really result from parallel execution. It comes about because each CPU is now working on a smaller set of memory. The problem data handled by any one CPU fits better in cache, so each CPU executes faster than the single CPU could do. A superlinear speedup is welcome, but it indicates that the sequential program was being held back by cache effects.
There are always parts of a program that you cannot make parallel—code that must run serially. For example, consider the DO-loop. Some amount of code is devoted to setting up the loop, allocating the work between CPUs. This housekeeping must be done serially. Then comes parallel execution of the loop body, with all CPUs running concurrently. At the end of the loop comes more housekeeping that must be done serially; for example, if n does not divide MAX evenly, one CPU must execute the few iterations that are left over.
The serial parts of the program cannot be speeded up by concurrency. Let p be the fraction of the program's code that can be made parallel (p is always a fraction less than 1.0.) The remaining fraction (1-p) of the code must run serially. In practical cases, p ranges from 0.2 to 0.99.
The potential speedup for a program is proportional to p divided by the CPUs you can apply, plus the remaining serial part, 1-p. As an equation, this appears as Example 8-2.
Suppose p = 0.8; then Speedup(2) = 1 / (0.4 + 0.2) = 1.67, and Speedup(4) = 1 / (0.2 + 0.2) = 2.5. The maximum possible speedup—if you could apply an infinite number of CPUs—would be 1 / (1-p). The fraction p has a strong effect on the possible speedup, as shown in the graph in Figure 8-1.
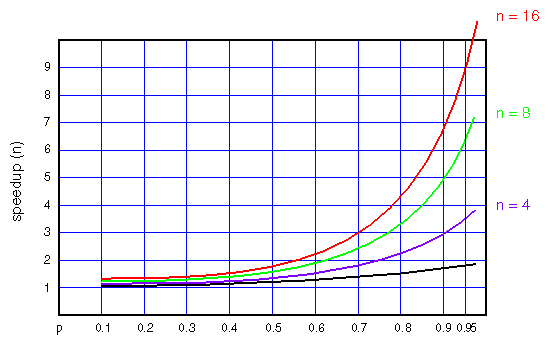
Two points are clear from Figure 8-1: First, the reward for parallelization is small unless p is substantial (at least 0.8); or to put the point another way, the reward for increasing p is great no matter how many CPUs you have. Second, the more CPUs you have, the more benefit you get from increasing p. Using only four CPUs, you need only p= 0.75 to get half the ideal speedup. With eight CPUs, you need p= 0.85 to get half the ideal speedup.
You do not have to guess at the value of p for a given program. Measure the execution times T(1) and T(2) to calculate a measured Speedup(2) = T(1) / T(2). The Amdahl's law equation can be rearranged to yield p when Speedup(2) is known, as in Example 8-3.
Example 8-3. Amdahl's law: p Given Speedup(2)
2 SpeedUp(2) - 1
p = --- * --------------
1 SpeedUp(2)
|
Suppose you measure T(1) = 188 seconds and T(2) = 104 seconds.
SpeedUp(2) = 188/104 = 1.81 p = 2 * ((1.81-1)/1.81) = 2*(0.81/1.81) = 0.895 |
In some cases, the Speedup(2) = T(1)/T(2) is a value greater than 2; in other words, a superlinear speedup (“Understanding Superlinear Speedup”). When this occurs, the formula in Example 8-3 returns a value of p greater than 1.0, which is clearly not useful. In this case you need to calculate p from two other more realistic timings, for example T(2) and T(3). The general formula for p is shown in Example 8-4, where n and m are the two CPU counts whose speedups are known, n>m.
Example 8-4. Amdahl's Law: p Given Speedup(n) and Speedup(m)
Speedup(n) - Speedup(m)
p = -------------------------------------------
(1 - 1/n)*Speedup(n) - (1 - 1/m)*Speedup(m)
|
You can use the calculated value of p to extrapolate the potential speedup with higher numbers of CPUs. For example, if p=0.895 and T(1)=188 seconds, what is the expected time with four CPUs?
Speedup(4)= 1/((0.895/4)+(1-0.895)) = 3.04 T(4)= T(1)/Speedup(4) = 188/3.04 = 61.8 |
The calculation can be made routine using the computer. Example C-8 shows an awk script that automates the calculation of p and extrapolation of run times.
These calculations are independent of most programming issues such as language, library, or programming model. They are not independent of hardware issues, because Amdahl's law assumes that all CPUs are equal. At some level of parallelism, adding a CPU no longer affects run time in a linear way. For example, in the SGI Power Challenge architecture, cache friendly codes scale closely with Amdahl's law up to the maximum number of CPUs, but scaling of memory intensive applications slows as the system bus approaches saturation. When the bus bandwidth limit is reached, the actual speedup is less than predicted.
In the SN0 architecture, the situation is different and better. Some benchmarks on SN0 scale very closely to Amdahl's law up to the maximum number of CPUs, n = 256. However, remember that there are two CPUs per node, so some applications (in particular, applications with high requirements for local memory bandwidth) follow Amdahl's law on a per-node basis rather than a per-CPU basis. Furthermore, not all added CPUs are equal because some are farther removed from shared data and thus may have a greater latency to access that data. In general, when you can place the data used by a CPU in the same node or a neighboring node, the difference in latencies is slight and the program speeds up in line with the prediction of Amdahl's law.
Fortran and C programs that are written in a straightforward, portable way, without explicit source directives for parallel execution, can be parallelized automatically by the compiler. Automatic parallelization is a feature of the MIPSpro compilers; its use is discussed in the compiler books listed under “Related Manuals”.
When the compiler option is installed, you produce a parallelized program by simply including the -apo compiler flag on a compile. The compiler analyzes the code for loops that can be executed in parallel, and inserts code to run those loops on multiple CPUs.
You can insert high-level compiler directives that assist the analyzer in modifying the source code.
A newer OpenMP API has been defined and accepted by several vendors to allow high-level compiler directives that are portable. These OpenMP directives can be inserted in your source code to assist the analyzer in modifying the source code. These directives are covered in the MPISpro 7 Fortran Commands and Directives Reference Manual: OpenMP Fortran API Multiprocessing Directives, the MIPSpro C and C++ Pragmas: OpenMP C/C++ API Multiprocessing Directives, and the MIPSpro Fortran 77 Programmer's Guide: OpenMP Multiprocessing Directives.
The compiler can produce a report showing which loops it could parallelize and which it could not parallelize, and why. The compiler can also produce a listing of the modified source code, after parallelizing and before loop-nest optimization.
The parallel version of the program can be run using from one CPU to as many CPUs as are available. The number of CPUs, and some other choices, are controlled externally to the program by setting environment variables. The number of CPUs the program will use is established by the value of the environment variable, OMP_NUM_THREADS. For more information, see the pe_environ(5) man page.
Run-time control of a parallelized program is the responsibility of libmp, the multiprocessing library that is automatically linked with a parallelized program.
You can use a variety of programming models to express parallel execution in your source program. This topic summarizes the models in order to provide background for tuning, For details, see the Topics in IRIX Programming manual, listed in “Related Manuals”, which contains an entire section on the topic of “models of parallel computation.”
Your Fortran program can contain directives that request parallel execution. When these directives are present in your program, the compiler works in conjunction with the MP runtime library, libmp, to run the program in parallel. There are three families of directives:
The OpenMP (OMP) directives permit you to specify general parallel execution.
Using OMP directives, you can write any block of code as a parallel region to be executed by multiple CPUs concurrently. You can specify parallel execution of the body of a DO-loop. Other directives coordinate parallel threads, for example, to define critical sections.
The OMP directives are documented in the manuals listed under “Compiler Manuals”.
The C$DOACROSS directive and related directives, still supported for compatibility, permit you to specify parallel execution of the bodies of specified DO-loops.
Using C$DOACROSS you can distribute the iterations of a single DO-loop across multiple CPUs. You can control how the work is divided. For example, the CPUs can do alternate iterations, or each CPU can do a block of iterations.
The data distribution directives such as C$DISTRIBUTE and the affinity clauses added to C$DOACROSS permit you to explicitly control data placement and affinity. These have an effect only when executing on SN0 systems.
These directives complement C$DOACROSS, making it easy for you to distribute the contents of an array in different nodes so that each CPU is close to the data it uses in its iterations of a loop body. The data distribution directives and the affinity clauses are discussed under “Using Data Distribution Directives”.
Your C or C++ program can contain pragma statements that specify parallel execution. These pragmas are documented in detail in the MIPSpro C and C++ Pragmas manual listed in “Compiler Manuals”.
The C pragmas are similar in concept to the OMP directives for Fortran. You use the pragmas to mark off a block of code as a parallel region. You can specify parallel execution of the body of a for-loop. Within a parallel region, you can mark off statements that must be executed by only one CPU at a time; this provides the equivalent of a critical section.
The data distribution directives and affinity clauses, which are available for Fortran, are also implemented for C in version 7.2 of the MIPSpro compilers. They are discussed under “Using Data Distribution Directives”.
MPI and PVM are two standard libraries, each designed to solve the problem of distributing a computation across not simply many CPUs but across many systems, possibly of different kinds. Both are supported on SN0 servers.
The MPI (Message-Passing Interface) library was designed and standardized at Argonne National Laboratory, and is documented on the MPI home page at http://www.mcs.anl.gov/mpi/index.html. The PVM (Parallel Virtual Machine) library was designed and standardized at Oak Ridge National Laboratory, and is documented on the PVM home page at http://www.epm.ornl.gov/pvm/.
The SGI implementation of the MPI library generally offers better performance than the SGI implementation of PVM, and MPI is the recommended library. The use of these libraries is documented in the Message Passing Toolkit manuals listed in the section “Software Tool Manuals”.
You can write a multithreaded program using the POSIX threads model and POSIX synchronization primitives (POSIX standards 1003.1b, threads, and 1003.1c, realtime facilities). The use of these libraries is documented in Topics in IRIX Programming, listed in the section “Software Tool Manuals”.
Through IRIX 6.4, the implementation of POSIX threads creates a certain number of IRIX processes and uses them to execute the pthreads. Typically the library creates fewer processes than the program creates pthreads (called an “m-on-n” implementation). You cannot control or predict which process will execute the code of any pthread at any time. When a pthread blocks, the process running it looks for another pthread to run.
Starting with IRIX 6.5, the pthreads library allocates a varying number of execution resources (basically, CPUs) and dispatches them to the runnable threads. These execution resources are allocated and dispatched entirely in the user process space, and do not require the creation of UNIX processes. As a result, pthread dispatching is more efficient.
You can write a multiprocess program using the IRIX sproc() system function to create a share group of processes that execute in a single address space. Alternatively, you can create a program that uses the UNIX model of independent processes that share portions of address space using the mmap() system function. In either case, IRIX offers a wide variety of mechanisms for interprocess communication and synchronization.
The use of the process model and shared memory arenas is covered in Topics in IRIX Programming (see “Software Tool Manuals”) and in the sproc(2) , mmap(2), and usinit(3) man pages.
Parallelizing a program is a big topic, worthy of a book all on its own. In fact, there are several good books and online courses on the subject (see “Third-Party Resources” for a list of some). Parallel programming is a very large topic, and this guide does not attempt to teach it. It assumes that you are already familiar with the basics and concentrates on what is different about the SN0 architecture.
Of course, what's new about SN0 is its shared memory architecture (see “Understanding Scalable Shared Memory” in Chapter 1). The change in architecture has the following implications:
You don't have to program differently for SN0 than for any other shared memory computer. In particular, binaries for earlier Silicon Graphics systems run on SN0, in most cases, with very good performance.
When programs do not scale as well as they should, simply taking account of the physically distributed memory usually restores optimum performance. This can often be done outside the program, or with only simple source changes.
The basic prescription for tuning a program for parallel execution is as follows:
Tune for single-CPU performance, as covered at length in Chapters 4 through 7.
Make sure the program is fully and properly parallelized; the parallel fraction p controls the effectiveness of added hardware (see “Calculating the Parallel Fraction of a Program”).
Examine cache use, and eliminate cache contention and false sharing.
Examine memory access, and apply the right page-placement method.
These last three steps are covered in the rest of this chapter.
The first step in tuning a parallel program is making sure that it has been properly parallelized. This means, first, that enough of the program can be parallelized to allow the program to attain the desired speedup. Use the Amdahl's law extrapolation to determine the parallel fraction of the code (“Calculating the Parallel Fraction of a Program”). If the fraction is not high enough for effective scaling, there is no point in further tuning until it has been increased. For a program that is automatically parallelized, work with the compiler to remove dependencies and increase the parallelized portions (see “Compiling an Auto-Parallel Version of a Program”). When the program uses explicit parallelization, you must work on the program's design, a subject beyond the scope of this book (see “Third-Party Resources”).
Proper parallelization means, second, that the workload is distributed evenly among the CPUs. You can use SpeedShop to profile a parallel program; it provides information on each of the parallel threads. You can use this information to verify that each thread takes about the same amount of time to carry out its pieces of the work. If this is not so, some CPUs are idling with no work at some times. In a program that is parallelized using Fortran or C directives, it may be possible to get better balance by changing the loop scheduling (such as dynamic or guided). In other programs it may again require algorithmic redesign.
If the program has run successfully on another parallel system, both these issues have been addressed. But if you are now running the program on more CPUs than previously available, it is still possible to encounter problems in the parallelization that simply never showed up with lesser parallelism. Be sure to revalidate that any limits in scalability are not due to Amdahl's law, and watch for bugs in code that has not previously been stressed.
The location of data in the SN0 distributed memory is not important when the parallel threads of a program access memory primarily through the L1 and L2 caches. When there is a high ratio of cache (and TLB) hits, the relatively infrequent references to main memory are simply not a significant factor in performance. As a result, you should remove any cache-contention problems before you think about data placement in the SN0 distributed memory. (For an overview of cache issues, see “Understanding the Levels of the Memory Hierarchy” in Chapter 6.)
You can determine how cache-friendly a program is using perfex; it tells you just how many primary, secondary, and TLB cache misses the program generates and what the cache hit ratios are, and it will estimate how much the cache misses cost (as discussed under “Getting Analytic Output with the -y Option” in Chapter 4). There are several possible sources of poor scaling and they can generally be distinguished by examining the event counts returned by perfex:
Load imbalance: Is each thread doing the same amount of work? One way to check this is to see if all threads issue a similar number of floating point instructions (event 21).
Excessive synchronization cost: Are counts of store conditionals high (event 4)?
Cache contention: Are counts of store exclusive to shared block high (event 31)?
When cache misses account for only a small percentage of the run time, the program makes good use of the memory and, more important, its performance will not be affected by data placement. On the other hand, if the time spent in cache misses at some level is high, the program is not cache-friendly. Possibly, data placement in the SN0 distributed memory could affect performance, but there are other issues, common to all cache-based shared memory systems, that are likely to be the source of performance problems, and these should be addressed first.
If a properly parallelized program does not scale as well as expected, there are several potential causes. The first thing to check is whether some form of cache contention is slowing the program. You have presumably done this as part of single-CPU tuning (“Identifying Cache Problems with Perfex and SpeedShop” in Chapter 6), but new cache contention problems can appear when a program starts executing in parallel.
New problems can be an issue, however, only for data that are frequently updated or written. Data that are mostly read and rarely written do not cause cache coherency contention for parallel programs.
The mechanism used in SN0 to maintain cache coherence is described under “Understanding Directory-Based Coherency” in Chapter 1. When one CPU modifies a cache line, any other CPU that has a copy of the same cache line is notified, and discards its copy. If that CPU needs that cache line again, it fetches a new copy. This arrangement can cause performance problems in two cases:
When one CPU repeatedly updates a cache line that other CPUs use for input, all the reading CPUs are forced to frequently retrieve new copies of the cache line from memory. This slows all the reading CPUs.
When two or more CPUs repeatedly update the same cache line, they contend for the exclusive ownership of the cache line. Each CPU has to get ownership and fetch a new copy of the cache line before it can perform its update. This forces the updating CPUs to execute serially, as well as making all other CPUs fetch a new copy of the cache line on every use.
In some cases, these problems arise because all parallel threads in the program are genuinely contending for use of the same key global variables. In that case, the only cure is an algorithmic change.
More often, cache contention arises because the CPUs are using and updating unrelated variables that happen to fall in the same cache line. This is false sharing. Fortunately, IRIX tools can help you identify these problems. Cache contention is revealed when perfex shows a high number of cache invalidation events: counter events 31, 12, 13, 28, and 29. A CPU that repeatedly updates the same cache line shows a high count of stores to shared cache lines: counter 31. (See “Cache Coherency Events” in Appendix B.)
False sharing can be demonstrated with code like that in Example 8-5.
Example 8-5. Fortran Loop with False Sharing
subroutine sum85 (a,s,m,n)
integer m, n, i, j
real a(m,n), s(m)
!$omp parallel do private(i,j), shared(s,a)
do i = 1, m
s(i) = 0.0
do j = 1, n
s(i) = s(i) + a(i,j)
enddo
enddo
return
end
|
This code calculates the sums of the rows of a matrix. For simplicity, assume m=4 and that the code is run on up to four CPUs. What you observe is that the time for the parallel runs is longer than when just one CPU is used. To understand what causes this, look at what happens when this loop is run in parallel.
The following is a time line of the operations that are carried out (more or less) simultaneously:
| t=0 | t=1 | t=2 |
|
CPU 0 | s(1) = 0.0 | s(1) = s(1) + a(1,1) | s(1) = s(1) + a(1,2) | ... |
CPU 1 | s(2) = 0.0 | s(2) = s(2) + a(2,1) | s(2) = s(2) + a(2,2) | ... |
CPU 2 | s(3) = 0.0 | s(3) = s(3) + a(3,1) | s(3) = s(3) + a(3,2) | ... |
CPU 3 | s(4) = 0.0 | s(4) = s(4) + a(4,1) | s(4) = s(4) + a(4,2) | ... |
At each stage of the calculation, all four CPUs attempt to update one element of the sum array, s(i). For a CPU to update one element of s, it needs to gain exclusive access to the cache line holding that element, but the four words of s are probably contained in a single cache line, so only one CPU at a time can update an element of s. Instead of operating in parallel, the calculation is serialized.
Actually, it's a bit worse than merely serialized. For a CPU to gain exclusive access to a cache line, it first needs to invalidate cached copies that may reside in the other caches. Then it needs to read a fresh copy of the cache line from memory, because the invalidations will have caused data in some other CPU's cache to be written back to main memory. In a sequential version of the program, the element being updated can be kept in a register, but in the parallel version, false sharing forces the value to be continually reread from memory, in addition to serializing the updates.
This serialization is purely a result of the unfortunate accident that the different elements of s ended up in the same cache line. If each element were in a separate cache line, each CPU could keep a copy of the appropriate line in its cache, and the calculations could be done perfectly in parallel. A possible way to fix the problem is to spread the elements of s out so that each updated element resides in its own cache line, as shown in Example 8-6.
Example 8-6. Fortran Loop with False Sharing Removed
subroutine sum86 (a,s,m,n)
integer m, n, i, j
real a(m,n), s(32,m)
!$omp parallel do private(i,j), shared(s,a)
do i = 1, m
s(1,i) = 0.0
do j = 1, n
s(1,i) = s(1,i) + a(i,j)
enddo
enddo
return
end
|
The elements s(1,1), s(1,2), s(1,3) and s(1,4) are separated by at least 32 × 4 = 128 bytes, and so are guaranteed to fall in separate cache lines. Implemented this way, the code achieves perfect parallel speedup.
Another possible way to fix the problem in Example 8-5 is to replace all of the s(i)s inside the loop on i with a new variable, stemp, that is declared private. Then add a final statement inside the loop on i to assign stemp to s(i).
Note that the problem of false sharing is not specific to the SN0 architecture. It occurs in any cached-coherent shared memory system.
To see how this works for a real code, see an example from a paper presented at the Supercomputing '96 conference. One example in this paper is a weather modeling program that shows poor parallel scaling (the red curve in Figure 8-2).
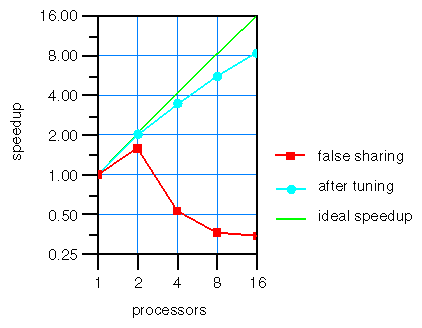
Running the program under perfex revealed that the number of secondary data cache misses (event 26) increased as the number of CPUs increased, as did the number of stores exclusive to a shared block (event 31). The large event 31 counts, increasing with the secondary cache misses, indicated a likely problem with false sharing. (The large number of secondary cache misses were a problem as well.)
The source of the problem was found using ssrun. There are several events that can be profiled to determine where false sharing occurs. The natural one to use is event 31, “store/prefetch exclusive to shared block in scache.” There is no explicitly named experiment type for this event, so profiling it requires setting the following environment variables:
% setenv _SPEEDSHOP_HWC_COUNTER_NUMBER 31 % setenv _SPEEDSHOP_HWC_COUNTER_OVERFLOW 99 % ssrun -exp prof_hwc a.out % prof a.out.prof_hwc.m* a.out.prof_hwc.p* |
(See “Sampling Through Other Hardware Counters” in Chapter 4.) You could also profile external interventions (event 12) or external invalidations (event 13), but using event 31 shows where the source of the problem is in the program (some thread asking for exclusive access to a cache line) rather than the place a thread happens to be when an invalidation or intervention occurs. Another event that can be profiled is secondary cache misses (event 26). For this event, use the -dsc_hwc experiment type and don't set any environment variables.
For this program, profiling secondary cache misses was sufficient to locate the source of the false sharing. The profile showed that the majority of secondary cache misses occurred in an accumulation step, similar to the row summation in Example 8-5. Padding was used to move each CPU's accumulation variable into its own cache line. After doing this, the performance improved dramatically (the blue curve in Figure 8-2).
You can often deal with cache contention by changing the layout of data in the source program, but sometimes you may have to make algorithmic changes as well. If profiling indicates that there is cache contention, examine the parallel regions identified; any assignment to memory in the parallel regions is a possible source of the contention. You need to determine if the assigned variable, or the data adjacent to it, is used by other CPUs at the same time. If so, the assignment forces the other CPUs to read a fresh copy of the cache line, and this is a source of contention.
To deal with cache contention, you have the following general strategies:
Minimize the number of variables that are accessed by more than one CPU.
Segregate non-volatile (rarely updated) data items into cache lines different from volatile (frequently updated) items.
Isolate unrelated volatile items into separate cache lines to eliminate false sharing.
When volatile items are updated together, group them into single cache lines.
An update of one word (that is, a 4-byte quantity) invalidates all the 31 other words in the same L2 cache line. When those other words are not related to the new data, false sharing results. Use strategy 3 to eliminate the false sharing.
Be careful when your program defines a group of global status variables that is visible to all parallel threads. In the normal course of running the program, every CPU will cache a copy of most or all of this common area. Shared, read-only access does no harm. But if items in the block are volatile (frequently updated), those cache lines are invalidated often. For example, a global status area might contain the anchor for a LIFO queue. Each time a thread puts or takes an item from the queue, it updates the queue head, invalidating that cache line.
It is inevitable that a queue anchor field will be frequently invalidated. The time cost, however, can be isolated to the code that accesses the queue by applying strategy 2. Allocate the queue anchor in separate memory from the global status area. Put only a pointer to the queue anchor (a non-volatile item) in the global status block. Now the cost of fetching the queue anchor is born only by CPUs that access the queue. If there are other items that are updated along with the queue anchor—such as a lock that controls exclusive access to the queue—place them adjacent to the queue, aligned so that all are in the same cache line (strategy 4). However, if there are two queues that are updated at unrelated times, place the anchor of each in its own cache line (strategy 3).
Synchronization objects such as locks, semaphores, and message queues are global variables that must be updated by each CPU that uses them. You may as well assume that synchronization objects are always accessed at memory speeds, not cache speeds. You can do two things to reduce contention:
Minimize contention for locks and semaphores through algorithmic design. In particular, use more, rather than fewer, semaphores, and make each one stand for the smallest resource possible so as to minimize the contention for any one resource. (Of course, this makes it more difficult to avoid deadlocks.)
Never place unrelated synchronization objects in the same cache line. A lock or semaphore may as well be in the same cache line as the data that it controls, because an update of one usually follows an update of the other. But unrelated locks or semaphores should be in different cache lines.
When you make a loop run in parallel, try to ensure that each CPU operates on its own distinct sections of the input and output arrays. Sometimes this falls out naturally, but there are also compiler directives for just this purpose. (These are described in “Using Data Distribution Directives”.)
Carefully review the design of any data collections that are used by parallel code. For example, the root and the first few branches of a binary tree are likely to be visited by every CPU that searches that tree, and they will be cached by every CPU. However, elements at higher levels in the tree may be visited by only a few CPUs. One option is to pre-build the top levels of the tree so that these levels never have to be updated once the program starts. Also, before you implement a balanced-tree algorithm, consider that tree-balancing can propagate modifications all the way to the root. It might be better to cut off balancing at a certain level and never disturb the lower levels of the tree. (Similar arguments apply to B-trees and other branching structures: the “thick” parts of the tree are widely cached and should be updated least often, while the twigs are less frequently used.)
Other classic data structures can cause memory contention, and algorithmic changes are needed to cure it:
The two basic operations on a heap (also called a priority queue) are “get the top item” and “insert a new item.” Each operation ripples a change from end to end of the heap-array. However, the same operations on a linked list are read-only at all nodes except for the one node that is directly affected. Therefore, a priority list used by parallel threads might be faster implemented as a linked list than as a heap—the opposite of the usual result.
A hash table can be implemented compactly, with only a word or two in each entry. But that creates false sharing by putting several table entries (which by definition are logically unrelated) into the same cache line. Avoid false sharing: make each hash table entry a full 128 bytes, cache-aligned. (You can take advantage of the extra space to store a list of overflow hits in each entry. Such a list can be quickly scanned because the entire cache line is fetched as one operation.)
Data placement issues do not arise for all parallel programs. Those that are cache friendly do not incur performance penalties even when data placement is not optimal, because such programs satisfy their memory requests primarily from cache, rather than main memory. Data placement can be an issue only for parallel programs that are memory intensive and are not cache friendly.
If a memory-intensive parallel program exhibits scaling that is less than expected, and you are sure that false sharing and other forms of cache contention are not a problem, consider data placement. Optimizing data placement is a new performance issue unique to SN0 and other distributed-memory architectures.
The IRIX operating system should automatically ensure that all programs achieve good data placement. There are two things IRIX wants to optimize:
The program's topology; that is, the processes making up the parallel program should run on nodes that minimize access costs for data they share.
The page placement; that is, the memory a process accesses the most often should be allocated from its own node, or the minimum distance from that node.
Accomplishing these two tasks automatically for all programs is virtually impossible. The operating system simply doesn't have enough information to do a perfect job, but it does the best it can to approximate a good solution. The policies and topology choices the operating system uses to try to optimize data placement were described under “IRIX Memory Locality Management” in Chapter 2. IRIX uses:
memory locality domains (MLDs) and policy modules (PMs) to achieve a good topology (“Memory Locality Management” in Chapter 2)
A variety of page placement policies to try to get the initial page placements correct (“Data Placement Policies” in Chapter 2)
Dynamic page migration to correct placement errors that arise as a program runs (“Dynamic Page Migration” in Chapter 2)
This technology produces good results for many, but not all, programs.You can also tune data placement, if the operating system's efforts are insufficient.
Data placement is tuned by specifying the appropriate policies and topologies, and if need be, programming with them in mind. They are specified using the utility dplace, environment variables understood by the MP library, and compiler directives.
Unlike false sharing, there is no profiling technique that will tell you definitively that poor data placement is hurting the performance of your program. Poor placement is a conclusion you have to reach after eliminating the other possibilities. Fortunately, once you suspect a data placement problem, many of the tuning options are very easy to perform, and you can often allay your suspicions or solve the problem with a few simple experiments.
The techniques for tuning data placement can be separated into two classes:
Use MP library environment variables to adjust the operating system's default data placement policies. This is simple to do, involves no modifications to your program, and is all you will have to do to solve many data placement problems.
Modify the program to ensure an optimal data placement. This approach requires more effort, so try this only if the first approach does not work, or if you are developing a new application. The amount of effort in this approach ranges from simple things such as making sure that the program's data initializations—as well as its calculations—are parallelized, to adding some data distribution compiler directives, to modifying algorithms as would be done for purely distributed memory architectures.
Data placement policies used by the operating system are introduced under “Data Placement Policies” in Chapter 2. The default policy is called first-touch. Under this policy, the process that first touches (that is, writes to, or reads from) a page of memory causes that page to be allocated in the node on which the process is running. This policy works well for sequential programs and for many parallel programs as well. For example, this is just what you want for message-passing programs that run on SN0. In such programs each process has its own separate data space. Except for messages sent between the processes, all processes use memory that should be local. Each process initializes its own data, so memory is allocated from the node the process is running in, thus making the accesses local.
But for some parallel programs, the first-touch policy can have unintended side effects. As an example, consider a program parallelized using the MP library. In parallelizing such a program, the programmer worries only about parallelizing those parts of the program that take the most amount of time. Often, data initialization code takes little time, so they are not parallelized, and so are executed by the main thread of the program. Under the first-touch policy, all the program's memory ends up allocated in the node running the main thread. Having all the data concentrated in one node or within a small radius of it creates a bottleneck: all data accesses are satisfied by one hub, and this limits the memory bandwidth. If the program is run on only a few CPUs, you may not notice a bottleneck. But as you add more CPUs, the one hub that serves the memory becomes saturated, and the speed does not scale as predicted by Amdahl's law.
One easy way to test for this problem is to try other memory allocation policies. The first one you should try is round-robin allocation. Under this policy, data are allocated in a round-robin fashion from all the nodes the program runs on. Thus, even if the data are initialized sequentially, the memory holding them will not be allocated from a single node; it will be evenly spread out among all the nodes running the program. This may not place the data in their optimal locations—that is, the access times are not likely to be minimized—but there will be no bottlenecks, so scalability will not be limited.
You can enable round-robin data placement for an MP library program with the following environment variable setting (see pe_environ(5) man page) :
% setenv _DSM_ROUND_ROBIN |
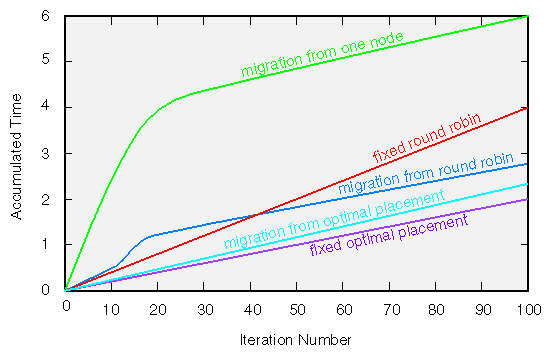
The performance improvement this can make is demonstrated with an example. The plot in Figure 8-3 shows the performance achieved for three parallelized runs of the double-precision vector operation a(i) = b(i) + q*c(i) .
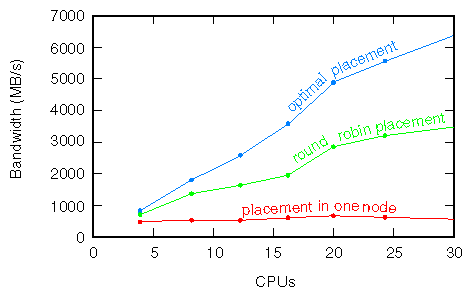
The bandwidth calculated assumes that 24 bytes are moved for each vector element. The red curve (“placement in one node”) shows the performance you attain using a first-touch placement policy and a sequential initialization so that all the data end up in the memory of one node. The memory bottleneck this creates severely limits the scaling. The green curve (“round-robin placement”) shows what happens when the data placement policy is changed to round-robin. The bottleneck disappears and the performance now scales with the number of CPUs. The performance isn't ideal—the blue line (“optimal placement”) shows what you measure if the data are placed optimally—but by spreading the data around, the round-robin policy makes the performance respectable. (Ideal data placement cannot be accomplished simply by initializing the data in parallel.)
If a round-robin data placement solves the scaling problem that led you to tune the data placement, then you're done! But if the performance is still not up to your expectations, the next experiment to perform is enabling dynamic page migration.
The IRIX automatic page migration facility is disabled by default because page migration is an expensive operation that impacts all CPUs, not just the ones used by the program whose data are being moved. You can enable dynamic page migration for a specific MP library program by setting the environment variable _DSM_MIGRATION. You can set it to either ON or ALL_ON:
% setenv _DSM_MIGRATION ON % setenv _DSM_MIGRATION ALL_ON |
When set to ALL_ON, all program data is subject to migration. When set only to ON, only those data structures that have not been explicitly placed via the compiler's data distribution directives (“Using Data Distribution Directives”) will be migrated.
Enabling migration is beneficial when a poor initial placement of the data is responsible for limited performance. However, it cannot be effective unless the program runs for at least half a minute, first because the operating system needs some time to move the data to the best layout, and second because the program needs to execute for some time with the pages in the best locations in order to recover the time cost of migrating.
In addition to the MP library environment variables, migration can also be enabled as follows:
For non-MP library programs, run the program using dplace with the -migration option. This is described under “Enabling Page Migration”.
The system administrator can temporarily enable page migration for all programs using the sn command (see the sn(1M) man page) or enable it permanently by using systune to set the numa_migr_base_enabled system parameter. (See the systune(1M) man page, the System Configuration manual listed in “Software Tool Manuals”, and the comments in the file /var/sysgen/mtune/numa.)
You can try to reduce the cost of migrating from a poor initial location to the optimal one by combining a round-robin initial placement with migration. You won't know whether round-robin, migration, or both together will produce the best results unless you try the different combinations, so tuning the data placement requires experimentation. Fortunately, the environment variables make these experiments easy to perform.
Figure 8-4 shows the results of several experiments on the vector operation
a(i) = b(i) + q*c(i) |
In addition to combinations of the round-robin policy and migration, the effect of serial and parallel initializations are shown. For the results presented in the diagram, the vector operation was iterated 100 times and the time per iteration was plotted to see the performance improvement as the data moved toward optimal layout.
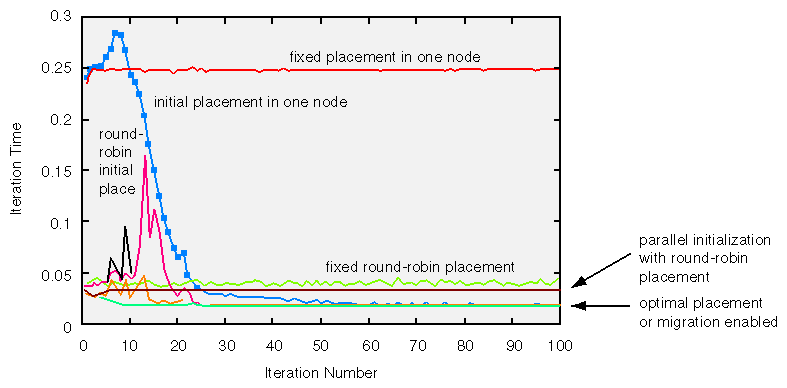
The curve at the top (“fixed placement in one node”) shows the performance for the poor initial placement caused by a sequential data initialization with a first-touch policy. No migration is used, so this performance is constant over all iterations. The line near the bottom (“fixed round-robin placement”) shows that a round-robin initial placement fixes most of the problems with the serial initialization: the time per iteration is five times faster than with the first-touch policy. Ultimately, though, the performance is still a factor of two slower than if an optimal data placement had been used. Once again, migration is not enabled, so the performance is constant over all iterations.
The flat curve just below the curve shows the performance achieved when a parallel initialization is used in conjunction with a round-robin policy. Its per-iteration time is constant and nearly the same as when round-robin is used with a sequential initialization. This is to be expected: the round-robin policy spreads the data evenly among the CPUs, so it matters little how the data are initialized.
The remaining five curves all asymptote to the optimal time per iteration. Four of these eventually achieve the optimal time due to the use of migration. The teal curve (at the bottom of the figure) uses a parallel initialization with a first-touch policy to achieve the optimal data placement from the outset. The orange curve just above it starts out the same, but for it, migration is enabled. The result of using migration on perfectly placed data is only to scramble the pages around before finally settling down on the ideal time. Above this curve are a magenta and a black curve (round-robin initial placement). They show the effect of combining migration and a round-robin policy. The only difference is that the magenta curve used a serial initialization while the black curve used a parallel initialization. For these runs, the serial initialization took longer to reach the steady-state performance (the black curve doesn't show up well in the figure), but you should not conclude that this is a general property; when a round-robin policy is used, it doesn't matter how the data are initialized.
Finally, the blue curve (“initial placement in one node”) shows how migration improves a poor initial placement in which all the data began in one node. It takes longer to migrate to the optimal placement than the other cases, indicating that by combining a round-robin policy with migration, one can do better than by using just one of the remedies alone. Dramatic evidence of this is seen when the cumulative program run time is plotted, as shown in Figure 8-5.
These results show clearly that, for this program, migration eventually gets the data to their optimal location and that migrating from an initial round-robin placement is faster than migrating from an initial placement in which all the data are on one node. Note, though, that migration does take time: if only a small number of iterations are going to be performed, it is better to use a round-robin policy without migration.
The results for data migration were generated using this environment variable setting:
% setenv _DSM_MIGRATION ON |
(This program has no data distribution directives in it, so in this case, there is no difference between a setting of ON and one of ALL_ON.) But you can also adjust the migration level, that is, control how aggressively the operating system migrates data from one memory to another. The migration level is controlled with the following environment variable setting (see pe_environ(5) man page):
% setenv _DSM_MIGRATION_LEVEL level |
A high level (100 maximum) means aggressive migration, and a low level means nonaggressive migration. A level of 0 means no migration. The migration level can be used to experiment with how aggressively migration is performed. The plot in Figure 8-6 shows the improvement in time per iteration for various migration levels as memory is migrated from an initial placement in one node. As you would expect, with migration enabled, the data will eventually end up in an optimal location, while the more aggressive migration is, the faster the pages get to where they should be.
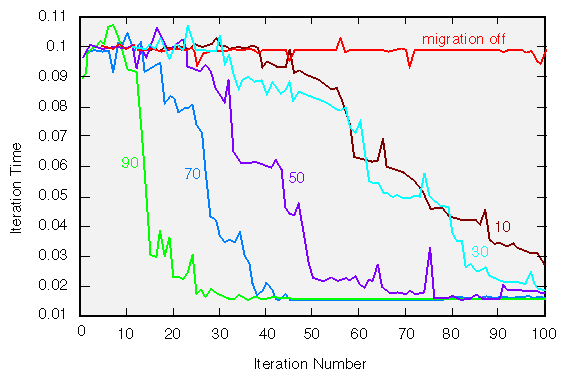
The best level for a particular program will depend on how much time is available to move the data to their optimal location. A low migration level is fine for a long-running program with a poor initial data placement. But if a program can only afford a small amount of time for the data to redistribute, a more aggressive migration level is needed. Keep in mind that migration has an impact on system-wide performance, and the more aggressive the migration, the greater the impact. For most programs the default migration level setting is 100 (agressive).
In general, you should try the following experiments when you need to tune data placement:
See if using a round-robin policy fixes the scaling problem. If so, you need not try other experiments.
Try migration. If migration achieves about the same performance as round-robin, round-robin is to be preferred because it has less of an impact on other users of the system.
If migration alone achieves a better performance than round-robin alone, try the combination of both. This combination might not improve the steady-state performance, but it might get it to the steady-state performance faster.
Note that these data placement tuning experiments apply only to MP library programs:
Sequential programs aren't affected by data placement.
First-touch is the right placement policy for message-passing (MPI or PVM) programs.
These environment variables are understood only by the MP library (for other features of libmp, see the mp(3) man page).
In some cases you will need to tune the data placement via code modifications. There are three levels of code modification you can use:
Rely on the default first-touch policy, and program with it in mind. This programming style is easy to use: often, fixing data placement problems is as simple as making sure all the data are initialized in a parallelized loop, so that the data starts off in the memory of the CPU that will use it.
Insert regular data distribution directives (for example, C$DISTRIBUTE). These directives allow you to specify how individual data structures should be distributed among the memory of the nodes running the program, subject to the constraint that only whole pages can be distributed.
Insert reshaping directives (for example, C$DISTRIBUTE_RESHAPE). These allow you to specify how individual data structures should be distributed among the memory of the nodes running the program, but they are not restricted to whole-page units. As a result, distributed data structures are not guaranteed to be contiguous; that is, they can have holes in them, and if you do not program properly, this can break your program.
Each of these three approaches requires the programmer to think about data placement explicitly. This is a new concept that doesn't apply to conventional shared-memory architectures. However, the concept has been used for years in programming distributed memory computers, and if you have written a message-passing program, you understand it well. These approaches are discussed in the three topics that follow.
If there is a single placement of data that is optimal for your program, you can use the default first-touch policy to cause each CPU's share of the data to be allocated from memory local to its node. As a simple example, consider parallelizing the vector operation in Example 8-7.
Example 8-7. Easily Parallelized Fortran Vector Routine
integer i, j, n, niters
parameter (n = 8*1024*1024, ndim = n+35, niters = 100)
real a(ndim), b(ndim), q
c initialization
do i = 1, n
a(i) = 1.0 - 0.5*i
b(i) = -10.0 + 0.01*(i*i)
enddo
c real work
do it = 1, niters
q = 0.01*it
do i = 1, n
a(i) = a(i) + q*b(i)
enddo
enddo
print *, a(1), a(n), q
end
|
This vector operation is easy to parallelize; the work can be divided among the CPUs of a shared memory computer any way you would like. For example, if p is the number of CPUs, the first CPU can carry out the first n/p iterations, the second CPU the next n/p iterations, and so on. (This is called SCHEDULE (STATIC).) Alternatively, each thread can perform one of the first p iterations, then one of the next p iterations and so on. (This is called SCHEDULE (STATIC,1).) If Example 8-7 is compiled with option -O2 and Example 8-8 is compiled with options -mp -O2, the speedup is approximately 3.2 when four processors are specified for the code using the OpenMP directives.
In a cache-based machine, not all divisions of work produce the same performance. The reason is that if a CPU accesses the element a(i), the entire cache line containing a(i) is moved into its cache. If the same CPU works on the following elements, they will be in cache. But if different CPUs work on the following elements, the cache line will have to be loaded into each one's cache. Even worse, false sharing is likely to occur. Thus performance is best for work allocations in which each CPU is responsible for blocks of consecutive elements.
Example 8-8 shows the above vector operation parallelized for SN0.
Example 8-8. Fortran Vector Operation, Parallelized
integer i, j, n, niters
parameter (n = 8*1024*1024, niters = 1000)
real a(n), b(n), q
c initialization
c$doacross local(i), shared(a,b)
do i = 1, n
a(i) = 1.0 - 0.5*i
b(i) = -10.0 + 0.01*(i*i)
enddo
c real work
do it = 1, niters
q = 0.01*it
c$doacross local(i), shared(a,b,q)
do i = 1, n
a(i) = a(i) + q*b(i)
enddo
enddo
|
Because the schedule type is not specified, it defaults to simple: that is., process 0 performs iterations 1 to n/p, process 1 performs iterations 1 + (n/p) to 2 × n/p, and so on. Each process accesses blocks of memory with stride 1.
Because the initialization takes a small amount of time compared with the “real work,” parallelizing it doesn't reduce the sequential time of this code by much. Some programmers wouldn't bother to parallelize the first loop for a traditional shared memory computer. However, if you are relying on the first-touch policy to ensure a good data placement, it is critical to parallelize the initialization code in exactly the same way as the processing loop.
Due to the correspondence of iteration number with data element, the parallelization of the “real work” loop means that elements 1 to n/p of the vectors a and b are accessed by process 0. To minimize memory access times, you would like these data elements to be allocated from the memory of the node running process 0. Similarly, elements 1 + (n/p) to 2 × n/p are accessed by process 1, and you would like them allocated from the memory of the node running it, and so on. This is accomplished automatically by the first-touch policy. The CPU that first touches a data element causes the page holding that data element to be allocated from its local memory. Thus, if the data are to be allocated so that each CPU can make local accesses during the “real work” section of the code, each CPU must be the one to initialize its share of the data. This means that the initialization loop must be parallelized the same way as the “real work” loop.
Now consider why the simple schedule type is important to Example 8-8. Data are placed in units of one page, so they will end up in their optimal location only if the same CPU processes all the data elements in a page. The default page size is 16 KB, or 4096 REAL*4 data elements; this is a fairly large number. Since the static schedule blocks together as many elements as possible for a single CPU to work on (n/p), it will create more optimally-allocated pages than any other work distribution.
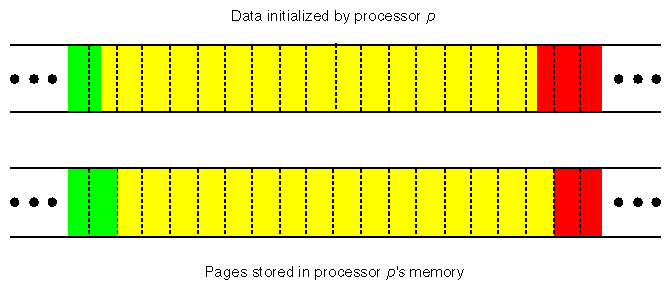
For Example 8-8, n = 8 × 1024 × 1024 = 8388608. If the program is run on 128 CPUs, n/p = 65536, which means that each CPU's share of each array fills sixteen 16 KB pages ((65536 elements × 4) ÷ 16 KB). However, it is unlikely that any array begins exactly on a page boundary, so you would expect 15 of a CPU's 16 pages to contain only elements it processes, and two additional pages, each of which will contain some elements of the appropriate CPU along with some elements belonging to a neighboring CPU. This effect is diagrammed in Figure 8-7.
In a perfect data layout, no pages would share elements from multiple CPUs, but this small imperfection has a negligible effect on performance.
On the other hand, if you used a SCHEDULE(STATIC,1) clause, all 128 CPUs repeatedly attempt to concurrently touch 128 adjacent data elements. Because 128 adjacent data elements are almost always on the same page, the resulting data placement could be anything from a random distribution of the pages, to one in which all pages end up in the memory of a single CPU. This initial data placement will certainly affect the performance.
In general, you should try to arrange it so that each CPU's share of a data structure exceeds the size of a page. For finer granularity, you need the directives discussed under “Using Reshaped Distribution Directives”.
Programming for the default first-touch policy is effective if the application requires only one distribution of data. When different data placements are required at different points in the program, more sophisticated techniques are required. The data directives (see “Using Data Distribution Directives”) allow data structures to be redistributed at execution time, so they provide the most general approach to handling multiple data placements.
In many cases, you don't need to go to this extra effort. For example, the initial data placement can be optimized with first-touch, and migration can redistribute data during the run of the program. In other cases, copying can be used to handle multiple data placements. As an example, consider the FT kernel of the NAS FT benchmark (see the link under “Third-Party Resources”). This is a three-dimensional Fast Fourier Transform (FFT) carried out multiple times. It is implemented by performing one-dimensional FFTs in each of the three dimensions. As long as you don't need more than 128-way parallelism, the x- and y-calculations can be parallelized by partitioning data along the z-axis, as sketched in Figure 8-8.
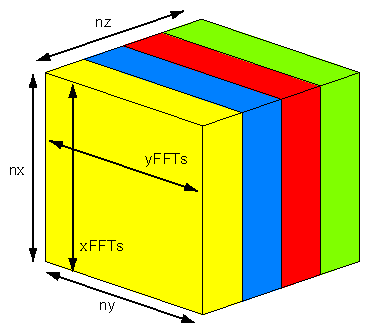
For SN0, first-touch is used to place nz/p, xy-planes in the local memory of each CPU. The CPUs are then responsible for performing the FFTs in their shares of planes.
Once the FFTs are complete, z-transforms need to be done. On a conventional distributed memory computer, this presents a problem. The xy-planes have been distributed, no CPU has access to all the data along the lines in the z-dimension, so the z-FFTs cannot be performed. The conventional solution is to redistribute the data by transposing the array, so that each CPU holds a set of zy-planes. One-dimensional FFTs can then be carried out along the first dimension in each plane. A transpose is convenient since it is a well-defined operation that can be optimized and packaged into a library routine. In addition, it moves a lot of data together, so it is more efficient than moving individual elements to perform z-FFTs one at a time. (This technique was discussed earlier at “Understanding Transpositions” in Chapter 6.)
SN0, however, is a shared memory computer, so explicit data redistribution is not needed. Instead, split up the z-FFTs among the CPUs by partitioning work along the y-axis, as sketched in Figure 8-9.
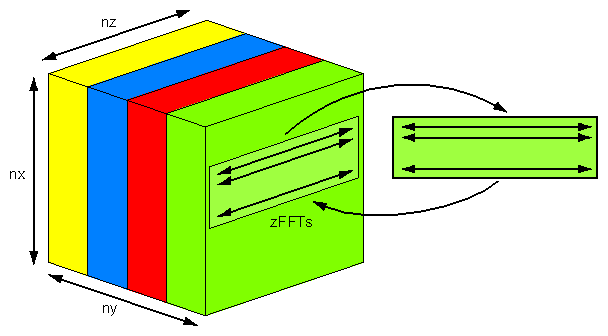
Each CPU then copies several z-lines at a time into a scratch array, performs the z-FFTs on the copied data, and completes the operation by copying back the results.
Copying has several advantages over explicitly redistributing the data:
It brings several z-lines directly into each CPU's cache, and the z-FFTs are performed on these in-cache data. A transpose moves nonlocal memory to local memory, which must then be moved into the cache in a separate step.
Copying reduces TLB misses. The same technique was recommended earlier under “Using Copying to Circumvent TLB Thrashing” in Chapter 6.
Copying scales well because it is perfectly parallel. Parallel transpose algorithms require frequent synchronization points.
Copying is easy to implement. An optimal transpose is not simple code to write.
Combining first-touch placement with copying solves a problem that might otherwise require two data distributions.
You can create almost any data placement using the first-touch policy. However, it may not be easy for others to see what you are trying to accomplish. Furthermore, changing the data placement could require modifying a lot of code. An alternate way to distribute data is through compiler directives. Directives state explicitly how the data are distributed. Modifying the data distribution is easy; it only requires updating the directives, rather than changing the program logic or the way the data structures are defined.
The MIPSpro 7.2 compilers support two types of data distribution directives: regular and reshaping. Both allow you to place blocks or stripes of arrays in the memory of the CPUs that operate on those data. The regular data distribution directives are limited to units of whole virtual pages, whereas the reshaping directives permit arbitrary granularity.
Data distribution directives are supported for both Fortran and C. For Fortran, two forms of the directives are accepted: an old form starting with C$ and a new form that extends the OpenMP directive set. For C and C++, the directives are written as pragmas.
Despite the differences in syntax, there are only five directives, plus an extended clause to the directive for parallel processing. These are supported in all languages beginning with compiler release 7.2. They are summarized in Table 8-1.
Table 8-1. Forms of the Data Distribution Directives
Purpose | C and C++ | Old Fortran | OpenMP style Fortran |
|---|---|---|---|
Define regular distribution of an array | #pragma distribute | C$DISTRIBUTE | !$SGI DISTRIBUTE |
Define reshaped distribution of an array | #pragma distribute_resh ape | C$DISTRIBUTE_RESHAPE | !$SGI DISTRIBUTE_RESHAPE |
Permit dynamic redistribution of an array | #pragma dynamic | C$DYNAMIC | !$SGI DYNAMIC |
Force redistribution of an array | #pragma redistribute | C$REDISTRIBUTE | !$SGI REDISTRIBUTE |
Specify distribution by pages | #pragma page_place | C$PAGE_PLACE | !$SGI PAGE_PLACE |
Associate parallel threads with distributed data | #pragma pfor ... affinity(idx) = data(array(expr)) ... | C$DOACROSS ... AFFINITY(idx) = data(array(expr)) ... | !$OMP PARALLEL DO... |
All directives but the last one have the same verb and arguments in each language; only the fixed text that precedes the verb varies (#pragma, C$, or !$SGI). This book refers to these directives by their verbs: Distribute, Distribute_Reshape, Dynamic, Redistribute, and Page_Place. The final directive is named depending on the language: pfor for C and C++, DOACROSS for old Fortran, or PARALLEL DO for OpenMP Fortran. For C/C++ the directives should appear completely in lower case, and an argument such as a(block) in Fortran becomes a[block] when expressed in a C/C++ #pragma.
Note that the distribute directive must follow the array(s) to which it makes reference. C/C++ programs are currently limited to have one array argument per distribute directive.
For detailed documentation of these directives, see the manuals listed in “Compiler Manuals”.
An example is the easiest way to show the use of the Distribute directive. Example 8-9 shows the easily-parallelized vector operation of Example 8-7 modified with directives to ensure proper placement of the arrays.
Example 8-9. Fortran Vector Operation with Distribution Directives
integer i, j, n, niters
parameter (n = 8*1024*1024, ndim = n+35, niters = 100)
c---Note that the distribute directive FOLLOWS the array declarations.
real a(ndim), b(ndim), q
!$sgi distribute a(block), b(block)
c initialization
do i = 1, n
a(i) = 1.0 - 0.5*i
b(i) = -10.0 + 0.01*(i*i)
enddo
c real work
do it = 1, niters
q = 0.01*it
!$OMP PARALLEL DO private(i), shared(a,b,q)
!$SGI+ affinity (i) = data(a(i))
do i = 1, n
a(i) = a(i) + q*b(i)
enddo
enddo
print *, a(1), a(n), q
end
|
Two directives are used: The first, Distribute, instructs the compiler to allocate the memory for the arrays a and b from all nodes on which the program runs. The second directive, Parallel Do, uses the clause AFFINITY (I) = DATA (A(I)), an SGI extension, to tell the compiler to distribute work to the CPUs based on how the contents of array a are distributed.
Note that because the data is explicitly distributed, it is no longer necessary to parallelize the initialization loop to properly distribute the data among all CPUs using first-touch allocation (although it is still good programming practice to parallelize data initializations).
In Example 8-9, Distribute specifies a BLOCK mapping for both arrays. BLOCK means that, when running with p CPUs, each array is to be divided into p blocks of size ceiling(n/p), with the first block assigned to the first CPU, the second block assigned to the second CPU, and so on. The intent of assigning blocks to CPUs is to allow each block to be stored in one CPUs' local memory.
Only whole pages are distributed, so when a page straddles blocks belonging to different CPUs, it is stored entirely in the memory of a single node. As a result, some CPUs will use nonlocal accesses to some of the data on one or two pages per array. (The situation is diagrammed in Figure 8-7.) An imperfect data distribution has a negligible effect on performance because, as long as a “block” comprises at least a few pages, the ratio of nonlocal to local accesses is small. When the block size is less than a page, you must live with a larger fraction of nonlocal accesses, or use the reshaped directives. (Data placement is rarely important for arrays smaller than a page, because if they are used heavily, they fit entirely in cache.)
Now look at the Parallel Do directive in Example 8-9. It instructs the compiler to run this loop in parallel. But instead of distributing iterations to CPUs by specifying a schedule type such as SCHEDULE(STATIC) or SCHEDULE(STATIC,1), the AFFINITY clause is used. This new clause tells the compiler to execute iteration i on the CPU that is responsible for data element a(i) under data distribution. Thus work is divided among the CPUs according to their access to local data. This is the situation achieved using first-touch allocation and default scheduling, but now it is specified explicitly. The AFFINITY clause is placed on a separate line beginning with !$SGI+ so that the clause winon-SGI ll be ignored if the program is run on a platform other than SGI.
Page granularity is not considered in assigning work; the first CPU carries out iterations 1 to ceiling(n/p), the second CPU performs iterations ceiling(n/p) + 1 to 2 × ceiling(n/p), and so on. This ensures a proper balance of work among CPUs, at the possible expense of a few nonlocal memory accesses.
For the default BLOCK distribution used in this example, an AFFINITY clause assigns work to CPUs identically to the default SCHEDULE(STATIC). The AFFINITY clause, however, has advantages. First, for some complicated data distributions, there are no defined schedule types that can achieve optimal work distribution. Second, the AFFINITY clause makes the code easier to maintain, because you can change the data distribution without having to modify the Distribute directive to realign the work with the data.
The Distribute directive allows you specify a different mapping for each dimension of each distributed array. The possible mappings are these:
An asterisk, to indicate you don't specify a distribution for that dimension.
BLOCK, meaning one block of adjacent elements is assigned to each CPU.
CYCLIC, meaning sequential elements on that dimension are dealt like cards to CPUs in rotation. (In poker and bridge, cards are dealt to players in CYCLIC order.)
CYCLIC(x), meaning blocks of x elements on that dimension are dealt to CPUs in rotation. (In the game of pinochle, cards are customarily dealt CYCLIC(3).)
For example, suppose a Fortran program has a two-dimensional array A and uses p CPUs. Then !$SGI DISTRIBUTE A(*,CYCLIC) assigns columns 1, p+1, 2p+1, ... of A to the first CPU; columns 2, p+2, 2p+2, ... to the second CPU; and so on. CYCLIC(x) specifies a block-cyclic mapping, in which blocks, rather than individual elements, are cyclically assigned to CPUs, with the block size given by the compile-time expression x. For example, !$SGI DISTRIBUTE A(*,CYCLIC(2)) assigns columns 1, 2, 2p+1, 2p+2, ... to the first CPU; 3, 4, 2p+3, 2p+4, ... to the second CPU; and so on.
Combinations of the mappings on different dimensions can produce a variety of distributions, as shown in Figure 8-10, in which each color represents the intended assignment of data elements to one CPU out of a total of four CPUs.
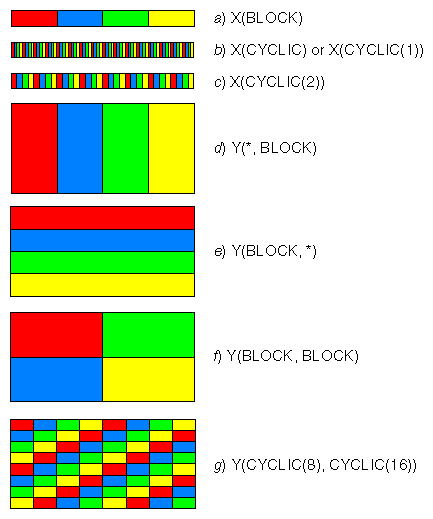
The distributions illustrated in Figure 8-10 are ideals, and do not take into consideration the restriction to whole pages. The intended distribution of data is achieved only when at least a page of data is assigned to a CPU's local memory. In the figure, mappings (a) and (d) produce the desired data distributions for arrays of moderate size, while mappings (e) and (f) require large arrays for the data placements to be near-optimal. For the cyclic mappings (b, c, and g), reshaped data distribution directives should be used to achieve the intended results (“Using Reshaped Distribution Directives”).
When an array is distributed in multiple dimensions, data is apportioned to CPUs as equally as possible across each dimension. For example, if an array has two distributed dimensions, execution on six CPUs assigns the first dimension to two CPUs and the second to three (2x 3= 6). The optional ONTO clause allows you to override this default and explicitly control the number of CPUs in each dimension. The clause ONTO(3,2) assigns three CPUs to the first dimension and two to the second. Some possible arrangements are sketched in Figure 8-11.
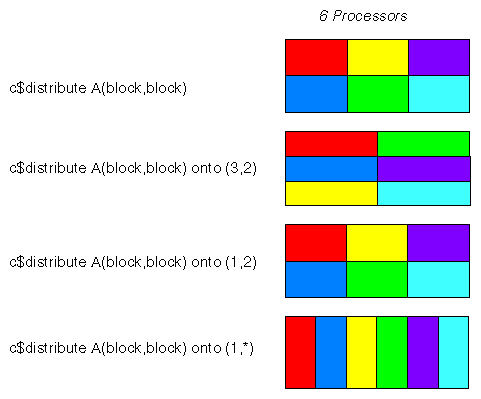
The arguments of ONTO specify the aspect ratio desired. If the available CPUs cannot exactly match the specified aspect ratio, the best approximation is used. In a six-CPU execution, ONTO(1,2) assigns two CPUs to the first dimension and three to the second. An argument of asterisk means that all remaining CPUs are to fill in that dimension: ONTO(2,*) assigns two CPUs to the first dimension and p/2 to the second.
The AFFINITY clause extends the Parallel Do directive to data distribution. Affinity has two forms. The data form, in which iterations are assigned to CPUs to match a data distribution, is used in Example 8-9. In that example, the correspondence between iterations and data distribution is quite simple. The clause, however, allows more complicated associations. One is shown in Example 8-10.
Example 8-10. Parallel Loop with Affinity in Data
parameter (n=800)
real a(2*n+3,0:n)
!$sgi distribute a(block,cyclic(1))
do j=0,n
do i=1,2*n+3
a(i,j)=1000*i+j
enddo
enddo
print *,a(5,0),a(5,1)
!$omp parallel do private(i,j), shared(a)
!$sgi+ affinity(i) = data(a(2*i+3,j))
do i=1,n
do j=1,n
a(2*i+3,j)=a(2*i+3,j-1)
enddo
enddo
print *,a(5,0),a(5,1)
end
|
Here the compiler and runtime try to execute loop iterations on i in those CPUs for which element A(2*i+3,j) is in local memory. The loop-index variable (i in the example) cannot appear in more than one dimension of the clause, and the expressions involving it are limited to the form m x i + k, where m and k are integer constants with m greater than zero.
A different kind of affinity relates iterations to threads of execution, without regard to data location. This form of the clause is shown in Example 8-11.
Example 8-11. Parallel Loop with Affinity in Threads
integer n, p, i
parameter (n = 8*1024*1024)
real a(n)
p = 1
!$ p = mp_numthreads()
!$omp parallel do private(i), shared (a,p)
!$sgi+ affinity(i) = thread(i/((n+p-1)/p))
do i = 1, n
a(i) = 0.0
enddo
print *, n, a(n)
end
|
This form of affinity has no direct relationship to data distribution. Rather, it replaces the schedule(type) clause (that is, #pragma omp for schedule(...), or !$OMP DO SCHEDULE) with a schedule based on an expression in an index variable. The code in Example 8-11 executes iteration i on the thread given by an expression, modulo the number of threads that exist. The expression may need to be evaluated in each iteration of the loop, so variables (other than the loop index) must be declared shared and not changed during the execution of the loop.
Multi-dimensional mappings (for example, mappings f and g in Figure 8-10) often benefit from parallelization over more than just the one loop to which a standard directive applies. The NEST clause permits such parallelizations. It specifies that the full set of iterations in the loop nest may be executed concurrently. Typical syntax is shown in Example 8-12.
Example 8-12. Loop Parallelized with the NEST Clause
parameter (n=1000)
real a(n,n)
!$omp parallel do private(i,j), shared(a)
!$sgi+ nest(i,j)
do j = 1, n
do i = 1, n
a(i,j) = 0.0
enddo
enddo
print *, n, a(n,n)
end
|
The normal and default parallelization of the loop in Example 8-12 would schedule the iterations of each column of the array—iterations in i for each value of j—on parallel CPUs. The work of the outer loop, which is only index incrementing, is done serially. In the example, the NEST clause specifies that all n x n iterations can be executed in parallel. To use this directive, the loops to be parallelized must be perfectly nested, that is, no code is allowed except within the innermost loop. Using NEST, when there are enough CPUs, every combination of i and j executes in parallel. In any event, when there are more than n CPUs, all will have work to do.
Example 8-13. Loop Parallelized with NEST Clause with Data Affinity
parameter (n=1000)
real a(n,n)
!$sgi distribute a(block,block)
!$omp parallel do private(i,j), shared(a)
!$sgi+ nest(i,j), affinity(i,j) = data(a(i,j))
do j = 1, n
do i = 1, n
a(i,j) = 0.0
enddo
enddo
print *, n, a(n,n)
end
|
Example 8-13 shows the combination of the NEST and AFFINITY (to data) clauses. All iterations of the loop are treated independently, but each CPU operates on its share of distributed data.
Example 8-14. Loop Parallelized with NEST, AFFINITY, and ONTO
parameter (m=2000,n=1000)
real a(m,n)
!$sgi distribute a(block,block) onto (2,1)
!$omp parallel do private(i,j), shared(a)
!$sgi+ nest(i,j), affinity(i,j) = data(a(i,j))
do j = 1, n
do i = 1, m
a(i,j) = 0.0
enddo
enddo
print *, m, n, a(m,n)
end
|
Example 8-14 shows the combination of all three clauses: NEST to parallelize all iterations; AFFINITY to causes CPUs to work on local data; and an ONTO clause to specify the aspect ratio of the parallelization. In this example, twice as many CPUs are used to parallelize the i-dimension as the j-dimension.
The Distribute directive is commonly used to specify a single arrangement of data that is constant throughout the program. In some programs you need to distribute an array differently during different phases of the program. Two directives allow you to accomplish this easily:
The Dynamic directive tells the compiler that an array may need to be redistributed, so its distribution must be calculated at runtime.
The Redistribute directive causes an array to be distributed differently.
Redistribute allows you to change the distribution defined by a Distribute directive to another mapping. However, redistribution should not be seen as a general performance tool. For example, the FFT algorithm is better with data copying, as discussed under “First-Touch Placement with Multiple Data Distributions”.
Despite its name, the Distribute_Reshape directive does not perform redistribution. It tells the compiler that it can reshape the distributed data into nonstandard layouts.
The block and cyclic mappings are well-suited for regular data structures such as numeric arrays. The Page_Place directive can be used to distribute nonrectangular data. This directive allows you to assign ranges of whole pages to precisely the CPUs you want. The penalty is that you have to understand the memory layout of your data in terms of virtual pages.
The Page_Place directive, unlike most other directives, is an executable statement (not an instruction to the compiler on how to treat the program). It takes three arguments:
The name of a variable, whose first address is the start of the area to be placed
The size of the area to be placed
The number of the CPU, where the first CPU being used for this program is 0
Because the directive is executable, you can use it to place dynamically allocated data, and you can use it to move data from one memory to another. (The Distribute directive is not an executable statement, so it can reference only the data that is statically declared in the code.) In Example 8-15, the Page_Place directive is used to create a block mapping of the array a onto p CPUs.
Example 8-15. Fortran Code for Explicit Page Placement
integer n, p, npp, i
parameter (n = 8*1024*1024)
real A(n)
p = 1
!$ p = mp_numthreads()
c-----distribute A using a block mapping
npp = (n + p-1)/p ! number of elements per CPU
!$omp parallel do private(i), shared(a,npp)
do i = 0, p-1
!$sgi page_place (a(1 + i*npp), npp*4, i)
enddo
end
|
If the array has not previously been distributed via first-touch or a Distribute directive, the Page_Place directive establishes the initial placement and incurs no time cost. If the data have already been placed, execution of the directive redistributes the data, causing the pages to migrate from their initial locations to those specified by the directive. This data movement requires some time to complete. (It may or may not be faster than data copying.) If your intention is only to set the initial placement, rather than redistributing the pages, make the directive the first executable statement that acts on the specified data, and don't use other distribution directives on the same variables.
When your intention is to redistribute the data, Page_Place will accomplish this. But for regularly distributed data, the Redistribute directive also works and is more convenient.
The regular data distribution directives provide an easy way to specify the desired data distribution, but they have a limitation: the distributions operate only on whole virtual pages. This limits their use with small arrays and cyclic distributions. For these situations another directive is provided, Distribute_Reshape.
The arguments to Distribute_Reshape are the same as those of the Distribute directive, and it has the same basic purpose. However, it also promises the compiler that the program makes no assumptions about the layout of data in memory; for example, that it does not assume that array elements with consecutive indexes are located in consecutive virtual addresses. With this assurance, the compiler can distribute data in ways that are not possible when it has to preserve the standard assumptions about the layout of data in memory. For example, when the size of a distributed block is less than a page, the compiler can pad each block of elements to a full page and distribute that. The implications of this are best seen through an example.
Example 8-16 shows the declaration of a three-dimensional array, a, and distributes its xy-planes to CPU local memory using a reshaped cyclic mapping.
Example 8-16. Declarations Using the Distribute_Reshape Directive
integer i, j, k
integer n1, n2, n3
parameter (n1=200, n2=150, n3=150)
real a(n1, n2, n3)
!$sgi distribute_reshape a(*,*,cyclic)
real sum
|
The reshaped data distribution means that each CPU is assigned ceiling(n3/p) xy-planes in a cyclic order. The x- and y-dimensions are not distributed, so each plane consumes n1 × n2 consecutive data locations in normal Fortran storage order (that is, the first n1 elements are down the first column, the next n1 elements are down the second column, and so on), and these are in the expected, consecutive, virtual storage locations.
However, the Distribute_Reshape directive promises the compiler that the program makes no assumptions about the location of one z-plane compared with another. That is, even though standard Fortran storage order specifies that a(1,1,2) is stored n1 x n2 elements after a(1,1,1), this is no longer guaranteed when the reshape directive is used. The compiler is allowed to insert “holes,” or padding space, between these planes as needed in order to perform the exact, cyclic distribution requested. The situation for four CPUs is reflected in Figure 8-12.
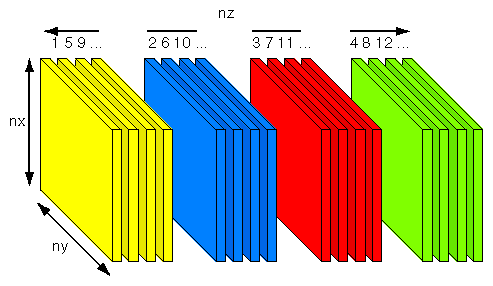
In Example 8-17, the BLAS-1 routines dasum and dscal from the CHALLENGE complib are applied in parallel to pencils of data in each of the three dimensions. The library routine dasum knows nothing about reshaped arrays. On the contrary, it assumes that it is working on a vector of consecutive reals. Its first argument tells it how many elements to sum; the second is the address at which to start summing; and the third argument is the stride, that is, the number of storage elements by which to increment the address to get to the next value included in the sum.
Example 8-17. Valid and Invalid Use of Reshaped Array
integer i, j, k
integer n1, n2, n3
parameter (n1=200, n2=150, n3=150)
real*8 a(n1, n2, n3)
!$sgi distribute_reshape a(*,*,cyclic)
real*8 sum, dasum
do k = 1, n3
do j = 1, n2
do i = 1, n1
a(i,j,k)=i+j+k
enddo
enddo
enddo
!$omp parallel do private(k,j,sum), shared(a)
do k = 1, n3
do j = 1, n2
sum = dasum(n1, a(1,j,k), 1)
sum = 1.d0/sum
call dscal(n1, sum, a(1,j,k), 1)
enddo
enddo
!$omp parallel do private(k,i,sum), shared(a)
do k = 1, n3
do i = 1, n1
sum = dasum(n2, a(i,1,k), n1)
sum = 1.d0/sum
call dscal(n2, sum, a(i,1,k), n1)
enddo
enddo
!$omp parallel do private(j,i,sum), shared(a)
do j = 1, n2
do i = 1, n1
sum = dasum(n3, a(i,j,1), n1*n2)
sum = 1.d0/sum
call dscal(n3, sum, a(i,j,1), n1*n2)
enddo
enddo
print *, a(1,1,1), a(n1,n2,n3)
end
|
In the first loop in Example 8-17, values are summed down the x-dimension. These are adjacent to one another in memory, so the stride is 1. In the second loop, values are summed in the y-dimension. Each y-value is one column of length n1 away from its predecessor, so these have a stride of n1. The x- and y-dimensions are not distributed, so these values are stored at the indicated strides, and the subroutine calls generate the expected results.
This is not the case for the z-dimension . You can make no assumptions about the storage layout in a distributed dimension. The stride argument of n1 × n2 used in the third loop, while logically correct, cannot be assumed to describe the storage addressing. Depending on the size and alignment of the array, the compiler may have inserted padding between elements to achieve perfect distribution. This third loop generates incorrect results when run in parallel. The sasum routine adds the value of some padding in place of some of the data elements. (If it is compiled without the -mp flag so that the directives are ignored, it does generate correct results.)
The problem is the result of using a library routine that makes assumptions about the storage layout. To correct this you have to remove those assumptions. One solution is to use standard array indexing instead of the library routine. Example 8-18 replaces the library call with code that does not assume a storage layout.
Example 8-18. Corrected Use of Reshaped Array
! replace third !$omp parallel do in Example 8-17 with this code:
!$omp parallel do private(j,i,k,sum), shared(a)
do j = 1, n2
do i = 1, n1
sum = 0.0
do k = 1, n3
sum = sum + abs(a(i,j,k))
enddo
do k = 1, n3
a(i,j,k) = a(i,j,k)/sum
enddo
enddo
enddo
|
A solution that allows you to employ library routines is to use copying. Example 8-19 shows this approach.
Example 8-19. Gathering Reshaped Data with Copying
! additional type statement needed
real*8 tmp(n3)
. . .
! replace third !$omp parallel do in Example 8-17 with this code:
!$omp parallel do private(j,i,k,sum,tmp), shared(a)
do j = 1, n2
do i = 1, n1
do k = 1, n3
tmp(k) = a(i,j,k)
enddo
sum = dasum(n3, tmp, 1)
sum = 1.d0/sum
call dscal(n3, sum, tmp, 1)
do k = 1, n3
a(i,j,k) = tmp(k)
enddo
enddo
enddo
|
The copy loop accesses array elements by their indexes, so it does not make assumptions about the storage layout—the compiler generates code that allows for any reshaping it has done. When a local scratch array is used, the stride is known, so dasum may be used safely. Note, though, that the copy step in Example 8-19 accesses memory in long strides. The version in Example 8-20 involves more code and scratch space, but it makes much more effective use of cache lines.
Example 8-20. Gathering Reshaped Data with Cache-Friendly Copying
! additional type statement needed
real*8 tmp(n1 ,n3)
. . .
! replace third !$omp parallel do in Example 8-17 with this code:
!$omp parallel do private(j,i,k,sum,tmp), shared(a)
do j = 1, n2
do k = 1, n3
do i = 1, n1
tmp(i,k) = a(i,j,k)
enddo
enddo
do i = 1, n1
sum = dasum(n3, tmp(i,1), n1)
sum = 1.d0/sum
call dscal(n3, sum, tmp(i,1), n1)
enddo
do k = 1, n3
do i = 1, n1
a(i,j,k) = tmp(i,k)
enddo
enddo
enddo
|
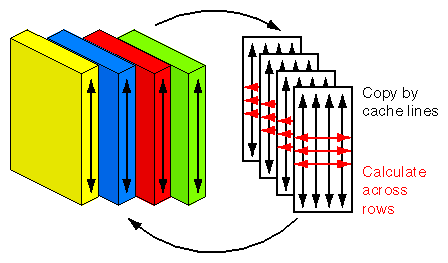
Distribute_Reshape, although implemented for shared memory programs, is essentially a distributed memory construct. You use it to partition data structures the way you would on a distributed-memory computer. In a true distributed-memory system, once the data structures are partitioned, accessing them in the distributed dimension is restricted. In considering whether you can safely perform an operation on a reshaped array, ask if it is something that wouldn't be allowed on a distributed-memory computer. However, if the operation makes no assumptions about data layout, SN0 shared memory allows you to conveniently perform many operations that would be much more difficult to implement on a distributed memory computer.
The purpose of the Distribute_Reshape directive is to achieve the desired data distribution without page-granularity limitations. You can accomplish the same thing through the use of dynamic memory allocation and pointers. The method follows this outline:
Allocate enough space for each CPU so that it doesn't need to share a page with another CPU.
Pack the pieces each CPU is responsible for into its pages of memory.
Use first-touch allocation, or Page_Place, to make sure each CPU's pages are stored locally.
Set up an array of pointers so the individual pieces can be accessed conveniently.
However, this approach can easily add great complexity to what ought to be a readable algorithm. As with most optimizations, it is usually better to leave the source code simple and let the compiler do the hard work behind the scenes.
When you use the Distribute_Reshape directive, there are some restrictions you should remember:
The distribution of a reshaped array cannot be changed dynamically (that is, there is no redistribute_reshape directive).
Static-initialized data cannot be reshaped.
Arrays that are explicitly allocated through alloc() or malloc() and accessed though pointers cannot be reshaped.
An array that is equivalenced to another array cannot be reshaped.
I/O for a reshaped array cannot be mixed with namelist I/O or a function call in the same I/O statement.
A COMMON block containing a reshaped array cannot be linked -Xlocal.
In addition, some care must be used in passing reshaped arrays to subroutines. As long as you pass the entire array, and the declared size of the array in the subroutine matches the size of array that was passed to it, problems are unlikely. Example 8-21 illustrates this.
Example 8-21. Reshaped Array as Actual Parameter—Valid
real a(n1,n2)
!$sgi distribute_reshape a(block,block)
call sub(a,n1,n2)
. . .
subroutine sub(a,n1,n2)
real a(n1,n2)
. . .
|
In Example 8-22, the formal parameter is declared differently from the actual reshaped array. Treating the two-dimensional array as a vector amounts to an assumption that consecutive elements are adjacent in memory, a false assumption. The compiler will catch this change of dimensionality and issue a warning message if you compile with the -mp option.
Example 8-22. Reshaped Array as Actual Parameter—Invalid
real a(n1,n2)
!$sgi distribute_reshape a(block,block)
call sub(a,n1*n2)
. . .
subroutine sub(a,n)
real a(n)
. . .
|
Inside a subroutine, you don't need to declare how an array has been distributed. In fact, the subroutine is more general if you do not declare the distribution. The compiler will generate versions of the subroutine necessary to handle all distributions that are passed to it. Example 8-23 shows a subroutine receiving two arrays that are reshaped differently.
Example 8-23. Differently Reshaped Arrays as Actual Parameters
real a(n1,n2)
!$sgi distribute_reshape a(block,block)
real b(n1,n2)
!$sgi distribute_reshape b(cyclic,cyclic)
call sub(a,n1,n2)
call sub(b,n1,n2)
. . .
subroutine sub(a,n1,n2)
real a(n1,n2)
. . .
|
The compiler actually generates code to handle each distribution passed to the subroutine. As long as the data calculations are efficient for both distributions, this will achieve good performance. If a particular algorithm works only for a specific data distribution, you can declare the required distribution inside the subroutine by using a Distribute_Reshape directive there. Then, calls to the subroutine that pass a mismatched distribution cause compile- or link-time errors.
Most errors in accessing reshaped arrays are caught at compile time or link time. However, some errors, such as passing a portion of a reshaped array that spans a distributed dimension, can be caught only at run time. You can instruct the compiler to do runtime checks for these with the -MP:check_reshape=on flag. You should use this flag during the development and debugging of programs which use reshaped arrays. In addition, the Fortran manuals listed in “Compiler Manuals” have more information about reshaped arrays.
Sometimes it is useful to check how data have been distributed. You can do this on a program basis with an environment variable and dynamically with a function call.
If you are using the data distribution directives, you can set the environment variable _DSM_VERBOSE. When it is set, the program will print out messages at run time that tell you whether the distribution directives are being used, which physical CPUs the threads are running on, and what the page sizes are. A report might look like Example 8-24.
Example 8-24. Typical Output of _DSM_VERBOSE
% setenv _DSM_VERBOSE
% a.out
[ 0]: 16 CPUs, using 4 threads.
1 CPUs per memory
Migration: OFF
MACHINE: IP27 --- is NUMA ---
MACHINE: IP27 --- is NUMA ---
Created 4 MLDs
Created and placed MLD-set. Topology-free, Advisory.
MLD attachments are:
MLD 0. Node /hw/module/3/slot/n4/node
MLD 1. Node /hw/module/3/slot/n3/node
MLD 2. Node /hw/module/3/slot/n1/node
MLD 3. Node /hw/module/3/slot/n2/node
[ 0]: process_mldlink: thread 0 (pid 3832) to memory 0. -advisory-.
Pagesize: stack 16384 data 16384 text 16384 (bytes)
--- finished MLD initialization ---
. . .
[ 0]: process_mldlink: thread 1 (pid 3797) to memory 1. -advisory-.
[ 0]: process_mldlink: thread 2 (pid 3828) to memory 2. -advisory-.
[ 0]: process_mldlink: thread 3 (pid 3843) to memory 3. -advisory-.
[ 0]: process_mldlink: thread 0 (pid 3832) to memory 0. -advisory-.
|
These messages are useful in verifying that the requested data placements are actually being performed.
The utility dplace (see “Non-MP Library Programs and Dplace”) disables the data distribution directives. It should not normally be used to run MP library programs. If you do use it, however, it displays messages reminding you that “DSM” is disabled.
You can obtain information about data placement within the program with the dsm_home_threadnum() intrinsic. It takes an address as an argument, and returns the number of the CPU in whose local memory the page containing that address is stored. It is used in Fortran as follows:
integer dsm_home_threadnum numthread = dsm_home_threadnum(array(i)) |
Two CPUs are connected to each node and they share the same memory, so the function returns the lowest CPU number of the two running on the node with the data.
The numbering of CPUs is relative to the program. You can also determine which absolute physical node a page of memory is stored in. (Note, though, that this number will typically change from run to run.) The information is gotten via the syssgi() system call using the SGI_PHYSP command (see the syssgi(2) man page). The routine va2pa() translates a virtual address to a physical address using this system call (see Example C-9). You can translate a physical page address to a node number with the following macro:
#define ADDR2NODE(A) ((int) (va2pa(A) >> 32)) |
Note that the node number is generally half the lowest numbered CPU on the node, so if you would prefer to use CPU numbers, multiply the return value by two.
To explore this information, a test program was written that allocated two vectors, a and b, of size 256 KB, initialized them sequentially, and then printed out the locations of their pages. The default first-touch policy for a run using five CPUs resulted in the page placements shown in Example 8-25.
Example 8-25. Test Placement Display from First-Touch Allocation
Distribution for array "a" address byte index thread proc -------------------------------------- 0xfffffb4760 0x 0 0 12 0xfffffb8000 0x 38a0 0 12 0xfffffbc000 0x 78a0 0 12 0xfffffc0000 0x b8a0 0 12 0xfffffc4000 0x f8a0 0 12 0xfffffc8000 0x 138a0 0 12 0xfffffcc000 0x 178a0 0 12 0xfffffd0000 0x 1b8a0 0 12 0xfffffd4000 0x 1f8a0 0 12 0xfffffd8000 0x 238a0 0 12 0xfffffdc000 0x 278a0 0 12 0xfffffe0000 0x 2b8a0 0 12 0xfffffe4000 0x 2f8a0 0 12 0xfffffe8000 0x 338a0 0 12 0xfffffec000 0x 378a0 0 12 0xffffff0000 0x 3b8a0 0 12 0xffffff4000 0x 3f8a0 0 12 Distribution for array "b" address byte index thread proc -------------------------------------- 0xfffff6e0f8 0x 0 0 12 0xfffff70000 0x 1f08 0 12 0xfffff74000 0x 5f08 0 12 0xfffff78000 0x 9f08 0 12 0xfffff7c000 0x df08 0 12 0xfffff80000 0x 11f08 0 12 0xfffff84000 0x 15f08 0 12 0xfffff88000 0x 19f08 0 12 0xfffff8c000 0x 1df08 0 12 0xfffff90000 0x 21f08 0 12 0xfffff94000 0x 25f08 0 12 0xfffff98000 0x 29f08 0 12 0xfffff9c000 0x 2df08 0 12 0xfffffa0000 0x 31f08 0 12 0xfffffa4000 0x 35f08 0 12 0xfffffa8000 0x 39f08 0 12 0xfffffac000 0x 3df08 0 12 |
The sequential initialization combined with the first-touch policy caused all the pages to be placed in the memory of the first thread which, in this run, was CPU 12, or node 6.
Example 8-26 shows the results from the same code after setting the environment variable _DSM_ROUND_ROBIN to use a round-robin page placement.
Example 8-26. Test Placement Display from Round-Robin Placement
Distribution for array "a" address byte index thread proc -------------------------------------- 0xfffffb4750 0x 0 2 2 0xfffffb8000 0x 38b0 0 0 0xfffffbc000 0x 78b0 4 4 0xfffffc0000 0x b8b0 2 2 0xfffffc4000 0x f8b0 0 0 0xfffffc8000 0x 138b0 4 4 0xfffffcc000 0x 178b0 2 2 0xfffffd0000 0x 1b8b0 0 0 0xfffffd4000 0x 1f8b0 4 4 0xfffffd8000 0x 238b0 2 2 0xfffffdc000 0x 278b0 0 0 0xfffffe0000 0x 2b8b0 4 4 0xfffffe4000 0x 2f8b0 2 2 0xfffffe8000 0x 338b0 0 0 0xfffffec000 0x 378b0 4 4 0xffffff0000 0x 3b8b0 2 2 0xffffff4000 0x 3f8b0 0 0 Distribution for array "b" address byte index thread proc -------------------------------------- 0xfffff6e0e8 0x 0 0 0 0xfffff70000 0x 1f18 4 4 0xfffff74000 0x 5f18 2 2 0xfffff78000 0x 9f18 0 0 0xfffff7c000 0x df18 4 4 0xfffff80000 0x 11f18 2 2 0xfffff84000 0x 15f18 0 0 0xfffff88000 0x 19f18 4 4 0xfffff8c000 0x 1df18 2 2 0xfffff90000 0x 21f18 0 0 0xfffff94000 0x 25f18 4 4 0xfffff98000 0x 29f18 2 2 0xfffff9c000 0x 2df18 0 0 0xfffffa0000 0x 31f18 4 4 0xfffffa4000 0x 35f18 2 2 0xfffffa8000 0x 39f18 0 0 0xfffffac000 0x 3df18 4 4 |
Round-robin placement really did spread the data over all three nodes used by this 5-CPU run.
Programs that do not use the MP library include message passing programs employing MPI, PVM and other libraries, as well as “roll your own parallelism” implemented via fork() or sproc() (see “Explicit Models of Parallel Computation”). If such programs have been properly parallelized, but do not scale as expected on SN0, they may require data placement tuning.
If you are developing a new parallel program or are willing to modify the source of your existing programs, you can ensure a good data placement by adhering to the following programming practices which take advantage of the default first-touch data placement policy:
In a program that starts multiple processes using fork(), each process should allocate and initialize its own memory areas. Then the memory used by a process resides in the node where the process runs.
In a program that starts multiple processes using sproc(), do not allocate all memory prior to creating child processes. In the parent process, allocate only memory used by the parent process and memory that is global to all processes. This memory will be located in the node where the parent process runs.
Each child process should allocate any memory areas that it uses exclusively. Those areas will be located in the node where that process runs.
In general, in any program composed of interacting, independent threads, each thread should be the first to touch any memory used exclusively by that thread. This applies to programs in which a thread is a process, or a POSIX thread, as well as to programs based on MPI and PVM.
For all these programs, data placement can be measure or tuned with the utility dplace, which allows you to:
Change the page size used for text, stack, or data.
Enable dynamic page migration.
Specify the topology used by the threads of a parallel program.
Indicate resource affinities.
Assign memory ranges to particular nodes.
For the syntax of dplace, refer to the dplace(1) man page. Some dplace commands use a placement file, whose syntax is documented in dplace(5) . If you are not familiar with dplace, it would be a good idea to skim these two man pages now. In addition, there is a subroutine library interface, documented in the dplace(3) man page, which not only allows you to accomplish all the same things from within a program, but also allows dynamic control over some of the data placement choices.
Although dplace can be used to adjust policies and topology for any program, in practice it should not be used with MP library programs because it disables the data placement specifications made via the MP library compiler directives. For these programs, use the MP library environment variables instead of dplace.
In “Using Larger Page Sizes to Reduce TLB Misses” in Chapter 6 we discussed using dplace to change the page size:
% dplace -data_pagesize 64k -stack_pagesize 64k program arguments... |
This command runs the specified program after increasing the size of two of the three types of pages—data and stack—from the default 16 KB to 64 KB. The text page size is unchanged. This technique causes the TLB to cover a wider range of virtual data addresses, so reducing TLB thrashing.
In general, TLB thrashing only occurs for pages that store data structures. Dynamically allocated memory space, and global variables such as Fortran common blocks, are stored in data segments; their page size is controlled by -data_pagesize. Variables that are local to subroutines are allocated on the stack, so it can also be useful to change -stack_pagesize when trying to fix TLB thrashing problems. Increasing the -text_pagesize is not generally of benefit for scientific programs, in which time is usually spent in the execution of tight loops over arrays.
There are some restrictions on page sizes. First, the only valid page sizes are 16 KB, 64 KB, 256 KB, 1 MB, 4 MB, and 16 MB. Second, the percentage of system memory allocated to the various possible page sizes is a system configuration parameter that the system administrator must specify. If the system has not been configured to allocate 1 MB pages, it has no effect to request this page size. The page size percentages are set with the systune command (see the systune(1) man page, and the System Configuration manual listed under “Software Tool Manuals”).
The concept of dynamic page migration is covered under “Dynamic Page Migration” in Chapter 2. Enabling migration tells the operating system to move pages of memory to the nodes that access them most frequently, so a poor initial placement can be corrected. Recall that page placement is not an issue for single-CPU jobs; migration is only a consideration for parallel programs. Furthermore, migration is only a potential benefit to programs employing a shared memory model; MPI, PVM, and other message-passing programs control data layout explicitly, so automated control of data placement would only get in their way.
The IRIX automatic page migration facility is disabled by default, because page migration is an expensive operation that affects overall system performance. The system administrator can temporarily enable page migration for all programs using the sn command, or can enable it permanently by using systune. (For more information, see the sn(1) and systune(1) man pages and the System Configuration manual listed under “Software Tool Manuals”.)
You can decide to use dynamic page migration for a specific program in one of two ways. If the program uses the MP library, use its environment variables as discussed under “Trying Dynamic Page Migration”. For other programs, you enable migration using dplace:
% dplace -migration threshold program arguments... |
The threshold argument is an integer between 0 and 100. A threshold value 0 is special; it turns migration off. Nonzero values adjust the sensitivity of migration, which is based on hardware-maintained access counters that are associated with every 4 KB block of memory. (See the refcnt(5) man page for a description of these counters and of how the IRIX kernel extends them to virtual pages.)
When migration is enabled, the IRIX kernel surveys the counters periodically. Migration is triggered when the difference between local accesses to a page, and accesses from any one other node, exceeds threshold% of the maximum counter value.
When you enable migration, use a conservative threshold, say 90 (which specifies that the count of remote accesses exceeds the count of local accesses by 90% of the counter value). The point is to permit enough migration to correct poor initial data placement, but not to cause so much migration that the expense of moving pages is more than the cost of accessing them remotely. You can experiment with smaller values, but keep in mind that smaller values could keep a page in constant motion. Suppose that a page is being used from three different nodes equally. Moving the page from one of the three nodes to another will not change the distribution of counts.
The topology of a program is the shape of the connections between the nodes where the parallel threads of the program are executed. When executing a parallel program, the operating system tries to arrange it so that the processes making up the parallel program run on nearby nodes to minimize the access time to shared data. “Nearby” means minimizing a simple distance metric, the number of router hops needed to get from one node to another. For an 8-node (16-CPU) system, the distance between any two nodes using this metric is as shown in Table 8-2.
Table 8-2. Distance in Router Hops Between Any Nodes in an 8-Node System
Node | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
0 | 0 | 1 | 2 | 2 | 2 | 2 | 2 | 2 |
1 | 1 | 0 | 2 | 2 | 2 | 2 | 2 | 2 |
2 | 2 | 2 | 0 | 1 | 2 | 2 | 2 | 2 |
2 | 2 | 2 | 1 | 0 | 2 | 2 | 2 | 2 |
4 | 2 | 2 | 2 | 2 | 0 | 1 | 2 | 2 |
5 | 2 | 2 | 2 | 2 | 1 | 0 | 2 | 2 |
6 | 2 | 2 | 2 | 2 | 2 | 2 | 0 | 1 |
7 | 2 | 2 | 2 | 2 | 2 | 2 | 1 | 0 |
Thus, if the first two threads of a 6-way parallel job are placed on node 3, the second and third threads will be placed on node 2 because, at a distance of only 1, it is the closest node. The final two threads may be placed on any of nodes 0, 1, 4, 5, 6, or 7 because they are all a distance of 2 away.
For most applications, this “cluster” topology is perfect, and you need not worry further about topology issues. For those cases in which it may be of benefit, however, dplace does give you a way to override the default and specify other topologies. This is done through a placement file, a text file indicating how many nodes should be used to run a program, what topology should be used, and where the threads should run.
Note: In a dplace placement file, a node is called a “memory.” You specify a topology of memories, and a specify on which memory a thread should run.
Figure 8-14 shows a simple placement file and its effect on the program:
With this placement file, two memories are used to run this two-thread program. Without a placement file, IRIX would try to place a two-thread program on a single memory, because two CPUs are associated with each memory, and only one CPU is needed per thread. In addition, the memories are laid out in a cube topology rather than the default cluster topology. For this simple case of two memories, there is no difference; but if more memories had been requested, the cube topology would ensure that memories which should be hypercube neighbors end up adjacent to each other in the SN0 system. Finally, threads are placed onto the memories in the reverse of the typical order, that is, thread 0 is run on memory 1 and thread 1 is run on memory 0.
The syntax of placement files is detailed in the dplace(5) man page. The key statements in it are the memories, threads, run, distribute, and place statements.
The placement file shown in Figure 8-14 has one limitation: it is not scalable. That is, if you want to change the number of threads, you need to change the placement file. A placement file can refer to environment variables, making it scalable. A file of this type is shown in Example 8-27.
Example 8-27. Scalable Placement File
# scalable placement_file memories $NP in topology none # set up memories which are close threads $NP # number of threads # run the last thread on the first memory etc. distribute threads $NP-1:0:-1 across memories |
Instead of writing the number of threads into the file, the environment variable $NP is used. (There is no significance to the name; any variable could be used.) When the placement file is read, the reference to the environment variable is replaced by its value taken from the shell. Thus, if NP is set to 2, the first two statements have the same effect as the version in Figure 8-14. To make the last two statements scalable, they are replaced with a distribute statement. This one statement specifies a mapping of all threads to all memories. Its use is covered under “Assigning Threads to Memories”.
You can use simple arithmetic on environment variables in placement files. A scalable placement file that uses a more conventional placement of two threads per memory is shown in Example 8-28. This example uses the MP_SET_NUMTHREADS environment variable used by the MP library (however, it is not recommended to apply dplace to MP library programs). A comparable variable is PT_ITC, the number of processes used by the POSIX Threads library to run a pthreaded program.
Example 8-28. Scalable Placement File for Two Threads Per Memory
# Standard 2 thread per memory scalable placement_file memories ($MP_SET_NUMTHREADS + 1)/2 in topology none threads $MP_SET_NUMTHREADS distribute threads across memories |
The memories statement specifies the number of memories (SN0 nodes) to be allocated to the program and, optionally, their topology. The topologies supported are these:
cube, the default value, specifies a hypercube, which is a proper subset of the SN0 topology.
none, which is the same as a cluster topology: any arrangement that minimizes router hops between nodes.
physical, used when placing nodes near to hardware, discussed in “Indicating Resource Affinity”.
The number of nodes in a hypercube is a power of two. As a result, cube topology can have strange side effects when used on machines that do not have a power of two number of nodes. In general, use the none (cluster) topology.
The memories are identified by number, starting from 0, in the order that they are allocated. Using cube or cluster topology, there is no way to relate a memory number to a specific SN0 node; memory 0 could be identified with any node in the system on any run of the program.
The threads statement specifies the number of IRIX processes the program will use. The MP library uses IRIX processes as does MPI, PVM, and standard UNIX software. POSIX threads programs are implemented using some number of processes; the number is available within the program using the pthread_get_concurrency() function.
The threads statement does not create the processes; creation happens as a result of the program's own actions. The threads statement tells dplace in advance how many threads the program will create. Threads are identified by number, starting from 0, in the sequence in which the program creates them. Thus the first process, the parent process of the program, is thread 0 to dplace.
There are two statements used to assign threads to memories, run and distribute. The run statement tells dplace to assign a specific thread, by number, to a specific memory by number. Optionally, it can assign the thread to a specific CPU in that node, although there is no particular advantage in doing so. The run statement deals with only one thread, so a placement file that uses it cannot be scalable.
The distribute statement specifies a mapping of all threads to all memories. In Example 8-27, a distribute statement is used to map threads in reverse order to memories, as follows:
distribute threads $NP-1:0:-1 across memories |
The three-part expression, reminiscent of a Fortran DO loop, specifies the threads in the program as first:last:stride. In this example, the last thread ($NP-1) is mapped to memory 0, the next-to-last thread is mapped to memory 1, and so on.
This example maps threads to memories in reverse order. If the normal order were desired, the statement could be written in any of the ways shown in Example 8-29.
Example 8-29. Various Ways of Distributing Threads to Memories
# Explicitly indicate order of threads distribute threads 0:$NP-1:1 across memories # No first:last:stride means 0:last:1 distribute threads across memories # The stride can be omitted when it is 1 distribute threads 0:$NP-1 across memories # first:last:stride notation applies to memories too distribute threads across memories 0:$NP-1:1 distribute threads $NP-1:0:-1 across memories $NP-1:0:-1 |
The distribute statement also supports a clause telling how threads are assigned to memories, when there are more threads than memories. The clause can be either block or cyclic. In a block mapping with a block size of two, the first two threads are assigned to the first memory, the second two to the second, and so on. In a cyclic mapping, threads are dealt to memories as you deal a deck of cards. The default is to use a block mapping, and the default block size is ceiling (number of threads ÷ number of memories); that is, 2 if there are twice as many threads as memories, and 1 if the number of threads and memories are equal.
The hardware characteristics of an SN0 system are maintained in the hardware graph, a simulated filesystem mounted at /hw. All real hardware devices and many symbolic pseudo-devices appear in the /hw filesystem. For example, all the nodes in a system can be listed with the following command:
[farewell 1] find /hw -name node -print /hw/module/5/slot/n1/node /hw/module/5/slot/n2/node /hw/module/5/slot/n3/node /hw/module/5/slot/n4/node /hw/module/6/slot/n1/node /hw/module/6/slot/n2/node /hw/module/6/slot/n3/node /hw/module/6/slot/n4/node /hw/module/7/slot/n1/node /hw/module/7/slot/n2/node /hw/module/7/slot/n3/node /hw/module/7/slot/n4/node /hw/module/8/slot/n1/node /hw/module/8/slot/n2/node /hw/module/8/slot/n3/node /hw/module/8/slot/n4/node |
This is an Origin 2000 system with four modules, 16 nodes, and 32 CPUs.
You can refer to entries in the hardware graph in order to name resources that you want your program to run near. This is done by adding a near clause to the memories statement in the placement file. For example, if InfiniteReality hardware is installed, it shows up in the hardware graph as follows:
% find /hw -name kona -print /hw/module/1/slot/io5/xwidget/kona |
In this case, it is in the fifth I/O slot of module 1. You may then indicate that you want your program run near this hardware device by using a line such as the following:
memories 3 in topology none near /hw/module/1/slot/io5/xwidget/kona |
You can also use the hardware graph entries and the physical topology to run the program on specific nodes:
memories 3 in topology physical near /hw/module/2/slot/n1/node
/hw/module/1/slot/n2/node
/hw/module/3/slot/n3/node
|
This line causes the program to be run on node 1 of module 2, node 2 of module 1, and node 3 of module 3. In general, though, it is best to let the operating system pick which nodes to run on, because users' jobs are likely to collide with each other if the physical topology is used.
You can use a placement file to place specific ranges of virtual memory on a particular node. This is done with a place statement. For example, a placement file can contain the lines
place range 0xfffbffc000 to 0xfffc000000 on memory 0 place range 0xfffd2e4000 to 0xfffda68000 on memory 1 |
Generally, placing address ranges is practical only when used in conjunction with dprof (see “Applying dprof” in Chapter 4). This utility profiles the memory accesses in a program. Given the -pout option, it writes place statements like those shown above to an output file. You can insert these address placement lines into a placement file for the program. Address ranges are likely to change after recompilation, so this use of a placement file is effective only for very fine tuning of an existing binary. Generally it is better to rely on memory placement policies, or source directives, to place memory.
In addition to the capabilities described above, dplace can also dynamically move data and threads during program execution. These tasks are accomplished with migrate and move statements (refer again to the dplace(5) man page). These statements may be included in a placement file, but they make little sense there. They are meant to be issued at strategic points during the execution of a program. This is done via the function/subroutine interface described in the dplace(3) man page.
The subroutine interface is simple; it includes only two functions:
dplace_file() takes as its argument the name of a placement file. It opens, reads, and executes the file, performing multiple statements.
dplace_line() takes a string containing a single dplace statement.
Example 8-30 contains some sample code showing how the dynamic specifications can be issued via the library calls.
Example 8-30. Calling dplace Dynamically from Fortran
CHARACTER*128 s
np = mp_numthreads()
WRITE(s,*) 'memories ',np,' in topology cluster'
CALL dplace_line(s)
WRITE(s,*) 'threads ',np
CALL dplace_line(s)
DO i=0, np-1
WRITE(s,*) 'run thread',i,' on memory',i
CALL dplace_line(s)
head = %loc( a( 1+i*(n/np) ) )
tail = %loc( a( (i+1)*(n/np) ) )
WRITE(s,*) 'place range',head,' to',tail,' on memory',i
CALL dplace_line(s)
END DO
DO i=0, np-1
WRITE(s,*) 'move thread',i,' to memory',np-1-i
CALL dplace_line(s)
END DO
DO i=0, np-1
head = %loc( a( 1+i*(n/np) ) )
tail = %loc( a( (i+1)*(n/np) ) )
WRITE(s,*) 'migrate range',head,' to',tail,' to memory',np-1-i
CALL dplace_line(s)
END DO
|
The library is linked in with the flag -ldplace -lmp. The example code calls on dplace_line() multiple times to execute the following statements:
memories p and threads p, taking the actual number of processes from the mp_numthreads function of the MP library (see the mp(3F) man page). Note that this code requests a memory (node) per process, which is usually unnecessary.
A run statement for each thread, placing it on the memory of the same number.
A series of move statements to reverse the order of threads on memories.
A series of migrate statements to migrate blocks of array a to the memories of different threads.
The MPI library (version 3.1 or higher) is aware of, and compatible with, the MP library. As a result, you rarely need to use dplace with MPI programs. However, in the rare cases when you do want this combination, the key to success is to apply the mpirun command to dplace, not the reverse. In addition, you must set an environment variable, MPI_DSM_OFF, as in the following two-line example:
% setenv MPI_DSM_OFF % mpirun -np 4 dplace -place pfile a.out |
This example starts copies of dplace on four CPUs. Each of them, in turn, invokes the program a.out, applying the placement file pfile.
When using a tool such as dplace that produces output on the standard output or standard error streams, it can be difficult to capture the tool's output. The correct approach, as shown in Example 8-31, is to write a small script to do the redirection, and to use mpirun to launch the script.
Example 8-31. Using a Script to Capture Redirected Output from an MPI Job
> cat myscript #!/bin/sh setenv MPI_DSM_OFF dplace -verbose a.out 2> outfile > mpirun -np 4 myscript hello world from process 0 hello world from process 1 hello world from process 2 hello world from process 3 > cat outfile there are now 1 threads Setting up policies and initial thread. Migration is off. Data placement policy is PlacementDefault. Creating data PM. Data pagesize is 16k. Setting data PM. Creating stack PM. Stack pagesize is 16k. Stack placement policy is PlacementDefault. Setting stack PM. there are now 2 threads there are now 3 threads there are now 4 threads there are now 5 threads |
The MP library and dplace together provide two advanced features that can be of use for realtime programs:
Running just one process per node
Locking processes to CPUs
Neither of these features is useful in the typical multi-user environment in which you must share the computer with other users, but they can be crucial for getting minimum response time from a dedicated system.
The first feature can be of use to programs which have high memory bandwidth requirements. Since one CPU can use more than half of a node's bandwidth, running two threads on a node can overload the bandwidth of the hub. Spreading the threads of a job across more nodes can result in higher sustained bandwidth. Of course, you are then limited to half the available CPUs. However, you could run a memory-intensive job with one thread per memory, and concurrently run a cache-friendly (and hence, low-bandwidth) job on the remaining CPUs.
Using the MP library, you can run just one thread per node by setting the environment variable _DSM_PPM to 1. Using dplace, write a placement file specifying the same number of memories as threads. In the distribute statement, you can explicitly use a block of 1, but this will be the default when the number of threads is the same as the number of memories:
memories $NP in topology none threads $NP distribute theads across memories block 1 |
The second feature, locking threads to CPUs, has long been available in IRIX via the sysmp(MP_MUSTRUN,...) system call. The MP library and dplace offer convenient access to this capability. For the MP library, you only need to set the _DSM_MUSTRUN environment variable to lock all threads onto the CPUs where they start execution.
Using dplace, use the -mustrun flag, as follows:
% dplace -mustrun -place placement_file program |
Both the MP library and dplace lock the processes onto the CPUs on which they start. This arrangement will change from run to run. If you want to lock threads onto specific physical CPUs, you must use a placement file specifying a physical topology, or call sysmp() explicitly.
Making a C or Fortran program run in parallel on multiple CPUs can be as simple as recompiling with the -apo option, and executing on a system with two or more CPUs. Alternatively, you can write the program for parallel execution using a variety of software models. In every case, the benefit of adding one more CPU depends on the fraction of the code that can be executed in parallel, and on the hardware constraints that can keep the added CPU from pulling its share of the load. You use the profiling tools to locate these bottlenecks, and generally you can relieve them in simple ways, so that the program's performance scales smoothly from one CPU to as many CPUs as you have.