Programming an SN0 system is little different from programming a conventional shared memory multiprocessor such as the SGI Power Challenge R10000. This is, of course, largely because the hardware makes the physically distributed memory work as a shared memory. It is also, however, a result of the IRIX 6.5 operating system, which contains important new capabilities for managing memory and for running the system as efficiently as possible. Although most of these added capabilities are transparent to the user, some new tools are available for fine-tuning performance, and there is some new terminology to go along with them.
This section describes some of the memory-management features of IRIX 6.5, so you can understand what the operating system is trying to accomplish. It familiarizes you with the terminology of memory management, because these terms are used in documenting the compilers and performance tools.
An SN0 system is a shared memory multiprocessor. It runs the IRIX operating system, which provides a familiar multiuser time-sharing environment as well as familiar compilers, tools, and programming conventions and methods. Even though I/O devices are physically attached to different nodes, any device can be accessed from any program just as you would expect in a UNIX based system.
The hardware, however, is different. As described in Chapter 1, “Understanding SN0 Architecture”, there is no longer a central bus into which CPUs, memory, and I/O devices are installed. Instead, memory and peripherals are distributed among the CPUs, and the CPUs are connected to one another via an interconnecting fabric of hub and router chips. This allows unprecedented scalability for a shared memory system. A side effect, however, is that the time it takes for a CPU to access a memory location varies according to the location of the memory relative to the CPU—according to how many hubs and routers the data must pass through. This is Non-uniform Memory Access (NUMA). (For an indication of the access times, see the Read Latency—Max column in Table 1-3.)
Although the hardware has been designed so that overall memory access times are greatly reduced compared to earlier systems, and although the variation in times is small, memory access times are, nevertheless, nonuniform, and this introduces a new set of problems to the task of program optimization. These facts are clear:
A program will run fastest when its data is in the memory closest to the CPU that is executing the code.
When it is not possible to have all of a program's data physically adjacent to the CPU—for example, if the program uses an array so large it cannot all be allocated in one node—then it is important to find the data that is most frequently used by a CPU, and bring that into nearby memory.
When a program is executing in parallel on multiple CPUs, the data used by each parallel thread of the algorithm should be close to the CPU that processes the data—even when the parallel threads are processing parallel slices through the same array.
IRIX has been enhanced to take NUMA into account and to make program optimization not only possible, but automatic. The remaining topics of this chapter summarize the NUMA support in IRIX. As a programmer, you are not required to deal with these features directly, but you have the opportunity to take advantage of them using tuning tools described in subsequent chapters.
It is important to remember that the impact of NUMA on performance is, first, important only to programs that incur a lot of secondary cache misses. (Programs that take data mostly out of cache make few references to memory in any location.) Second, these effects apply to multithreaded programs, and to single-threaded programs with large memory requirements. (Single-threaded programs using up to a few tens of megabytes usually run entirely in one node anyway.) Third, NUMA effects are minimal except in larger system configurations. You must have more than 8 CPUs before it is possible to have a path with more than one router in it.
The concepts and terminology are presented anyway, so that you can understand what the operating system is trying to accomplish. In addition, it will make you aware of the programming practices that lead to the most scalable code.
IRIX 6.5 manages an SN0 system to create a single-system image with the many advanced features required by a modern distributed shared memory operating system. It combines the virtues of the data center environment and the distributed workstation environment, including the following:
Scalability from 2 to 256 CPUs and from 64 MB to 1 TB of virtual memory
Upward compatibility with previous versions of IRIX
Availability features such as IRIS Failsafe, RAID, integrated checkpoint-restart
Support for interactive and batch scheduling and system partitioning
Support for parallel-execution languages and tools
The NUMA dependency of memory latency on memory location leads to a new resource for the operating system to manage: memory locality. Ideally, each memory access should be satisfied from memory on the same node board as the CPU making the access. This is not always possible; some processes may require more memory than fits on one node board, and different threads in a parallel program, running on separate nodes, may need to access the same memory location. Nevertheless, a high degree of memory locality can be achieved, and the operating system works to maximize memory locality.
For the vast majority of cases, executing an application in the default environment will yield a large fraction of the achievable performance. IRIX obtains optimal memory locality management through the use of a variety of mechanisms described in the following topics.
The operating system always attempts to allocate the memory a process uses from the same node on which the process runs. If there is not sufficient memory on the node to allow this, the remainder of the memory is allocated from nodes close to the process.
The usual effect of default allocation policies is to put data close to the CPU that uses it. In some cases of parallel programs, it does not, but the programmer can modify the default policies to suit the program's needs.
IRIX can move data from one node to another that is making heavier use of it. IRIX manages memory in virtual pages with a size of 16 KB or larger. (The programmer can control the page size, and in fact can specify different page sizes for data and for code.)
IRIX maintains counters that show which nodes are making the heaviest use of each virtual page. When it discovers that most of the references to a page are coming from a different node, IRIX can move the page to be closer to its primary user. This changes the physical address of the page, but the program uses the virtual address. IRIX copies the data and adjusts the page-translation tables. The movement is transparent to programs. This facility is also called page migration.
The programmer can turn page migration on or off for a given program, or turn it on dynamically during specific periods of program execution. These options are discussed in Chapter 8, “Tuning for Parallel Processing”.
When selecting a CPU on which to initiate a job, the operating system tries to choose a node that, along with its neighbors, provides an ample supply of memory. Thus, should the process's memory requirements grow over time, the additional memory will be allocated from nearby nodes, keeping the access latency low.
The IRIX scheduler, in juggling the demands of a multiuser environment, makes every attempt to keep each process running on CPUs that are close to the memories in which the process's data resides.
The IRIX strategies are designed for the “typical” program's needs, and they can be less than optimal for specific programs. Application programmers can influence IRIX memory placement in several ways: through compiler directives; through use of the dplace tool (see the dplace(1) man page, and see Chapter 8, “Tuning for Parallel Processing”); and by runtime calls to special library routines.
The operating system supports memory locality management through a set of low-level system calls. These are not of interest to the application programmer because the capabilities needed to fine-tune performance are available in a high-level tool, dplace, and through compiler directives. But a couple of concepts that the system calls rely on are described because terminology derived from them is used by the high-level tools. These concepts are memory locality domains (MLDs) and policy modules (PMs).
Every user of an SN0 system implicitly makes use of MLDs and policy modules because the operating system uses them to maximize memory locality. Their use is completely transparent to the user, and they do not need to be understood to use an SN0 system. But for those of you interested in fine-tuning application performance—particularly of large parallel jobs—it can be useful to know that MLDs and policy modules exist, and which types of policies are supported and what they do.
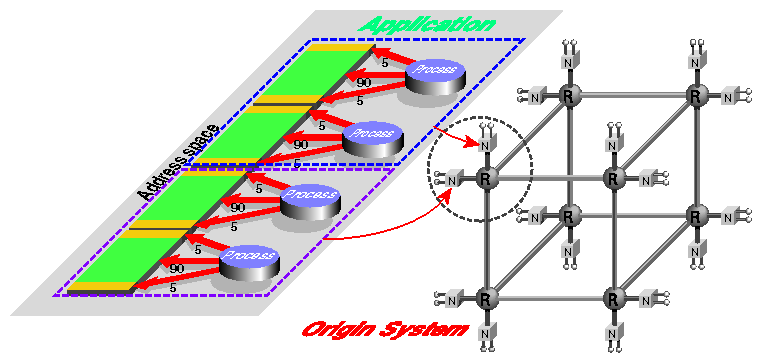
To understand the issues involved in memory locality management, consider the scenario diagrammed in Figure 2-1.
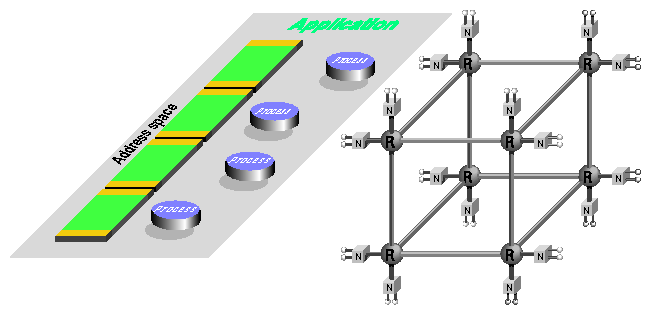
Diagrammed on the left in Figure 2-1 is the programmer's view of a shared memory application, consisting of a single virtual address space and four parallel processes. On the right is the architecture of a 32-CPU (16-node) SN0 system. The four application processes can run in any four of the CPUs. The pages that compose the program's address space can be distributed across any combination of one to sixteen nodes. Out of the myriad possible arrangements, how should IRIX locate process execution and data?
Assume that this application exhibits a relatively simple (and typical) pattern of memory use: each process addresses 5% of its accesses to memory shared with another process; 5% to memory shared with a third process; while 90% of its cache misses are from memory accesses to an almost unshared section of memory. The pattern is best seen graphically, as in Figure 2-2.
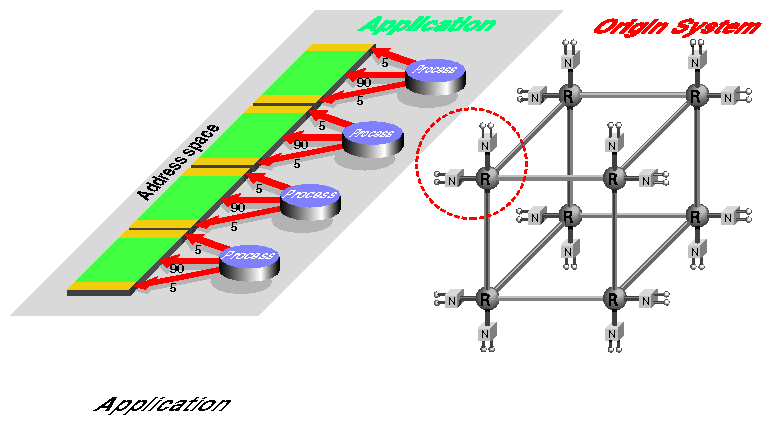
If IRIX paid little attention to memory locality, the program could end up in the situation shown in Figure 2-3: two processes and half the memory in one corner of the machine, the other processes and memory running in an opposite corner.
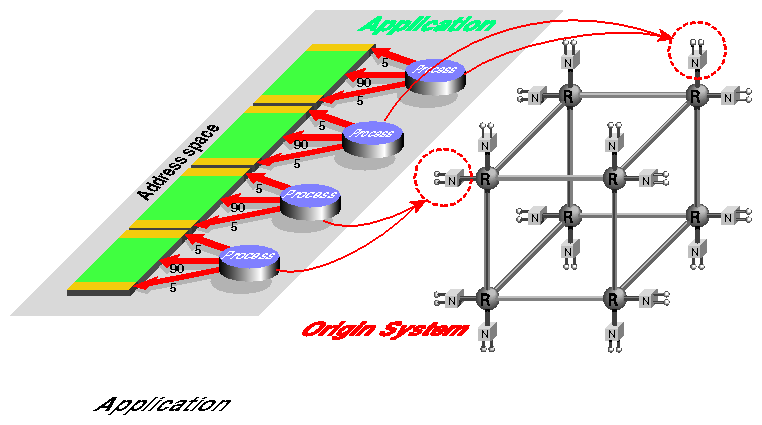
The result is acceptable. The first and fourth processes, and 95% of the memory use of the second and third processes, run at local speed. Only when the second and third processes access the data they share, and especially when they update these locations, will data fly back and forth through several routers. The SN0 hardware has been designed to keep the variation in memory latencies small, and accesses to the shared section of memory account for only 5% of two of the processes' cache misses, so this suboptimal placement has a small effect on the performance of the program.
There are situations in which performance could be significantly affected. If absolutely no attention was paid to memory locality, the processes and memory could end up as shown in Figure 2-4.
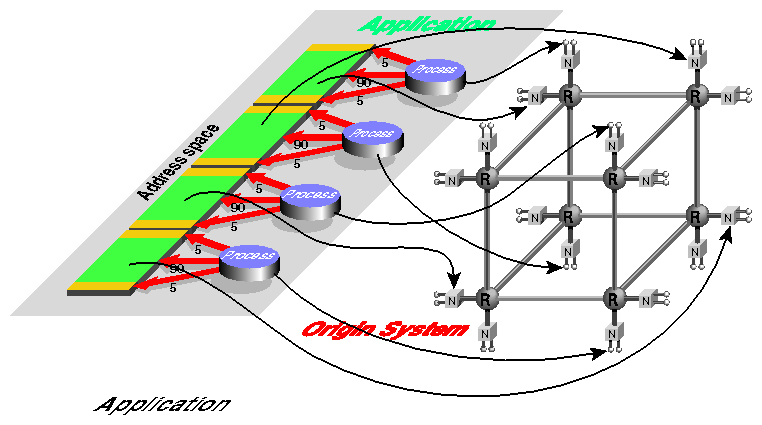
Here, each process runs on a different and distant CPU, and the sections of memory it uses are allocated on a different set of distant nodes. In this case, even the accesses to unshared sections of memory—which account for 90% of each process's cache misses—are nonlocal, increasing the costs of accessing memory. In addition, program performance can vary from run to run depending on how close each process ends up to its most-accessed memory. (It is worth mentioning that, even in this least-optimal arrangement, the program would run correctly. The poor assignment of nodes would not make the program fail or produce wrong answers, only slow it down and create needless contention for the NUMAlink fabric.)
However, the memory locality management mechanisms in IRIX are designed to avoid such situations. Ideally, the processes and memory used by this application are placed in the machine as shown in Figure 2-5.
The first two processes run on the two CPUs in one node.
The other two processes run on the CPUs in an adjacent node, one hop away.
The memory for each pair of processes is allocated in the same node.
To allow IRIX to achieve this ideal placement, two abstractions of physical memory nodes are used:
Memory locality domains (MLDs)
Memory locality domain sets (MLDSETs)
A memory locality domain is a source of physical memory. It can represent one node, if there is sufficient memory available for the process(es) that run there, or it can stand for several nodes within a given radius of a center node. For the example application, the operating system creates two MLDs, one for each pair of processes, as diagrammed in Figure 2-6.
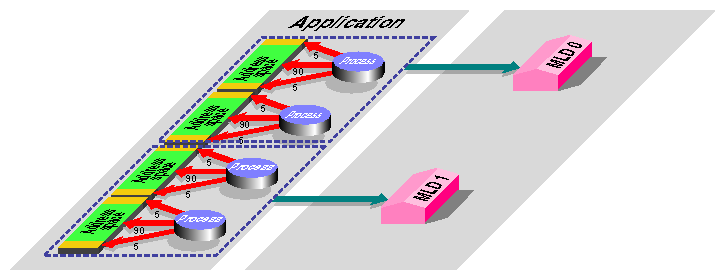
It is up to the operating system to decide where in the machine these two MLDs should be placed. Optimal performance requires that they be placed on adjacent nodes, so the operating system needs some additional information.
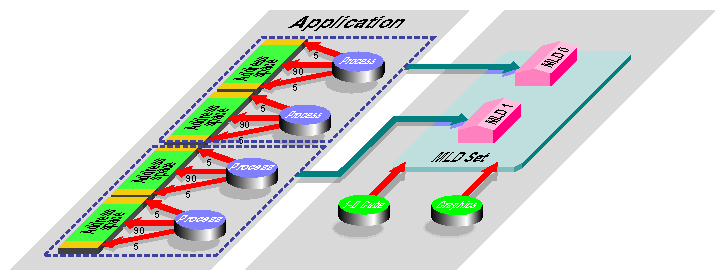
Memory locality domain sets describe how a program's MLDs should be placed within the machine, and whether they need to be located near any particular hardware devices (for example, close to a graphics pipe). The first property is known as the topology, and the second as resource affinity.
Several topology choices are available. The default is to let the operating system place the MLDs of the set on a cluster of physical nodes that is as compact as possible. Other topologies allow MLDs to be placed in hypercube configurations (which are proper subsets of the SN0 interconnection topology), or on specific physical nodes. Figure 2-7 shows the MLDs for the example application placed in a one-dimensional hypercube topology with resource affinity for a graphics device.
Figure 2-7. Parallel Program Mapped to an MLD Set with Hypercube Topology and Affinity to a Graphics Device
 |
With the MLDs and MLD set defined, the operating system is almost ready to attach the program's processes to the MLDs, but first policy modules need to be created for the MLDs. Policy modules tell the operating system the following:
How to place pages of memory in the MLDs.
Which page size(s) to use.
What fallback policies to use if the resource limitations prevent the preferred placement and page size choices from being carried out.
Whether page migration is enabled.
The operating system uses a set of default policies unless instructed otherwise. You can change the defaults through the utility dplace or via compiler directives. Once the desired policies have been set, the operating system can map processes to MLDs and MLDs to hardware, as shown in Figure 2-8. This ensures that the application threads execute on the nodes from which the memory is allocated.
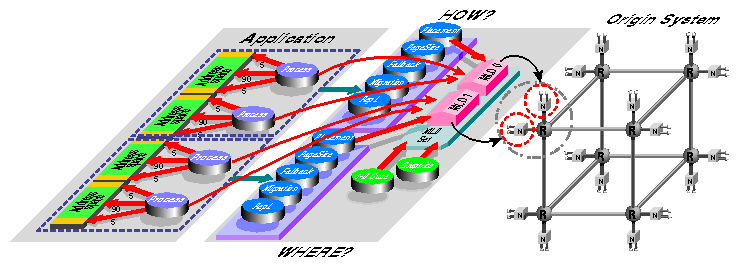
The initial placement of data is important for consistently achieving high performance on parallelized applications. It is not an issue for single-threaded programs because they have only one MLD from which to allocate memory.
There is, however, one difference you may see when running a large, single-threaded program on SN0 compared to a bus-based system. When the program has modest memory requirements, it is likely to succeed in allocating all its memory from the node on which it runs. Then all cache misses incur local memory latencies. However, as the program's data requirements grow, it may need to draw memory from nearby nodes. As a result, some cache misses have longer latencies.
Thus the effective time for a cache miss can change, either because the program uses more memory (due either to a change in the algorithm or to larger input data), or because other jobs consume more of the memory on the node. Note that if the program is allocating significantly more memory, it is likely to run longer in any case, because it is doing more work. Any NUMA variation may be unnoticeable beside the algorithmic difference.
Although a program's memory access patterns may be very obvious to an application programmer, the operating system has no way to obtain this information. The placement policies determine how the memory for virtual pages is allocated from the different MLDs in the MLD set. Three memory placement policies are available:
First-touch, in which memory is allocated from the MLD associated with the first process to access the page (in other words, the process that first faults that page).
Fixed, in which memory is allocated from a specific MLD.
Round-robin, in which pages of memory are allocated in a round-robin fashion from each of the MLDs in the MLD Set in turn.
The default policy is first-touch. It works well with single-threaded programs, because it keeps memory close to the program's one process. It also works well for programs that have been parallelized completely, so that each parallel thread allocates and initializes the memory it uses.
When the example program above (Figure 2-8) is running, each CPU accesses three segments of data: a 90% segment accessed by no other node and two 5% pieces, each of which is also accessed by a neighboring CPU. In the ideal data layout, the 90% piece for each CPU is stored in its local memory. In addition, the two adjacent 5% pieces are stored locally, while the two remaining 5% pieces are stored in the neighboring CPUs. This distributes responsibility for storing the data equally among all CPUs and ensures that they all incur the same cost for accessing nonlocal memory.
If the initialization of memory is done in parallel in each process, each CPU is the first to touch its 90% piece and the two adjacent 5% pieces, causing those segments to be allocated locally. This is exactly where we want these segments to reside. When you program memory initialization in each program thread independently, the first-touch policy guarantees good data placement. The common alternative, to initialize all of memory from a single master process before starting the parallel processes, has just the wrong effect, placing all memory into a single node.
Although this extra consideration is not required in a bus-based system such as Power Challenge, it is simple to do and does not require you to learn anything new, such as the compiler directives, which also allow data to be placed optimally.
If a program has not been completely parallelized, the first-touch policy may not be the best one to use. For the example application, if all the data are initialized by just one of the four processes, all the data will be allocated from a single MLD, rather than being evenly spread out among the four MLDs. This introduces two problems:
Accesses that should be local are now remote.
All the processes' cache misses are satisfied from the same memory. This can cause a performance bottleneck by overloading the hub in that node.
Even in this case, if dynamic page migration is enabled, the data will eventually move to where it is used, so ultimately pages should be placed correctly. This works well for applications in which there is one optimal data placement, and the application runs long enough (minutes) for the data to migrate to their optimal locations.
In some complicated applications, different placements of data are needed in different phases of the program, and the program phases alternate so quickly, that there is not time for the operating system to migrate the data to the best location for one program phase before that phase ends and a new one begins.
For such applications, a difficult solution is to perform explicit page migration using programmed compiler directives. A simple solution is to use the round-robin placement policy. Under this policy, memory is evenly distributed, by pages, among the MLDs. Any one page is not likely to be in an optimal location at a particular phase of the program; however, by spreading memory accesses across all the nodes where the program runs, you avoid creating performance bottlenecks.
Avoiding bottlenecks is actually a more important consideration than getting the lowest latency. The variation in memory latency is moderate, but if all the data are stored in one node, the outgoing bandwidth of that one hub chip is divided among all the other CPUs that use the data.
The final placement policy is fixed placement, which places pages of memory in a specific MLD. You invoke this policy using the compiler placement directives. These directives are a convenient way to specify the optimal placement of data, when you are sure you know what it is. You can specify different placements in different parts of a program, so these directives are ideal for complicated applications that need different data placements during different processing phases.
The memory locality management automatically performed by IRIX means that most SN0 programs can achieve good performance and enhanced scalability without having to program any differently from the way they do on any other system. But some programs that were developed on a uniform memory access architecture might run more slowly than they could. This section summarizes when you can expect to see the effects of the NUMA architecture and what tools you can use to minimize them.
Even though SN0 is a highly parallel system, the vast majority of programs it runs use only a single CPU. Nothing new or different needs to be done to achieve good performance on such applications. Tune them just as you would for any other system. Chapter 3, “Tuning for a Single Process”, provides a detailed discussion of the tools available and steps you can take to improve the performance of single-threaded programs.
There is one new capability in the SN0 architecture that single-CPU programs can sometimes use to improve performance, namely, support for multiple page sizes. Recall that page size is one of the policies that IRIX 6.5 can apply in allocating memory for processes. Normally, the default page size of 16 KB is used, but for programs that incur a performance penalty from a large number of virtual page faults, it can be beneficial to use a larger page size. For single-CPU programs, page size is controlled via dplace and explained under “Using Larger Page Sizes to Reduce TLB Misses” in Chapter 6.
Single-CPU tuning accounts for most of the performance work you do. Using the proper compiler flags and coding practices can yield big improvements in program performance. Once you have made your best effort at single-CPU tuning, you can turn your attention to issues related to parallel programming. Parallel programs are separated into two classes:
MP library programs. These use the shared memory parallel programming directives that have been available in Silicon Graphics compilers for many years, or the parallel programming directives defined in the OpenMP API. It also includes programs using MPI version 3 or later, as distributed with IRIX.
Non-MP library programs. These include programs using the IRIX facilities for starting parallel processes, programs using the pthreads model, programs using the PVM library, and programs using the Cray shared-memory models.
For programs in the second class, it is a good idea to use dplace to specify a memory placement policy. This is covered in Chapter 8, “Tuning for Parallel Processing”.
Programs in the first class that make good use of the CPU's caches see little effect from NUMA architecture. The reason for this is that memory performance is affected by memory latencies only if the program spends a noticeable amount of time actually accessing memory, as opposed to cache. Cache-friendly programs have very few cache misses, so the vast majority of their data accesses are satisfied by the caches, not memory. Thus the only NUMA effect these programs see is scalability to a larger number of CPUs.
The perfex and Speedshop tools can be used to determine if a program is cache-friendly and, if not, where the problems are. You can find a detailed discussion in Chapter 3, “Tuning for a Single Process”.
Not all programs can be made cache friendly, however. That only means these memory-intensive programs will spend more time accessing memory than their cache-friendly brethren, and in general will run at lower performance. This is just one of the facts of life for cache-based systems, which is to say, all computer systems except very expensive vector CPUs.
When there is a performance or scalability problem, the data may not have been well placed, and modifying the placement policies can fix this. First, try a round-robin placement policy. (For programs that have been parallelized using the SGI MP directives, round-robin placement can be enabled by changing only an environment variable (see “Trying Round-Robin Placement” in Chapter 8). If this solves the performance problem, you're done. If not, try enabling dynamic page migration (done with yet another environment variable, see “Trying Dynamic Page Migration” in Chapter 8). Both can be tried in combination.
Often, these policy changes are all that is needed to fix a performance problem. They are convenient because they require no modifications to your program. When they do not fix a performance or scalability problem, you need to modify the program to ensure that the data are optimally placed. This can be done in a couple of ways.
You can use the default first-touch policy, and program so that the data are first accessed by the CPU in whose memory they should reside. This programming style is easy to use, and it does not require learning new compiler directives. (See “Programming For First-Touch Placement” in Chapter 8.)
The second way to ensure proper data layout is to use the data placement directives, which permit you to specify the precise data layout that is optimal for your program. The use of these directives is described in “Using Data Distribution Directives” in Chapter 8.
While the distributed shared memory architecture of the SN0 systems introduces new complexities, most of them are handled automatically by IRIX, which uses a number of internal strategies to ensure that processes and their data end up reasonably close together. Normally, single-threaded programs operate very well, showing no effects from the NUMA architecture, other than a run-to-run variation in memory latency that depends on the program's dynamic memory use.
When programs are made parallel using the SGI-supplied compiler and MP library, and when parallel programs are based on the SGI-supplied MPI version 3 library, they use appropriate MLDs automatically and are likely to run well without further tuning for NUMA effects. Parallel programs based on other models may gain from programmer control over memory placement, and the tools for this control are available. All these points are examined in detail in Chapter 8, “Tuning for Parallel Processing”.