Because the SN0 architecture has multiple levels of memory access, optimizations that improve a program's utilization of memory can have major effects. This chapter introduces the concepts of cache and virtual memory use and its effects on performance in these topics:
“Understanding the Levels of the Memory Hierarchy” describes the relation between the programmer's view of memory as arrays and variables, and the system's view of memory as a hierarchy of caches and nodes.
“Identifying Cache Problems with Perfex and SpeedShop” shows how you can tell when a program is being slowed by memory access problems.
“Using Other Cache Techniques” describes some basic strategies you can use to overcome memory-access problems.
The discussion continues in Chapter 7, “Using Loop Nest Optimization”, with details of the compiler optimizations that automatically exploit the memory hierarchy.
To understand why cache utilization problems occur, it is important to understand how the data caches in the system function. As mentioned under “Cache Architecture” in Chapter 1, the CPUs in the SN0 architecture utilize a two-level cache hierarchy. There are 32 KB L1 data and instruction caches on the CPU chip, and a much larger L2 cache external to the CPU on the node board. The virtual memory system makes the third and fourth levels of caching.
The L1 and L2 caches are two-way set associative; that is, any data element may reside in only two possible locations in either cache, as determined by the low-order bits of its address. If the program refers to two locations that have the same low-order address bits, copies of both can be maintained in the cache simultaneously. When a third datum with the same low-order address bits is accessed, it replaces one of the two previous data—the one that was least recently accessed.
To maintain a high bandwidth between the caches and memory, each location in the cache holds a contiguous block, or cache line, of data. For the primary cache, the line size is 32 bytes; it is 128 bytes for the secondary cache. Thus, when a particular word is copied into a cache, several nearby words are copied with it.
The CPU can make use only of data in registers, and it can load data into registers only from the primary cache. So data must be brought into the primary cache before it can be used in calculations. The primary cache can obtain data only from the secondary cache, so all data in the primary cache is simultaneously resident in the secondary cache. The secondary cache obtains its data from main memory. The operating system uses main memory to create a larger virtual address space for each process, keeping unneeded pages of data on disk and loading them as required—so, in effect, main memory is a cache also, with a cache line size of 16KB, the size of a virtual page.
A cache miss occurs when the program refers to a datum that is not present in the cache. That instruction is suspended while the datum (and the rest of the cache line that contains it) is copied into the cache. When an instruction refers to a datum that is already in the cache, this is a cache hit.
A page is the smallest contiguous block of memory that the operating system allocates to your program. Memory is divided into pages to allow the operating system to freely partition the physical memory of the system among the running processes while presenting a uniform virtual address space to all jobs. Your programs see a contiguous range of virtual memory addresses, but the physical memory pages can be scattered all over the system.
The operating system translates between the virtual addresses your programs use and the physical addresses that the hardware requires. These translations are done for every memory access, so, to keep their overhead low, the 64 most recently used page addresses are cached in the translation lookaside buffer (TLB). This allows virtual-to-physical translation to be carried out with zero latency, in hardware—for those 64 pages.
When the program refers to a virtual address that is not cached in the TLB, a TLB miss has occurred. Only then must the operating system assist in address translation. The hardware traps to a routine in the IRIX kernel. It locates the needed physical address in a memory table and loads it into one of the TLB registers, before resuming execution.
Thus the TLB acts as a cache for frequently-used page addresses. The virtual memory of a program is usually much larger than 64 pages. The most recently used pages of memory (hundreds or thousands of them) are retained in physical memory, but depending on program activity and total system use, some virtual pages can be copied to disk and removed from memory. Sometimes, when a program suffers a TLB miss, the operating system discovers that the referenced page is not presently in memory—a “page fault” has occurred. Then the program is delayed while the page is read from disk.
The latency of data access becomes greater with each cache level. Latency of memory access is best measured in CPU clock cycles. One cycle occupies from 4 to 6 nanoseconds, depending on the CPU clock speed. The latencies to the different levels of the memory hierarchy are as follows:
CPU Register: 0 cycles.
L1 cache hit: 2 or 3 cycles.
L1 cache miss satisfied by L2 cache hit: 8 to 12 cycles.
L2 cache miss satisfied from main memory, no TLB miss: 75 to 250 cycles; that is, 300 to 1100 nanoseconds, depending on the node where the memory resides (see Table 1-3).
TLB miss requiring only reload of the TLB to refer to a virtual page already in memory: approximately 2000 cycles.
TLB miss requiring virtual page to load from backing store: hundreds of millions of cycles; that is, tens to hundreds of milliseconds.
A miss at each level of the memory hierarchy multiplies the latency by an order of magnitude or more. Clearly a program can sustain high performance only by achieving a very high ratio of cache hits at every level. Fortunately, hit ratios of 95% and higher are commonly achieved.
One way to disguise the latency of memory access is to overlap this time with other work. This is the reason for the out-of-order execution capability of the R10000 CPU, which can suspend as many as four instructions that are waiting for data, and continue to execute following instructions that have their data. This is sufficient to hide most of the latencyv of the L1 cache and often that of the L2 cache as well. Something more is needed to overlap main memory latency with work: data prefetch.
Prefetch instructions are part of the MIPS IV instruction set architecture (see “MIPS IV Instruction Set Architecture” in Chapter 1). They allow data to be moved into the cache before their use. If the program requests the data far enough in advance, main-memory latency can be completely hidden. A prefetch instruction is similar to a load instruction: an address is specified and the datum at that address is accessed. The difference is that no register is specified to receive the datum. The CPU checks availability of the datum and, if there is a cache miss, initiates a fetch, so the data ends up in the cache.
There is no syntax in standard languages such as C and Fortran to request a prefetch, so you normally rely on the compiler to automatically insert prefetch instructions. Compiler directives are also provided to allow you to specify prefetching manually.
The operation of the caches immediately leads to some straightforward principles. Two of the most obvious are:
A program ought to make use of every word of every cache line that it touches.
Clearly, if a program does not make use of every word in a cache line, the time spent loading the unused parts of the line is wasted.
A program should use a cache line intensively and then not return to it later.
When a program visits a cache line a second time after a delay, the cache line may have been displaced by other data, so the program is delayed twice waiting for the same data.
These two principles together imply that every loop should use a memory stride of 1; that is, a loop over an array should access array elements from adjacent memory addresses. When the loop “walks” through memory by consecutive words, it uses every word of every cache line in sequence, and does not return to any cache line after finishing it.
Consider the loop nest in Example 6-1.
Example 6-1. Simple Loop Nest with Poor Cache Use
do i = 1, n
do j = 1, n
a(i,j) = b(i,j)
enddo
enddo
|
In Example 6-1, the array b is copied to the array a one row at a time. Because Fortran stores matrices in column-major order—that is, consecutive elements of a column are in consecutive memory locations—this loop accesses memory with a stride of n. Each element loaded or stored is n elements away from the last one. As a result, a new cache line must be brought in for each element of a and of b. If the matrix is small enough, all of it will shortly be brought into cache, displacing other data that was there. However, if the array is too large (the L1 data cache is only 32 KB in size), cache lines holding elements at the beginning of a row may be displaced from the cache before the next row is begun. This causes a cache line to be loaded multiple times, once for each row it spans.
Simply reversing the order of the loops, as in Example 6-2, changes the loop to stride-one access.
Example 6-2. Reversing Loop Nest to Achieve Stride-One Access
do j = 1, n
do i = 1, n
a(i,j) = b(i,j)
enddo
enddo
|
Using this ordering, the data are copied one column at a time. In Fortran, this means copying adjacent memory locations in sequence. Thus, all data in the same cache line are used, and each line needs to be loaded only once.
Consider the Fortran code segment in Example 6-3, which performs a calculation involving three vectors, x, y, and z.
Example 6-3. Loop Using Three Vectors
d = 0.0
do i = 1, n
j = ind(i)
d = d + sqrt(x(j)*x(j) + y(j)*y(j) + z(j)*z(j))
enddo
|
Access to the elements of the vectors is not sequential, but indirect through an index array, ind. It is not likely that the accesses are stride-one in any vector. Thus, each iteration of the loop may well cause three new cache lines to be loaded, one from each of the vectors.
It appears that x(j), y(j), and z(j), for one value of j, are a triple that is always processed together. Consider Example 6-4, in which the three vectors have been grouped together as the three rows of a two-dimensional array, r. Each column of the array contains one of the triples x, y, z.
Example 6-4. Three Vectors Combined in an Array
d = 0.0
do i = 1, n
j = ind(i)
d = d + sqrt(r(1,j)*r(1,j) + r(2,j)*r(2,j) + r(3,j)*r(3,j))
enddo
|
Because r(1,j), r(2,j), and r(3,j)—the three rows of column j—are contiguous in memory, it is likely that all three values used in one loop iteration will fall in the same cache line. This reduces traffic to the cache by as much as a factor of three. There could be a cache line or two, but not three, fetched for each iteration of the loop.
Suppose the loop in Example 6-3 had not used indirect indexing, but instead progressed through the vectors sequentially, as in this example:
d = d + sqrt(x(i)*x(i) + y(i)*y(i) + z(i)*z(i))
|
Then the accesses would have been stride-1, and there would be no advantage to grouping the vectors—unless they were aligned in memory so that x(i), y(i), and z(i) all mapped to the same location in the cache. Such unfortunate alignments can happen, and cause what is called cache thrashing.
Consider the code fragment in Example 6-5, where three large vectors are combined into a fourth.
Example 6-5. Fortran Code That May Cause Thrashing
parameter (max = 1024*1024)
dimension a(max), b(max), c(max), d(max)
do i = 1, max
a(i) = b(i) + c(i)*d(i)
enddo
|
The four vectors are declared one after the other, so they are allocated contiguously in memory. Each vector is 4 MB in size (1024 × 1024 times the size of a default real, 4 bytes). Thus the low 22 bits of the addresses of elements a(i), b(i), c(i), and d(i) are the same. The vectors map to the same locations in the associative caches.
To perform the calculation in iteration i of this loop, a(i), b(i), c(i), and d(i) must be resident in the primary cache. c(i) and d(i) are needed first to carry out the multiplication. They map to the same location in the cache, but both can be resident simultaneously because the cache is two-way set associative—it can tolerate two lines using the same address bits. To carry out the addition, b(i) needs to be in the cache. It maps to the same cache location, so the line containing c(i) is displaced to make room for it (here we assume that c(i) was accessed least recently). To store the result in a(i), the cache line holding d(i) must be displaced.
Now the loop proceeds to iteration i+1. The line containing c(i+1) must be loaded anew into the cache, because one of the following things is true:
c(i+1) is in a different line than c(i) and so its line must be loaded for the first time.
c(i+1) is in the same line as c(i) but was displaced from the cache during the previous iteration.
Similarly, the cache line holding d(i+1) must also be reloaded. In fact, every reference to a vector element results in a cache miss, because only two of the four values needed during each iteration can reside in the cache simultaneously. Even though the accesses are stride-one, there is no cache line reuse.
This behavior is known as cache thrashing, and it results in very poor performance, essentially reducing the program to uncached use of memory. The cause of the thrashing is the unfortunate alignment of the vectors: they all map to the same cache location. In Example 6-5 the alignment is especially bad because max is large enough to cause thrashing in both primary and secondary caches.
There are two ways to repair cache thrashing:
Redimension the vectors so that their size is not a power of two. A new size that spaces the vectors out in memory so that a(1), b(1), c(1) and d(1) all map to different locations in the cache is ideal. For example, max = 1024 x 1024 + 32 would offset the beginning of each vector 32 elements, or 128 bytes. This is the size of an L2 cache line, so each vector begins at a different cache address. All four values may now reside in the cache simultaneously, and complete cache line reuse is possible.
For two-dimensional arrays, it is sufficient to make the leading dimension an odd number, as in the following:
dimension a(1024+1,1024)For multidimensional arrays, it is necessary to change two or more dimensions, as in the following:
dimension a(64+1,64+1,64)
Eliminating cache thrashing makes the loop at least 100 times faster.
The profiling tools discussed in Chapter 4, “Profiling and Analyzing Program Behavior”, are used to determine if there is a cache problem. To see how they work, reexamine the profiles taken from adi2.f (Example 4-2 and Example 4-6).
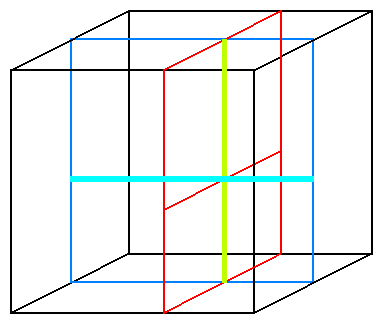
You can review the code of this program in Example C-1. It processes a three-dimensional cubical array. The three procedures xsweep, ysweep, and zsweep perform operations along pencils in each of the three dimensions, as indicated in Figure 6-1.
The profiles using PC sampling (Example 4-6) presented times for these procedures indicating that the vast majority of time is spent in the routine zsweep:
samples time(%) cum time(%) procedure (dso:file)
6688 6.7s( 78.0) 6.7s( 78.0) zsweep (adi2:adi2.f)
671 0.67s( 7.8) 7.4s( 85.8) xsweep (adi2:adi2.f)
662 0.66s( 7.7) 8s( 93.6) ysweep (adi2:adi2.f)
|
However, the ideal time profile (Example 4-9) presented quite a different picture, showing identical instruction counts in each routine.
PC sampling, which samples of the program counter position as the program runs, obtains an accurate measure of elapsed time associated with memory accesses. Ideal time counts the instructions and cannot tell the difference between a cache hit and a miss.
The difference between the -pcsamp and -ideal profiles indicates that the instructions in zsweep occupied much more elapsed time than similar instructions in the other routines. The explanation is that zsweep suffers from some serious cache problems, but it provides no indication of the level of memory—L1 cache, L2 cache, or TLB—that is the principal source of the trouble. This can be determined using the R10000 event counters.
The perfex -a -y output for this program appears in Example 4-3 including the lines shown in Example 6-6 (only the “Typical” time column is retained).
Example 6-6. Perfex Data for adi2.f based on 250 MHz IP27 MIPS R10000 CPU
0 Cycles....................................................... 1367270208 5.469081 26 Secondary data cache misses................................. 7102608 2.144988 23 TLB misses.................................................. 5813232 1.583292 7 Quadwords written back from scache.......................... 55599616 1.423350 25 Primary data cache misses................................... 15630496 0.563323 22 Quadwords written back from primary data cache.............. 27158560 0.418242 |
The program spent about 3 seconds of its 8-second run in secondary cache misses, and nearly 2 seconds in TLB misses. These results make it likely that both secondary cache and TLB misses are hindering the performance of zsweep. To understand why, it is necessary look in more detail at what happens when this routine is called (read the program in Example C-1).
If you know that a program is being slowed by memory access problems, but you are not sure which parts of the program are causing the problem, you could perform ssrun experiments of types -dc_hwc, -sc_hwc, and -tlb_hwc (see Table 4-3). These profiles should highlight exactly the parts of the program that are most delayed. In the current example, we know from the profile in Example 4-6 that the problem is in routine zsweep.
zsweep performs calculations along a pencil in the z-dimension. This is the index of the a array that varies most slowly in memory. The declaration for data is as follows:
parameter (ldx = 128, ldy = 128, ldz = 128) real*4 data(ldx,ldy,ldz) |
There are 128 × 128 = 16384 array elements, or 64KB, between successive elements in the z-dimension. Thus, each element along the pencil maps to the same location in the primary cache. In addition, every 32nd element maps to the same place in a 4 MB secondary cache (every eighth element, for a 1 MB cache). The pencil is 128 elements long, so the data in the pencil map to four different secondary cache lines (16, for a 1 MB L2 cache). Since the caches are only two-way set associative, there will be cache thrashing.
As we saw (“Understanding Cache Thrashing”), cache thrashing is fixed by introducing padding. All the data are in a single array, so you can introduce padding by increasing the array bounds. Changing the array declaration to the following provides sufficient padding:
parameter (ldx = 129, ldy = 129, ldz = 129) real*4 data(ldx,ldy,ldz) |
With these dimensions, array elements along a z-pencil all map to different secondary cache lines. (For a system with a 4MB cache, two elements, a(i,j,k1) and a(i,j,k2), map to the same secondary cache line when ((k2 - k1) × 129 × 129 × 4 mod (4MB ÷ (2 associative sets))) ÷ 128 = 0.)
Running this modification of the program produces the counts shown in Example 6-7.
Example 6-7. Perfex Data for adi5.f based on 250 MHz IP27 MIPS R10000 CPU
0 Cycles....................................................... 508485680 2.033943 23 TLB misses.................................................. 5621232 1.530999 26 Secondary data cache misses................................. 667616 0.201620 7 Quadwords written back from scache........................... 5529776 0.141562 25 Primary data cache misses................................... 3091888 0.111432 22 Quadwords written back from primary data cache.............. 6428832 0.099004 |
The secondary cache misses have been reduced by more than a factor of ten. The primary cache misses have also been reduced by a factor of 5. Now, TLB misses represent the dominant memory cost, at 1.5 seconds of the program's 2.0-second run time.
The reason TLB misses consume such a large percentage of the time is thrashing of that cache. Each TLB entry stores the real-memory address of an even-odd pair of virtual memory pages. Each page is 16 KB in size (by default), and adjacent elements in a z-pencil are separated by 129 × 129 × 4 = 65564 bytes, so every z-element falls in a separate TLB entry. However, there are 128 elements per pencil and only 64 TLB entries, so the TLB must be completely reloaded (twice) for each sweep in the z-direction; there is no TLB cache reuse. (Note that this does not mean the data is not present in memory. There are no page faults happening. However, the CPU can address only a limited number of pages at one time. What consumes the time is the frequent traps to the kernel to reload the TLB registers for different virtual pages.)
There are a couple of ways to fix this problem: cache blocking and copying. Cache blocking is an operation that the compiler loop-nest optimizer can perform automatically (see “Controlling Cache Blocking” in Chapter 7). Copying is a trick that the optimizer does not perform, but that is not difficult to do manually. Cache blocking can be used in cases where the work along z-pencils can be carried out independently on subsets of the pencil. But if the calculations along a pencil require a more complicated intermixing of data, or are performed in a library routine, copying is the only general way to solve this problem.
The TLB thrashing results from having to work on data that are spread over too many virtual pages. This is not a problem for the x- and y-dimensions because these data are close enough together to allow many sweeps to reuse the same TLB entries. What is needed is a way to achieve the same kind of reuse for the z-dimension. This can be accomplished by a three-step algorithm:
Copy each z-pencil to a scratch array that is small enough to avoid TLB thrashing.
Carry out the z-sweep on the scratch array.
Copy the results back to the data array.
How big should this scratch array be? To avoid thrashing, it needs to be smaller than the number of pages that the TLB can map simultaneously; this is approximately 58 × 2 pages (IRIX reserves a few of the 64 TLB entries for its own use), or 1,856 KB. But it shouldn't be too small, because the goal is to get a lot of reuse from the page mappings while they are resident in the TLB.
The calculations in both the x- and y-dimensions achieve good performance. This indicates that an array the size of an xz-plane should work well. An xz-plane is used rather than a yz-plane to maximize cache reuse in the x-dimension. If an entire plane requires more scratch space than is practical, a smaller array can be used, but to get good secondary cache reuse, a subset of an xz-plane whose x-size is a multiple of a cache line should be used.
A version of the program modified to copy entire xz-planes to a scratch array before z-sweeps are performed (see Example C-3) produces the counts shown in Example 6-8.
Example 6-8. Perfex Data for adi53.f based on 250 MHz IP27 MIPS R10000 CPU
0 Cycles....................................................... 489865088 1.959460 25 Primary data cache misses................................... 12152464 0.437975 22 Quadwords written back from primary data cache.............. 20673664 0.318374 26 Secondary data cache misses................................. 695712 0.210105 7 Quadwords written back from scache.......................... 5366576 0.137384 23 TLB misses.................................................. 66784 0.018189 |
Comparing Example 6-8 to Example 6-7, the TLB misses all but disappear, and overall performance is significantly improved. Thus the overhead of copying is a good trade-off.
In cases where it is possible to use cache blocking instead of copying, the TLB miss problem can be solved without increasing the primary and secondary cache misses and without expending time to do the copying, so it will provide even better performance. Use copying when cache blocking is not an option.
An alternate technique, one that does not require code modification, is to tell the operating system to use larger page sizes. Each TLB entry represents two adjacent pages; when pages are larger, each entry represents more data. Of course, if you then attempt to work on larger problems, the TLB misses can return, so this technique is more of an expedient than a general solution. Nevertheless, it's worth looking into.
The page size can be changed in two ways: The utility dplace can reset the page size for any program. Its use is very simple (see the dplace(1) man page):
% dplace -data_pagesize 64k -stack_pagesize 64k a.out program-arguments... |
With this command, the data and stack page sizes are set to 64 KB during the execution of the specified a.out. TLB misses typically come as a result of calculations on the data in the program, so setting the page size for the program text (the instructions)—which would be done with the option -text_pagesize 64k—is generally not needed.
For parallel programs that use the MP library, a second method exists. All you need do is to set some environment variables. For example, the following three lines set the page size for data, text and stack to 64 KB:
% setenv PAGESIZE_DATA 64 % setenv PAGESIZE_STACK 64 % setenv PAGESIZE_TEXT 64 |
These environment variables are acted on by the runtime multiprogramming library (libmp) and are effective only when the program is linked with-lmp.
There are some restrictions, on what page sizes can be used. First of all, the only valid page sizes are 16 KB, 64 KB, 256 KB, 1 MB, 4 MB, and 16 MB. Second, the system administrator must specify what percentage of memory is allocated to the various possible page sizes. Thus, if the system has not been set up to allow 1 MB pages, requesting this page size will be of no use.
Only the administrator can change the page size allocation percentages at run-time, for the entire system, using the systune command to change the system variables percent_totalmem_*_pages where * is a valid page size mentioned in the paragraph(see Chapter 10 of the System Configuration and Operation manual mentioned under “Related Manuals”).
Through the use of perfex, PC sampling, and ideal time profiling, cache problems can easily be identified. Two techniques for dealing with them have already been covered (“Understanding Cache Thrashing” and “Using Copying to Circumvent TLB Thrashing”). Other useful methods for improving cache performance are loop fusion, cache blocking, and data transposition.
Consider the pair of loops in Example 6-9.
Example 6-9. Sequence of DAXPY and Dot-Product on a Single Vector
dimension a(N), b(N)
do i = 1, N
a(i) = a(i) + alpha*b(i)
enddo
dot = 0.0
do i = 1, N
dot = dot + a(i)*a(i)
enddo
|
These two loops carry out two vector operations. The first is the DAXPY operation seen before (Example 5-3); the second is a dot-product. If N is large enough that the vectors don't fit in cache, the code will stream the vector b from memory through the cache once and the vector a twice: once to perform the DAXPY operation, and a second time to calculate the product. This violates the second general principle of cache management (“Principles of Good Cache Use”), that a program should use each cache line once and not revisit it.
The code in Example 6-10 performs the same work as Example 6-9 but in one loop.
Example 6-10. DAXPY and Dot-Product Loops Fused
dimension a(N), b(N)
dot = 0.0
do i = 1, N
a(i) = a(i) + alpha*b(i)
dot = dot + a(i)*a(i)
enddo
|
Now the vector a only needs to be streamed through the cache once because its contribution to the dot-product can be calculated while the cache line holding a(i) is still resident. This version takes approximately one-third less time than the original version.
Combining two loops into one is called loop fusion. One potential drawback to fusing loops, however, is that it makes the body of the fused loop larger. If the loop body gets too large, it can impede software pipelining. The Loop-Nest Optimizer tries to balance the conflicting goals of better cache behavior with efficient software pipelining.
Another standard technique used to improve cache performance is cache blocking, or cache tiling. Here, data structures that are too big to fit in the cache are broken up into smaller pieces that will fit in the cache. As an example, consider the matrix multiplication code in Example 6-11.
Example 6-11. Matrix Multiplication Loop
do j = 1, n
do i = 1, m
do k = 1, l
c(i,j) = c(i,j) + a(i,k)*b(k,j)
enddo
enddo
enddo
|
If arrays a, b, and c are small enough that all fit in cache, performance is great. But if they are too big, performance drops substantially, as can be seen from the results in Table 6-1
Table 6-1. Cache Effect on Performance of Matrix Multiply
m | n | l | Seconds | MFLOPS |
|---|---|---|---|---|
30 | 30 | 30 | 0.000162 | 333.9 |
200 | 200 | 200 | 0.056613 | 282.6 |
1000 | 1000 | 1000 | 25.43118 | 78.6 |
(The results in Table 6-1 were obtained with LNO turned off because the LNO is designed to fix these problems!) The reason for the drop in performance is clear if you use perfex on the 1000 × 1000 case:
0 Cycles......................................... 5460189286 27.858109 23 TLB misses..................................... 35017210 12.164907 25 Primary data cache misses...................... 200511309 9.217382 26 Secondary data cache misses.................... 24215965 9.141769 |
What causes this heavy memory traffic? To answer this question, we need to count the number of times each matrix element is touched. From reading the original code in Example 6-11, we can see that the memory access pattern shown schematically in Figure 6-2.
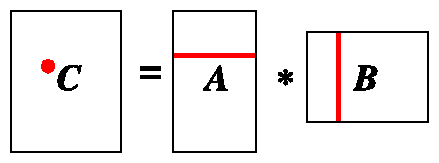
Calculating one element of c requires reading an entire row of a and an entire column from b. Calculating an entire column of c requires reading all the rows of a, so a is swept n times, once for each column of b (or, equivalently, each column of c). Similarly, every column of b must be reread for each element of c, so b is swept m times.
If a and b don't fit in the cache, the earlier rows and columns are likely to be displaced by the later ones, so there is likely to be little reuse. As a result, these arrays will require streaming data in from main memory, n times for a and m times for b.
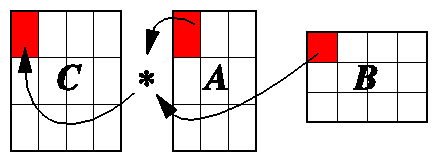
Because the operations on array cells in Example 6-11 are not order-dependent, this problem with cache misses can be fixed by treating the matrices in sub-blocks as shown in Figure 6-3. In blocking, a block of c is calculated by taking the dot-product of a block-row of a with a block-column of b. The dot-product consists of a series of sub-matrix multiplies. When three blocks, one from each matrix, all fit in cache simultaneously, the elements of those blocks need to be read in from memory only once for each sub-matrix-multiply.
The bigger the blocks are, the greater the reduction in memory traffic—but only up to a point. Three blocks must be able to fit into cache at the same time, so there is an upper bound on how big the blocks can be. For example, three 200x200 double-precision blocks take up almost 1 MB, so this is about as big as the blocks can be on a 1 MB cache system. (Most SN0 systems now have 4 MB caches or larger. The hinv command reports the cache size.) Furthermore, the addresses of the blocks must not conflict with themselves or one another; that is, elements of different blocks must not map to the same cache lines (see “Understanding Cache Thrashing”). Conflicts can be reduced or eliminated by proper padding of the leading dimension of the matrices, by careful alignment of the matrices in memory with respect to one another, and, if necessary, by further limiting of the block size.
One other factor affects what size blocks can be used: the TLB cache. The larger we make the blocks, the greater the number of TLB entries that will be required to map their data. If the blocks are too big, the TLB cache will thrash (see “Diagnosing and Eliminating TLB Thrashing”). For small matrices, in which a pair of pages spans multiple columns of a submatrix, this is not much of a restriction. But for very large matrices, this means that the width of a block will be limited by the number of available TLB entries. (The submatrix multiplies can be carried out so that data accesses go down the columns of two of the three submatrixes and across the rows of only one submatrix. Thus, the number of TLB entries only limits the width of one of the submatrixes.) This is just one more detail that must be factored into how the block sizes are chosen.
Return now to the 1000 × 1000 matrix multiply example. Each column is 8,000 bytes in size. Thus (1048576 ÷ 2) ÷ 8000 = 65 columns will fit in one associative set of a 1 MB secondary cache, and 130 will fill both sets. In addition, each TLB entry maps four columns, so the block size is limited to about 225 before TLB thrashing starts to become a problem. The performance results for three different block sizes is shown in Table 6-2.
Table 6-2. Cache Blocking Performance of Large Matrix Multiply
m | n | l | block order | mbs | nbs | lbs | Seconds | MFLOPS |
|---|---|---|---|---|---|---|---|---|
1000 | 1000 | 1000 | ijk | 65 | 65 | 65 | 6.837563 | 292.5 |
1000 | 1000 | 1000 | ijk | 130 | 130 | 130 | 7.144015 | 280.0 |
1000 | 1000 | 1000 | ijk | 195 | 195 | 195 | 7.323006 | 273.1 |
For block sizes that limit cache conflicts, the performance of the blocked algorithm on this larger problem matches the performance of the unblocked code on a size that fits entirely in the secondary cache (the 200 × 200 case in Table 6-1). The perfex counts for the block size of 65 are as follows:
0 Cycles......................................... 1406325962 7.175132 21 Graduated floating point instructions.......... 1017594402 5.191808 25 Primary data cache misses...................... 82420215 3.788806 26 Secondary data cache misses.................... 1082906 0.408808 23 TLB misses..................................... 208588 0.072463 |
The secondary cache misses have been greatly reduced and the TLB misses are now almost nonexistent. From the times perfex estimates, the primary cache misses look to be a potential problem (as much as 3.8 seconds of the run time). However, the perfex estimate assumes no overlap of primary cache misses with other work. The R10000 CPU manages to achieve a lot of overlap on these misses, so this “typical” time is an overestimate. This can be confirmed by looking at the times of the other events and comparing them with the total time. The inner loop of matrix multiply generates one madd instruction per cycle, and perfex estimates the time based on this same ratio, so the floating point time should be pretty accurate. On the basis of this number, the primary cache misses can account for, at most, two seconds of time. (This points out that, when estimating primary cache misses, you have to make some attempt to account for overlap, either by making an educated guess or by letting the other counts lead you to reasonable bounds.)
Square blocks are used for convenience in the example above. But there is some overhead to starting up and winding down software pipelines, so rectangular blocks, in which the longest dimension corresponds to the inner loop, generally perform the best.
Cache blocking is one of the optimizations the Loop-Nest Optimizer performs. It chooses block sizes that are as large as it can fit into the cache without conflicts. In addition, it uses rectangular blocks to reduce software pipeline overhead and maximize data use from each cache line. If we simply compile the matrix multiply kernel with -O3 or -Ofast, which enable LNO, the unmodified code of Example 6-11 with 1000 × 1000 arrays achieves the same speed as the best run shown in Table 6-2.
But the LNO's automatic cache blocking will not solve all possible cache problems automatically. Some require manual intervention.
Fast Fourier transforms (FFT) algorithms present challenges on a cache-based machine because of their data access patterns, and because they usually involve arrays that are a power of two in size.
In a radix-2 FFT implementation, there are log(n) computational stages. In each stage, pairs of values are combined. In the first stage, these data are n/2 elements apart; in the second stage, data that are n/4 elements apart are combined; and so on. Figure 6-4 is a diagram showing the three stages of an 8-point transform.
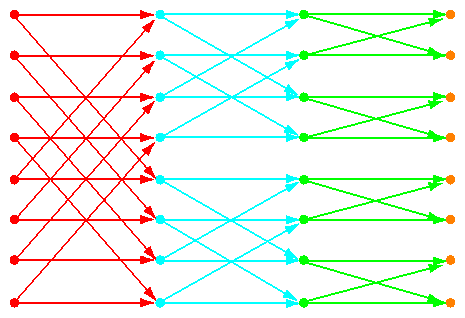
Both the size of the cache and the separation between combined data elements is a power of 2, so this data access pattern is likely to cause cache conflicts when n is large enough that the data do not fit in the primary cache. The R10000 caches are two-way set associative, and the two-way conflicts of the radix-2 algorithm are resolved without thrashing. However, a radix-2 implementation is not particularly efficient. A radix-4 implementation, in which four elements are combined at each stage, is much better: it uses half the number of stages—which means it makes half the memory accesses—and it requires fewer arithmetic operations. But cache address conflicts among four data elements are likely to cause thrashing.
The solution is to view the data as a two-dimensional, rather than a one-dimensional, array. Viewed this way, half the stages of the algorithm become FFTs across the rows of the array, while the remainder are FFTs down the columns. The column FFTs are cache friendly (assuming Fortran storage order), so nothing special needs to be done for them.
The row FFTs can suffer from cache thrashing. The easiest way to eliminate the thrashing is through the use of copying (see “Using Copying to Circumvent TLB Thrashing”).
An alternative that results in slightly better performance is to transpose the two-dimensional array, so that cache-thrashing row FFTs become cache-friendly column FFTs.This method is described at a high level here. However, library algorithms for FFT are already tuned to implement this method, so there is rarely a need to reimplement it.
To carry out the transpose, partition the two-dimensional array into square blocks. If the array itself cannot be a square, it can have twice as many rows as columns, or vice versa. In this case, it can be divided into two squares; these two squares can be transposed independently.
The number of columns in a block is chosen to be that number that will fit in the cache without conflict (two-way conflicts are all right because of the two-way set associativity). The square array is then transposed as follows:
Off-diagonal blocks in the first block-column and block-row are transposed and exchanged with one another. At this point, the entire first column will be in the cache.
Before proceeding with the rest of the transpose, perform the FFTs down the first block-column on the in-cache data.
Once these have been completed, exchange the next block-column and block-row. These are one block shorter than in the previous exchange; as a result, once the exchange is completed, not all of the second block-column is guaranteed to be in the cache. But most of it is, so FFTs are carried on this second block-column.
Continue exchanges and FFTs until all the row FFTs have been completed.
Now we are ready for the column FFTs, but there is a problem. The columns are now rows, and so the FFTs will cause conflicts. This is cured just as above: transpose the array, but to take greatest advantage of the data currently in the cache, proceed from right to left rather than from left to right.
When this transpose and the column FFTs have been completed, the work is almost done. A side effect of treating the one-dimensional FFT as a two-dimensional FFT is that the data end up transposed. Once again this is no problem; they can simply be transposed a third time.
Despite the three transpositions, this algorithm is significantly faster than allowing the row FFTs to thrash the cache, for data that don't fit in L1. But what about data that do not even fit in the secondary cache? Treat these larger arrays in blocks just as above, but if the FFTs down the columns of the transposed array don't fit in the primary cache, use another level of blocking and transposing for them.
Any well-tuned library routine for calculating FFT requires three separate algorithms: a textbook radix-4 algorithm for the small data sets that fit in L1; a single-blocked algorithm for the intermediate sizes; and a double-blocked algorithm for large data sets. The FFTs in CHALLENGE complib and SCSL are designed in just this way (see “Exploiting Existing Tuned Code” in Chapter 3).
Each level of the memory hierarchy is at least an order of magnitude faster than the level below it. The basic guidelines of good cache management follow from this: fetch data from memory only once, and, when data has been fetched, use every word of it before moving on. Perfectly innocent loops can violate these guidelines when they are applied to large arrays, with the result that the program slows down drastically.
In order to diagnose memory access problems, look for cases where a profile based on real-time sampling differs from an ideal-time profile, or use ssrun experiments to isolate the delayed routines. Then use perfex counts to find out which levels of the memory hierarchy are the problem. Once the problem is clear, it can usually be fixed by inverting the order of loops so as to proceed through memory with stride one, or by copying scattered data into a compact buffer, or by transposing to make rows into columns. Or, as the next chapter details, the compiler can often take care of the problem automatically.