When you compile with the highest optimization levels (-O3 or -Ofast), the compiler applies the Loop-Nest Optimizer (LNO). The LNO is capable of solving many cache-use problems automatically. When you know what it can do, you can use it to implement more sophisticated cache optimizations. This chapter surveys the features of the LNO in the following topics:
The LNO attempts to improve cache and instruction scheduling by performing high-level transformations on the source code of loops. Some of the changes the LNO can make have been presented as manual techniques (for example, “Diagnosing and Eliminating Cache Thrashing” in Chapter 6 and “Understanding Loop Fusion” in Chapter 6). Often the LNO applies such techniques automatically. Many LNO optimizations have effects beyond improved cache behavior. For example, software pipelining is more effective following some of the LNO transformations.
Much of the time you can accept the default actions of the LNO and get good results, but not all loop nest optimizations improve program performance all the time, so there are instances in which you can improve program performance by turning off some or all of the LNO options.
The LNO is turned on automatically when you use the highest level of optimization, -O3 or -Ofast. You send specific options to the LNO phase using the -LNO: compiler option group. The numerous sub-options are documented in the LNO(5) man page. To restrict the LNO from transforming loops while performing other optimizations, use -O3 -LNO:opt=0.
You can invoke specific LNO features directly in the source code. In C, you use pragma statements; in Fortran, directives. Source directives take precedence over the command-line options, but they can be disabled with the flag -LNO:ignore_pragmas.
When the compiler cannot determine the run-time size of data structures, it assumes they will not fit in the cache, and it carries out all the cache optimizations it is capable of. As a result, unnecessary optimizations can be performed on programs that are already cache-friendly. This typically occurs when the program uses an array whose size is not declared in the source. When this seems to be a problem, disable LNO transformations either for the entire module, or for a specific loop using a pragma or directive.
You can find out what transformations are performed by LNO, IPA, and other components of the compiler in a transformation file. This source file, emitted by the compiler, shows what the C or Fortran program looks like after the optimizations have been applied.
You cause a Fortran transformation file to be emitted by using the -flist or -FLIST:=ON flags; a C file will be emitted if the -clist or -CLIST:=ON flags are used. The transformation file is given the same name as the source file being compiled, but .w2f or .w2c is inserted before the .f or .c suffix; for example the transformation file for test.f is test.w2f.f. The compiler issues a diagnostic message indicating that the transformation file has been written and what its name is.
When IPA is enabled (“Requesting IPA” in Chapter 5), the transformation file is not written until the link step. Without IPA, the transformation file is written when the module is compiled.
To be as readable as possible, the transformation file uses as many of the variable names from the original source as it can. However, Fortran files are written using a free format in which lines begin with a tab character and do not adhere to the 72-character limit. The MIPSpro compilers compile this form correctly, but if you wish the file to be written using the standard 72-character Fortran layout, use the compiler option -FLIST:ansi_format=on.
The LNO's transformations complicate the code of loops. It is educational to see what it has done, and you can judge whether a particular loop justified the changes that are made to it.
In addition to the transformation file, recall that the compiler writes software pipelining report cards into the assembler file it emits when the -S option is used (see “Reading Software Pipelining Messages” in Chapter 5).
One of the noncache optimizations that the LNO performs is outer loop unrolling (sometimes called register blocking, because it tends to get a small block of array values into registers for multiple operations). Consider the subroutine in Example 7-1, which implements a matrix multiplication.
Example 7-1. Matrix Multiplication Subroutine
subroutine mm(a,lda,b,ldb,c,ldc,m,l,n)
integer lda, ldb, ldc, m, l, n
real*8 a(lda,l), b(ldb,n), c(ldc,n)
do j = 1, n
do k = 1, l
do i = 1, m
c(i,j) = c(i,j) + a(i,k)*b(k,j)
enddo
enddo
enddo
return
end
|
The SWP report card for this loop (assuming we compile with loop nest transformations turned off) is as shown in Example 7-2.
Example 7-2. SWP Report Card for Matrix Multiplication
#<swps> Pipelined loop line 7 steady state #<swps> #<swps> 50 estimated iterations before pipelining #<swps> 2 unrollings before pipelining #<swps> 6 cycles per 2 iterations #<swps> 4 flops ( 33% of peak) (madds count as 2) #<swps> 2 flops ( 16% of peak) (madds count as 1) #<swps> 2 madds ( 33% of peak) #<swps> 6 mem refs (100% of peak) #<swps> 3 integer ops ( 25% of peak) #<swps> 11 instructions ( 45% of peak) #<swps> 1 short trip threshold #<swps> 5 integer registers used. #<swps> 9 float registers used. |
Example 7-2 is just like the report card for the DAXPY operation (Example 5-7). It says that, in the steady state, this loop will achieve 33% of the peak floating-point rate, and the reason for this less-than-peak performance is that the loop is limited by loads and stores to memory. But is it really?
Software pipelining is applied to only a single loop. In the case of a loop nest, as in Example 7-1, the innermost loop is software pipelined. The inner loop is processed as if it were independent of the loops surrounding it. But this is not the case in general, and it is certainly not the case for matrix multiply. Consider the modified loop nest in Example 7-3.
Example 7-3. Matrix Multiplication Unrolled on Outer Loop
subroutine mm1(a,lda,b,ldb,c,ldc,m,l,n)
integer lda, ldb, ldc, m, l, n
real*8 a(lda,l), b(ldb,n), c(ldc,n)
do j = 1, n, nb
do k = 1, l
do i = 1, m
c(i,j+0) = c(i,j+0) + a(i,k)*b(k,j+0)
c(i,j+1) = c(i,j+1) + a(i,k)*b(k,j+1)
.
.
.
c(i,j+nb-1) = c(i,j+nb-1) + a(i,k)*b(k,j+nb-1)
enddo
enddo
enddo
return
end
|
Example 7-3 is the same as Example 7-1 except that the outermost loop has been unrolled nb times. (To be truly equivalent, the upper limit of the j-loop should be changed to n-nb+1 and an additional loop nest added to take care of leftover iterations when nb does not divide n evenly. These details have been omitted for ease of presentation.)
The thing to note about Example 7-3 in comparison Example 7-1 is that it processes nb different j-values in the inner loop, and a(i,k) needs to be loaded into a register only once for all these calculations. Because of the order of operations in Example 7-1, the same a(i,k) value needs to be loaded once for each of the c(i,j+0), ... c(i,j+nb-1) calculations, that is, a total of nb times. Thus, the outer loop unrolling has reduced by a factor of nb the number of times that elements of matrix a need to be loaded.
Now consider the modified loop nest in Example 7-4.
Example 7-4. Matrix Multiplication Unrolled on Middle Loop
subroutine mm2(a,lda,b,ldb,c,ldc,m,l,n)
integer lda, ldb, ldc, m, l, n
real*8 a(lda,l), b(ldb,n), c(ldc,n)
do j = 1, n
do k = 1, l, lb
do i = 1, m
c(i,j) = c(i,j) + a(i,k+0)*b(k+0,j)
c(i,j) = c(i,j) + a(i,k+1)*b(k+1,j)
.
.
.
c(i,j) = c(i,j) + a(i,k+lb-1)*b(k+lb-1,j)
enddo
enddo
enddo
return
end
|
Here, the middle loop has been unrolled lb times. Because of the unrolling, c(i,j) needs to be loaded and stored only once for all lb calculations in the inner loop. Thus, unrolling the middle loop reduces the loads and stores of the c matrix by a factor of lb.
If both outer and middle loops are unrolled simultaneously, then both the load and store reductions occur. This code is shown in Example 7-5.
Example 7-5. Matrix Multiplication Unrolled on Outer and Middle Loops
subroutine mm3(a,lda,b,ldb,c,ldc,m,l,n)
integer lda, ldb, ldc, m, l, n
real*8 a(lda,l), b(ldb,n), c(ldc,n)
do j = 1, n, nb
do k = 1, l, lb
do i = 1, m
c(i,j) = c(i,j+0) + a(i,k+0)*b(k+0,j+0)
c(i,j) = c(i,j+0) + a(i,k+1)*b(k+1,j+0)
.
.
.
c(i,j) = c(i,j+0) + a(i,k+lb-1)*b(k+lb-1,j+0)
c(i,j) = c(i,j+1) + a(i,k+0)*b(k+0,j+1)
c(i,j) = c(i,j+1) + a(i,k+1)*b(k+1,j+1)
.
.
.
c(i,j) = c(i,j+1) + a(i,k+lb-1)*b(k+lb-1,j+1)
.
.
.
c(i,j) = c(i,j+nb-1) + a(i,k+0)*b(k+0,j+0)
c(i,j) = c(i,j+nb-1) + a(i,k+1)*b(k+1,j+0)
.
.
.
c(i,j) = c(i,j+nb-1) + a(i,k+lb-1)*b(k+lb-1,j+nb-1)
enddo
enddo
enddo
return
end
|
The total operation count in the inner loop of Example 7-5 is as follows:
madds | lb * nb |
c loads | nb |
c stores | nb |
a loads | lb |
b loads | none—the b subscripts, j and k, do not vary in the inner loop; if there are enough machine registers, all needed b values are loaded in the middle loop and remain in registers throughout the inner loop. |
With no unrolling (nb = lb = 1), the inner loop is memory-bound. However, the number of madds grows quadratically with the unrolling, while the number of memory operations grows only linearly. By increasing the unrolling, it may be possible to convert the loop from memory-bound to floating point-bound.
Accomplishing this requires that the number of madds be at least as large as the number of memory operations. Although a branch and a pointer increment must also be executed by the CPU, the integer ALUs are responsible for these operations. For the R10000 CPU there are plenty of superscalar slots for them to fit in, so they don't figure in the selection of the unrolling factors. (This is not the case for R8000, because memory operations and madds together can fill up all the superscalar slots.)
The table in Figure 7-1 shows how changing the loop-unrolling counts lb and nb affect the software pipelining of Example 7-5.
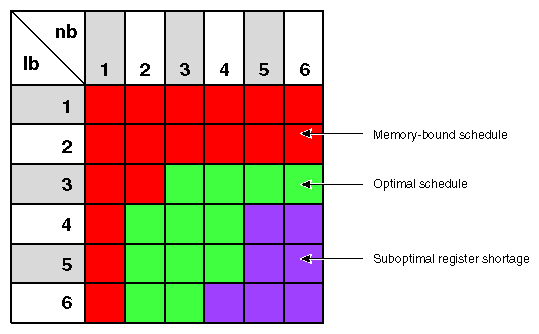
Several blocking choices produce schedules achieving 100% of floating-point peak. Keep in mind, though, that this reflects the steady-state performance of the inner loop for in-cache data. Some overhead is incurred in filling and draining the software pipeline, and this overhead varies depending on the unrolling values used. In addition, if the arrays don't fit in the cache, the performance will be substantially lower (unless the array blocking optimization is also applied).
Outer loop unrolling is one optimization that the LNO performs; it chooses the proper amount of unrolling for loop nests such as this matrix multiply kernel. For this particular case, if you compile with blocking turned off, the compiler chooses to unroll the j-loop by two and the k-loop by four, achieving a schedule that yields maximum performance. (With blocking turned on, the compiler blocks the matrix multiply in a more complicated transformation, so it is more difficult to rate the effectiveness of just the outer loop unrolling.)
Although the LNO often chooses the optimal amount of unrolling, several flags and a directive are provided for fine-tuning. The three principal flags that control outer loop unrolling are these:
-LNO:outer_unroll=n | Tells the compiler to unroll every outer loop for which unrolling is possible by exactly n. It either unrolls by n or not at all. If you use this flag, you cannot use the next two. 1 <= n <= 32 |
-LNO:outer_unroll_max=n | Tells the compiler it may unroll any outer loop by as many as n, but no more. 1 <= n <= 32 |
-LNO:outer_unroll_prod_ max=n | Says that the product of unrolling a given loop nest shall not exceed n. The default is 16. 1 <= n <= 32 |
These flags apply to all the loop nests in the file being compiled. To control the unrolling of an individual loop, you may use a directive or pragma. For Fortran, directive is
c*$* unroll (n) (f77) !*$* unroll (n) (f90) |
For C, the corresponding pragma is:
#pragma unroll (n) |
These directives apply to the loop immediately following the directive; when it is not innermost in its nest, outer loop unrolling is performed. The value of n must be at least one. If n = 1, no unrolling is performed. If n = 0, the default unrolling is applied.
When this directive immediately precedes an innermost loop, standard loop unrolling is done. This latter use is not recommended because the software pipeliner unrolls inner loops if it finds that beneficial; generally, the software pipeliner is the best judge of how much inner loop unrolling should be done.
The importance of stride-1 array accesses was explained under “Using Stride-One Access” in Chapter 6. In C, for example, the initialization loop in Example 7-6 touches memory with a stride of m.
Example 7-6. Simple Loop Nest with Poor Cache Use
for (i=0; i<n; i++) {
for (j=0; j<m; j++) {
a[j][i] = 0.0;
}
}
|
Memory access is more efficient when the loops are interchanged, as in Example 7-7.
Example 7-7. Simple Loop Nest Interchanged for Stride-1 Access
for (j=0; j<m; j++) {
for (i=0; i<n; i++) {
a[j][i] = 0.0;
}
}
|
This transformation is carried out automatically by the loop nest optimizer. However, the LNO has to consider more than just the cache behavior. What if, in Example 7-6, n=2 and m=100? (Or 1000, or 10000?) Then the array fits in cache, and the original loop order achieves full cache reuse. Worse, interchanging the loops puts the shorter i loop inside. Software pipeline code for any loop incurs substantial overhead; pipeline code for a loop with few iterations results, essentially, in all setup and no pipeline. It would be wrong of the compiler to transform the loops in this case.
Example 7-8 shows a different problem case.
Example 7-8. Loop Nest with Data Recursion
for (i=1; i<n; i++) {
for (j=0; j<m; j++) {
a[j][i] = a[j][i] + a[j][i-1];
}
}
|
Reversing the order of this loop nest produces nice cache behavior, but the recursion in i limits the performance that software pipelining can achieve for the inner loop. The LNO needs to consider the cache effects, the instruction scheduling, and loop overhead when deciding whether it should reorder such a loop nest. (In this case, the LNO assumes that m and n are large enough that optimizing for cache behavior is the best choice.)
If you know that the LNO has made the wrong loop interchange choice, you can instruct it to make a correction. Similar to the need to tell the compiler about the aliasing model (see “Understanding Aliasing Models” in Chapter 5), you can provide the LNO with the information it needs to make the right optimization. There are two ways to supply this extra information:
Turn off loop interchange.
Tell the compiler which order you want the loops in.
You can turn off loop interchange for the entire module with the -LNO:interchange=off flag. To turn it off for a single loop nest, precede the nest with a directive or pragma:
#pragma no interchange c*$* no interchange !*$* no interchange |
To specify a particular order for a loop nest, precede the loop nest with the following directive:
#pragma interchange (i, j [,k ...]) c*$* interchange (i, j [,k ...]) !*$* interchange (i, j [,k ...]) |
This directive instructs the compiler to try to order the loops so that the loop using index variable i is outermost, the one using j is inside it, and so on. The loops should be perfectly nested (that is, there should be no code between the do or for statements). The compiler will try to order the loops as requested, but it is not guaranteed.
Loop interchange and outer loop unrolling can be combined to solve some performance problems that neither technique can solve on its own. For example, consider the data-recursive loop nest in Example 7-8.
Interchange of this loop improves cache performance, but the recurrence on i limits software pipeline performance. If the j-loop is unrolled after interchange, the recurrence will be mitigated because there will be several independent streams of work that can be used to fill up the CPU's functional units. A simplified version of the interchanged, unrolled loop is shown in Example 7-9.
Example 7-9. Recursive Loop Nest Interchanged and Unrolled
for (j=0; j<m; j+=4) {
for (i=1; i<n; i++) {
a[j+0][i] = a[j+0][i] + a[j+0][i-1];
a[j+1][i] = a[j+1][i] + a[j+1][i-1];
a[j+2][i] = a[j+2][i] + a[j+2][i-1];
a[j+3][i] = a[j+3][i] + a[j+3][i-1];
}
}
|
The LNO considers interchange, unrolling, and blocking together to achieve the overall best performance.
The idea of cache blocking is explained under “Understanding Cache Blocking” in Chapter 6. The LNO performs cache blocking automatically. Thus a matrix multiplication like the one in Example 7-10 is automatically transformed into a blocked loop nest.
Example 7-10. Matrix Multiplication in C
for (j=0; j<n; j++) {
for (i=0; i<m; i++) {
for (k=0; k<l; k++) {
c[i][j] += a[i][k]*b[k][j];
}
}
}
|
The transformation of Example 7-10, as reported in the w2c file (see “Reading the Transformation File”), resembles Example 7-11.
Example 7-11. Cache-Blocked Matrix Multiplication
for (ii=0; ii<m; ii+=b1) {
for (kk=0; kk<l; kk+=b2) {
for (j=0; j<n; j++) {
for (i=ii; i<MIN(ii+b1-1,m); i++) {
for (k=kk; k<MIN(kk+b2-1,l); k++) {
c[i][j] += a[i][k]*b[k][j];
}
}
}
}
}
|
(The transformed code is actually more complicated than this: register blocking is used on the i- and j-loops; separate cleanup loops are generated, and the compiler takes multiple cache levels into consideration.)
For the majority of programs, these transformations are the proper optimizations. But in some cases, they can hurt performance. For example, if the data already fit in the cache, the blocking merely introduces overhead, and should be avoided. Several flags and directives are available to fine-tune the blocking that the LNO performs, as summarized in Table 7-1.
Table 7-1. LNO Options and Directives for Cache Blocking
Compiler Flag | Equivalent Directive or Pragma | Effect |
|---|---|---|
-LNO:blocking=off | C*$* NO BLOCKING !*$* NO BLOCKING | Prevent cache blocking of the whole module by using the flag or one loop nest by using the directive/pragma. |
-LNO:blocking_siz e =l1[,l2] | C*$* BLOCKING SIZE
[l1][,l2] | Specify block size for L1 cache, or both the L1 and L2 caches. |
(none) | C*$* BLOCKABLE (dovar,dovar...) !*$* BLOCKABLE (dovar,dovar...) | Specify a loop nest as blockable. |
If a loop operates on in-cache data, or if you have already done your own blocking, the LNO's blocking can be turned off completely or for a specific loop nest.
Occasionally you might find a reason to dictate a block size different from the default calculated by the LNO (examine the transformation file to find out the block size it used). You can specify a specific block size for all blocked loop nests in the module with the -LNO:blocking_size flag, or you can specify the blocking sizes for a specific loop nest using a directive. Example 7-12 shows a Fortran loop with a specified blocking size.
Example 7-12. Fortran Nest with Explicit Cache Block Sizes for Middle and Inner Loops
subroutine amat(x,y,z,n,m,mm)
real*8 x(1000,1000), y(1000,1000), z(1000,1000)
do k = 1, n
C*$* BLOCKING SIZE (0,200)
do j = 1, m
C*$* BLOCKING SIZE (0,200)
do i = 1, mm
z(i,k) = z(i,k) + x(i,j)*y(j,k)
enddo
enddo
enddo
return
end
|
Compiling Example 7-12, the LNO tries to make 200 x 200 blocks for the j- and i-loops. But there is no requirement that it interchange loops so that the k-loop is inside the other two. You can instruct the compiler that you want this done by inserting a directive with a block size of zero above the k-loop, as shown in Example 7-13.
Example 7-13. Fortran Loop with Explicit Cache Block Sizes and Interchange
subroutine amat(x,y,z,n,m,mm)
real*8 x(1000,1000), y(1000,1000), z(1000,1000)
C*$* BLOCKING SIZE (0,0)
do k = 1, n
C*$* BLOCKING SIZE (0,200)
do j = 1, m
C*$* BLOCKING SIZE (0,200)
do i = 1, mm
z(i,k) = z(i,k) + x(i,j)*y(j,k)
enddo
enddo
enddo
return
end
|
This produces a blocked loop nest with a form like that shown in Example 7-14.
Example 7-14. Transformed Fortran Loop
subroutine amat(x,y,z,n,m,mm)
real*8 x(1000,1000), y(1000,1000), z(1000,1000)
do jj = 1, m, 200
do ii = 1, mm, 200
do k = 1, n
do j = jj, MIN(m, jj+199)
do i = ii, MIN(mm, ii+199)
z(i,k) = z(i,k) + x(i,j)*y(j,k)
enddo
enddo
enddo
enddo
enddo
return
end
|
The second way to affect block sizes is to modify the compiler's cache model. The LNO makes blocking decisions at compile time using a fixed description of the cache system of the target processor board. Although the -Ofast=ip27 flag tells the compiler to optimize for current SN0 systems, it can't know what size the secondary cache will be in the system on which the program runs—1 MB, 4 MB, and larger secondary caches are available. As a result, it chooses to optimize for the lowest common denominator, the 1 MB cache.
A variety of flags tell the compiler to optimize for specific sizes and structures of L1, L2, and TLB caches. See the LNO(5) man page for a discussion.
The Loop Nest Optimizer can transform loops by loop fusion, loop fission, and loop peeling.
Loop fusion, described under “Understanding Loop Fusion” in Chapter 6, is a standard technique that can improve cache performance. The LNO performs this optimization automatically. It will even perform loop peeling, if necessary, to fuse loops. Example 7-15 shows a pair of adjacent loops that could be fused if they used the same range of indexes.
Example 7-15. Adjacent Loops that Cannot be Fused
subroutine ex715 (a,b,c,n)
real*8 a(n),b(n),c(n)
do i = 1, n
a(i) = 0.0
enddo
do i = 2, n-1
c(i) = 0.5 * (b(i+1) + b(i-1))
enddo
return
end
|
Loop peeling is the technique of removing iterations from the beginning and/or ending of a loop so that the index range will match that of another loop. The second loop in Example 7-15 may be reindexed in such a way that i traverses the range 1 to n-2. If the last two iterations of the first loop are peeled off, the two loops will have the same index range. These loops can then be fused. If the code shown in Example 7-15 is compiled with the options -O3 -flist, the LNO applies loop peeling and then loop fusion to produce the code segment of *.w2f.f output as shown in Example 7-16.
Example 7-16. Adjacent Loops Fused After Peeling
DO _I_0 = 1, (N + -2), 1
A(_I_0) = 0.0D00
C(_I_0 + 1) = (((B(_I_0) + B(_I_0 + 2))) * 5.0D-01)
END DO
IF(N .GE. 2) THEN
A(N + -1) = 0.0D00
ENDIF
IF(N .GE. 1) THEN
A(N) = 0.0D00
ENDIF
|
Although loop fusion improves cache performance, it has one potential drawback: It makes the body of the loop larger. Large loop bodies place greater demands on the compiler because more registers are required to schedule the loop efficiently. The compilation takes longer since the algorithms for register allocation and software pipelining grow faster than linearly with the size of the loop body. To balance these negative aspects, the LNO also performs loop fission, whereby large loops are broken into smaller, more manageable ones. Loop fission can require the invention of new variables. Consider Example 7-17, in which an intermediate value must be saved in a temporary location s over several statements.
The compiler can introduce an array of temporaries and then break the loop into two pieces, as shown in Example 7-18.
Example 7-18. Sketch of a Loop After Fission
for (j=0; j<n; j++) {
...
se[j] = ...
...
}
for (j=0; j<n; j++) {
...
... = se[j]
...
}
|
Example 7-19 shows an outer loop that controls two inner loops, neither of which uses stride-1 access. Cache behavior would be better if the loops could be reversed, but this cannot be done as the code stands.
Example 7-19. Loop Nest that Cannot Be Interchanged
for (j=0; j<n; j++) {
for (i=0; i<n; i++) {
b[i][j] = a[i][j];
}
for (i=0; i<n; i++) {
c[i][j] = b[i+m][j];
}
}
|
The LNO can apply loop fission to separate the two inner loops. Then it can interchange both, as shown in Example 7-20, and improve the cache behavior.
Example 7-20. Loop Nest After Fission and Interchange
for (i=0; i<n; i++) {
for (j=0; j<n; j++) {
b[i][j] = a[i][j];
}
}
for (i=0; i<n; i++) {
for (j=0; j<n; j++) {
c[i][j] = b[i+m][j];
}
}
|
Like most optimizations, loop fission presents some trade-offs. Some common subexpression elimination that occurs when all the code is in one loop can be lost when the loops are split. In addition, more loops mean more code, so instruction cache performance can suffer. Loop fission also needs to be balanced with loop fusion, which has its own benefits and liabilities.
The compiler attempts to mix both optimizations, as well as the others it performs, to produce the best code possible. Different mixtures of optimizations are required in different situations, so it is impossible for the compiler always to achieve the best performance. As a result, several flags and directives are provided to control loop fusion and fission, as listed in the LNO(5) man page.
As described under “Understanding Prefetching” in Chapter 6, the MIPS IV ISA contains prefetch instructions—instructions that move data from main memory into cache in advance of their use. This allows some or all of the time required to access the data to be hidden behind other work. One optimization the LNO performs is to insert prefetch instructions into your program. To see how this works, consider the simple reduction loop in Example 7-21.
If the loop in Example 7-21 is executed exactly as written, every secondary cache miss of the vector b stalls the CPU, because there is no other work to do. Now consider the modification in Example 7-22. In this example, “prefetch” is not a C statement; it indicates only that a prefetch instruction for the data at the specified address is issued at that point in the program.
Example 7-22. Simple Reduction Loop with Prefetch
for (i=0; i<n; i++) {
prefetch b[i+16];
a += b[i];
}
|
If b is an array of doubles, the address b[i+16] is one L2 cache line (128 bytes) ahead of the value that is being read in the current iteration. With this prefetch instruction inserted in the loop, each cache line is requested 16 iterations before it needs to be used. Prefetch instructions are ignored when they address a cache line that is already in-cache or on the way to cache.
Each iteration of the loop in Example 7-22 takes two cycles: the prefetch instruction and the load of b[i] each take one cycle and the addition is overlapped. Therefore, cache lines are prefetched 32 cycles (16, 2-cycle iterations) in advance of their use. The latency of a cache miss to local memory is approximately 60 cycles, and roughly half of this time will be overlapped with work on the previous cache line.
Example 7-22 issues a prefetch instruction for every load. For out-of-cache data, this is not bad because the time spent executing prefetch instructions would otherwise be spent waiting for the cache miss. However, if the loop processed only in-cache data, the performance would be half what it could be—half the instruction cycles would be needless prefetch instructions.
Only one prefetch instruction is needed per cache line, so it would be better to make prefetching conditional, as suggested in Example 7-23.
Example 7-23. Reduction with Conditional Prefetch
for (i=0; i<n; i++) {
if ((i % 16) == 0) prefetch b[i+16];
a += b[i];
}
|
This implementation issues just one prefetch instruction per cache line, but the instructions to implement the if-test costs more than issuing a single redundant prefetch, so it is no improvement. A better way to reduce prefetch overhead is to unroll the loop as shown in Example 7-24.
Example 7-24. Reduction with Prefetch Unrolled Once
for (i=0; i<n; i+=2) {
prefetch b[i+16];
a += b[i+0];
a += b[i+1];
}
|
In Example 7-24, prefetch instructions are issued only eight times per cache line, so the in-cache case pays for eight fewer redundant prefetch instructions. Further unrolling reduces them even more; in fact, unrolling by 16 eliminates all redundant prefetches (and drastically reduces the loop-management overhead).
The LNO automatically inserts prefetch instructions and uses unrolling to limit the number of redundant prefetch instructions it generates. It does not unroll the loop enough to eliminate the redundancies completely because the extra unrolling, like too much loop fusion, can have a negative effect on software pipelining. So, in prefetching, as in all its other optimizations, the LNO tries to achieve a delicate balance.
The LNO does one further thing to improve prefetch performance. Instead of prefetching just one cache line ahead, it prefetches two or more cache lines ahead so that most, if not all, of the memory latency is overlapped. Consider Example 7-25, a reduction loop unrolled with a two-ahead prefetch.
Example 7-25. Reduction Loop Unrolled with Two-Ahead Prefetch
for (i=0; i<n; i+=8) {
prefetch b[i+32];
a += b[i+0];
a += b[i+1];
a += b[i+2];
a += b[i+3];
a += b[i+4];
a += b[i+5];
a += b[i+6];
a += b[i+7];
}
|
This code prefetches two cache lines ahead, and makes only one redundant prefetch per cache line.
Prefetch instructions can be used to move data into the primary cache from either main memory or the secondary cache. However, the latency for fetching from L2 to L1 cache is small, eight to ten cycles, and it can usually be hidden without resorting to prefetch instructions. Consider Example 7-26, a reduction loop unrolled four times.
Example 7-26. Reduction Loop Unrolled Four Times
for (i=0; i<n; i+=4) {
a += b[i+0];
a += b[i+1];
a += b[i+2];
a += b[i+3];
}
|
By introducing a temporary register and reordering the instructions, this becomes
for (i=0; i<n; i+=4) {t = b[i+3];
a += b[i+0];
a += b[i+1];
a += b[i+2];
a += t;
}
|
Written this way, data in the next cache line, b[i+4](primary cache lines are 32 bytes), will be referenced several cycles before they are needed and so will be overlapped with operations on the current cache line.
This technique, called pseudo-prefetching, is the default way that the LNO hides the latency to the secondary cache. Since no prefetch instructions are used, it introduces no overhead for in-cache data. It does require the use of additional registers, however.
(To see how performance is affected by using real prefetches rather than pseudo-prefetches from the secondary cache, the flag -CG:pf_l1=true converts the pseudo-prefetches into genuine prefetch instructions.)
To provide the best performance for the majority of programs, the LNO generally assumes that any variable whose size it cannot determine is not cache-resident. It generates prefetch instructions in loops involving these data. Sometimes—for example, as a result of cache blocking—it can determine that certain cache misses will be satisfied from the secondary cache rather than main memory. For these misses the LNO uses pseudo-prefetching.
Although this default behavior works well most of the time, it may impose overhead in cases where the data fit in the cache, or where you have already put your own cache blocking into the program. Several flags and directives are provided to fine-tune such situations. For details, see the LNO(1) man page.
For standard vector code, automatic prefetching does a good job; but it can't do a perfect job for all code. One limitation is that it applies only to sequential access over dense arrays. If the program uses sparse or nonrectangular data structures, it is not always possible for the compiler to analyze where prefetch instructions should be placed. If your code does not access data in a regular fashion using loops, prefetches are also not used. Furthermore, data accessed in outer loops is not prefetched.
You can insert an explicit prefetch using the prefetch_ref pragma or directive, as shown in Example 7-27. This directive generates a single prefetch instruction to the memory location specified. This memory location does not have to be a compile-time constant expression; it can involve any program variables, for example, an indexed array element or a pointer expression. Automatic prefetching, if it is enabled, ignores all references to this array in the loop nest containing the directive; this allows you to use manual prefetching on some data in conjunction with automatic prefetching on other data.
Ideally, the program should execute precisely one prefetch instruction per cache line. The stride option allows you to specify how often the prefetch instruction is to be issued. For example, Example 7-27 shows a Fortran fragment that uses two-ahead manual prefetch.
Example 7-27. Fortran Use of Manual Prefetch
c*$* prefetch_ref=a(1)
c*$* prefetch_ref=a(1+16)
do i = 1, n
c*$* prefetch_ref=a(i+32), stride=16, kind=rd, level 2
sum = sum + a(i)
enddo
|
In Example 7-27, the stride=16 clause in the directive tells the compiler that it should insert a prefetch instruction only once every 16 iterations. As with automatic prefetching, the compiler unrolls the loop and places just one prefetch instruction in the loop body. Because there is a limit to the amount of unrolling that is beneficial, the compiler may choose to unroll less than specified in the stride value.
The MIPS IV prefetch instructions allow you to specify whether the prefetched line is intended to be read from or written into. For the R10000 CPU, this information can be used to stream some data through one associative set of the cache while leaving other data in the second set; this can result in fewer cache conflicts. Thus, it is a good idea to specify whether the prefetched data are to read or written. If it will be both read and written, specify that it is written.
You can specify the level in the memory hierarchy to prefetch with the level clause. Most often you need only prefetch from main memory into L2, so the default level of 2 is correct.
You can use the size clause to tell the compiler how much space in the cache will be used by the array being manually prefetched. This value helps the compiler decide which other arrays should be prefetched automatically. If the compiler believes there is a lot of available cache space, other arrays are less likely to be prefetched because there is room for them—or, at least, blocks of them—to reside in the cache. On the other hand, if the compiler believes the other arrays will not fit in the cache, it will generate code that streams them though the cache and uses prefetch instructions to improve the out-of-cache performance. So, when using the prefetch_ref directive, if you find that other arrays are not automatically being prefetched, use the size clause with a large value to encourage the compiler to generate prefetch instructions for them. Conversely, if other arrays are being prefetched and should not be, a small size value may encourage the compiler not to prefetch the other arrays.
As described under “Understanding Cache Thrashing” in Chapter 6, an unlucky alignment of arrays can cause significant performance penalties from cache thrashing. This is particularly likely when array dimensions are a power of 2. Fortunately, the LNO automatically pads arrays to eliminate or reduce such cache conflicts. Local variables, such as those in the typical code in Example 7-28, are spaced out so that cache thrashing does not occur.
Example 7-28. Typical Fortran Declaration of Local Arrays
subroutine abcdmax(a,b,c,d,max)
dimension a(max), b(max), c(max), d(max)
do i = 1, max
a(i) = b(i) + c(i)*d(i)
enddo
return
end
|
Note that if you compile Example 7-28 with -flist, you won't see padding explicitly in the listing file.
The compiler also pads C global variables, and common blocks such as the following when you use the highest optimization level, -O3 or -Ofast:
subroutine sub
common a(512,512), b(512*512)
|
The compiler does this by putting each variable in its own common block. This optimization only occurs when both of the following are true:
All routines that use the common block are compiled at -O3.
The compiler detects no inconsistent uses of the common block across routines.
If any routine that uses the common block is compiled at an optimization level lower than -O3, or if there are inconsistent uses, the splitting, and hence the padding, will not be performed. Instead, the linker pastes the common blocks back together, and the original unsplit version is used. Thus, this implementation of common block padding is perfectly safe, even if you make a mistake in usage.
One programming practice causes problems. If out-of-bounds array accesses are made, wrong answers can result. For example, one improper but not uncommon usage is to operate on all data in a common block as if they were contiguous, as in Example 7-29.
Example 7-29. Common, Improper Fortran Practice
subroutine sub
common a(512*512), b(512,512)
do i = 1, 2*512*512
a(i) = 6.0
enddo
return
end
|
In this example, both a and b are zeroed out by indexing only through a, under the assumption that array b immediately follows a in memory. (Note that this is not legal Fortran.) This code will not work as expected if common block padding is used. There are three ways to deal with problems of this type:
Compile routines using this common block at -O2 instead of -O3. This is not recommended because it is likely to hurt performance.
Compile using the flag -OPT:reorg_common=off. This disables the common block padding optimization. Although it compensates for the improper coding style, it means other common blocks are also not padded and may result in less than optimal performance.
Fix the code so that it is legal Fortran.
Naturally, the last alternative is recommended. To detect such programming mistakes, use the -check_bounds flag. Be sure to test your Fortran programs with this flag if you encounter incorrect answers only after compiling with -O3.
If you use interprocedural analysis, the compiler can also perform padding inside common block arrays. For example, in a common block declared as follows, the compiler pads the first dimension as part of IPA optimization:
common a(1024,1024)
|
The LNO performs two other optimizations on loops: gather-scatter and converting scalar math intrinsics to vector calls.
The gather-scatter optimization is best explained via an example. In the code fragment in Example 7-30, the loop can be software pipelined even though there is a branch inside it; the resulting code, however, is not fast.
Example 7-30. Fortran Loop to which Gather-Scatter Is Applicable
subroutine fred(a,b,c,n)
real*8 a(n), b(n), c(n)
do i = 1, n
if (c(i) .gt. 0.0) then
a(i) = c(i)/b(i)
c(i) = c(i)*b(i)
b(i) = 2*b(i)
endif
enddo
return
end
|
Code of this type has two sources of inefficiency. First, the fact that some array elements are skipped makes it impossible for the software pipeline to work efficiently. Second, each time the if condition fails, the CPU performs a few instructions speculatively before the failure is evident. CPU cycles are wasted on these instructions and on internal resynchronization.
With compiler optimization -O3, the compiler uses LNO optimization to produce a faster implementation, which separates the scan of the array and the processing of selected elements into two loops. A portion of the output file, fred.w2f.f, produced by the command, f90 -O3 -flist -c fred.f, is shown in Example 7-31.
Example 7-31. Fortran Loop with Gather-Scatter Applied
inc_0 = 0
DO I = seonly0I, MIN(N, (seonly0I + 999)), 1
deref_gs1_I4(inc_0 + 1) = I
IF(C(I) .GT. 0.0D00) THEN
inc_0 = (inc_0 + 1)
ENDIF
END DO
DO ind_0 = 0, inc_0 + -1, 1
I_gs_rn_1 = deref_gs1_I4(ind_0 + 1)
A(I_gs_rn_1) = (C(I_gs_rn_1) / B(I_gs_rn_1))
C(I_gs_rn_1) = (B(I_gs_rn_1) * C(I_gs_rn_1))
B(I_gs_rn_1) = (B(I_gs_rn_1) * 2.0D00)
END DO
|
Here, deref_gs1_I4 is a scratch array allocated on the stack by the compiler.
This transformed code first scans through the data, gathering the indices for which the conditional test is true. Then the second loop does the work on the gathered data. The condition is true for all these iterations, so the if statement can be removed from the second loop. The loop can now be efficiently pipelined and unused speculative instructions are avoided.
By default, the compiler performs this optimization for loops that have non-nested if statements. For loops that have nested if statements, the optimization can be tried by using the flag -LNO:gather_scatter=2. For these loops, the optimization is less likely to be advantageous, so this is not the default. In some instances, this optimization could slow down the code (for example, if the loop iterates over a small range). In such cases, disable this optimization completely with the flag -LNO:gather_scatter=0.
In addition to the gather-scatter optimization, the LNO also converts scalar math intrinsic calls into vector calls so they can take advantage of the vector math routines in the math library (see “Standard Math Library” in Chapter 3).
Example 7-32. Fortran Loop That Processes a Vector
subroutine vfred(a)
real*8 a(200)
do i = 1, 200
a(i) = a(i) + cos(a(i))
enddo
return
end
|
The loop in Example 7-32 applies a scalar math function, cos(), to a stride-1 vector. The LNO can convert it into a call on the vector routine vcos() similar to the code in Example 7-33.
Example 7-33. Fortran Loop Transformed to Vector Intrinsic Call
CALL vcos$(A(1), deref_se1_F8(1), %val(200), %val(1), %val(1))
DO i = 1, 200, 1
a(i) = (a(i) + deref_se1_F8(i))
END DO
|
As documented in the math(3) man page, the input and output arrays of the vector routines must not overlap. The code in Example 7-32 stores its result back into array a. In order to call the vector routine, the compiler creates deref_se1_F8, a scratch array allocated on the stack, to hold the vector output. The vector routine is enough faster than a scalar loop to make up for the overhead of copying.
The results of using a vector routine may not agree, bit for bit, with the result of the scalar routines. If for some reason it is critical to have numeric agreement precise to the last bit, disable this optimization with the flag -LNO:vintr=off.
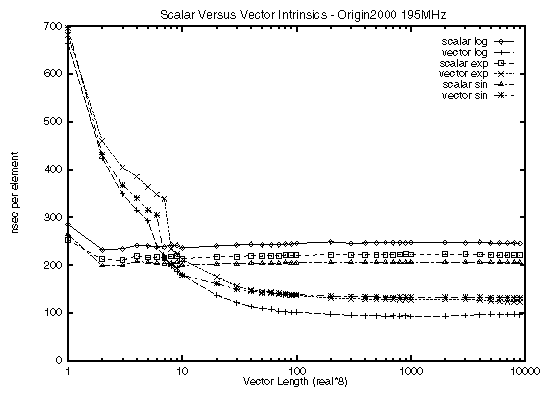
The actual performance of the vector instrinsic functions is graphed in Figure 7-2. As it shows, the vector functions are always faster than the scalar functions when the vector has at least ten elements.
The Loop Nest Optimizer (LNO) transforms loops and nests of loops for better cache access and for more effective software pipelining. It performs many cache access modifications automatically. You can help the LNO generate the fastest code in the following ways:
In C code, use the most aggressive aliasing model you can (see “Understanding Aliasing Models” in Chapter 5).
Use the ivdep directive with those loops for which it is valid (see “Breaking Other Dependencies” in Chapter 5).
Avoid equivalence statements in Fortran code; they introduce aliasing and prevent padding and other optimizations.
Avoid goto statements; they obscure control flow and prevent the compiler from analyzing your code effectively.
Declare and use common blocks consistently in every module so that the LNO can properly pad them.
Don't unroll loops by hand (unless you don't want the compiler to unroll them).
Don't violate the Fortran standard. Out-of-bounds array references can cause the common block padding optimizations to generate wrong results.