You can view the system status in the following ways:
| Note: Administrative tasks must be performed using the GUI when it is connected to a CXFS administration node (a node that has the cluster_admin software package installed) or using the cmgr(1M) command when logged in to a CXFS administration node. Administration commands must be run on a CXFS administration node; the cxfs_info(1M) status command is run on a client-only node. |
Monitor log files in /var/cluster/ha/logs.
Use the GUI or the tail(1) command to view the end of the SYSLOG file.
Keep continuous watch on the state of a cluster using the GUI view area or the cluster_status(1M) command.
Query the status of an individual node or cluster using either the GUI or the cmgr(1M) command.
Manually test the filesystems with the ls(1) command.
Monitor the system with Performance Co-Pilot (PCP). You can use PCP to monitor the read/write throughput and I/O load distribution across all disks and for all nodes in the cluster. The activity can be visualized, used to generate alarms, or archived for later analysis. You can also monitor XVM statistics. See the Performance Co-Pilot User's and Administrator's Guide, the Performance Co-Pilot Programmer's Guide, and the dkvis(1), pmie(1), pmieconf(1), and pmlogger(1) man pages.

Note: You must manually install the XVM statistics for the PCP package; it is not installed by default. See Chapter 2, “IRIX Systems: Installation of CXFS Software and System Preparation ”.
The following sections describe the procedures for performing some of these tasks.
You should monitor the following log files listed for problems:
/var/adm/SYSLOG (system log; look for a Membership delivered message to indicate that a cluster was formed)
/var/cluster/ha/log/cad_log (events from the GUI and clconfd)
/var/cluster/ha/log/clconfd_hostname (kernel status)
/var/cluster/ha/log/cli_hostname (command line interface log)
/var/cluster/ha/log/cmond_log (monitoring of other daemons)
/var/cluster/ha/log/crsd_hostname (reset daemon log)
/var/cluster/ha/log/diags_hostname (output of the diagnostic tools such as the serial and network connectivity tests)
/var/cluster/ha/log/fs2d_log (cluster database membership status)
/var/sysadm/salog (system administration log, which contains a list of the commands run by the GUI)
If the disk is filling with log messages, see “Log File Management” in Chapter 6.
| Caution: Do not change the names of the log files. If you change the names, errors can occur. |
You can monitor system status with the GUI or the cluster_status(1M), clconf_info, cmgr(1M), or cxfs_info(1M) commands. Also see “Key to Icons and States” in Chapter 4
The easiest way to keep a continuous watch on the state of a cluster is to use the view area and choose the following:
Edit -> Expand All
The cluster status can be one of the following:
ACTIVE, which means the cluster is up and running.
INACTIVE, which means the start CXFS services task has not been run.
ERROR, which means that some nodes are in a DOWN state; that is, the cluster should be running, but it is not.
UNKNOWN, which means that the state cannot be determined because CXFS services are not running on the node performing the query. For more information, see in “Node Status”.
You can use the cluster_status command to monitor the cluster using a curses(3X) interface. For example, the following shows a three-node cluster with a single filesystem mounted and the help text displayed:
# /var/cluster/cmgr-scripts/cluster_status
+ Cluster=cxfs6-8 FailSafe=Not Configured CXFS=ACTIVE 15:15:33
Nodes = cxfs6 cxfs7 cxfs8
FailSafe =
CXFS = UP UP UP
CXFS DevName MountPoint MetaServer Status
/dev/cxvm/concat0 /concat0 cxfs7 UP
+-------+ cluster_status Help +--------+
| on s - Toggle Sound on event |
| on r - Toggle Resource Group View |
| on c - Toggle CXFS View |
| h - Toggle help screen |
| i - View Resource Group detail |
| q - Quit cluster_status |
+--- Press 'h' to remove help window --+
----------------------------------------------------------------
cmd('h' for help) > |
The above shows that a sound will be activated when a node or the cluster changes status. (The r and i commands are not relevant for CXFS; they are of use only with FailSafe.) You can override the s setting by invoking cluster_status with the -m (mute) option.
The following output shows that the CXFS cluster is up and that cxfs7 is the metadata server for the /dev/cxvm/concat0 XVM volume:
cxfs6# /var/cluster/cmgr-scripts/cluster_status
+ Cluster=cxfs6-8 FailSafe=Not Configured CXFS=ACTIVE 15:18:28
Nodes = cxfs6 cxfs7 cxfs8
FailSafe =
CXFS = UP UP UP
CXFS DevName MountPoint MetaServer Status
/dev/cxvm/concat0 /concat0 cxfs7 UP |
| Note: The cluster_status command can display no more than 128 CXFS filesystems. |
If the cluster is up, you can see detailed information by using /usr/cluster/bin/clconf_info.
For example:
cxfs6 # clconf_info Membership since Thu Mar 1 08:15:39 2001 Node NodeId Status Age Incarnation CellId cxfs6 6 UP 0 0 2 cxfs7 7 UP 0 0 1 cxfs8 8 UP 0 0 0 1 CXFS FileSystems /dev/cxvm/concat0 on /concat0 enabled server=(cxfs7) 2 client(s)=(cxfs8,cxfs6) |
To query node and cluster status, use the following cmgr(1M) command:
cmgr> show status of cluster cluster_name |
The cxfs_info command provides information about the cluster status, node status, and filesystem status. cxfs_info(1M) is run from a client-only node:
IRIX client-only node:
/usr/cluster/bin/cxfs_info
Solaris:
/usr/cxfs_cluster/bin/cxfs_info
Windows (from a command prompt or from Explorer):
\Program Files\CXFS\cxfs_info
You can use the -e option to display information continuously, updating the screen when new information is available; use the -c option to clear the screen between updates. For less verbose output, use the -q (quiet) option.
For example, on a Solaris node named cxfssun4:
cxfssun4 # /usr/cxfs_cluster/bin/cxfs_info
cxfs_client status [timestamp Sep 03 12:16:06 / generation 18879]
Cluster:
sun4 (4) - enabled
Local:
cxfssun4 (2) - enabled, state: stable, cms: up, xvm: up, fs: up
Nodes:
cxfs27 enabled up 1
cxfs28 enabled up 0
cxfsnt4 enabled up 3
cxfssun4 enabled up 2
mesabi enabled DOWN 4
Filesystems:
lun1s0 enabled mounted lun1s0 /lun1s0
mirror0 disabled unmounted mirror0 /mirror0 |
To query the status of a node, you provide the logical name of the node. The node status can be one of the following:
UP, which means that CXFS services are started and the node is part of the CXFS kernel membership. For more information, see “Membership Quorums” in Chapter 1.
DOWN, which means that although CXFS services are started and the node is defined as part of the cluster, the node is not in the current CXFS kernel membership.
INACTIVE, which means that the start CXFS services task has not been run.
UNKNOWN, which means that the state cannot be determined because CXFS services are not running on the node performing the query.
State information is exchanged by daemons that run only when CXFS services are started. A given CXFS administration node must be running CXFS services in order to report status on other nodes.
For example, CXFS services must be started on node1 in order for it to show the status of node2. If CXFS services are started on node1, then it will accurately report the state of all other nodes in the cluster. However, if node1's CXFS services are not started, it will report the following states:
INACTIVE for its own state, because it can determine that the start CXFS services task has not been run
UNKNOWN as the state of all other nodes, because the daemons required to exchange information with other nodes are not running, and therefore state cannot be determined
The following sections provide different methods to monitor node status. Also see “Check Cluster/Node/Filesystem Status with cxfs_info”.
You can use the view area to monitor the status of the nodes. Select View: Nodes in Cluster.
To determine whether a node applies to CXFS, to FailSafe, or both, double-click on the node name in the display. Figure 9-1 shows an example of a node that is of type CXFS only.
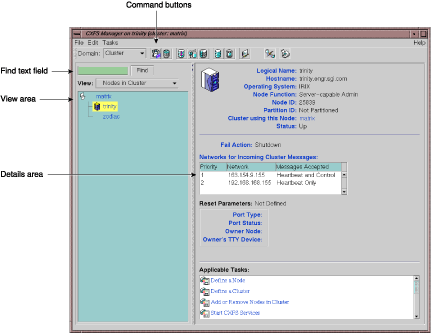
To query node status, use the following cmgr(1M) command:
cmgr> show status of node node_name |
You can use the cluster_status command to monitor the status of the nodes in the cluster. For example, the following output shows that all three nodes in the CXFS cluster are up:
cxfs6# /var/cluster/cmgr-scripts/cluster_status
+ Cluster=cxfs6-8 FailSafe=Not Configured CXFS=ACTIVE 15:15:33
Nodes = cxfs6 cxfs7 cxfs8
FailSafe =
CXFS = UP UP UP |
If you toggle the c command to off, the CXFS line will disappear.
When CXFS is running, you can determine whether the system controller on a node is responding by using the following cmgr(1M) command:
cmgr> admin ping node node_name |
This command uses the CXFS daemons to test whether the system controller is responding.
You can verify reset connectivity on a node in a cluster even when the CXFS daemons are not running by using the standalone option of the admin ping command:
cmgr> admin ping standalone node node_name |
This command calls the ping command directly to test whether the system controller on the indicated node is responding.
| Note: This feature assumes that you have installed the pcp_eoe and pcp_eoe.sw.xvm packages; see Chapter 2, “IRIX Systems: Installation of CXFS Software and System Preparation ”. |
You can use Performance Co-Pilot (PCP) to monitor XVM statistics. To do this, you must enable the collection of statistics:
To enable the collection of statistics for the local host, enter the following:
$ pmstore xvm.control.stats_on 1
To disable the collection of statistics for the local host, enter the following:
$ pmstore xvm.control.stats_on 0
You can gather XVM statistics in the following ways:
By using the pmval(1) command from the pcp_eoe.sw.monitor package. This command is provided with the IRIX release and can be used to produce an ASCII report of selected metrics from the xvm group in the PCP namespace of available metrics.
By using the optional pmgxvm(1) command provided with the PCP pcp.sw.monitor package (an optional product available for purchase).
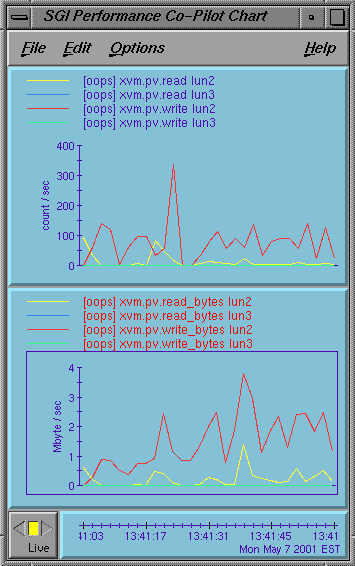
If you have the pcp.sw.monitor package, you can also use the pmchart(1) command to view time-series data in the form of a moving graph. Figure 9-2 shows an example.
To check the current fencing status, select View: Switches in the GUI view area, or use the admin fence query command in cmgr(1M), or use the hafence(1M) command as follows:
/usr/cluster/bin/hafence -q |
For example, the following output shows that all nodes are enabled.
# /usr/cluster/bin/hafence -q
Switch[0] "ptg-brocade" has 8 ports
Port 1 type=FABRIC status=enabled hba=210000e08b0102c6 on host thunderbox
Port 2 type=FABRIC status=enabled hba=210000e08b01fec5 on host whack
Port 5 type=FABRIC status=enabled hba=210000e08b027795 on host thump
Port 6 type=FABRIC status=enabled hba=210000e08b019ef0 on host thud |
A fenced port shows status=disabled. For example:
# /usr/cluster/bin/hafence -q
Switch[0] "brocade04" has 16 ports
Port 4 type=FABRIC status=enabled hba=210000e08b0042d8 on host o200c
Port 5 type=FABRIC status=enabled hba=210000e08b00908e on host cxfs30
Port 9 type=FABRIC status=enabled hba=2000000173002d3e on host cxfssun3 |
Verbose (-v) output would be as follows:
# /usr/cluster/bin/hafence -v
Switch[0] "brocade04" has 16 ports
Port 0 type=FABRIC status=enabled hba=2000000173003b5f on host UNKNOWN
Port 1 type=FABRIC status=enabled hba=2000000173003adf on host UNKNOWN
Port 2 type=FABRIC status=enabled hba=210000e08b023649 on host UNKNOWN
Port 3 type=FABRIC status=enabled hba=210000e08b021249 on host UNKNOWN
Port 4 type=FABRIC status=enabled hba=210000e08b0042d8 on host o200c
Port 5 type=FABRIC status=enabled hba=210000e08b00908e on host cxfs30
Port 6 type=FABRIC status=enabled hba=2000000173002d2a on host UNKNOWN
Port 7 type=FABRIC status=enabled hba=2000000173003376 on host UNKNOWN
Port 8 type=FABRIC status=enabled hba=2000000173002c0b on host UNKNOWN
Port 9 type=FABRIC status=enabled hba=2000000173002d3e on host cxfssun3
Port 10 type=FABRIC status=enabled hba=2000000173003430 on host UNKNOWN
Port 11 type=FABRIC status=enabled hba=200900a0b80c13c9 on host UNKNOWN
Port 12 type=FABRIC status=disabled hba=0000000000000000 on host UNKNOWN
Port 13 type=FABRIC status=enabled hba=200d00a0b80c2476 on host UNKNOWN
Port 14 type=FABRIC status=enabled hba=1000006069201e5b on host UNKNOWN
Port 15 type=FABRIC status=enabled hba=1000006069201e5b on host UNKNOWN |
To check current failure action settings, use the show node nodename command in cmgr or use the cms_failconf command as follows:
/usr/cluster/bin/cms_failconf -q |
For example, the following output shows that all nodes except thud have the system default failure action configuration. The node thud has been configured for fencing and resetting.
# cms_failconf -q
CMS failure configuration:
cell[0] whack Reset Shutdown
cell[1] thunderbox Reset Shutdown
cell[2] thud Fence Reset
cell[3] thump Reset Shutdown
cell[4] terry Reset Shutdown
cell[5] leesa Reset Shutdown |