This chapter discusses the following:
| Note: You should read through this entire book, especially Chapter 10, “Troubleshooting”, before attempting to install and configure a CXFS cluster. |
CXFS is clustered XFS, a clustered filesystem for high-performance computing environments.
CXFS allows groups of computers to coherently share XFS filesystems among multiple hosts and storage devices while maintaining high performance. CXFS runs on storage area network (SAN) disks, such as Fibre Channel. A SAN is a high-speed, scalable network of servers and storage devices that provides storage resource consolidation, enhanced data access/availability, and centralized storage management. CXFS filesystems are mounted across the cluster by CXFS management software. All files in the filesystem are available to all nodes that mount the filesystem.
CXFS and IRIS FailSafe share the same infrastructure.
CXFS uses the same filesystem structure as XFS. A CXFS filesystem is initially created using the same mkfs(1M) command used to create standard XFS filesystems.
The primary difference between XFS and CXFS filesystems is the way in which filesystems are mounted and managed:
In XFS:
In CXFS:
Filesystems are mounted using the CXFS Manager graphical user interface (GUI) or the cmgr(1M) command.
A filesystem is accessible from all hosts (nodes) in the cluster. CXFS filesystems are mounted across the cluster by CXFS management software. All files in the filesystem are visible to all hosts that mount the filesystem.
One node coordinates the updating of metadata (information that describes a file, such as the file's name, size, location, and permissions) on behalf of all nodes in a cluster; this is known ans the metadata server. There is one active metadata server per CXFS filesystem; there can be multiple active metadata servers in a cluster, one for each CXFS filesystem.
The filesystem information is stored in the cluster database (CDB), which contains persistent static configuration information about the filesystems, nodes, and cluster. The CXFS cluster daemons manage the distribution of multiple synchronized copies of the cluster database across the CXFS administration nodes in the pool. The administrator can view the database and modify it using the CXFS Manager GUI or the cmgr(1M) command.
The GUI shows the static and dynamic state of the cluster. For example, suppose the database contains the static information that a filesystem is enabled for mount; the GUI will display the dynamic information showing one of the following:
An icon indicating that the filesystem is mounted (the static and dynamic states match)
An icon indicating that the filesystem is ready to be mounted but the procedure cannot complete because CXFS services have not been started (the static and dynamic states do not match, but this is expected under the current circumstances)
An error (red) icon indicating that the filesystem is supposed to be mounted (CXFS services have been started), but it is not (the static and dynamic states do not match, and there is a problem)
The following commands can also be used to view the cluster state:
cmgr(1M) (used on a CXFS administration node) shows the static cluster state
clconf_info and cluster_status(1M) (used on a CXFS administration node) show both the static and dynamic cluster states
cxfs_info command on client-only nodes provides status information
Information is not stored in the /etc/fstab file. (However, the CXFS filesystems do show up in the /etc/mtab file.) For CXFS, information is instead stored in the cluster database.
XFS features that are also present in CXFS include the following:
Reliability and fast (subsecond) recovery of a log-based filesystem.
64-bit scalability to 9 million terabytes (9 exabytes) per file.
Speed: high bandwidth (megabytes per second), high transaction rates (I/O per second), and fast metadata operations.
Dynamically allocated metadata space.
Quotas. You can administer quotas anywhere in the cluster just as if this were a regular XFS filesystem.
Filesystem reorganizer (defragmenter), which must be run from the CXFS metadata server for a given filesystem. See the fsr_xfs(1M) man page.
Restriction of access to files using file permissions and access control lists (ACLs). You can also use logical unit (lun) masking or physical cabling to deny access from a specific host to a specific set of disks in the SAN.
CXFS preserves these underlying XFS features while distributing the I/O directly between the disks and the hosts. The efficient XFS I/O path uses asynchronous buffering techniques to avoid unnecessary physical I/O by delaying writes as long as possible. This allows the filesystem to allocate the data space efficiently and often contiguously. The data tends to be allocated in large contiguous chunks, which yields sustained high bandwidths.
The XFS directory structure is based on B-trees, which allow XFS to maintain good response times, even as the number of files in a directory grows to tens or hundreds of thousands of files.
For more information about XFS features, see IRIX Admin: Disks and Filesystems.
You should use CXFS when you have multiple hosts running applications that require high-bandwidth access to common filesystems.
CXFS performs best under the following conditions:
All processes that perform reads/writes for a given file reside on the same host
Multiple processes on multiple hosts read the same file
Direct-access I/O is used for reads/writes for multiple processes on multiple hosts
Large files and file accesses are being used
For most filesystem loads, the scenarios above represent the bulk of the file accesses. Thus, CXFS delivers fast local file performance. CXFS is also useful when the amount of data I/O is larger than the amount of metadata I/O. CXFS is faster than NFS because the data does not go through the network.
CXFS may not give optimal performance under the following circumstances, and extra consideration should be given to using CXFS in these cases:
When exporting a CXFS filesystem via NFS, be aware that performance will be much better when the export is performed from a CXFS metadata server than when it is performed from a CXFS client.
When access would be as slow with CXFS as with network filesystems, such as with the following:
Small files
Low bandwidth
Lots of metadata transfer
Metadata operations can take longer to complete through CXFS than on local filesystems. Metadata transaction examples include the following:
Opening and closing a file
Changing file size (usually extending a file)
Creating and deleting files
Searching a directory
In addition, multiple processes on multiple hosts that are reading and writing the same file using buffered I/O can be slower with CXFS than when using a local filesystem. This performance difference comes from maintaining coherency among the distributed file buffers; a write into a shared, buffered file will invalidate data (pertaining to that file) that is buffered in other hosts.
When distributed applications write to shared files that are memory mapped.
Network filesystems and CXFS filesystems perform many of the same functions, but with important performance and functional differences noted here.
Accessing remote files over local area networks (LANs) can be significantly slower than accessing local files. The network hardware and software introduces delays that tend to significantly lower the transaction rates and the bandwidth. These delays are difficult to avoid in the client-server architecture of LAN-based network filesystems. The delays stem from the limits of the LAN bandwidth and latency and the shared path through the data server.
LAN bandwidths force an upper limit for the speed of most existing shared filesystems. This can be one to several orders of magnitude slower than the bandwidth possible across multiple disk channels to local or shared disks. The layers of network protocols and server software also tend to limit the bandwidth rates.
A shared fileserver can be a bottleneck for performance when multiple clients wait their turns for data, which must pass through the centralized fileserver. For example, NFS and Samba servers read data from disks attached to the server, copy the data into UDP/IP or TCP/IP packets, and then send it over a LAN to a client host. When many clients access the server simultaneously, the server's responsiveness degrades.
CXFS is a clustered XFS filesystem that allows for logical file sharing, as with network filesystems, but with significant performance and functionality advantages. CXFS runs on top of a storage area network (SAN), where each host in the cluster has direct high-speed data channels to a shared set of disks.
CXFS has the following unique features:
A peer-to-disk model for the data access. The shared files are treated as local files by all of the hosts in the cluster. Each host can read and write the disks at near-local disk speeds; the data passes directly from the disks to the host requesting the I/O, without passing through a data server or over a local area network (LAN). For the data path, each host is a peer on the SAN; each can have equally fast direct data paths to the shared disks.
Therefore, adding disk channels and storage to the SAN can scale the bandwidth. On large systems, the bandwidth can scale to gigabytes and even tens of gigabytes per second. Compare this with a network filesystem with the data typically flowing over a 1- to 100-MB-per-second LAN.
This peer-to-disk data path also removes the file-server data-path bottleneck found in most LAN-based shared filesystems.
Each host can buffer the shared disk much as it would for locally attached disks. CXFS maintains the coherency of these distributed buffers, preserving the advanced buffering techniques of the XFS filesystem.
A flat, single-system view of the filesystem; it is identical from all hosts sharing the filesystem and is not dependent on any particular host. The pathname is a normal POSIX pathname; for example, /u/username/directory.
The path does not vary if the metadata server moves from one node to another, if the metadata server name is changed, or if a metadata server is added or replaced. This simplifies storage management for administrators and users. Multiple processes on one host and processes distributed across multiple hosts have the same view of the filesystem, with performance similar on each host.
This differs from typical network filesystems, which tend to include the name of the fileserver in the pathname. This difference reflects the simplicity of the SAN architecture with its direct-to-disk I/O compared with the extra hierarchy of the LAN filesystem that goes through a named server to get to the disks.
A full UNIX filesystem interface, including POSIX, System V, and BSD interfaces. This includes filesystem semantics such as mandatory and advisory record locks. No special record-locking library is required.
CXFS has the following restrictions:
Some filesystem semantics are not appropriate and not supported in shared filesystems. For example, the root filesystem is not an appropriate shared filesystem. Root filesystems belong to a particular host, with system files configured for each particular host's characteristics.
Hierarchical storage management (HSM) applications must run on the metadata server.
The inode monitor device (imon) is not supported on CXFS filesystems. See “Initial Configuration Requirements and Recommendations” in Chapter 3.
The following XFS features are not supported in CXFS:
This section discusses the following:
For details about CXFS daemons, communication paths, and the flow of metadata, see Appendix A, “CXFS Software Architecture”.
This section defines the terminology necessary to understand CXFS. Also see the Glossary.
A cluster is the set of systems (nodes) configured to work together as a single computing resource. A cluster is identified by a simple name and a cluster ID. A cluster running multiple operating systems is known as a multiOS cluster.
Only one cluster may be formed from a given pool of nodes.
Disks or logical units (LUNs) are assigned to clusters by recording the name of the cluster on the disk (or LUN). Thus, if any disk is accessible (via a Fibre Channel connection) from machines in multiple clusters, then those clusters must have unique names. When members of a cluster send messages to each other, they identify their cluster via the cluster ID. Thus, if two clusters will be sharing the same network for communications, then they must have unique cluster IDs. In the case of multiOS clusters, both the names and IDs must be unique if the clusters share a network.
Because of the above restrictions on cluster names and cluster IDs, and because cluster names and cluster IDs cannot be changed once the cluster is created (without deleting the cluster and recreating it), SGI advises that you choose unique names and cluster IDs for each of the clusters within your organization.
A node is an operating system (OS) image, usually an individual computer. (This use of the term node does not have the same meaning as a node in an SGI Origin 3000 or SGI 2000 system.)
A given node can be a member of only one pool and therefore only one cluster.
The pool is the set of nodes from which a particular cluster may be formed. Only one cluster may be configured from a given pool, and it need not contain all of the available nodes. (Other pools may exist, but each is disjoint from the other. They share no node or cluster definitions.)
A pool is first formed when you connect to a given CXFS administration node (one that is installed with cluster_admin) and define that node in the cluster database using the CXFS GUI or cmgr(1M) command. You can then add other nodes to the pool by defining them while still connected to the first node, or to any other CXFS administration node that is already in the pool. (If you were to connect to a different node and then define it, you would be creating a second pool).
Figure 1-1 shows the concepts of pool and cluster.
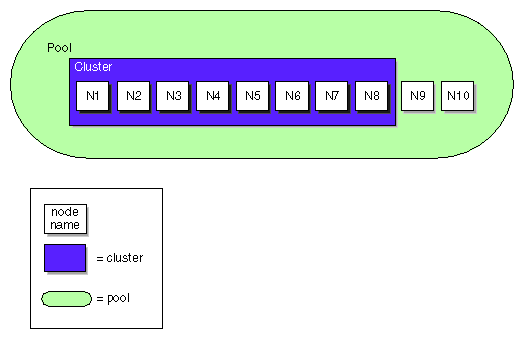
The cluster database contains persistent configuration information about filesystems, nodes, and the cluster. The cluster administration daemons manage the distribution of the cluster database (CDB) across the CXFS administration nodes in the pool.
The database consists of a collection of files; you can view and modify the contents of the database by using the CXFS Manager GUI and the cmgr(1M), cluster_status(1M), clconf_info and cxfs_info(1M) commands. The GUI must be connected to a CXFS administration node, and the cmgr, cluster_status, and clconf_info commands must run on a CXFS administration node. You can use the cxfs_info command on any node.
A node can have one of the following functions:
CXFS metadata server-capable administration node (IRIX only).
This node is installed with the cluster_admin software product, which contains the full set of CXFS cluster administration daemons (fs2d, clconfd, crsd, cad, and cmond; for more details about daemons, see Appendix A, “CXFS Software Architecture”.)
This node type is capable of coordinating cluster activity and metadata. Metadata is information that describes a file, such as the file's name, size, location, and permissions. Metadata tends to be small, usually about 512 bytes per file in XFS. This differs from the data, which is the contents of the file. The data may be many megabytes or gigabytes in size.
For each CXFS filesystem, one node is responsible for updating that filesystem's metadata. This node is referred to as the metadata server. Only nodes defined as server-capable nodes are eligible to be metadata servers.
Multiple CXFS administration nodes can be defined as potential metadata servers for a given CXFS filesystem, but only one node per filesystem is chosen to be the active metadata server. There can be multiple active metadata servers in the cluster, one per CXFS filesystem.
Other nodes that mount a CXFS filesystem are referred to CXFS clients. A CXFS administration node can function as either a metadata server or CXFS client, depending upon how it is configured and whether it is chosen to be the active metadata server.

Note: Do not confuse metadata server and CXFS client with the traditional data-path client/server model used by network filesystems. Only the metadata information passes through the metadata server via the private Ethernet network; the data is passed directly to and from disk on the CXFS client via the fibre channel connection.
You perform cluster administration tasks using the cmgr(1) command running on a CXFS administration node or using the CXFS Manager graphical user interface (GUI) and connecting it to a CXFS administration node; for more details, see “Starting the GUI” in Chapter 4.
There should be an odd number of server-capable administration nodes for quorum calculation purposes.
CXFS client administration node (IRIX only).
This is a node that is installed with the cluster_admin software product but it cannot be a metadata server. This node type should only be used when necessary for coexecution with IRIS FailSafe.
CXFS client-only node (IRIX and other supported operating systems, such as Solaris).
This node is one that runs a minimal implementation of the CXFS and cluster services. This node can safely mount CXFS filesystems but it cannot become a CXFS metadata server or perform cluster administration. This node does not contain a copy of the cluster database.
Nodes that are running supported operating systems other than IRIX are always configured as CXFS client-only nodes. IRIX nodes are client-only nodes if they are installed with the cxfs_client software package and defined as client-only nodes.
For more information, see CXFS MultiOS for CXFS Client-Only Nodes: Installation and Configuration Guide.
A standby node is a server-capable administration node that is configured as a potential metadata server for a given filesystem, but does not currently run any applications that will use that filesystem. (The node can run applications that use other filesystems.)
Ideally, all IRIX nodes will run the same version of the IRIX operating system. However, as of IRIX 6.5.18f, SGI supports a policy for CXFS that permits a rolling annual upgrade; see “Rolling Upgrades” in Chapter 2.
The following figures show different possibilities for metadata server and client configurations. The potential metadata servers are required to be CXFS administration nodes; the other nodes could be client-only nodes.
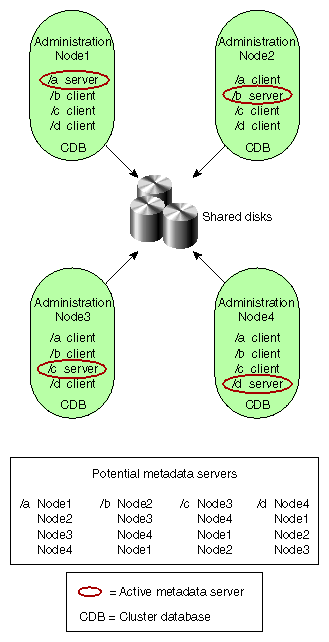
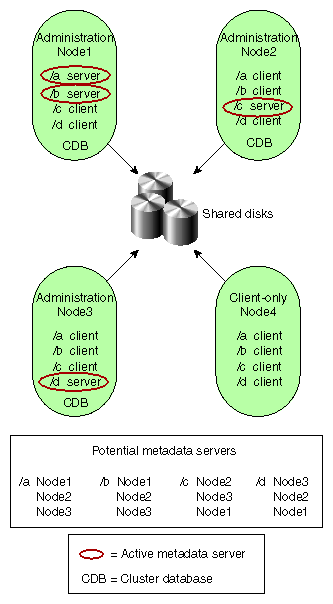
In Figure 1-3, Node4 could be running any supported OS because it is a client-only node; it is not a potential metadata server.
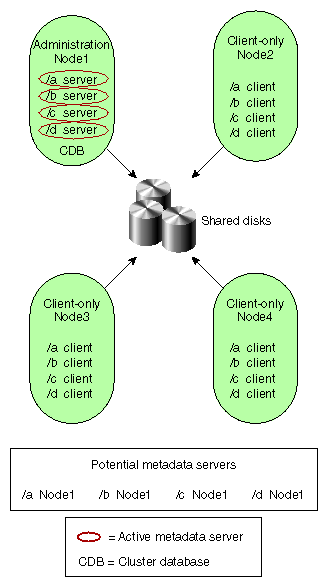
In Figure 1-4, Node2, Node3, and Node4 could be running any supported OS because they are client-only nodes; they are not potential metadata servers.
There are the following types of membership:
CXFS kernel membership is the group of CXFS nodes in the cluster that can actively share filesystems, as determined by the the CXFS kernel, which manages membership and heartbeating. The CXFS kernel membership may be a subset of the nodes defined in a cluster. All nodes in the cluster are eligible for CXFS kernel membership.
During the boot process, a node applies for CXFS kernel membership. Once accepted, the node can actively share the filesystems in the cluster. Membership differs from quorum; see “CXFS Kernel Membership Quorum”.
Cluster database membership (also known as fs2d membership or user-space membership) is the group of CXFS administration nodes that are accessible to each other. CXFS client-only nodes are not eligible for cluster database membership.
For more information, see “Membership Quorums”, and Appendix A, “CXFS Software Architecture”.
CXFS kernel membership and cluster database membership differ from FailSafe membership. For more information about FailSafe, see the IRIS FailSafe Version 2 Administrator's Guide.
A private network is one that is dedicated to cluster communication and is accessible by administrators but not by users.
CXFS uses the private network for metadata traffic. The cluster software uses the private network to send the heartbeat/control messages necessary for the cluster configuration to function. Even small variations in heartbeat timing can cause problems. If there are delays in receiving heartbeat messages, the cluster software may determine that a node is not responding and therefore revoke its CXFS kernel membership; this causes it to either be reset or disconnected, depending upon the configuration.
Rebooting network equipment can cause the nodes in a cluster to lose communication and may result in the loss of CXFS kernel membership and/or cluster database membership ; the cluster will move into a degraded state or shut down if communication between nodes is lost. Using a private network limits the traffic on the network and therefore will help avoid unnecessary resets or disconnects. Also, a network with restricted access is safer than one with user access because the messaging protocol does not prevent snooping (illicit viewing) or spoofing (in which one machine on the network masquerades as another).
Therefore, because the performance and security characteristics of a public network could cause problems in the cluster and because heartbeat is very timing-dependent, a private network is required.
The heartbeat and control network must be connected to all nodes, and all nodes must be configured to use the same subnet for that network.
| Caution: If there are any network issues on the private network, fix them before trying to use CXFS. |
For more information about network segments and partitioning, see “Network Partition Example”. For information about using IP filtering for the private network, see Appendix B, “IP Filtering Example for the CXFS Private Network”.
| Note: In this release, relocation is disabled by default and recovery
is supported only when using standby nodes.
Relocation and recovery are fully implemented, but the number of associated problems prevents full support of these features in the current release. Although data integrity is not compromised, cluster node panics or hangs are likely to occur. Relocation and recovery will be fully supported in a future release when these issues are resolved. |
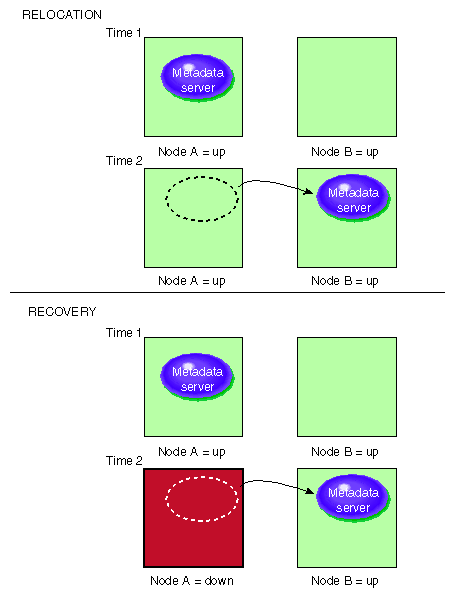
Relocation is the process by which the metadata server moves from one node to another due to an administrative action; other services on the first node are not interrupted.
CXFS kernel membership is not affected by relocation. However, users may experience a degradation in filesystem performance while the metadata server is relocating.
The following are examples of relocation triggers:
The system administrator uses the GUI or cmgr to relocate the metadata server.
The FailSafe CXFS resource relocates the metadata server.
The system administrator unmounts the CXFS filesystem on the metadata server.
An application issues commands to relocate the metadata server.
| Note: Recovery is supported in this release only on standby nodes. |
Recovery is the process by which the metadata server moves from one node to another due to an interruption in services on the first node.
The following are examples of recovery triggers:
A metadata server panic.
A metadata server locks up, causing heartbeat timeouts on metadata clients.
A metadata server loses connection to the heartbeat network.
Figure 1-5 describes the difference between relocation and recovery for a metadata server. (Remember that there is one active metadata server per CXFS filesystem. There can be multiple active metadata servers within a cluster, one for each CXFS filesystem.)
CXFS uses the following methods to isolate failed nodes:
I/O fencing, which isolates a problem node from the SAN so that it cannot access I/O devices, and therefore cannot corrupt data in the shared CXFS filesystem. I/O fencing can be applied to any node in the cluster. When fencing is applied, the rest of the cluster can begin immediate recovery. However, I/O fencing cannot return a nonresponsive node to the cluster; this problem will require intervention from the system administrator.
I/O fencing is required to protect data for the following nodes because they do not provide reset lines:
The following nodes running IRIX:
Silicon Graphics Fuel nodes
Silicon Graphics Octane nodes
Silicon Graphics Octane2 nodes
Nodes running other supported operating systems
To support I/O fencing, these platforms require a Brocade Fibre Channel switch sold and supported by SGI. The fencing network connected to the Brocade switch must be physically separate from the private heartbeat network. .
Serial hardware reset, which performs a system reset via a serial line connected to the system controller. This method applies only to IRIX nodes with system controllers.
I/O fencing and serial hardware reset, which disables access to the SAN from the problem node and then, if the node is successfully fenced, performs an asynchronous reset of the node if it is an IRIX node with a system controller; recovery begins without waiting for reset acknowledgment.
CXFS shutdown, which stops CXFS kernel-based services on the node in response to a loss of CXFS kernel membership. The surviving cluster delays the beginning of recovery to allow the node time to complete the shutdown.
On nodes without system controllers, your only choice for data integrity protection is I/O fencing.
On IRIX nodes with system controllers, you would want to use I/O fencing for data integrity protection when CXFS is just a part of what the node is doing and losing access to CXFS is preferable to having the system rebooted. An example of this would be a large compute server that is also a CXFS client. You would want to use serial hardware reset for I/O protection on an IRIX node when CXFS is a primary activity and you want to get it back online fast; for example, a CXFS fileserver. However, I/O fencing cannot return a nonresponsive node to the cluster; this problem will require intervention from the system administrator.
You can specify how these methods are implemented by defining the failure action hierarchy, the set of instructions that determines which method is used; see “Define a Node with the GUI” in Chapter 4, and “Define a Node with cmgr” in Chapter 5. If you do not define a failure action hierarchy, the default is to perform a serial hardware reset and a CXFS shutdown.
The rest of this section provides more details about I/O fencing and serial hardware resets. For more information about CXFS shutdown, see “Normal CXFS Shutdown” in Chapter 6.
I/O fencing does the following:
Preserves data integrity by preventing I/O from nodes expelled from the cluster
Speeds the recovery of the surviving cluster, which can continue immediately rather than waiting for an expelled node to reset under some circumstances
When a node joins the CXFS kernel membership, the worldwide node name (WWNN) of its host bus adapter (HBA) is stored in the cluster database. If there are problems with the node, the I/O fencing software sends a message via the telnet protocol to the appropriate Brocade Fibre Channel switch and disables the port.
The Brocade Fibre Channel switch then blocks the problem node from communicating with the storage area network (SAN) resources via the corresponding HBA. Figure 1-6, describes this.
If users require access to nonclustered LUNs or devices in the SAN, these LUNs/devices must be accessed or mounted via an HBA that has been explicitly masked from fencing. For details on how to exclude HBAs from fencing for IRIX nodes, see “Define a Switch with the GUI” in Chapter 4, “Define a Switch with cmgr” in Chapter 5; for nodes running other supported operating systems, see CXFS MultiOS for CXFS Client-Only Nodes: Installation and Configuration Guide.
To recover, the affected node withdraws from the CXFS kernel membership, unmounts all file systems that are using an I/O path via fenced HBA(s), and then rejoins the cluster. This process is called fencing recovery and is initiated automatically. Depending on the failure action hierarchy that has been configured, a node may be reset (rebooted) before initiating fencing recovery. For information about setting the failure action hierarchy, see “Define a Node with cmgr” in Chapter 5, and “Define a Node with the GUI” in Chapter 4.
In order for a fenced node to rejoin the CXFS kernel membership, the current cluster leader must lower its fence to allow it to reprobe its XVM volumes and then remount its filesystems. If a node fails to rejoin the CXFS kernel membership, it may remain fenced. This is independent of whether the node was rebooted, because fencing is an operation applied on the Brocade Fibre Channel switch, not the affected node. In certain cases, it may therefore be necessary to manually lower a fence. For instructions, see “Lower the I/O Fence for a Node with the GUI” in Chapter 4, and “Lower the I/O Fence for a Node with cmgr” in Chapter 5.
Caution: If you choose to use I/O fencing, you must understand that
when a fence is raised on an HBA, no further I/O is possible
to the SAN via that HBA until the fence is lowered. This includes
the following:
|
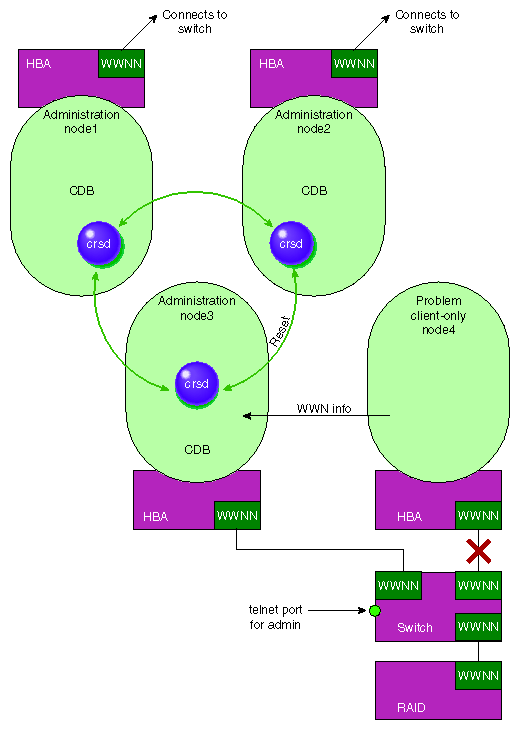
For more information, see “Switches and I/O Fencing Tasks with the GUI” in Chapter 4, and “Switches and I/O Fencing Tasks with cmgr” in Chapter 5.
| Note: I/O fencing cannot be used for FailSafe nodes. FailSafe nodes require the serial hardware reset capability. |
IRIX nodes with system controllers can be reset via a serial line connected to the system controller.
Figure 1-7 shows an example of the CXFS hardware components for a cluster using the serial hardware reset capability and an Ethernet serial port multiplexer.
| Note: The serial hardware reset capability or the use of I/O fencing and switches is mandatory to ensure data integrity for clusters with only two server-capable nodes and it is highly recommended for all server-capable nodes. Larger clusters should have an odd number of server-capable nodes, or must have serial hardware reset lines or use I/O fencing and switches if only two of the nodes are server-capable. (See “Recovery Issues in a Cluster with Only Two Server-Capable Nodes ”.) |
The reset connection has the same connection configuration as IRIS FailSafe; for more information, contact SGI professional or managed services.
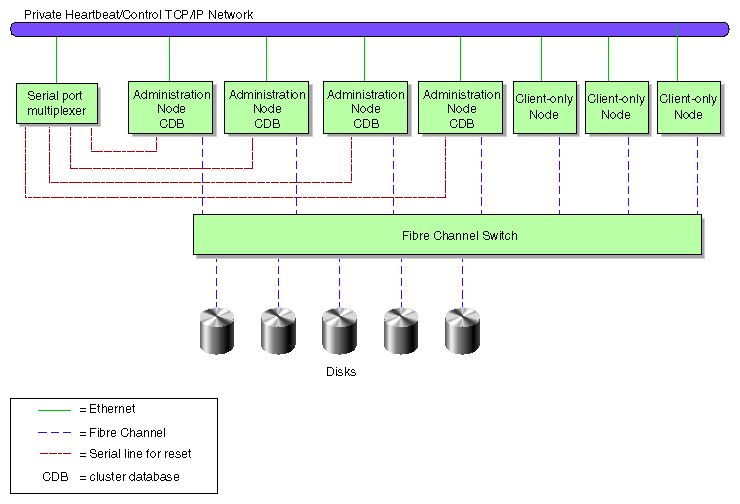
Nodes that have lost contact with the cluster will forcibly terminate access to shared disks. In the absence of serial hardware reset hardware, this may be sufficient to ensure data integrity on the shared disks, assuming the following:
The node is able to detect it has lost communication; that is, an error on the node does not prevent it from detecting the loss.
The node detects the loss in a timely fashion (which it is designed to do); that is, an error on the node does not delay the detection.
However, to ensure data integrity in certain rarely seen error situations, SGI recommends that you use the hardware required for serial hardware reset, especially for clusters with an even number of server-capable nodes. A cluster containing nodes without system controllers also requires the use of I/O fencing to protect data integrity.
The serial hardware reset capability or the use of I/O fencing with switches is mandatory to ensure data integrity for clusters with only two server-capable nodes, and it is highly recommended for all server-capable nodes. Larger clusters should have an odd number of server-capable nodes, or must have serial hardware reset lines or use I/O fencing with switches if only two of the nodes are server-capable. Reset is required for IRIS FailSafe.
The worst scenario is one in which the node does not detect the loss of communication but still allows access to the shared disks, leading to data corruption. For example, it is possible that one node in the cluster could be unable to communicate with other nodes in the cluster (due to a software or hardware failure) but still be able to access shared disks, despite the fact that the cluster does not see this node as an active member.
In this case, the serial hardware reset will allow one of the other nodes to forcibly prevent the failing node from accessing the disk at the instant the error is detected and prior to recovery from the node's departure from the cluster, ensuring no further activity from this node.
In a case of a true network partition, where an existing CXFS kernel membership splits into two halves (each with half the total number of server-capable nodes), the following will happen:
If the CXFS tiebreaker and serial hardware reset or fencing are configured, the half with the tiebreaker node will reset or fence the other half. The side without the tiebreaker will attempt to forcibly shut down CXFS services.
If there is no CXFS tiebreaker node but reset or fencing is configured, each half will attempt to reset or fence the other half using a delay heuristic. One half will succeed and continue. The other will lose the reset/fence race and be rebooted/fenced.
If there is no CXFS tiebreaker node and reset or fencing is not configured, then both halves will delay, each assuming that one will win the race and reset the other. Both halves will then continue running, because neither will have been reset or fenced, leading to likely data corruption.
To avoid this situation, you should always have at least the tiebreaker node or reset or fencing capability configured. However, if the tiebreaker node (in a cluster with only two server-capable nodes) fails, or if the administrator stops CXFS services, the other node will do a forced shutdown, which unmounts all CXFS filesystems.
If the network partition persists when the losing half attempts to form a CXFS kernel membership, it will have only half the number of server-capable nodes and be unable to form an initial CXFS kernel membership, preventing two CXFS kernel memberships in a single cluster.
The serial hardware reset connections take the following forms:
For more information, contact SGI professional or managed services.
The distributed cluster database (CDB) is central to the management of the CXFS cluster. Multiple synchronized copies of the database are maintained across the CXFS administration nodes in the pool (that is, those nodes installed with the cluster_admin software package). For any given CXFS Manager GUI task or cmgr task, the CXFS cluster daemons must apply the associated changes to the cluster database and distribute the changes to each CXFS administration node before another task can begin.
The client-only nodes in the pool do not maintain a local synchronized copy of the full cluster database. Instead, one of the daemons running on a CXFS administration node provides relevant database information to those nodes. If the set of CXFS administration nodes changes, another node may become responsible for updating the client-only nodes.
There are separate quorum mechanisms for each membership type. This section discusses the following:
By design, there can only be one active metadata server per filesystem. However, a problem could develop if there are problems in the heartbeat/control network, which is used to transport metadata information between clients and the metadata server. If the heartbeat/control network is somehow split in half (for example, due to a network failure), the network could become two smaller networks (segments). If this happens, the CXFS kernel membership quorum ensures that only one metadata server is writing the metadata portion of the CXFS filesystem over the storage area network.
The CXFS kernel membership quorum is calculated based on the number of server-capable nodes attempting to participate in the CXFS kernel membership compared to the total number of all server-capable nodes defined in the cluster.
| Note: Client administration nodes and client-only nodes are not considered when forming a kernel membership quorum. |
For optimum performance, a CXFS cluster should have an odd number of server-capable administration nodes.
In most cases, IRIX nodes that are never going to be metadata servers should be installed as client-only nodes rather than CXFS client administration nodes.
At least one node must be defined as a server-capable administration node. All nodes that you wish to be potential metadata servers must have be defined as server-capable administration nodes.
For the initial CXFS kernel membership quorum, a majority (>50%) of the server-capable nodes must be available to bring up a cluster; a large cluster in which all nodes are server-capable will require more nodes to be available before a cluster can be formed than if most of the nodes are client administration or client-only nodes. To maintain the existing CXFS kernel membership quorum requires half (50%) of the server-capable nodes defined in the cluster.
If you do not use serial hardware reset or fencing, you should set a CXFS tiebreaker node to avoid multiple clusters in the event of a network partition.
| Note: The serial hardware reset capability is mandatory
to ensure data integrity for clusters with only two server-capable
nodes and is highly recommended for all server-capable nodes; larger
clusters should have an odd number of server-capable nodes, or must have
serial hardware reset lines or I/O fencing with switches if only two of
the nodes are server-capable.
A Brocade switch is mandatory for data integrity protection in nodes without system controllers. |
A CXFS tiebreaker node is a node that is identified for CXFS to use in the process of computing CXFS kernel membership for the cluster, when exactly half of the server nodes in the cluster are up and can communicate with each other. There is no default CXFS tiebreaker.
However, if the CXFS tiebreaker node in a cluster with only two server-capable nodes fails or if the administrator stops CXFS services, the other node will do a forced shutdown, which unmounts all CXFS filesystems.
If the network being used for heartbeat/control is divided in half, only the portion of the network that has the quorum of server-capable nodes and the CXFS tiebreaker node will be remain in the cluster. Nodes on any portion of the heartbeat/control network that is not part of the quorum will exit from the cluster. Therefore, if the heartbeat/control network is cut in half, you will not have an active metadata server on each half of the heartbeat/control network trying to access the same CXFS metadata over the storage area network at the same time.
The CXFS kernel membership monitors itself with normal messaging and heartbeating. If a failure occurs, the offending nodes are removed from the CXFS kernel membership or are reset to prevent further access to shared resources by these nodes. A node that discovers it has been eliminated from the CXFS kernel membership (due to a communication failure) will forcibly terminate access to the shared disks and stop CXFS services, if it is not first reset.
The number of nodes possible in the CXFS kernel membership can be changed to either expand the cluster to include new nodes or to remove nodes that have left the CXFS kernel membership. Removal of a server-capable node that is down and will remain unavailable reduces the number of server-capable nodes required to form a quorum.
The following is an example of a changing CXFS kernel membership quorum.
Consider a pool of six CXFS server-capable administration nodes (A, B, C, D, E, and F) on one private network:
C is a CXFS tiebreaker node
A, B, C, D, and E are members of the CXFS cluster
Given this, the minimum number of nodes needed for an initial CXFS kernel membership quorum is three nodes (>50%).
If B were to shut down or leave the CXFS kernel membership, then the remaining nodes in the cluster are A, C, D and E. The cluster would still be available in this case because the cluster still satisfies the requirements to maintain the CXFS kernel membership quorum (50%).
Figure 1-8 displays a situation in which a router dies and the heartbeat/control network is effectively split in two. The nodes on network segment 2 (nodes D and E) will disconnect because they do not contain the CXFS tiebreaker node, and therefore do not have a quorum. On network segment 1, one of the other two potential metadata servers will become active and the cluster will only include the systems on network segment 1. Even after the router is repaired, the nodes that were on network segment 2 will remain disconnected until cluster services are restarted on them.
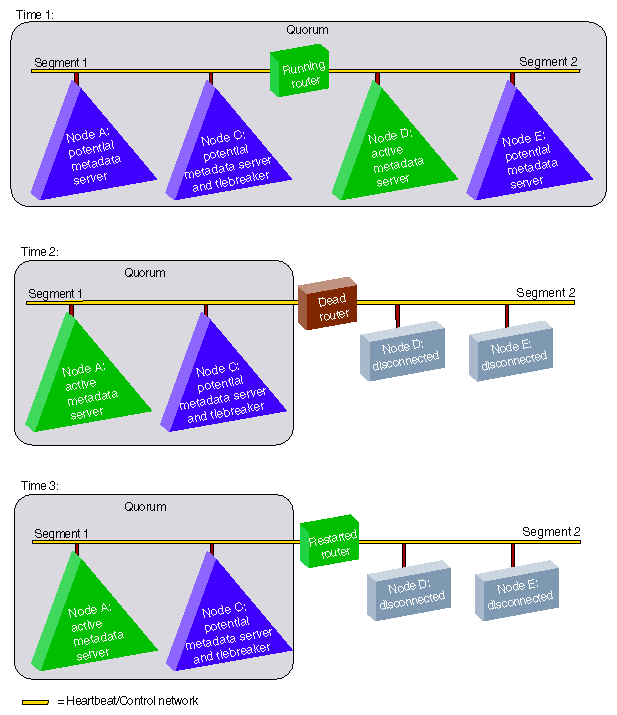
Only CXFS administration nodes contain the full set of CXFS cluster administration daemons and contain distributed copies of the complete cluster database; client-only nodes contain only minimal database information.
The cluster database membership quorum allows an initial cluster to be formed when half (50%) of the CXFS administration nodes in the pool are available to receive cluster database updates.
Figure 1-9 shows the concepts of minimum CXFS kernel membership and cluster database membership in a multiOS cluster.
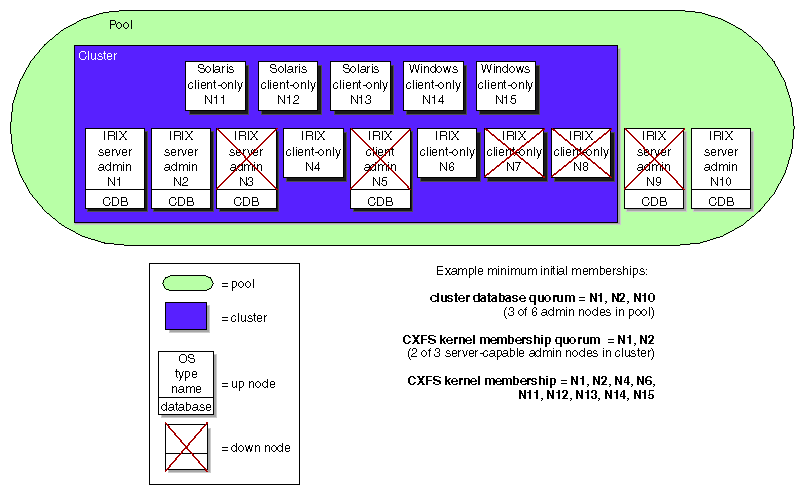
A cluster of at least three server-capable nodes is recommended for a production environment.
However, if you use a production cluster with an even number of server-capable nodes (especially only two server-capable nodes), you must do one of the following:
Use serial hardware reset lines to ensure protection of data and guarantee that only one node is running in error conditions. The reset capability is mandatory to ensure data integrity for clusters with only two server-capable nodes and it is highly recommended for all server-capable nodes. Larger clusters should have an odd number of server-capable nodes, or must have serial hardware reset lines or I/O fencing with switches if only two of the nodes are server-capable.
Note: A Brocade Fibre Channel switch sold and supported by SGI is mandatory for clusters containing nodes without system controllers. Set a CXFS tiebreaker node. This will result in a loss of cluster services and filesystems if the tiebreaker node goes down.
However, even with these methods, there are recovery and relocation issues inherent to a cluster with only two server-capable nodes.
Suppose you have a cluster with serial hardware reset lines and only two server-capable nodes, and one of the nodes has a problem. The following situations may occur:
Both nodes are server-capable, no CXFS tiebreaker:
The CXFS client node will survive a server panic or reset and might survive a loss of connection with the metadata server on the private network. If there is a connection loss, both the client and the metadata server will attempt to reset the other node. The node that succeeds first will survive and become the server.
Both nodes are server-capable, the metadata server is the CXFS tiebreaker:
The CXFS client node will not survive a failure of the metadata server because (although the existing CXFS kernel membership quorum can be maintained with only 50% of the server-capable nodes present), the metadata server is the tiebreaker.
Both nodes are server-capable, the CXFS client node is the CXFS tiebreaker:
For both a server panic or reset and a loss of connection with the metadata server on the private network, the CXFS client node will survive. If the CXFS client was listed as a potential metadata server, it will become the active metadata server. If it was not listed, then the filesystem will be unmounted.
For more information, see “Isolating Failed Nodes”, and “Quorum Calculation”.
The metadata server must perform cluster-coordination functions such as the following:
All CXFS requests for metadata are routed over a TCP/IP network and through the metadata server, and all changes to metadata are sent to the metadata server. The metadata server uses the advanced XFS journal features to log the metadata changes. Because the size of the metadata is typically small, the bandwidth of a fast Ethernet local area network (LAN) is generally sufficient for the metadata traffic.
The operations to the CXFS metadata server are typically infrequent compared with the data operations directly to the disks. For example, opening a file causes a request for the file information from the metadata server. After the file is open, a process can usually read and write the file many times without additional metadata requests. When the file size or other metadata attributes for the file change, this triggers a metadata operation.
The following rules apply:
Any node installed with the cluster_admin product can be defined as a server-capable administration node.
A single server-capable node in the cluster can be the active metadata server for multiple filesystems at once.
There can be multiple server-capable nodes that are active metadata servers, each with a different set of filesystems. However, a given filesystem has a single active metadata server on a single node.
Although you can configure multiple server-capable CXFS administration nodes to be potential metadata servers for a given filesystem, only the first of these nodes to mount the filesystem will become the active metadata server. The list of potential metadata servers for a given filesystem is ordered, but because of network latencies and other unpredictable delays, it is impossible to predict which node will become the active metadata server.
If the last potential metadata server for a filesystem goes down while there are active CXFS clients, all of the clients will be forced out of the filesystem. (If another potential metadata server exists in the list, recovery will take place. For more information, see “Metadata Server Recovery” in Chapter 6.)
If you are exporting the CXFS filesystem to be used with other NFS clients, the filesystem should be exported from the active metadata server for best performance. For more information on NFS exporting of CXFS filesystems, see “NFS Export Scripts” in Chapter 6.
For more information, see “Flow of Metadata for Reads and Writes” in Appendix A.
CXFS provides a single-system view of the filesystems; each host in the SAN has equally direct access to the shared disks and common pathnames to the files. CXFS lets you scale the shared-filesystem performance as needed by adding disk channels and storage to increase the direct host-to-disk bandwidth. The CXFS shared-file performance is not limited by LAN speeds or a bottleneck of data passing through a centralized fileserver. It combines the speed of near-local disk access with the flexibility, scalability, and reliability of clustering.
This section describes the CXFS requirements, compatibility, and recommendations.
A supported SAN hardware configuration using the following platforms for metadata servers:
IRIX systems with system controllers (which means that the nodes can use either serial hardware reset or I/O fencing for data integrity protection):
IRIX systems without system controllers (which means that the nodes require I/O fencing for data integrity protection):
In a CXFS multiOS cluster, CXFS client-only platforms as defined in the CXFS MultiOS for CXFS Client-Only Nodes: Installation and Configuration Guide. These platforms do not contain system controllers.
Serial hardware reset lines or I/O fencing with Brocade Fibre Channel switches sold and supported by SGI. One of these solutions is mandatory for clusters with only two server-capable nodes. Larger clusters should have an odd number of server-capable nodes.
A Brocade Fibre Channel switch sold and supported by SGI is mandatory to support I/O fencing. Nodes without system controllers require I/O fencing for data integrity protection.
RAID hardware:
SGI TP9400:
Required controller firmware and NVSRAM files for 4774 or 4884 units from the SGI TP9400 4.0 CD.
Must be running Mojave code (default for 4884).
SGI TP9100:
2-Gbit TP9100 supported via a Brocade Fibre Channel switch sold and supported by SGI or (only for IRIX nodes using serial hardware reset lines) direct connect.
1-Gbit SGI TP9100 supported via special request with the following conditions: Brocade Fibre Channel switch sold and supported by SGI; release 4 firmware; optical attach. (Other conditions may also apply.)
Adequate compute power for CXFS nodes, particularly metadata servers, which must deal with the required communication and I/O overhead. There should be at least 512 MB of RAM on the system.
A FLEXlm license key for CXFS.
XVM provides a mirroring feature. If you want to access a mirrored volume from a given node in the cluster, you must purchase the XFS Volume Plexing software option and obtain and install a FLEXlm license. Only those nodes that will access the mirrored volume must be licensed. For information about purchasing this license, see your sales representative.
Note: Partitioned Origin 3000 and Onyx 3000 systems upgrading to IRIX 6.5.15f or later will require replacement licenses. Prior to IRIX 6.5.15f, these partitioned systems used the same license for all the partitions in the system. For more information, see the Start Here/Welcome and the following web page: http://www.sgi.com/support/licensing/partitionlic.html. The XVM volume manager, which is provided as part of the IRIX release.
If you use I/O fencing and ipfilterd (1M) on a node, the ipfilterd configuration must allow communication between the node and the telnet(1) port on the switch.
A cluster is supported with as many as 32 nodes, of which as many as 16 can be CXFS administration nodes.
A cluster in which both CXFS and IRIS FailSafe 2.1 or later are run (known as coexecution) is supported with a maximum of 32 nodes, as many as 8 of which can run FailSafe. Even when running with FailSafe, there is only one pool and one cluster. See “Overview of IRIS FailSafe Coexecution”, for further configuration details.
All IRIX nodes must be running the same or adjacent levels of the IRIX operating system (OS), beginning with IRIX 6.5.12f; for example, 6.5.16f and 6.5.17f.
Clients must be running IRIX or the other operating systems specified in the CXFS MultiOS for CXFS Client-Only Nodes: Installation and Configuration Guide. The IRIX nodes in a cluster containing nodes running other operating systems must be running 6.5.16f or later.
CXFS is compatible with the following:
Data Migration Facility (DMF) and Tape Management Facility (TMF).
Trusted IRIX/CMW (Compartmented Mode Workstation). CXFS has been qualified in an SGI Trusted IRIX cluster with the Data Migration Facility (DMF) and Tape Management Facility (TMF).
If you want to run CXFS and Trusted IRIX, SGI recommends that all nodes in the cluster run Trusted IRIX; all nodes must be IRIX nodes or Trusted IRIX nodes (you cannot run Trusted IRIX in a multiOS cluster). For more information, see Chapter 8, “Trusted IRIX and CXFS”.
IRIS FailSafe (coexecution). See the “Overview of IRIS FailSafe Coexecution”, and the IRIS FailSafe Version 2 Administrator's Guide.
IRISconsole; see the IRISconsole Administrator's Guide. (CXFS does not support the Silicon Graphics O2 workstation as a CXFS node.)
A serial port multiplexer used for the serial hardware reset capability.
SGI recommends the following when running CXFS:
Only those nodes that you want to be potential metadata servers should be CXFS administration nodes (installed with the cluster_admin software product). CXFS client administration nodes should only be used when necessary for coexecution with IRIS FailSafe. All other nodes should be client-only nodes (installed with cxfs_client).
Use a network switch rather than a hub for performance and control.
A production cluster should be configured with a minimum of three server-capable nodes.
If you want to run CXFS and Trusted IRIX/CMW, have all nodes in the cluster run Trusted IRIX. You should configure your system such that all nodes in the cluster have the same user IDs, access control lists (ACLs), and capabilities.
As for any case with long running jobs, you should use the IRIX checkpoint and restart feature. For more information, see the cpr(1) man page.
For more configuration and administration suggestions, see “Initial Configuration Requirements and Recommendations” in Chapter 3.
CXFS allows groups of computers to coherently share large amounts of data while maintaining high performance. The SGI IRIS FailSafe product provides a general facility for providing highly available services.
You can therefore use FailSafe in a CXFS cluster (known as coexecution) to provide highly available services (such as NFS or web) running on a CXFS filesystem. This combination provides high-performance shared data access for highly available applications in a clustered system.
CXFS 6.5.10 or later and IRIS FailSafe 2.1 or later (plus relevant patches) may be installed and run on the same system.
A subset of nodes in a coexecution cluster can be configured to be used as FailSafe nodes; a coexecution cluster can have up to eight nodes that run FailSafe.
For more information, see Chapter 7, “Coexecution with IRIS FailSafe”.
CXFS provides a set of tools to manage the cluster. These tools execute only on the appropriate node types:
Administration nodes:
cxfsmgr(1M), which invokes the CXFS Manager graphical user interface (GUI)
cmgr(1M) (also known as cluster_mgr)
cluster_status(1M)
clconf_info
Client-only nodes:
cxfs_info
| Note: The must be connected to a CXFS administration node, but it can be launched elsewhere; see “Starting the GUI” in Chapter 4. |
You can perform CXFS configuration tasks using either the GUI or the cmgr(1M) cluster manager command. These tools update the cluster database, which persistently stores metadata and cluster configuration information.
Although these tools use the same underlying software command line interface (CLI) to configure and monitor a cluster, the GUI provides the following additional features, which are particularly important in a production system:
You can click any blue text to get more information about that concept or input field. Online help is also provided with the Help button.
The cluster state is shown visually for instant recognition of status and problems.
The state is updated dynamically for continuous system monitoring.
All inputs are checked for correct syntax before attempting to change the cluster configuration information. In every task, the cluster configuration will not update until you click OK.
Tasks take you step-by-step through configuration and management operations, making actual changes to the cluster configuration as you complete a task.
The graphical tools can be run securely and remotely on any IRIX workstation or any computer that has a Java-enabled web browser, including Windows and Linux computers and laptops.
The cmgr(1M) command is more limited in its functions. It enables you to configure and administer a cluster system only on a CXFS administration node (one that is installed with the cluster_admin software product). It provides a minimum of help and formatted output and does not provide dynamic status except when queried. However, an experienced administrator may find cmgr to be convenient when performing basic configuration tasks or isolated single tasks in a production environment, or when running scripts to automate some cluster administration tasks. You can use the build_cmgr_script(1M) command to automatically create a cmgr(1M) script based on the contents of the cluster database.
After the associated changes are applied to all online database copies in the pool, the view area in the GUI will be updated. You can use the GUI or the cmgr(1M), cluster_status(1M), and clconf_info commands to view the state of the database. (The database is a collection of files, which you cannot access directly.) On a client-only node, you can use the cxfs_info command.
For more details, see the following: