This chapter provides some basic guidelines to follow when tuning your application for optimal performance. It also describes how to use debugging tools like pixie, prof, and ogldebug to debug and tune your applications on IRIX. It concludes with some specific notes on tuning applications on systems with RealityEngine graphics.
This section contains some general performance tuning principles. Some of these issues are discussed in more detail later in this chapter.
Remember that high performance does not come by accident. You must design your programs with speed in mind for optimal results.
Tuning graphical applications, particularly OpenGL Performer applications, requires a pipeline-based approach. You can think of the graphics pipeline as comprising three separate stages; the pipeline runs only as fast as the slowest stage; so, improving the performance of the pipeline requires improving the slowest stage's performance. The three stages are the following:
The host (or CPU) stage, in which routines are called and general processing is done by the application. This stage can be thought of as a software pipeline, sometimes called the rendering pipeline, itself comprising up to three sub-stages—the application, cull, and draw stages—as discussed at length throughout this guide.
The transformation stage, in which transformation matrices are applied to objects to position them in space (this includes matrix operations, setting graphics modes, transforming vertices, handling lighting, and clipping polygons).
The fill stage, which includes clearing the screen and then drawing and filling polygons (with operations such as Gouraud shading, z-buffering, and texture mapping).
You can estimate your expected frame rate based on the makeup of the scene to be drawn and graphics speeds for the hardware you are using. Be sure to include fill rates, polygon transform rates, and time for mode changes, matrix operations, and screen clear in your calculations.
Measure both the performance of complex scenes in your database and of individual objects and drawing primitive to verify your understanding of the performance requirements.
Use the OpenGL Performer diagnostic statistics to evaluate how long each stage takes and how much it does. See Chapter 23, “Statistics”, for more information. These statistics are referred to frequently in this chapter.
Tuning an application is an incremental process. As you improve one stage's performance, bottlenecks in other stages may become more noticeable. Also, do not be discouraged if you apply tuning techniques and find that your frame rate does not change—frame rates only change by a field at a time (which is to say in increments of 16.67 milliseconds for a 60 Hz display) while tuning may provide speed increases of finer granularity than that. To see performance improvements that do not actually increase frame rate, look at the times reported by OpenGL Performer statistics on the cull and draw processes (see Chapter 23, “Statistics” for more information).
OpenGL Performer uses many techniques to increase application performance. Knowing about what OpenGL Performer is doing and how it affects the various pipeline stages may help you write more efficient code. This section lists some of the things OpenGL Performer can do for you.
During drawing, OpenGL Performer does the following:
Sets up an internal record of what routines and rendering methods are fastest for the current graphics platform. This information can be queried in any process with pfQueryFeature(). You can use this information at run time when setting state properties on your pfGeoStates.
Has machine-dependent fast options for commands that are very performance-sensitive. Use the _ON and _FAST mode settings whenever possible to get machine-dependent high-performance defaults. Some examples include the following:
Sets up default modes for drawing, multiprocessing, statistics, and other areas, that are chosen to provide high scene quality and performance. Some rendering defaults differ from GL defaults: backface elimination is enabled by default ( pfCullFace(PFCF_BACK)) and lighting materials use glColorMaterial() to minimize the number of materials required in a database ( pfMtlColorMode(mtl, side, PFMTL_CMODE_AD)).
Uses a large number of specialized routines for rendering different kinds of objects extremely quickly. There is a specialized drawing routine for each possible pfGeoSet configuration (each choice of primitive type, attribute bindings, and index selection). Each time you change from one pfGeoSet to another, one of these specialized routines is called. However, this happens even if the new pfGeoSet has the same configuration as the old one, so larger pfGeoSets are more efficient than smaller ones—the function-call overhead for drawing many small pfGeoSets can reduce performance. As a rule of thumb, a pfGeoSet should contain at least 4 triangles, preferably between 8 and 64. If the pfGeoSet is too large, it can reduce the efficiency of other parts of the process pipeline.
Caches state changes, because applying state changes is costly in the draw stage. OpenGL Performer accumulates state changes until you call one of the pfApply*() functions, at which point it applies all the changes at once. Note that this differs from the graphics libraries, in which state changes are immediate. If you have several state changes to make in OpenGL Performer, set up all the changes before applying them, rather than using the one-change-at-a-time approach (with each change followed by an apply operation) that you might expect if you are used to graphics library programming.
Evaluates state changes lazily—that is, it avoids making any redundant changes. When you apply a state change, OpenGL Performer compares the new graphics state to the previous one to see if they are different. If they are, it checks whether the new state sets any modes. If it does, OpenGL Performer checks each mode being set to see whether it is different from the previous setting. To take advantage of this feature, share pfGeoStates and inherit states from the global state wherever possible. Set all the settings you can at the global level and let other nodes inherit those settings, rather than setting each node's attributes redundantly. To do this within a database, you can set up pfGeoStates with your desired global state and apply them to the pfChannel or pfScene with pfChanGState() or pfSceneGState(). You can do this through the database loader utilities in libpfdu trivially for a given scene with pfdMakeSharedScene() or have more control over the process with pfdDefaultGState(), pfdMakeSceneGState(), and pfdOptimizeGStateList().
Provides an optimized immediate mode rendering display list data type, pfDispList, in libpr. The pfDispList type reduces host overhead in the drawing process and requires much less memory than a graphics library display list. libpf uses pfDispLists to pass results from the cull process to the draw process when the PFMP_CULL_DL_DRAW mode is turned on as part of the multiprocessing model. For more information about display lists, see “Display Lists” in Chapter 12; for more information about multiprocessing, see “Successful Multiprocessing with OpenGL Performer” in Chapter 5.
To help optimize culling and intersection, OpenGL Performer does the following:
Provides pfFlatten() to resolve instancing (via cloning) and static matrix transformations (by pre-transforming the cloned geometry). It can be especially important to flatten small pfGeoSets; otherwise, matrix transformations must be applied to each small pfGeoSet at significant computational expense. Note that flattening resolves only static coordinate systems, not dynamic ones, but that, where desired, pfDCS nodes can be converted to pfSCS nodes automatically using the OpenGL Performer utility function pfdFreezeTransforms(), which allows for subsequent flattening. Using pfFlatten(), of course, increases performance at the cost of greater memory use. Further, the function pfdCleanTree() can be used to remove needless nodes: identity matrix pfSCS nodes, single child pfGroup nodes, and the like.
Uses bounding spheres around nodes for fast culling—the intersection test for spheres is much faster than that for bounding boxes. If a node's bounding sphere does not intersect the viewing frustum, there is no need to descend further into that node. There are bounding boxes around pfGeoSets; the intersection test is more expensive but provides greater accuracy at that level.
Provides the pfPartition node type to partition geometry for fast intersection testing. Use a pfPartition node as the parent for anything that needs intersection testing.
Provides level-of-detail ( LOD) capabilities in order to draw simpler (and thus cheaper) versions of objects when they are too far away for the user to discern small details.
Allows intersection performance enhancement by precomputation of polygon plane equations within pfGeoSets. This pre-computation is in the form of a traversal that is nearly always appropriate—only in cases of non-intersectable or dynamically changing geometry might these cached plane equations be disadvantageous. This optimization is performed by pfuCollideSetup() using the PFTRAV_IS_CACHE bit mask value.
Sorts pfGeoSets by graphics state in the cull process, in order to minimize state changes and flatten matrix transformations when libpf creates display lists to send to the draw process (as occurs in the PFMP_CULL_DL_DRAW multiprocessing mode). This procedure takes extra time in the cull stage but can greatly improve performance when rendering a complex scene that uses many pfGeoStates. The sorting is enabled by default; it can be turned off and on by calling the function pfChanTravMode(chan, PFTRAV_CULL, mode) and including or excluding the PFCULL_SORT token. See “pfChannel Traversal Modes” in Chapter 4 and “Sorting the Scene” in Chapter 4 for more information on sorting.
During the application stage, OpenGL Performer does the following:
Divides the application process into two parts: the latency-critical section (which includes everything between pfSync() and pfFrame()), where last-minute latency-critical operations are performed before the cull of the current frame can start; and the noncritical portion, after pfFrame() and before pfSync(). The critical section is displayed in the channel statistics graph drawn with pfDrawChanStats().
Provides an efficient mechanism to automatically propagate database changes down the process pipeline and provides pfPassChanData() for passing custom application data down the process pipeline.
Minimizes overhead in copying database changes to the cull process by accumulating unique changes and updating the cull once inside pfFrame(). This updated period is displayed in the MP statistics of the channel statistics graph drawn with pfDrawChanStats().
Provides a mechanism for performing database intersections in a forked process: pass the PFMP_FORK_ISECT flag to pfMultiprocess() and declare an intersection callback with pfIsectFunc().
Provides a mechanism for performing database loading and editing operations in a forked process, such as the DBASE process: pass the PFMP_FORK_DBASE flag to pfMultiprocess() and declare an intersection callback with pfDBaseFunc().
While OpenGL Performer provides inherent performance optimization, there are specific techniques you can use to increase performance even more. This section contains some guidelines and advice pertaining to database organization, code structure and style, managing system resources, and rules for using OpenGL Performer.
Tuning the graphics pipeline requires identifying and removing bottlenecks in the pipeline. You can remove a bottleneck either by minimizing the amount of work being done in the stage that has the bottleneck or, in some cases, by reorganizing your rendering to more effectively distribute the workload over the pipeline stages. This section contains specific tips for finding and removing bottlenecks in each stage of the graphics pipeline.
Here are some ways to minimize the time spent in the host stage of the graphics pipeline:
Function calls, loops, and other programming constructs require a certain amount of overhead. To make such constructs cost-effective, make sure they do as much work as possible with each invocation. For instance, drawing a pfGeoSet of triangle strips involves a nested loop, iterating on strips within the set and triangles within each strip; it therefore makes sense to have several triangles in each strip and several strips in each set. If you put only two triangles in a pfGeoSet, you will spend all that loop overhead on drawing those two triangles, when you could be drawing many more with little extra cost. The channel statistics can display (as part of the graphics statistics) a histogram showing the percentage of your database that is drawn in triangle strips of certain lengths.
On systems that can store vertex arrays on the graphics cards (such as Onyx4 or Prism systems), using pfGeoArrays can reduce the transfers from the host to the graphics subsystem.
Only bind vertex attributes that are actually in use. For example, if you bind per-vertex colors on a set of flat-shaded quads, the software will waste work by sending those colors to the graphics pipeline, which will ignore them. Similarly, it is pointless to bind normals on an unlit pfGeoSet.
Nonindexed drawing has less host overhead than indexed drawing because indexed drawing requires an extra memory reference to get the vertex data to the graphics pipeline. This is most significant for primitives that are easily host-limited, such as independent polygons or very short triangle strips. However, indexed drawing can be very helpful in reducing the memory requirements of a very large database.
Enable state sorting for pfChannels (this is the default). By sorting, the CPU does not need to examine as many pfGeoStates. The graphics channel statistics can be used to report the pfGeoSet-to-pfGeoState drawing ratio.
A transform bottleneck can arise from expensive vertex operations, from a scene that is typically drawn with many very tiny polygons, from a scene modeled with inefficient primitive types, or from excessive mode or transform operations. Here are some tips on reducing such bottlenecks:
Connected primitives will have better vertex rates than independent primitives, and quadrilaterals are typically much more efficient in vertex operations than independent triangles are. This is certainly the case for systems with on-chip vertex caches (Onyx4 or Prism systems, for example). Repeating indices can reduce the number of required transformations.
You can use function pfdStripGraph() and other optimization functions to optimize your geometry. For more details, see “Optimizing Geometry for Rendering” in Chapter 8.
The expensive vertex operations are generally lighting calculations. The fastest lighting configuration is always one infinite light. Multiple lights, local viewing models, and local lights have (in that order) dramatically increasing cost. Two-sided lighting also incurs some additional transform cost. On some graphics platforms, texturing and fog can add further significant cost to per-vertex transformation. The channel graphics statistics will tell you what kinds of lights and light models are being used in the scene.
Matrix transforms are also fairly expensive and definitely more costly than one or two explicit scale, translate, or rotate operations. When possible, flatten matrix operations into the database with pfFlatten().
The most frequent causes of mode changes are glShadeModel(), textures, and object materials. The speed of these changes depends on the graphics hardware; however, material changes do tend to be expensive. Sharing materials among different objects can be increased with the use of pfMtlColorMode(), which is PFMTL_CMODE_AD by default. However, on some older graphics platforms (such as the Elan, Extreme, and VGX), the use of pfMtlColorMode() (which actually calls the function glColorMaterial()) has some associated per-vertex cost and should be used with some caution.
If your cull stage is not a bottleneck, make sure your pfChannels sort the scene by graphics state. Even if you are running in single process mode, the extra time taken to sort the database is often more than offset by the savings in rendering time. See “Sorting the Scene” in Chapter 4 for more details on how to configure sorting.
Here are some methods of dealing with fill-stage bottlenecks:
One technique to hide the cost of expensive fill operations is to fill the pipeline from the back forward so that no part is sitting idle waiting for an upstream stage to finish. The last stage of the pipeline is the fill stage; so, by drawing backgrounds or clearing the screen using pfClearChan() first, before pfDraw(), you can keep the fill stage busy. In addition, if you have a couple of large objects that reliably occlude much of the scene, drawing them very early on can both fill up the back-end stage and also reduce future fill work, because the occluded parts of the scene will fail a z-buffer test and will not have to write z values to the z-buffer or go on to more complex fill operations.
Use the pfStats fill statistics (available for display through the channel statistics) to visualize your depth complexity and get a count of how many pixels are being computed each frame.
Be aware of the cost of any fill operations you use and their relative cost on the relevant graphics hardware configuration. Quick experiments you can do to test for a fill limitation include:
If either of these tests causes a significant reduction in the time to draw the scene, then a significant fill bottleneck probably exists.
The cost of specific fill operations can vary greatly depending on the graphics hardware configuration. As a rule of thumb, flat shading is much faster than Gouraud shading because it reduces both fill work and the host overhead of specifying per-vertex colors. Z-buffering is typically next in cost, and then stencil and blending. On a RealityEngine, the use of multisampling can add to the cost of some of these operations, specifically z-buffering and stenciling. See “Multisampling” for more information. Texturing is considered free on RealityEngine and Impact systems but is relatively expensive on a VGX and is actually done in the host stage on lower-end graphics platforms, such as Extreme and XZ. Some of the low-end graphics platforms also implement z-buffering on the host.
You may not be able to achieve benchmark-level performance in all cases for all features. For instance, if you frequently change modes and you use short triangle strips, you get much less than the peak triangle mesh performance quoted for the machine. Fill rates are sensitive to both modes, mode changes, and polygon sizes. As a general rule of thumb, assume that fill rates average around 70% of peak on general scenes to account for polygon size and position as well as for pipeline efficiency.
Large fragment programs and shaders can negatively impact fill rate.
In some applications, drawing from front to back by setting the bin sorting options can increase performance.
These simple tips will help you optimize your OpenGL Performer process pipeline:
Use pfMultiprocess() to set the appropriate process model for the current machine.
You usually should not specify more processes with pfMultiprocess() than there are CPUs on the system. The default multiprocess mode (PFMP_DEFAULT) attempts an optimal configuration for the number of unrestricted CPUs. However, if there are fewer processors than significant tasks (consider APP, CULL, DRAW, ISECT, and DBASE), you will want experiment with the different two-process models to find the one that will yield the best overall frame rate. Use of pfDrawChanStats(), described in Chapter 23, “Statistics”, will greatly help with this task.
Put only latency-critical tasks between the pfSync() and pfFrame() calls. For example, put latency-critical updates, like changes to the viewpoint, after pfSync() but before pfFrame(). Put time-consuming tasks, such as intersection tests and system dynamics, after pfFrame().
You will also want to refer to the IRIX REACT documentation for setting up a real-time system.
For maximum performance, use the OpenGL Performer utilities in libpfutil for setting non-degrading priorities and isolating CPUs ( pfuPrioritizeProcs(), pfuLockDownProc(), pfuLockDownApp(), pfuLockDownCull(), and pfuLockDownDraw()). These facilities require that the application runs with root permissions. The source code for these utilities is in /usr/share/Performer/src/lib/libpfutil/lockcpu.c for IRIX and Linux and in %PFROOT%\Src\lib\libpfutil\lockcpu.c for Microsoft Windows. For an example of their use, see the sample source code in /usr/share/Performer/src/pguide/libpf/C/bench.c for IRIX and Linux and in %PFROOT%\Src\pguide\libpf\C\bench.c for Microsoft Windows. For more information about priority scheduling and real-time programming on IRIX systems, see the chapter of the IRIX System Programming Guide entitled “Using Real-Time Programming Features” and the IRIX REACT technical report.
Make sure you are not generating any floating-point exceptions. Floating-point exceptions can cause an individual computation to incur tens of times its normal cost. Furthermore, a single floating point exception can lead to many further exceptions in computations that use the exceptional result and can even propagate performance degradation down the process pipeline. OpenGL Performer will detect and tell you about the existence of floating point exceptions if your pfNotifyLevel() is set to PFNFY_INFO or PFNFY_DEBUG. You can then run your application in dbx (on IRIX) or gdb (on Linux) and your application will stop when it encounters an exception, enabling you to trace the cause.
Make sure the main pipeline (APP, CULL, and DRAW processes) do not make per-frame memory allocations or deallocations (asynchronous processes like DBASE can do per-frame allocations). On IRIX, you can use the debugging library's tracing feature of libdmalloc run-time malloc to verify that no memory allocation routines are being called. On Linux, use the Electric Fence (libefence). See the “Memory Corruption and Leaks” section later in this chapter for more about libdmalloc.
Minimize the amount of channel data allocated by pfAllocChanData() and call pfPassChanData() only when necessary to reduce the overhead of copying the data. Copying pointers instead of data is often sufficient.
Here are a couple of suggestions for tuning the cull process:
The default channel culling mode enables all types of culling. If your cull process is your most expensive task, you may want to consider doing less culling operations. When doing database culling, always use view-frustum culling (PFCULL_VIEW) and usually use graphics library mode database sorting (PFCULL_SORT) and pfGeoSet culling (PFCULL_GSET) as well:
pfChanTravMode(chan, root, PFCULL_VIEW | PFCULL_GSET | PFCULL_SORT);A cull-limited application might realize a quick gain from turning off pfGeoSet culling. If you think your database has few textures and materials, you might turn off sorting. However, if possible it would be better to try improving cull performance by improving database construction. “Efficient Intersection and Traversals” discusses optimizing cull traversals in more detail.
Look at the channel-culling statistics for the following:
A large amount of the database being traversed by the culling process and being trivially rejected as not being in the viewing frustum. This can be improved with better spatial organization of the database.
A large number of database nodes being non-trivially culled. This can be improved with better spatial organization and breakup of large pfGeodes and pfGeoSets.
A surprising number of LODs in their fade state (the fade computations can be expensive, particularly if channel stress management has been enabled).
Balance the database hierarchy with the scene complexity: the depth of the hierarchy, the number of pfGeoStates, and the depth of culling. See “Balancing Cull and Draw Processing with Database Hierarchy” for details.
pfNodes that have significant evaluation in the cull stage include pfBillboards, pfLightPoints, pfLightSources, and pfLODs.
Here are some suggestions specific to the draw process:
Minimize host work done in the draw process before the call to pfDraw(). Time spent before the call to pfDraw() is time that the graphics pipeline is idle. Any graphics library (or X) input processing or mode changes should be done after pfDraw() to take effect in the following frame.
Use only one pfPipe per hardware graphics pipeline and preferably one pfPipeWindow per pfPipe. Use multiple channels within that pfPipeWindow to manage multiple views or scenes. It is fairly expensive to simultaneously render to multiple graphics windows on a single hardware graphics pipeline and is not advisable for a real-time application.
Pre-define and pre-load all of the textures in the database into hardware texture memory by using a pfApplyTex() function on each pfTexture. You can do this texture-applying in the pfConfigStage() draw callback or (for multipipe applications to allow parallelism) the pfConfigPWin() callback. This approach avoids the huge performance impact that results when textures are encountered for the first time while drawing the database and must then be downloaded to texture memory. Utilities are provided in libpfutil to apply textures appropriately; see the pfuDownloadTexList() routine in the distributed source code file /usr/share/Performer/src/lib/libpfutil/tex.c for IRIX and Linux and in file %PFROOT%\Src\lib\libpfutil\tex.c on Microsoft Windows. The Perfly application demonstrates this. For IRIX and Linux, see the Perfly source file generic.c in either the C language (/usr/share/Performer/src/sample/C/common) or C++ language (/usr/share/Performer/src/sample/C++/common) versions of Perfly.For Microsoft Windows, see the Perfly source file generic.c in either the C language (%PFROOT%\Src\sample\C\common) or C++ language (%PFROOT%\Src\sample\C++\common) versions of Perfly.
Minimize the use of pfSCSs and pfDCSs and nodes with draw callbacks in the database since aggressive state sorting is kept local to subtrees under these nodes.
Do not do any graphics library input handling in the draw process. Instead, use X input handling in an asynchronous process. OpenGL Performer provides utilities for asynchronous input handling in libpfutil with source code provided in /usr/share/Performer/src/lib/libpfutil/input.c for IRIX and Linux and in %PFROOT%\Src\lib\libpfutil\input.c for Microsoft Windows. For a demonstration of asynchronous X input handling, see provided sample applications, such as perfly, and also the distributed sample programs /usr/share/Performer/src/pguide/libpf/C/motif.c and /usr/share/Performer/src/pguide/libpfui/C/motifxformer.c for IRIX and Linux and the programs %PFROOT%\Src\lib\pguide\libpf\C\motif.c and %PFROOT%\Src\lib\pguide\libpfui\C\motifxformer.c for Microsoft Windows.
Here are some tips on optimizing intersections and traversals:
Use pfPartition nodes on pieces of the database that will be handed to intersection traversal. These nodes impose spatial partitioning on the subgraph beneath them, which can dramatically improve the performance of intersection traversals.

Note: Subgraphs under pfDCS, pfLOD, pfSwitch, and pfSequence nodes are not partitioned; so, intersection traversals of these subgraphs will not be affected. Use intersection caching. For static objects, enable intersection caching at initialization—first call pfNodeTravMask(), specifying intersection traversal (PFTRAV_ISECT), and then include PFTRAV_IS_CACHE in the mode for intersections. You can turn this mode on and off for dynamic objects as appropriate.
Use intersection masks on nodes to eliminate large sections of the database when doing intersection tests. Note that intersections are sproc()-safe in the current version of OpenGL Performer; you can check intersections in more than one process.
Bundle segments for intersections with bounding cylinders. You can pass as many as 32 segments to each intersection request. If the request contains more than a few segments and if the segments are close together, the traversal will run faster if you place a bounding cylinder around the segments using pfCylAroundSegs() and pass that bounding cylinder to pfNodeIsectSegs(). The intersection traversal will use the cylinder rather than each segment when testing the segments against the bounding volumes of nodes and pfGeoSets.
Note: Bundling segments pertains only to IRIX and Linux.
Optimizing your databases can provide large performance increases.
The following tips will help you achieve peak performance when using libpr:
Minimize the number of pfGeoStates by sharing as much as possible.
Initialize each mode in the global state to match the majority of the database in order to set as little local state for individual pfGeoStates as possible.
Use triangle strips wherever possible; they produce the largest number of polygons from a given number of vertices; so, they use the least memory and are drawn the fastest of the primitive types.
Use the simplest possible attribute bindings and use flat-shaded primitives wherever possible. If you are not going to need an object's attributes, do not bind them—anything you bind will have to be sent to the pipeline with the object.
Flat-shaded primitives and simple attribute bindings reduce the transformation and lighting requirements for the polygon. Note that the flat-shaded triangle-strip primitive renders faster than a regular triangle strip, but you have to change the index by two to get the colors right (that is, you need to ignore the first two vertices when coloring). See “Attributes” in Chapter 8 for more information.
Use nonindexed drawing wherever possible, especially for independent polygon primitives and short triangle strips.
When building the database, avoid fragmentation in memory of data to be rendered. Minimize the number of separate data and index arrays. Keep the data and index arrays for pfGeoSets contiguous and try to keep separate pfGeoSets contiguous to avoid small, fragmented pfMalloc() memory allocations.
The ideal size of a pfGeoSet (and of each triangle strip within the pfGeoSet) depends a great deal on the specific CPU and system architecture involved; you may have to do benchmarks to find out what is best for your machine. For a general rule of thumb, use at least 4 triangles per strip on any machine, and 8 on most. Use 5 to 10 strips in each pfGeoSet, or a total of 24 to 100 triangles per pfGeoSet.
When you are using libpf, the following tips can improve the performance of database tasks:
Use pfFlatten(), especially when a pfScene contains many small instanced objects and billboards. Use pfdCleanTree() and (if application considerations permit) pfdFreezeTransforms() to minimize the cull traversal processing time and maximize state sorting scope.
Initialize each mode in the scene pfGeoState to match the majority of the database in order to set as little local state for individual pfGeoStates as possible. The utility function pfdMakeSharedScene() provides an easy to use mechanism for this task.
Minimize the number of very small pfGeoSets (that is, those containing four or fewer total triangles). Each tiny pfGeoSet means another bounding box to test against if you are culling down to the pfGeoSet level (that is, when PFCULL_GSET is set with pfChanTravMode()) as well as another item to sort during culling. (If your pfGeoSets are large, on the other hand, you should definitely cull down to the pfGeoSet level.)
Be sparing in the use of pfLayers. Layers imply that pixels are being filled with geometry that is not visible. If fill performance is a concern, this should be minimized in the modeling process by cutting layers into their bases when possible. However, this will produce more polygons which require more transform and host processing; so, it should only be done if it will not greatly increase database size.
Make the hierarchy of the database spatially coherent so that culling will be more accurate and geometry that is outside the viewing frustum will not be drawn. (See Figure 4-3 for an example of a spatially organized database.)
Construct your database to minimize the draw-process time spent traversing and rendering the culled part of the database without the cull-process time becoming the limiting performance factor. This process involves making tradeoffs as a simpler cull means a less efficient draw stage. This section describes these tradeoffs and some good rules to follow to give you a good start.
If the cull and draw processes are performed in parallel, the goal is to minimize the larger of the culling and drawing times. In this case, an application can spend approximately the same amount of time on each task. However, if both culling and drawing are performed in the same process, the goal is to optimize the sum of these two times, and both processes must be streamlined to minimize the total frame time. Important parameters in this optimization include the number of pfGeoSets, the average branching factor of the database hierarchy, and the enabled channel culling traversal modes. The pfDrawChanStats() function (see Chapter 23, “Statistics”) can easily provide diagnostic information to aid in this tuning.
The average number of immediate children per node can directly affect the culling process. If most nodes have a high number of children, the bounding spheres are more likely to intersect the viewing frustum and all those nodes will have to be tested for visibility. At the other extreme, a very low number of children per node will mean that each bounding sphere test can only eliminate a small part of the database and so many nodes may still have to be traversed. A good place to start is with a quad-tree type organization where each node has about four children and the bounding geometry of sibling nodes are adjacent but have minimal intersection. In the ideal case, projected to a two-dimensional plane on the ground, the spatial extent of each node and its parents would form a hierarchy of boxes.
The transition from pfGeodes to pfGeoSets is an important point in the database structure. If there are many very small pfGeoSets within a single pfGeode, not culling down to pfGeoSets can actually improve overall frame time because the cost of drawing the tiny pfGeoSets may be small relative to the time spent culling them. Adding more pfGeodes to break up the pfGeoSets can help by providing a slightly more accurate cull at less cost than considering each pfGeoSet individually. In addition, pfGeodes are culled by their bounding spheres, which is faster than the culling of pfGeoSets, which are culled by their bounding boxes.
The size (both spatial extend and number of triangles) can also directly impact culling and drawing performance. If pfGeoSets are relatively large, there will be fewer to cull so pfGeoSet culling can probably be afforded. pfGeoSets with more triangles will draw faster. However, pfGeoSets with larger spatial extent are more likely to have geometry being drawn outside of the viewing frustum; this wastes time in the graphics stage. Breaking up some of the large pfGeoSets can improve graphics performance by allowing a more accurate cull.
With some added cost to the culling task, the use of level-of-detail nodes (pfLODs) can make a tremendous difference in graphics performance and image quality. LODs allow objects to be automatically drawn with a simplified version when they are in a state that yields little contribution to the scene (such as being far from the eyepoint). This allows you to have many more objects in your scene than if you always were drawing all objects at full complexity. However, you do not want the cull to be testing all LODs of an object every frame when only one will be used. Again, proper use of hierarchy can help. pfLODs (non-fading) can be inserted into the hierarchy with actual object pfLODs grouped beneath them. If the parent LOD is out of range for the current viewpoint, the child LODs will never be tested. The pfLODs of each object can be placed together under a pfGroup so that no LOD tests for the object will be done if the object is outside of the viewing frustum.
Calling pfFlatten(), pfdFreezeTransforms(), or pfdCleanTree() to remove extraneous nodes can often help culling performance. Use pfFlatten() to de-instance and apply pfSCS node transformations to leaf geometry—resulting in less work during the cull traversal. This allows both better database sorting for the draw and also better caching of matrix and bounding information, which can speed up culling. When these scene graph modifications are not acceptable, you may reduce cull time by turning off culling of pfGeoSets but this will directly impact rendering performance by forcing the rendering of geometry that is outside the viewing frustum.
On machines with fast-texture mapping, texture should be used to replace complex geometry. Complex objects, such as trees, signs, and building fronts, can be effectively and efficiently represented by textured images on single polygons in combination with applying pfAlphaFunc() to remove parts of the polygon that do not appear in the image. Using texture to reduce polygonal complexity can often give both an improved picture and improved performance. This is because of the following:
The image texture provides scene complexity, and the texture hardware handles scaling of the image with MIPmap interpolation functions for minification (and, on RealityEngine systems, Sharpen and DetailTexture functions for magnification).
Using just a few textured polygons rather than a complex model containing many individual polygons reduces system load.
In order to represent a tree or other 3D object as a single textured polygon, OpenGL Performer can rotate polygons to always face the eyepoint. An object of this type is known as a billboard and is represented by a pfBillboard node. As the viewer moves around the object, the textured polygon rotates so that the object appears three-dimensional. For more information on billboards, see “pfBillboard Nodes” in Chapter 3.
To determine if the current graphics platform has fast-texture mapping, look for a PFQFTR_FAST return value from the following call:
pfFeature(PFQFTR_TEXTURE, &ret);
|
pfAlphaFunc() with a function PFAF_GEQUAL and a reference value greater than zero can be used whenever transparency is used to remove pixels of low contribution and avoid their expensive processing phase.
For maximum performance, routines that make extensive use of the OpenGL Performer linear algebra routines should use the macros defined in prmath.h to allow the compiler to in-line these operations.
Use single- rather than double-precision arithmetic where possible and avoid the use of short-integer data in arithmetic expressions. Append an `f' to all floating point constants used in arithmetic expressions.
| BAD | In this example, values in both of the expressions involving the floating point variable x are promoted to double precision when evaluated:
| ||
| GOOD | In this example, both of the expressions involving the floating point variable x remain in single-precision mode, because there is an `f' appended to the floating point constants:
|
Performance measurement tools can help you track the progress of your application by gathering statistics on certain operations. OpenGL Performer provides run-time profiling of the time spent in parts of the graphics pipeline for a given frame. The pfDrawChanStats() function displays application, cull, and draw time in the form of a graph drawn in a channel; see Chapter 23, “Statistics”, for more information on that and related functions. There are advanced debugging and tuning tools available from SGI that can be of great assistance.The WorkShop product in the CASEVision tools provides a complete development environment for debugging and tuning of host tasks. The Performance Co-Pilot helps you to tune host code in a real-time environment. There is also the WindView product from WindRiver that works with IRIX REACT to do full system profiling in a real-time environment. However, progress can be made with the basic tools that are in the IRIX development environment: prof and pixie. On Linux, use gprof and on Microsoft Windows use VTune (see www.intel.com/software/products/vtune). The OpenGL debugging utility, ogldebug, can also be used to aid in performance tuning. This section briefly discusses getting started with these tools.
| Note: See the graphics library manual available from SGI for complete instructions on using these graphics tools. See the IRIX System Programming Guide to learn more about pixie and prof. |
| Note: This section does not pertain to Microsoft Windows systems. |
You can use the IRIX performance analysis utilities pixie and prof to tune the application process. For Linux, use gprof. Use pixie for basic-block counting and use prof or gprof for program counter (PC) sampling. PC sampling gives run-time estimation of where significant amounts of time are spent, whereas basic-block counting will report the number of times a given instruction is executed.
To isolate statistics for the application process, even in single-process models, run the application through pixie or prof in APP_CULL_DRAW mode to separate out the process of interest. Both pixie and prof can generate statistics for an individual process.
When using OpenGL Performer DSO libraries with prof you may want to provide the -dso option to prof with the full pathname of the library of interest to have OpenGL Performer routines included in the analysis. When using pixie, you will need to have the .pixie versions of the DSO libraries in your LD_LIBRARY_PATH. Additionally, you will need a .pixie version of the loader DSO for your database in your LD_LIBRARY_PATH. You may have to pixie the loader DSO separately since pixie will not find it automatically if your executable was not linked with it. When using prof to do PC sampling, link with unshared libraries exclusively and use the –p option to ld. Then set the environment variable PROFDIR to indicate the directory in which to put profiling data files.
When profiling, run the program for a while so that the initialization will not be significant in the profiling output. When running a program for profiling, run a set number of frames and then use the automatic exit described below.
You can use the graphics utility ogldebug to both debug and tune OpenGL Performer applications. Note that ogldebug can handle multiprocessed programs.
Use ogldebug to do the following:
Show which graphics calls are being issued.
Look for frequent mode changes or unnecessary mode settings that can be caused if your initialization of the global state does not match the majority of the database.
Look for unnecessary vertex bindings such as unneeded per-vertex colors or normals for a flat-shaded object.
Follow these steps to examine one frame of the application in an ogldebug session:
Start the profiler of your choice:
ogldebug your_prog_name prog_options
Turn off output and breakpoints from the control panel.
Under IRIX and Linux, set a breakpoint at glXSwapBuffers().Under Microsoft Windows, set a breakpoint at wglSwapBuffers().
Click the “Continue” button and go to the frame of interest.
Turn on breakpoints.
Execution stops at glXSwapBuffers().
Turn on all trace output.
Click the “Continue” button.
Execution stops at the next glSwapBuffers(), outputting one full scene to progname.pid.trace.
Quit and examine the output.
Note: Since OpenGL Performer avoids unnecessary mode settings, recording one frame shows modes that are set during that frame, but it does not reflect modes that were set previously. It is, therefore, best to have a program that can come up in the desired location and with the desired modes, then grab the first two frames: one for initialization and one for continued drawing.
This section lists some general guidelines to keep in mind when debugging OpenGL Performer applications.
Because malloc() does not allocate memory until that memory is used, core dumps may occur when arenas do not find enough disk space for paging. On IRIX systems, the kernel can be configured to actually allocate space upon calling malloc(), but this change is pervasive and has performance ramifications for fork() and exec(). Reconfiguring the kernel is not recommended, so be aware that unexplained core dumps can result from inadequate disk space.
Be sure to initialize pointers to shared memory and all other nonshared global values before OpenGL Performer creates the additional processes in the call to pfConfig(). Values put in global variables initialized after pfConfig() will only be visible to the process that set them.
For detailed information about other aspects of shared memory, see “Memory Allocation” in Chapter 18.
When debugging an application that uses a multiprocess model, first use a single-process model to verify the basic paths of execution in the program. You do not have to restructure your code; simply select single-process operation by calling pfMultiprocess( PFMP_APPCULLDRAW) to force all tasks to initiate execution sequentially on a frame-by-frame basis.
If an application fails to run in multiprocess mode but runs smoothly in single-process mode, you may have a problem with the initialization and use of data that is shared among processes.
If you need to debug one of multiple processes, use the following command while the process is running:
IRIX% dbx -p progname LINUX% gdb progname pid |
For Microsoft Windows, use the following commands:
set PATH=%PFROOT%\Lib\Debug;%PATH% msdev programName programParameters |
The preceding is how you debug using Microsoft Developer Studio 6.0.
This will show the related processes and allow you to choose a process to trace. The application process will always be the process with the lowest process ID. In order after that will be the (default) clock process, then the cull process, and then the draw.
Once the program works, experiment with the different multiprocess models to achieve the best overall frame rate for a given machine. Do not specify more processes than CPUs. Use pfDrawChanStats() to compare the frame timings of the different stages and frame times for the different process models.
Arrange error handling for floating-point operations. To see floating-point errors, turn debug messages on and enable floating-point traps. Set pfNotifyLevel( PFNFY_DEBUG).
The goal is to have no NaN (Not a Number), INF (infinite value), or floating-point exceptions resulting from numerical computations.
If a NULL or invalid function pointer is called, the program dies with a segmentation fault, bus error, or invalid instruction, and the debugger is often unable to give a stack trace.
(dbx or gdb) where
> 0 <Unknown>() [< unknown >, 0x0]
|
When this happens on IRIX, you can usually still get a single level of trace by looking at the return address register.
(dbx) $ra/i
[main:6, 0x400c18] lw ra,28(sp)
|
Once you know this information, you may be able to set a breakpoint to stop just before the bad function pointer and then get a full stack trace from there.
On Microsoft Windows, do the following:
Ensure that the path to the debug libraries is set:
set PATH=%PFROOT%\Lib\Debug;%PATH%
Run the program from your normal development environment.
Enter the following command:
set _PF_DISPLAY_MODULES_LOADED=1
Debuggers like dbx and gdb allow you to set a breakpoint or trace on a particular variable or address in memory.
However, this feature does not work well on programs that use atomic shared memory access functions like test_and_set() which are implemented on IRIX using the MIPS instructions ll and sc. Calling such a function on an address that is on the same memory page (typically 4096 bytes) as the address where a breakpoint is set results in the program being killed with a SIGTRAP signal.
OpenGL Performer uses test_then_add() to implement pfMemory::ref() and pfMemory::unref(); so, you almost always run into this problem if you try to trace a member of an OpenGL Performer object (anything derived from pfMemory).
You can get around the problem by setting the following environment variable before running the program.
Under IRIX and Linux:
% setenv _PF_OLD_REFCOUNTING |
Under Microsoft Windows:
set _PF_OLD_REFCOUNTING=1 |
This tells OpenGL Performer to use an alternate (slower) implementation of shared memory reference counting that avoids the ll and sc operations so that breakpoints on variables can be used.
A number of tools are available for debugging memory corruption errors and memory leaks; no single one is ideal for all purposes. We will briefly describe and compare two useful tools: purify and libdmalloc.
Purify is a product of PureAtria; see their Web site, http://www.pureatria.com for ordering information.
Purify works by rewriting your program (and all dynamic shared libraries it uses), intercepting malloc and associated functions, and inserting instruction sequences before each load and store instruction that immediately catch invalid memory accesses (that is, uninitialized memory reads, out-of-bounds memory reads or writes, freed memory reads or writes, and multiple frees) and also keeps track of memory leaks. When an error is encountered, a stack trace is given for the error as well as a stack trace from when the memory in question was originally allocated. When used in conjunction with a debugger like dbx or gdb , you can set a breakpoint to stop when Purify encounters an error so that you can examine the program state.
Purify is immensely useful for tracking down memory problems. Its main drawbacks are that it is very slow (to compile and run programs) and it currently does not know about the functions amalloc(), afree(),and arealloc(), which are very important in OpenGL Performer applications (pfMalloc and associated functions are implemented in terms of them).
You can trick Purify into telling you about some shared arena memory access errors by telling the run-time linker to use malloc in place of amalloc; however, this cannot work if there are forked processes sharing the arena, so to use this trick you must run in single-process (PFMP_APPCULLDRAW) mode. To do this, compile the following into a DSO called pureamalloc.so:
malloc(int n) {return malloc(n);}
afree(void*p) {free(p);}
arealloc(void*p, int n) {return realloc(p, n);}
|
Then tell the run-time linker to point to it:
% setenv _RLDN32_LIST `pwd`/pureamalloc.so:DEFAULT |
This assumes you are using the N32 ABI; see the rld man page for the equivalents for the O32 and 64 ABIs.Then run perfly -m0 or any other program in PFMP_APPCULLDRAW mode.
For more information on Purify, visit PureAtria's web site: http://www.pureatria.com.
libdmalloc is a library that was developed internally at SGI. It is officially unsupported but you can get it through OpenGL Performer's ftp site.
libdmalloc is implemented as a dynamic shared object (DSO) that you can link in to your program at run-time. It intercepts all calls to malloc(), free(), and associated functions and checks for memory corruption of the particular piece of memory being accessed. It also attempts to purposely break programs that make bad assumptions: it initializes newly malloced (or amalloced) memory with a fill pattern to break programs that depend on it being 0's and similarly fills freed memory with a fill pattern to break programs that look at freed memory. Finally, the entire malloc arena and any shared arenas are checked for corruption during exit() and execve(). Error messages are printed to stderr whenever an error is detected (which is typically later than the error actually occured, unlike Purify's immediate detection). libdmalloc does not know about UMRs (uninitialized memory reads) or stack variables, unlike Purify.
libdmalloc's advantages are that it knows about amalloc/afree/arealloc, and it has virtually no overhead; so, you can leave it on all the time (it will check for errors in every program you run). If it uncovers a reproducible bug in an area that Purify knows about too, then you can use Purify to trace the exact location of the problem— Purify is much better at that than libdmalloc.
When using libdmalloc, you can easily toggle verbose tracing of all calls to malloc()/free()/realloc() and amalloc()/afree()/arealloc() by sending the processes a signal at run time— there should be none of these calls per-frame in the main pipeline of a tuned OpenGL Performer application.
For more information, install libdmalloc from the OpenGL Performer ftp site and read the files /usr/share/src/dmalloc/README and, for OpenGL Performer-specific suggestions, /usr/share/src/dmalloc/SOURCEME.dmalloc.performer.
This section contains some specific notes on performance tuning with RealityEngine graphics.
Multisampling provides full-scene antialiasing with performance sufficient for a real-time visual simulation application. However, it is not free and it adds to the cost of some other fill operations. With RealityEngine graphics, most other modes are free until you add multisampling— multisampling requires some fill operations to be performed on every subpixel. This is most noticeable with z-buffering and stenciling operations but also applies to glBlendFunc(). Texturing is an example of a fill operation that can be free on a RealityEngine and is not affected by the use of multisampling.
The multisampling hardware reduces the cost of subpixel operations by optimizing for pixels that are fully opaque. Pixels that have several primitives contributing to their result are thus more expensive to evaluate and are called complex pixels. Scenes usually end up having a very low ratio of complex pixels.
Multisampling offers an additional performance optimization that helps balance its cost: a virtually free screen clear. Technically, it does not really clear the screen but rather allows you to set the z values in the framebuffer to be undefined. Therefore, use of this clear requires that every pixel on the screen be rendered every frame. This clear is invoked with a pfEarthSky using the PFES_TAG option to pfESkyMode(). Refer to the pfEarthSky(3pf) man page for more detailed information.
There are two ways of achieving transparency on a RealityEngine: blending and screen-door transparency with multisampling.
Blended transparency, using the routine glBlendFunc(), can be used with or without multisampling. Blending does not increase the number of complex pixels but is expensive for complex pixels.
To reduce the number of pixels with very low alpha, one can use a pfAlphaFunc() that ignores pixels of low alpha, such as alpha less than 3 or 4. This will slightly improve fill performance and probably not have a noticeable effect on scene quality. Many scenes can use values as high as 60 or 70 without suffering degradation in image quality. In fact, for a scene with very little actual transparency, this can reduce the fuzzy edges on textures that simulate geometry (such as trees and fences) that arise from MIP-mapping.
Screen-door transparency gives order-independent transparent effects and is used for achieving the fade-LOD effect. It is a common misperception that screen-door transparency on RealityEngine gives you n levels of transparency for n multisamples. In fact, n samples gives you 4n levels of transparency, because RealityEngine uses 2-pixel by 2-pixel dithering. However, screen-door transparency causes a dramatic increase in the number of complex pixels in a scene, which can affect fill performance.
Texturing is free on a RealityEngine if you use a 16-bit texel internal texture format. There are 16-bit texel formats for each number of components. These formats are used by default by OpenGL Performer but can be set on a pfTexture with pfTexFormat(). Using a 32-bit texel format will yield half the fill rate of the 16-bit texel formats.
Do not use huge ranges of texture coordinates on individual triangles. This can incur both an image quality degradation and a severe performance degradation. Keep the maximum texture coordinate range for a given component on a single triangle under the following value:
1 << (13-log |
2(TexCSize))
where TexCSize is the size in the dimension of that component.
The use of Detail Texture and Sharpen can greatly improve image quality. Minimize the number of different detail and sharpen splines (or just use the internal default splines). Applying the same detail texture to many base textures can incur a noticeable cost when base textures are changed. Detail textures are intended to be derived from a high-resolution image that corresponds to that of the base texture.
It is often very difficult to analyze a single missed frame by using the pfChannel statistics displays. OpenGL Performer is instrumented to generate internal timing events and write them into a file upon an application program request. You can analyze these collected events at your own pace using a graphic analysis tool. EventView is such a tool.
| Note: EventView was originally developed by Ran Yakir from BVR Systems. |
Each event has a start time and an end time. Together they bind the execution of important parts of an OpenGL Performer frame in the various OpenGL Performer processes. The captured event durations are similar to the durations presented in pfFrameStats. However, EventView events can be written to a file and analyzed offline after the execution of an OpenGL Performer program completes. In addition, an application program can design its private set of events and can merge them into the same output file as the OpenGL Performer internal events.
The following subsections describe the use of EventView:
EventView provides an analysis program called evanalyzer for generating a graphic display of the captured events. Figure 24-1 shows a sample screen from the evanalyzer program. Each row contains events of a single type. For each event, its start is marked by a vertical line, its duration is marked by a horizontal line, and its end is marked by another vertical line extending upward.

Use the following functions in order to control EventView event collection:
This section provides samples of the simplest use of EventView and a more complex use.
The simplest way to use EventView is to use only OpenGL Performer internal events. In this case, an application program may look like the following:
main()
{
pfInit();
// Initialize event capture. Call between pfInit and pfConfig.
pfInitializeEvents();
pfConfig();
// Create window & scene graph.
....
// Start event capture
pfEventSampleOn();
for (i = 0 ; i < numFrames ; i ++)
{
pfSync();
pfFrame();
}
// Stop event capture.
pfEventSampleOff();
// Write to file.
pfWriteEvents("events.timefile");
}
|
After the program completes, you can analyze the generated events using the command evanalyzer events.timefile.
In a more complex case, an application has some private events that it wishes to add to the captured event file. Two stages are necessary:
Stage 1
You must define application's private events in a file. The following example defines a single event named myDrawCB and assigns a single information slot of type integer for this event:
file "myEvents.timefile";
max_events 10000;
c_file "myEvents.c";
h_file "myEvents.h";
active true;
conditional_sampling true;
malloc "pfSharedMalloc";
event "myDrawCB"
{
info "CB_Info"
{
name "Something" ;
type int ;
};
};
|
Running the command evpp on the preceding file creates the two files myEvents.c and myEvents.h. The application should compile and link with the newly generated file myEvents.c. The file myEvents.h contains macros that the application uses to control event capturing.
Stage 2
The following application code generates an event of type myDrawCB in a DRAW callback of some node in the scene graph. Every time the program generates an event, the program assigns a value to its information slot:
int pre_draw_cb(pfTraverser *trav, void *userData)
{
int someValue;
// Mark the start of private event MyDrawCB.
EVENT_START_MYDRAWCB;
// Assign value to the information field of this event.
EVENT_MYDRAWCB_INFO_CB_Info (someValue);
... Run callback code.
// Mark the end of private event MyDrawCB.
EVENT_END_MYDRAWCB;
}
main()
{
pfGeode *geode;
pfInit();
// Initialize Performer-internal event capture.
pfInitializeEvents();
// Initialize application-private event capture.
EVENT_INIT;
pfConfig();
// Create window & scene graph.
....
// Setup DRAW callback on a node.
pfNodeTravFuncs(geode, PFTRAV_DRAW, pre_draw_cb, NULL);
// Start event capture on all initialized event sets
// (Performer-internal and application-private).
EVENT_SAMPLE_ALL_ON;
for (i = 0 ; i < numFrames ; i ++)
{
pfSync();
pfFrame();
}
// Stop event capture on all initialized event sets..
EVENT_SAMPLE_ALL_OFF;
// Write all captured events from all initialized sets to a file.
// Since we named a file in the evpp input file,
// we need not specify it here.
EVENT_WRITE_ALL;
}
|
As in the first example, after the program completes, you can analyze the generated events using the command evanalyzer myEvents.timefile. This time the file contains both OpenGL Performer internal events and application-private events (myDrawCB). Clicking the right-hand mouse button on the line marked myDrawCB can toggle the display of the information field on this event. Figure 24-2 shows sample output with a user event. The top row of the display shows the user event myDrawCB.

Note that it was not necessary to start and stop the sampling of OpenGL Performer internal events. The EVENT_SAMPLE_ALL_ON and EVENT_SAMPLE_ALL_OFF macros start and stop sampling for all currently initialized event sets.
The EventView toolset contains the following tools:
The following sections describe these tools in more detail.
The program evpp is a preprocessor for adding user events to an OpenGL Performer program. As input, it expects a text file describing a set of new event types. It produces a C source file and a C include file. To enable the recording of the newly generated events, you must compile and link the new C source file in your program.
Sample Input File
The following is an example of an evpp input file:
file "out.timefile";
max_events 10000;
c_file "myEvents.c";
h_file "myEvents.h";
active true;
conditional_sampling true;
malloc "pfSharedMalloc";
group "my_APP" 0x000001;
group "my_Cull_CB" 0x000002;
group "my_APP"
{
event "my_pfFrame";
event "my_pfSync";
};
group "my_Cull_CB"
{
event "my_Cull_Group_CB"
{
size 5;
};
event "my_Cull_DCS_CB"
{
size 5;
};
};
event "myCB"
{
info "myInfo"
{
type int;
name "myInfoName";
};
}
|
The preceding file defines two groups of events. Each group contains two events. In the second group (my_Cull_CB), each event is an array of five events. This is useful for generating the same event types from different processes. In this case, each CULL process will generate events on callbacks to pfGroups and pfDCS. The preceding file also defines an event called myCB,which does not belong to any group. This event contains a single information slot of type integer.
The input file contains the following directives
| Directive | Description | |
| file | Specifies the output filename. If the character ? is used instead of a filename, the generated macros EVENT_WRITE and EVENT_WRITE_ALL will require a filename as a parameter. | |
| max_events | Specifies the maximum number of events that will be allocated and captured. | |
| c_file | Specifies the filename for the source code file that evpp generates. | |
| h_file | Specifies the filename of the include file that evpp generates. | |
| active | Determines whether evpp will generate empty macros. This directive may be true or false. This is useful when trying to avoid generating any macros without changing any application source code. | |
| conditional_sampling | Determines whether events will be captured. This directive can be true or false. If false, events will be captured regardless of the call to EVENT_SAMPLE_ON. | |
evpp Command-Line Options
The following are the evpp command-line options:
| Option | Description | |
| –h | Prints the usage string. | |
| –c | Compiles the generated files. This option can make makefiles simpler. | |
| –n | Sets all the events in the input file to inactive. The macros generated for all events will be empty. This flag is useful when trying to disable the instrumentation of a source file without removing the macros. |
The program evanalyzer generates a graphic display of captured events. Each line in its display contains events of a single type. The horizontal axis of the display denotes the time.
View of a Single Event
Figure 24-3 shows a graphic representation of a single event.
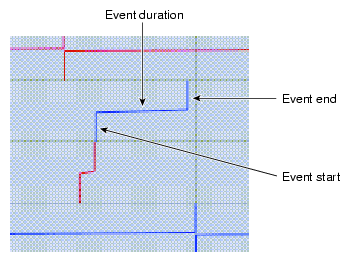
An event starts at a vertical bar from the bottom of the event line to its middle, continues horizontally, and ends as a vertical bar from the middle of the event line to its top.
Keyboard and Mouse Controls
The following are the keyboard and mouse controls for evanalyzer:
| Control | Description | |
| Up/Down arrows | Changes the zoom factor of the display. | |
| Right/Left arrows | Shifts the display window across the captured data. | |
| Left mouse button | Picks an event start or end point. Clicking on one event start or end point and releasing on another prints the time difference between the two on the top of the display. | |
| Middle mouse button | Drags the event display window across the captured data. | |
| Right mouse button | If the mouse is on an event line and the event has information fields, allows toggling of their display. If the mouse is not on an event line, this button toggles events displayed and groups displayed. | |
| h key | Brings up the histogram program (evhist) and runs it on the currently selected event. | |
| f key | If the event line under the mouse has information slots, prompts for a slot. Brings up a function plot program (evgraph) and runs it on the selected information slot on the current event. | |
| Esc key | Exits evanalyzer. |
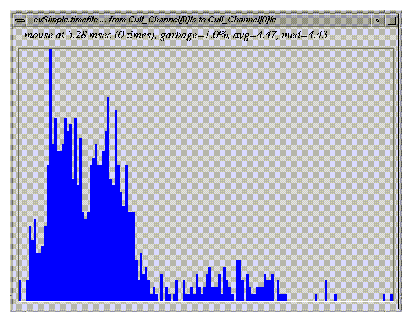
The display program evhist generates histograms of event durations. It is usually activated from within evanalyzer.
Moving the mouse across the window prints the number of samples that are on the histogram bar under the mouse and what time value it represents. Figure 24-4 contains a sample screen of evhist.
The following are the keyboard controls for evhist:
| Control | Description | |
| Up/Down arrows | Change the resolution of the histogram. | |
| Right/Left arrows | Change the percentage of samples on both extremes of the histogram that we ignore (displayed as garbage on the top of the display). | |
| Esc key | Exits evhist. |
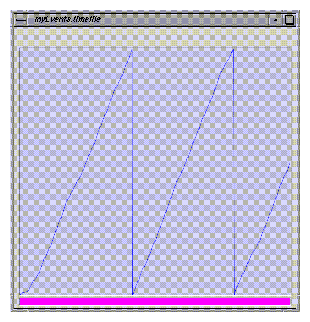
The display program evgraph plots the information slot of a given event type. It is usually activated by evanalyzer. Figure 24-5 shows a sample display of evgraph.
The following are the keyboard and mouse controls for evgraph:
| Control | Description | |
| Up/Down arrows | Changes the resolution of the plot. | |
| Right/Left arrows | Translates the plot horizontally. | |
| Middle mouse button | Drags the plot horizontally. |
Performance tuning typically requires finding a portion of the frame time that takes too long to execute and taking measures to shrink its duration. EventView enables bounding some major OpenGL Performer internal functions and measuring their duration.
To make the EventView toolset useful, you have to understand the position and relationships of the OpenGL Performer internal events and the OpenGL Performer internal processing that they bound. This section places the OpenGL Performer internal events in the context of OpenGL Performer functions.
An application calls the OpenGL Performer function pfSync() to synchronize with the hardware video frame rate. OpenGL Performer packs multiple internal management tasks into this function because the application process has already finished its processing for this frame; so, this is the least critical time in the frame. The following pseudo code describes the main processing units of pfSync() and shows what EventView events are generated during the pfSync() duration:
pfSync()
{
EVENT_START - pfSync
... clean scene graph (first time).
... Recompute bounding spheres of nodes modified between the
... previous call to pfFrame and the present time.
EVENT_START - New_Updatables
...process all newly generated nodes for this frame.
EVENT_END - New_Updatables
EVENT_START - MergeBuffers
... Process call to pfMergeBuffers from a DBASE process.
... Process new nodes that the DBASE process merged.
EVENT_END - MergeBuffers
EVENT_START - App_Trav
... Run APP traversal on all nodes.
EVENT_END - App_Trav
EVENT_START - pfSync_Clean
... clean scene graph (second time)
... Recompute bounding spheres of nodes modified during the APP
... traversal.
EVENT_END - pfSync_Clean
... Update internal stats.
... Update pfASD positions.
... Update clip-texture emulation internals.
EVENT_START - pfSync_Sleep
... Sleep until start of next video frame.
EVENT_END - pfSync_Sleep
EVENT_END - pfSync
}
|
The OpenGL Performer function pfFrame() is responsible for initiating a new rendering frame. It contains the minimal necessary processing for spawning other OpenGL Performer processes for a new frame. The following pseudo code describes the main processing units that pfFrame() contains and the EventView events it generates:
pfFrame()
{
EVENT_START - pfFrame
EVENT_START - pfFrame_Clean
... Clean scene graph.
... Recompute bounding spheres of nodes modified between the
... previous call to pfSync and the present time.
EVENT_END - pfFrame_Clean
... Check all CULL processes for completion of previous frame.
... Decide what CULL processes should start a new frame.
EVENT_START - pfFrame_Updates
... Send forked processes (CULL, ISECT, DBASE, COMPUTE) to copy
... all scene graph changes from APP copy of the scene graph to
... their private copy of the scene graph.
... Wait for all above processes to finish updating their copy
... of the scene graph.
EVENT_END - pfFrame_Updates
... Execute all unforked processes as part of the APP process.
EVENT_END - pfFrame
}
|
The following pseudo code shows the main processing units of the CULL process and the EventView events that it generates. The code portion shown spans a single CULL process frame:
while(1)
{
EVENT_START - Cull
EVENT_START - Cull_Updates
... Copy all scene graph changes from the APP copy of the
... scene graph to the CULL copy of the scene graph.
EVENT_END - Cull_Updates
for each channel on this pipe do
EVENT_START - Cull_Channel
... Call CULL traversal on this channel.
EVENT_END - Cull_Channel
EVENT_END - Cull
}
|
The following pseudo code shows the main processing units of the DRAW process and the EventView events that it generates. The code portion shown spans a single DRAW process frame:
while (1)
{
EVENT_START - Draw
... for each channel on this pipe do
EVENT_START - Draw_Channels
.... Call the drawing function on a channel.
EVENT_END - Draw_Channels
EVENT_END - Draw
}
|