This chapter describes objects that manage nongraphic tasks, including the following:
Queues
Clocks
Memory allocation
Asynchronous I/O
Error handling and notification
File search paths
A pfQueue object is a queue of elements, which are all the same type and size; the default size is the size of a void pointer. A pfQueue object actually consists of three interrelated queues, as shown in Figure 18-1.
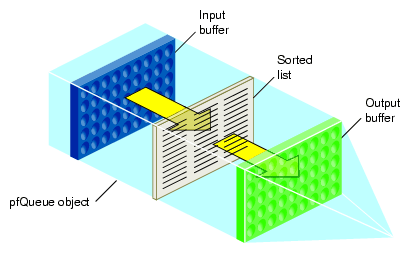
Input buffer—where processes dump values to be added to the pfQueue object
Output buffer—values at one end of the queue that processes may remove from the output buffer pfQueue object
Sorted list—sorted values that processes may not remove from the pfQueue object

Note: In nonsorting mode, there is only the input buffer; values in the output buffer and the sorted list are transferred into the input buffer.
Values in the input buffer are not sorted and are not part of the sorted list. Values in the sorted list and the output buffer are sorted (when the pfQueue object is in sort mode) according to a user-defined sorting function. Sorted values of highest priority are automatically moved from the sorted list to the output buffer whenever the pfQueue object is sorted. Priority is defined by the sorting function, for example, if a pfQueue object contains pointers to tiles of texture, the sorting function might sort according to the proximity of the viewer and the tile: the closer the tile is to the viewer, the higher its priority, and the more likely the pointer to the tile will be in the output buffer. Processes do not have access to values in the sorted list; only to those values in the output buffer.
Because there are separate input and output buffers, multiple processes can add or retrieve elements, but only one process can actually insert elements into the input buffer and one process retrieve elements from the output buffer at one time. The process adding elements to the input buffer can be different from the process removing elements from the output buffer.
The contents of the pfQueue object can be any fixed-size object; for example, pfQueues often contain pointers to OpenGL Performer objects. You might use a pfQueue object, for example, to organize tiles of texture according to the direction the viewer is looking and the proximity of the viewer to the tiles. Because you declare the size and type of objects in the pfQueue in the constructor, you cannot change the type or size of its elements after its creation.
You can insert elements into the input buffer or remove them from the output buffer using the following methods, respectively:
pfQueue::insert()
pfQueue::remove()
These methods can be used by multiple processes asynchronously without collision.
| Warning: Do not insert NULL elements into the queue. |
The pfQueue object is resized dynamically when the number of elements inserted into the queue exceeds its declared size; the size is doubled automatically. Doubling the size prevents repeated, incremental, costly resizing of the queue.
| Tip: Doubling the size of the queue can cause excessive memory allocation. It is important therefore to accurately declare the size of the queue. |
You can set the size of the queue in the constructor of the pfQueue object or afterwards by using pfQueue::setArrayLen(). pfQueue::getNum() returns the number of elements in the queue.
It is possible for you to do the following:
It is much easier, however, to use the pfQueue::addServiceProc() method to perform all of those tasks. This method does the following:
Creates a thread.
Returns the thread ID.
Invokes the developer-supplied function in the argument of the function.
Deletes the thread.
The developer-supplied function must take as its argument an element from the output buffer and process it. For example, if the queue contains pointers to tiles of texture, the function might download a tile from disk to the image cache.
The pfQueue class provides a variety of other methods, described in Table 18-1, that return information about the threads created to process the elements in the output buffer of the pfQueue object.
Table 18-1. Thread Information
Method | Description |
|---|---|
getServiceProcPID() | Returns the ID of the created thread. |
pfGetGlobalQueueServiceProcPID() | Returns the ID of the nth thread. |
getNumServiceProcs() | Returns the number of currently active threads. |
pfGetNumGlobalQueueServiceProcs() | Returns the number of processes that have been sproc'd by all pfQueues. |
pfGetGlobalQueueServiceProcQueue() | Returns the pfQueue associated with a particular thread. |
exitServiceProc() | Terminates a specific thread. |
exitAllServiceProcs() | Terminates all pfQueue object threads. |
The pfQueue objects can run in one of two modes:
Either the elements in the queue are sorted according to some criteria specified by a developer-supplied sorting function or not.
The sorting function is NULL and the sorting mode is nonsorting by default.
In nonsorting mode, the sorted list and the output buffer are empty; all pfQueue elements are in the input buffer. Processes append new input objects to the front of the queue while (potentially) other processes read and remove pfQueue objects from the other end of the queue.
A process can potentially read and remove all of the elements in a nonsorted queue. Access to the elements is not random, however; it is sequential and ordered according to FIFO.
Multiple processes can add to the input buffer asynchronously. The objects remain unsorted and separate from the sorted list and output buffer until the sorting function is triggered. At that time, the following events occur:
The objects in the input buffer are flushed into the sorted list.
The objects in the sorted list and the output buffer are resorted together.
To sort the elements in a pfQueue, you do the following:
Specify a developer-supplied sorting function using pfQueue::setSortFunc().
Enable sorting by passing a non-NULL argument to pfQueue::setSortMode().
Specify the maximum and minimum number of values for the input and output of the sorting function using pfQueue::setInputRange() and pfQueue::setOutputRange().

Tip: You must specify the sorting function before enabling sorting; otherwise, sorting remains disabled and pfQueue returns a warning.
The sorting function runs in a separate thread parallel to the function specified in the argument of pfQueue. You can even specify that the sorting function run on a CPU different from the one processing the pfQueue object, as described in “Running the Sort Process on a Different CPU”.
In sorting mode, only those elements in the output buffer are available to processes. Access to the elements in the output buffer is not random, but sequential and in a FIFO order.
The sorting function sorts, according to its own criteria, the elements in the sorted list and the output buffer. To sort the queue, you must do the following:
Implement your own function to sort the pfQueue object.
Identify the function in your application using pfQueue::setSortFunc().
Make the function return a value of type that matches that of pfQueueSortFuncType.
Make the function handle an input data structure of type pfQueueSortFuncData(), defined as follows:
typedef struct { pfList *sortList; //list of elements to sort volatile int *inSize; //number of elements on input queue volatile int *outSize; //number of elements on output queue int inHi; // maximum number of elements at the input int inLo; // minimum number of elements at the input int outHi; // maximum number of elements at the output int outLo; // minimum number of elements at the output } pfQueueSortFuncData;
The actual data in the pfQueue object is maintained in a pfList, to which the pfQueueSortFuncData structure points.
The range values work as triggers to start the sorting function, which sleeps otherwise. For example, when the number of unprocessed inputs is greater than inHi, pfQueue calls the sorting function to sort the pfQueue object.
You can set the minimum and maximum number of input and output elements entered before the sort is triggered using the following methods:
pfQueue::setInputRange()
pfQueue::setOutputRange()
Table 18-2 shows the default range values:
The range values have no effect in nonsorting mode.
The sorting function sleeps until one of the following conditions occurs:
The number of elements in the input buffer exceeds the input maximum range value.
The number of elements in the output buffer drops below the output minimum range value.
pfQueue::notifySortProc() is called.
By increasing the maximum number of values allowed in the input buffer, or reducing the minimum number of values allowed in the output buffer, the sorting function is potentially called fewer times.
Table 18-2 shows that, using default range values, the queue is sorted when three or more elements are added to the input buffer or when two or less values remain in the output buffer.
The pfQueue::notifySortProc() method is provided for those times when the queue should be sorted without regard to the number of elements in the input or output buffers. For example, if an element in the queue changes, it might be necessary to re-sort the queue. If, for example, the elements are sorted alphabetically, the sort function should be explicitly called when one of the elements is renamed.
You can run the sorting process on a different CPU from the one processing the pfQueue by doing one the following:
Use getSortProcPID() to get the process ID of the sorting function and assigning the process to run on a specified CPU with OpenGL Performer or operating system utilities.
Use the pfuProcessManager provided in libpfutil. See the pfuInitDefaultProcessManager(3) man page for more information.
OpenGL Performer provides access to a high-resolution clock that reports elapsed time in seconds to support for timing operations. To start a clock, call pfInitClock() with the initial time in seconds—usually 0.0—as the parameter. Subsequent calls to pfInitClock() reset the time to whatever value you specify. To read the time, call pfGetTime(). This function returns a double-precision floating point number representing the seconds elapsed from initialization added to the latest reset value.
The resolution of the clock depends on your system type and configuration. In most cases, the resolved time interval is under a microsecond, and so is much less than the time required to process the pfGetTime() call itself. Silicon Graphics Onyx, Crimson, Indigo2, Indigo, and Indy™ systems all provide submicrosecond resolution. Newer systems, including Silicon Graphics Onyx2, Silicon Graphics Onyx3, Silicon Graphics Octane, Silicon Graphics Octane2, and Silicon Graphics O2 have even higher resolution clocks and use the CYCLE_COUNTER functionality through the syssgi(2). On a machine that uses a fast hardware counter, the first invocation of pfInitClock() forks off a process that periodically wakes up and checks the counter for wrapping. This additional process can be suppressed by using pfClockMode().
If OpenGL Performer cannot find a fast hardware counter to use, it defaults to the time-of-day clock, which typically has a resolution between one and ten milliseconds. This clock resolution can be improved by using fast timers. See the ftimer(1) man page for more information on fast timers.
By default, processes forked after the first call to pfInitClock() share the same clock and will all see the results of any subsequent calls to pfInitClock(). All such processes receive the same time.
Unrelated processes can share the same clock by calling pfClockName() with a clock name before calling pfInitClock(). This provides a way to name and reference a clock. By default, unrelated processes do not share clocks.
The video refresh counter (VClock) is a counter that increments once for every vertical retrace interval. There is one VClock per system. In systems where multiple graphics pipelines are present, but not genlocked (synchronized, see the setmon(3) man page), screen 0 is used as the source for the counter. A process can be blocked until a certain count, or the count modulo some value (usually the desired number of video fields per frame) is reached.
Table 18-3 lists and describes the pfVClock routines.
Routine | Action |
|---|---|
Initialize the clock to a value. | |
Get the current count. | |
Block the calling process until a count is reached. |
When using pfVClockSync(), the calling routine is blocked until the current count modulo rate is offset. The VClock functions can be used to synchronize several channels or pipelines.
You can use OpenGL Performer memory-allocation functions to allocate memory from the heap, from shared memory, and from data pools.
| Note: On Microsoft Windows systems, all memory allocation is from the heap. |
Table 18-4 lists and describes the OpenGL Performer shared-memory routines.
Table 18-4. Memory Allocation Routines
Routine | Action |
|---|---|
Create arenas for shared memory and semaphores. | |
Specify the size of a shared-memory arena. | |
Get the shared-memory arena pointer. | |
Get the shared-semaphore/lock arena pointer. | |
Allocate from an arena or the heap. | |
Release memory allocated with pfMalloc(). |
The pfMalloc() function can allocate memory either from the heap or from a shared memory arena. Multiple processes can access memory allocated from a shared memory arena, whereas memory allocated from the heap is visible only to the allocating process. Pass a shared-memory arena pointer to pfMalloc() to allocate memory from the given arena. pfGetSharedArena() returns the pointer for the arena allocated by pfInitArenas() or NULL if the given memory was allocated from the heap. Alternately, an application can create its own shared-memory arena; see the acreate(3P) man page for information on how to create an arena.
To allocate memory from the heap, pass NULL to pfMalloc() instead of an arena pointer.
Under normal conditions pfMalloc() never returns NULL. If the allocation fails, pfMalloc() generates a pfNotify() of level PFNFY_FATAL; so, unless the application has set a pfNotifyHandler(), the application will exit.
Memory allocated with pfMalloc() must be freed with pfFree(), not with the standard C library's free() function. Using free() with data allocated by pfMalloc() will have devastating results.
Memory allocated with pfMalloc() has a reference count (see “pfDelete() and Reference Counting” in Chapter 1 for information on reference counting). For example, if you use pfMalloc() to create attribute and index arrays, which you then attach to pfGeoSets using pfGSetAttr(), OpenGL Performer automatically tracks the reference counts for the arrays; this allows you to delete the arrays much more easily than if you create them without pfMalloc(). All the reference-counting routines (including pfDelete()) work with data allocated using pfMalloc(). Note, however, that pfFree() does not check the reference count before freeing memory; use pfFree() only when you are sure the data you are freeing is not referenced.
The pfGetSize() function returns the size in bytes of any data allocated by pfMalloc(). Since the size of such data is known, pfCopy() also works on allocated data.
Although dtat allocated by pfMalloc() behaves in many ways like a pfObject (see “Nodes” in Chapter 3), such data does not contain a user-data pointer. This omission avoids requiring an extra word to be allocated with every piece of pfMalloc() data.
| Note: Shared arenas are not pertinent to Microsoft Windows systems. |
The pfInitArenas() function creates two arenas, one for the allocation of shared memory with pfMalloc() and one for the allocation of semaphores and locks with usnewlock() and usnewsema(). The arenas are visible to all processes forked after pfInitArenas() is called.
Applications using libpf do not need to explicitly call pfInitArenas(), since it is invoked by pfInit().
The shared memory arena can be allocated by memory-mapping either swap space (/dev/zero, the default) or an actual disk file (in the directory specified by the environment variable PFTMPDIR). The latter requires sufficient disk space for as much of the shared memory arena as will be used, and disk files are somewhat slower than swap space in allocating memory.
By default, OpenGL Performer creates a large shared memory arena (256 MB on IRIX and 64 MB on Linux). Though this approach makes large numbers appear when you run ps(1), it does not consume any substantial resources, since swap or file system space is not actually allocated until accessed (that is, until pfMalloc() is called).
| Note: The following description applies only to IRIX systems. |
Because OpenGL Performer cannot increase the size of the arena after initialization, an application requiring a larger shared memory arena should call pfSharedArenaSize() to specify the maximum amount of memory to be used. Arena sizes as large as 1.7 GB are usually acceptable; but you may need to set the virtual-memory-use and memory-use limits, using the shell limit command or the setrlimit() function, to allow your application to use that much memory. To use arenas larger than 4 GB, you must use 64-bit operation.
If you are having difficulties in creating a large arena, it could be due to fragmentation of the address space from too many DSOs. You can reduce the number of DSOs you are using by compiling some of them statically. You can also change the default address of the DSOs by running the rqs(1) with a custom so_locations file.
An application requiring lockable pieces of memory should consider using pfDataPools, described in the following section. Alternatively, when a lock or semaphore is required in an application that has called pfInitArenas(), you can call pfGetSemaArena() to get an arena pointer, and you can allocate locks or semaphores using usnewlock() and usnewsema().
Datapools, or pfDataPools, are also a form of shared memory, but they work differently from pfMalloc(). Datapools allow unrelated processes to share memory and lock out access to eliminate data contention. They also provide a way for one process to access memory allocated by another process.
Any process can create a datapool by calling pfCreateDPool() with a name and byte size for the pool. If an unrelated process needs access to the datapool, it must first put the datapool in its address space by calling pfAttachDPool() with the name of the datapool. The datapool must reside at the same virtual address in all processes. If the default choice of an address causes a conflict in an attaching process, pfAttachDPool() will fail. To avoid this, call pfDPoolAttachAddr() before pfCreateDPool() to specify a different address for the datapool.
Any attached process can allocate memory from the datapool by calling pfDPoolAlloc(). Each block of memory allocated from a datapool is assigned an ID so that other processes can retrieve the address using pfDPoolFind().
Once you have allocated memory from a datapool, you can lock the memory chunk (not the entire pfDataPool) by calling pfDPoolLock() before accessing the memory. This locking mechanism works only if all processes wishing to access the datapool memory use pfDPoolLock() and pfDPoolUnlock(). After a piece of memory has been locked using pfDPoolLock(), any subsequent pfDPoolLock() call on the same piece of memory will block until the next time a pfDPoolUnlock() function is called for that memory.
The pfDataPools are pfObjects; so, call pfDelete() to delete them. Calling pfReleaseDPool() unlinks the file used for the datapool—it does not immediately free the memory that was used or prevent further allocations from the datapool; it just prevents processes from attaching to it. The memory is freed when the last process referring to the datapool pfDelete() to remove it.
A multiprocessed environment often requires that data be duplicated so that each process can work on its own copy of the data without adversely colliding with other processes. pfCycleBuffer is a memory structure which supports this programming paradigm. A pfCycleBuffer consists of one or more pfCycleMemories, which are equally-sized memory blocks. The number of pfCycleMemories per pfCycleBuffer is global, is set once with pfCBufferConfig(), and is typically equal to the number of processes accessing the data.
| Note: pfFlux replaces the functionality of pfCycleBuffer. |
Each process has a global index, set with pfCurCBufferIndex(), which indexes a pfCycleBuffer's array of pfCycleMemories. When each process has a different index (and its own address space), mutual exclusion is ensured if the process limits its pfCycleMemory access to the currently indexed one.
The “cycle” term of pfCycleBuffer refers to its suitability for pipelined multiprocessing environments where processes are arranged in stages like an assembly line and data propagates down one stage of the pipeline each frame. In this situation, the array of pfCycleMemories can be visualized as a circular list. Each stage in the pipeline accesses a different pfCycleMemory and at frame boundaries the global index in each process is advanced to the next pfCycleMemory in the chain. In this way, data changes made in the head of the pipeline are propagated through the pipeline stages by “cycling” the pfCycleMemories.
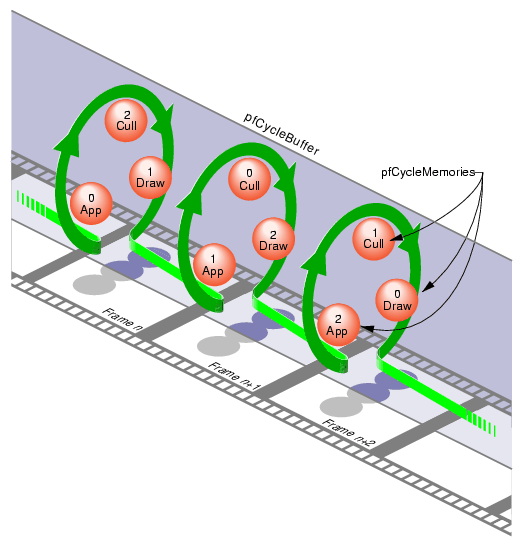
Cycling the memory buffers works if each current pfCycleMemory is completely updated each frame. If this is not the case, buffer cycling will eventually access a “stale” pfCycleMemory whose contents were valid some number of frames ago but are invalid now. pfCycleBuffers manage this by frame-stamping a pfCycleMemory whenever pfCBufferChanged() is called. The global frame count is advanced with pfCBufferFrame(), which also copies most recent pfCycleMemories into “stale” pfCycleMemories, thereby automatically keeping all pfCycleBuffers current.
A pfCycleBuffer consisting of pfCycleMemories of nbytes size is allocated from memory arena with pfNewCBuffer(nbytes, arena). To initialize all the pfCycleMemories of a pfCycleBuffer to the same data call, pfInitCBuffer(). pfCycleMemory is derived from pfMemory so you can use inherited routines like pfCopy() , pfGetSize(), and pfGetArena() on pfCycleMemories.
While pfCycleBuffers may be used for application data, their primary use is as pfGeoSet attribute arrays, for example, coordinates or colors. pfGeoSets accept pfCycleBuffers (or pfCycleMemory) references as attribute references and automatically select the proper pfCycleMemory when drawing or intersecting with the pfGeoSet.
| Note: libpf applications do not need to call pfCBufferConfig() or pfCBufferFrame() since the libpf routines pfConfig() and pfFrame() call these, respectively. |
A nonblocking file interface is provided to allow real-time programs access to disk files without affecting program timing. The system calls pfOpenFile(), pfCloseFile(), pfReadFile(), and pfWriteFile() work in an identical fashion to their IRIX counterparts open(), close(), read(), and write().
When pfOpenFile() or pfCreateFile() is called, a new process is created using sproc(), which manages access to the file. Subsequent calls to pfReadFile(), pfWriteFile(), and pfSeekFile() place commands in a queue for the file manager to execute and return immediately. To determine the status of a file operation, call pfGetFileStatus().
OpenGL Performer provides a general method for handling errors both within OpenGL Performer and in the application. Applications can control error handling by installing their own error-handling functions. You can also control the level of importance of an error.
Table 18-5 lists and describes the functions for setting notification levels.
Routine | Action |
|---|---|
Install user error-handling function. | |
Set the error-notification level. | |
Generate a notification. |
The pfNotify() function allows an application to signal an error or print a message that can be selectively suppressed. pfNotifyLevel() sets the notification level to one of the values listed in Table 18-6.
Table 18-6. Error Notification Levels
Token | Meaning |
|---|---|
Always print regardless of notify level. | |
Fatal error. | |
Serious warning. | |
Warning. | |
Information and floating point exceptions. | |
Debug information. | |
Floating point debug information. |
The environment variable PFNFYLEVEL can be set to override the value specified in pfNotifyLevel(). Once the notification level is set via PFNFYLEVEL, it cannot be changed by an application.
Once the notify level is set, only those messages with a priority greater than or equal to the current level are printed or handed off to the user function. Fatal errors cause the program to exit unless the application has installed a handler with pfNotifyHandler().
Setting the notification level to PFNFY_FP_DEBUG has the additional effect of trapping floating point exceptions such as overflows or operations on invalid floating point numbers. It may be a good idea to use a notification level of PFNFY_FP_DEBUG while testing your application so that you will be informed of all floating-point exceptions that occur.
OpenGL Performer provides a mechanism to allow referencing a file via a set of path names. Applications can create a search list of path names in three ways: the PFPATH environment variable, the function pfFilePathv(), or the function pfFilePath(). (Note that the PFPATH environment variable controls file search paths and has nothing to do with the pfPath data structure.)
Table 18-7 describes the routines for working with pfFilePaths.
Table 18-7. pfFilePath Routines
Routine | Action |
|---|---|
Create a search path. | |
Search for the file using the search path. | |
Supply current search path. |
You can specify a search path using pfFilePath(path), pfFilePathv(path0, path1, ..., pathn, NULL), or with the environment variable PFPATH. You can specify any number of directories using pfFilePath() and a maximum of 64 using pfFilePathv(). Colons separate path names on IRIX and Linux and semicolons on Windows. Since pfFilePathv() allows you to specify path names delimited by commas, it provides much more economy in coding compared to the use of pfFilePath(), where you must employ conditional code to accomodate cross-platform use.
Directories are searched in the order given, beginning with those specified in PFPATH, followed by those specified by pfFilePath() or pfFilePathv(). Calling pfFilePath() or pfFilePathv() a second time replaces the current path list rather than appending to it.
The function pfFindFile() searches the paths in PFPATH first, then those given in the most recent pfFilePath() call; it returns the complete path name for the file if the file is found. OpenGL Performer applications should use pfFindFile() (either directly or through routines such as pfdLoadFile()) to look for input data files.
The pfGetFilePath() function returns the last search path specified by a pfFilePath() or pfFilePathv() call. It does not return the path specified by the PFPATH environment variable. If you want to find out that value, call getenv().