Scalable graphics hardware provides nearly perfect scaling of both geometry rate and fill rate on some applications. This chapter describes how you use OpenGL Performer in conjunction with an SGI Video Digital Multiplexer (DPLEX), an SGI Scalable Graphics Compositor, and graphics processing units ( GPUs). The corresponding sections are the following:
A DPLEX is an optional daughtercard that permits multiple graphics hardware pipelines to work simultaneiously on a single visual application. DPLEX hardware is available on Silicon Graphics Onyx2, SGI Onyx 3000, and SGI Onyx 300 systems. For an overview of the DPLEX hardware, see the document Onyx2 DPLEX Option Hardware User's Guide.
OpenGL Performer taps the power of a DPLEX by using hyperpipes. The following sections describe how to use hyperpipes:
A pfH yperpipe is a combination of pfPipes or pfMultipipes; there is one pfPipe for each graphics pipe in a DPLEX ring or chain. A DPLEX ring or chain is a collection of interconnected graphic boards.
A key concept with hyperpipes is that of temporal decomposition. Think of a rendered sequence as a 3D data set with time being the third axis. With temporal decomposition, the dataset is subdivided along the time axis and distributed across, in this case, each of the graphic pipes in the hyperpipe group.
Temporal decomposition is different from spatial decomposition, in which the dataset is subdivided along the X axis, Y axis, or both X and Y axes.
It is the responsibility of the application to establish the hyperpipe group configuration for OpenGL Performer. There are two steps in the configuration process:
Establish the number of graphic pipes (or pfPipes because there is a one-to-one correspondence) in each hyperpipe group.
Map the pfPipes to specific graphic pipes.
Use the argument in the pfHyperpipe() function to establish the number of graphic pipes in the hyperpipe group, for example:
pfHyperpipe(2); pfConfig(); |
In this example, two pfPipes combine to create the pfHyperpipe, as shown in Figure 14-1.
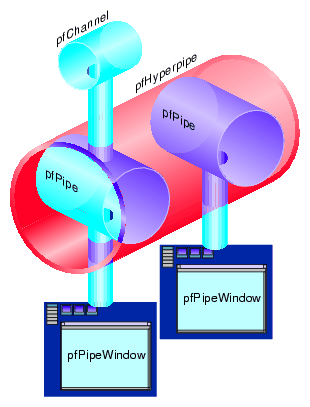
Like the pfMultipipe() function, pfHyperpipe() must be invoked prior to configuring the pfPipes using pfConfig() and after the call to pfInit().
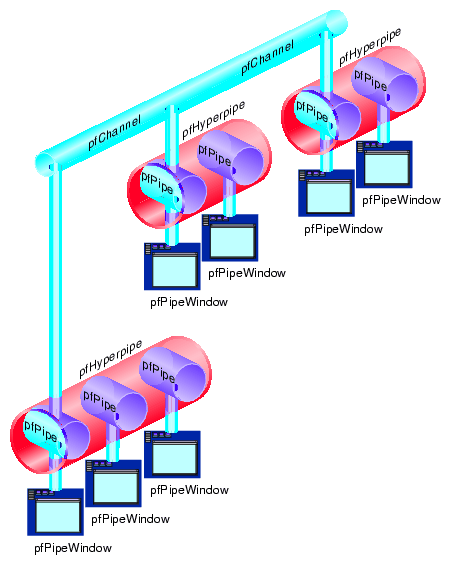
The number of pipes is used by pfConfig() to associate the configured pfPipes. The pfHyperpipe() function can be invoked multiple times to construct multiple hyperpipe groups, as shown in Figure 14-2.
Additionally, the pfHyperpipe() function can be combined with the pfMultipipe() call to configure pfPipes that are not associated with a hyperpipe group. The num argument to the pfMultipipe() function defines the total number of pfPipes to configure (including those in hyperpipe groups).
Example 14-1, diagrammed in Figure 14-2, shows the configuration of a system with three hyperpipe groups. The first hyperpipe group consists of three graphic pipes. The remaining two hyperpipe groups have two graphic pipes each. This example also configures one non-hyperpipe group graphic pipe.
Example 14-1. Configuring a System with Three Hyperpipe Groups
pfInit(); pfMultipipe(8); /* need eight pfPipes 3-2-2-1 */ pfHyperpipe(3); /* pfPipes 0, 1, 2 are the first group */ pfHyperpipe(2); /* pfPipes 3, 4 are the second group */ pfHyperpipe(2); /* pfPipes 5, 6 are the third group */ pfConfig(); /* construct the pfPipes */ |
If the target configuration includes only hyperpipe groups, it is not necessary to invoke pfMultipipe(). OpenGL Performer correctly determines the number of pfPipes from the pfHyperpipe() calls.
The pfPipes constructed by pfConfig() are ordered into a linear array and are selected with the pfGetPipe() function. The pfPipes that are part of a hyperpipe group always appear in this array before any non-hyperpipe group pfPipes.
The pfHyperpipe() function groups pfPipes together starting, by default, with pfPipe number 0. In the following example, there are four pfPipes; the first two are combined into a hyperpipe group:
pfMultipipe(4); pfHyperpipe(2); pfConfig(); |
OpenGL Performer maps each pfPipe to a graphic pipe, which is associated with a specific X display, as shown in Figure 14-3:
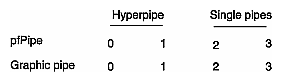
Each graphics pipe is associated with only one X screen. By default, OpenGL Performer assigns each pfPipe to the screen of the default X display that matches the pfPipe index in the pfPipe array; in other words, pfPipe(0) in the hyperpipe is mapped to X screen 0.
In most configurations, this default mapping is not sufficient. The second phase, therefore, involves associating the configured pfPipes with the graphic pipes. This is achieved through the pfPipeScreen() or pfPipeWSConnectionName() function on the pfPipes of the hyperpipe group.
Example 14-2 shows, given the configuration in Example 14-1, how to map the pfPipes to the appropriate screens. In this example, all of the graphic pipes are managed under the same X display, that is, a different screen on the same display.
Example 14-2. Mapping Hyperpipes to Graphic Pipes
/* assign the single pfPipe to screen 0 */
pfPipeScreen(pfGetPipe(7), 0);
/* assign the pfPipes of hyperpipe group 0 to screens 1,2,3 */
for (i=0; i < 3; i++)
pfPipeScreen(pfGetPipe(i), i+1);
/* assign the pfPipes of hyperpipe group 1 to screens 4,5 */
for (i=3; i<5; i++)
pfPipeScreen(pfGetPipe(i), i+1);
/* assign the pfPipes of hyperpipe group 2 to screens 6,7 */
for (i=5; i<7; i++)
pfPipeScreen(pfGetPipe(i), i+1);
|
The following is a more complex example that uses GLXHyperpipeNetworkSGIX returned from glXQueryHyperpipeNetworkSGIX() to configure the pfPipes. This example is much more complete and is referred to in the following sections.
Example 14-3. More Complete Example: Mapping Hyperpipes to Graphic Pipes
int hasHyperpipe;
GLXHyperpipeNetworkSGIX* hyperNet;
int numHyperNet;
int i;
Display* dsp;
int numNet;
int pipeIdx;
pfChannel* masterChan;
/* initialize Performer */
pfInit();
/* does this configuration support hyperpipe */
pfQueryFeature(PFQFTR_HYPERPIPE, &hasHyperpipe);
if (!hasHyperpipe) {
pfNotify(PFNFY_FATAL, PFNFY_RESOURCE, "no hyperpipe support");
exit(1);
}
/* query the network */
dsp = pfGetCurWSConnection();
hyperNet = glXQueryHyperpipeNetworkSGIX(dsp, &numHyperNet);
if (numHyperNet == 0) {
pfNotify(PFNFY_FATAL, PFNFY_RESOURCE, "no hyperpipes");
exit(1);
}
/*
* determine the number of distinct hyperpipe networks. network
* ids are monotonically increasing from zero. a value < 0
* is used to indicate pipes that are not members of any hyperpipe.
*/
for (i=0, numNet=-1; i<numHyperNet; i++)
if (numNet < hyperNet[i].networkId)
numNet = hyperNet[i].networkId;
numNet += 1;
/*
* configure all of the hyperpipes in the net
*
* NOTE -
* while it is possible to be selective about which hyperpipe(s)
* to configure, that is left as an exercise.
*/
for (i=0; i<numNet; i++) {
int count = 0;
int j;
for (j=0; j<numHyperNet; j++)
if (hyperNet[i].networkId == i) count++;
pfHyperpipe(count);
}
pfConfig();
/* associate pfPipes with screens */
for (i=0, pipeIdx=0; i<numNet; i++) {
int j;
for (j=0; j<numHyperNet; j++)
if (hyperNet[i].networkId == i)
pfPipeWSConnectionName(pfGetPipe(pipeIdx++),
hyperNet[i].pipeName);
}
/* construct the pfPipeWindows for each hyperpipe */
masterChan = NULL;
for (i=0, pipeIdx=0; i<numNet; i++) {
pfPipe* pipe;
pfPipeWindow* pwin;
pfChannel* chan;
PFVEC3 xyz, hpr;
pipe = pfGetPipe(pipeIdx);
pwin = pfNewPWin(pipe);
pfPWinName(pwin, "Hyperpipe Window");
/*
* void
* openPipeWindow(pfPipeWindow* pwin)
* {
* pfPWinOpen(pwin);
* }
*/
pfPWinConfigFunc(pwin, openPipeWindow);
pfPWinFullScreen(pwin);
pfPWinMode(pwin, PFWIN_NOBORDER, 1);
pfPWinConfig(pwin);
chan = pfNewChan(pipe);
pfPWinAddChan(pwin, chan);
/*
* layout channels left to right in hyperpipe order. this
* ordering is arbitrary and should be redefined for the
* specific application.
*/
pfChanShare(chan,
pfGetChanShare() | PFCHAN_VIEWPORT |
PFCHAN_SWAPBUFFERS | PFCHAN_SWAPBUFFERS_HW);
pfMakeSimpleChan(chan, 45);
pfChanAutoAspect(chan, PFFRUST_CALC_VERT);
xyz[0] = xyz[1] = xyz[2] = 0;
hpr[0] = (((numNet-1)*.5f)-i)*45.f;
hpr[1] = hpr[2] = 0;
pfChanViewOffsets(chan, xyz, hpr);
pfChanNearFar(.000001, 100000);
/*
* void
* drawFunc(pfChannel* chan, void* notUsed)
* {
* pfClearChan(chan);
* pfDraw();
* }
*/
pfChanTravFunc(PFTRAV_DRAW, drawFunc);
if (i == 0)
masterChan = chan;
else
pfAttachChan(masterChan, chan);
/* bump to the first pipe of the next hyperpipe */
pipeIdx += pfGetHyperpipe(pipe);
}
/*
* the next step is to construct the scene, attach it to
* masterChan and start the main loop. this bit of code
* is not included here since it follows other demonstration
* applications included elsewhere in the Programmer's Guide.
*/
|
The pfPipes grouped into a pfHyperpipe are indexed; the first pfPipe is pfPipe(0) and it is referred to as the master pfPipe. Most actions taken on the hyperpipe group are effected through this pfPipe; for example, all objects, such as pfPipeWindows and pfC hannels, are attached to the master pfPipe. OpenGL Performer automatically clones all objects, except pfChannels, across all of the pfPipes in the pfHyperpipe, as shown in Figure 14-4.
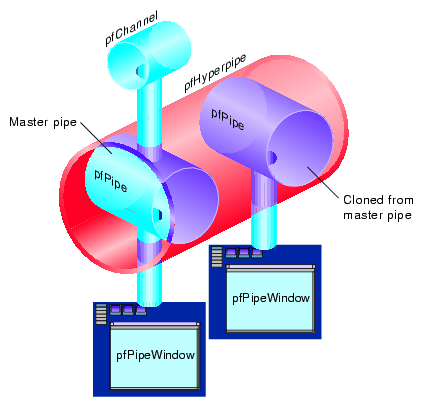
When constructing pfPipeWindows or pfChannels, the pfPipe argument should be the master pfPipe. OpenGL Performer ensures that the constructed objects are cloned (pfPipeWindows) or attached (pfChannels) as needed to the other pfPipes in the hyperpipe group.
With the exception of certain attributes, detailed in Table 14-1, OpenGL Performer propagates attribute updates to the cloned pfPipeWindows when they occur. The following is a list of pfPipeWindow functions for which the attributes do not propagate.
Table 14-1. pfPipeWindow Functions That Do Not Propagate
C Function | C++ Member Function |
|---|---|
setSwapBarrier() | |
setWSConnectionName() | |
setOverlayWin() | |
setStatsWin() | |
setScreen() | |
setWSWindow() | |
setWSDrawable() | |
setFBConfigData() | |
setFBConfigAttrs() | |
setFBConfig() | |
setFBConfigId() | |
setGLCxt() | |
setWinList() | |
setPVChan() | |
addPVChan() | |
removePVChan() | |
removePVChanIndex() | |
bindPVChans() | |
unbindPVChans() | |
select() | |
attachWin() | |
detachWin() | |
attach() | |
attachSwapGroup() | |
attachWinSwapGroup() | |
detachSwapGroup() | |
chooseFBConfig() |
When using any of the preceding interfaces within an application, set the appropriate attribute in the cloned pfPipeWindow.
Clones are identified by an index value. The index of a clone matches that of the master pfPipeWindow. This index is used to retrieve the clone pfPipeWindow from the other pfPipes in the hyperpipe group. Example 14-4 sets the FBConfigAttrs for each of the pfPipeWindows in the first hyperpipe group.
Example 14-4. Set FBConfigAttrs for Each pfPipeWindow
static int attr[] = {
GLX_RGBA,
GLX_DOUBLEBUFFER,
GLX_LEVEL, 0,
GLX_RED_SIZE, 8,
GLX_GREEN_SIZE, 8,
GLX_BLUE_SIZE, 8,
GLX_ALPHA_SIZE, 8,
GLX_DEPTH_SIZE, 16,
GLX_STENCIL_SIZE, 0,
GLX_ACCUM_RED_SIZE, 0,
GLX_SAMPLE_BUFFERS_SGIS, 1,
GLX_SAMPLES_SGIS, 4,
None
};
int numHyper = pfGetHyperpipe(pfGetPipe(0));
for (i=0; i<numHyper; i++) {
/* get the first pfPipeWindow on pfPipe */
pfPipeWindow* pwin = pfGetPipePWin(pfGetPipe(i), 0);
pfPipeFBConfigAttrs(pwin, attr);
}
|
The current API has no support for directly querying the pfPipeWindow index within the pfPipe. The only mechanism to determine an index value is to track it in the application or search the pfPipeWindow list of the pfPipe. Example 14-5 performs such a search.
Example 14-5. Search the pfPipeWindow List of the pfPipe
/* search the master pfPipe pipe for the pfPipeWindow in pwin */ int pwinIdx; int numPWins = pfGetPipeNumPWins(pipe); for (i=0; i<numPWins; i++) if (pfGetPipePWin(pipe) == pwin) break; if (i == numPWins) pfNotify(PFNFY_FATAL, PFNFY_PRINT, "oops!"); pwinIdx = i; |
When working with pfPipeWindows, it is possible for some updates to occur within the DRAW process. For this release (and possibly future releases) of OpenGL Performer, these updates are not automatically propagated to the clone pfPipeWindows. It is the responsibility of the application to ensure that the appropriate attributes are propagated or that similar actions occur on the clones.
The CULL and DRAW stages of different pfPipes within a hyperpipe group can run in parallel. For this reason, applications that assume a fixed pfChannel to pfPipe relationship or maintain global configuration data associated with a pfChannel that is updated in either the CULL or DRAW stages may fail. It is currently impossible (or at least very difficult) to transmit information from the CULL or DRAW stages of one pfPipe to another CULL or DRAW stage of another pfPipe within a hyperpipe group. All changes should be affected by the APP stage.
Programming with hyperpipes, as described in the preceding sections, generally involves the following steps:
Configure the hyperpipe either on the fly or using a configuration file.
Map screens to hyperpipes, if necessary.
Allocate pfPipeWindow and pfChannels:
Create one pfPipeWindow for each pfHyperpipe.
Attach a pfPipeWindow to the master pfPipe.
Create a pfChannel for each pfHyperpipe.
Start the main loop (pfFrame()...pfSync()).
There are two additional requirements for DPLEX:
You cannot use single buffer visuals.
The DPLEX option uses the glXSwapBuffers() call as an indication to switch the multiplexer. This logic is bypassed for single buffered visuals.
glXSwapBuffers() and pfSwapWinBuffers() functions must not be invoked outside of the internal draw synchronization logic.
Because the pfuDownloadTexList() function with the style parameter set to PFUTEX_SHOW calls glXSwapBuffers(), this feature must be disabled. (Simply set the style parameter to PFUTEX_APPLY).
Also, the Perfly application displays a message at startup which also swaps the buffers. Again, this function must be disabled when using hyperpipe groups. The version of Perfly that ships with performer_demo correctly disables these features.
Each pfPipe software rendering pipeline runs at a fraction of the target frame rate as defined by pfFrameRate(). The fraction is 1/(number of pipes in hyperpipe group). For example, if there are two pfPipes in the pfHyperpipe, each pfPipe runs at one half of the pfFrameRate(). Although the CULL and DRAW stages run at a slower rate, the APP stage must run at the target frame rate.
This section gives a brief overview of the SGI Scalable Graphics Compositor and how to use it with OpenGL Performer. For more information on the compositor, including the details of the hardware setup, see the document SGI InfinitePerformance: Scalable Graphics Compositor User's Guide.
| Note: The compositor is currently supported on InfinitePerformance, Onyx4, and Prism graphics systems. |
This section contains the following subsections:
The compositor receives two to four input signals and outputs a single signal either in analog or digital format. Hence, it can handle spatial composition of four inputs which enables multiple pipes to contribute to a single output. Four different composition schemes are available:
Figure 14-5 illustrates the various hardware composition schemes.
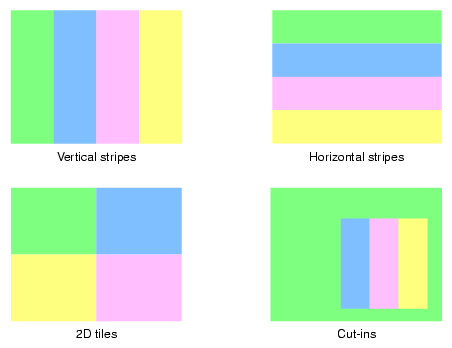
The following items are noteworthy regarding the compositor's capabilities:
In addition to the spatial composition modes shown in Figure 14-5, the compositor provides applications with the means to do full-scene antialiasing (FSAA) in hardware. This capability stems from the following feature: for every output pixel, the compositor averages all values from all the pipes.
Stereo support is not provided explicitly through the compositor, but OpenGL Performer does allow you to structure your application to do so.

Note: For more information on the current limitations and anomalies associated with the use of the SGI Scalable Graphics Compositor, refer to the hardware documentation.
A compositor is a hardware device that takes a number of video inputs and combines them to produce a single video output. The video inputs can be divided spatially or blended together to form one output. OpenGL Performer uses the pfCompositor class to support compositors. The pfCompositor class transparently distributes rendering across multiple hardware pipes and combines their outputs by either feeding them to a hardware compositor device or through software composition.
Several different spatial composition modes are supported, as well as an antialias mode in which channel frustums on composited pipes are slightly jittered and the outputs blended together by the hardware compositor.
The pfCompositor class also supports dynamic load balancing. When enabled, the spatial subdivision of the compositor inputs will be updated on each frame based on the load of each contributing pfPipe. Load balancing is disabled by default but can be enabled through setMode().
During initialization, the pfCompositor class will perform a system topology query to determine the availability of hardware compositors. The results of this query can be examined by the application through the static methods listed in Table 14-2.
Table 14-2. Methods for Querying the System for Hardware Compositors
Methods | Description |
|---|---|
Returns the number of available hardware compositors found on the system. | |
Returns the network ID of the cth hardware compositor, or –1 if c is not a valid index. | |
Returns the number of inputs physically connected to the cth hardware compositor. Each input can either be a single pipe or the output of another hardware compositor. If c is not a valid index, –1 is returned. | |
Returns PFCOMP_INPUTTYPE_PIPE if the ith input of the cth hardware compositor is a single pipe, or PFCOMP_INPUTTYPE_COMPOSITOR if it is another hardware compositor. If c is not a valid index, 0 is returned. | |
Returns the string identifying the display of that pipe (for example, ":0.0") if the ith input of the cth hardware compositor is a single pipe. If c or i is not a valid index or if the ith input of the cth compositor is not a single pipe, NULL is returned. | |
Returns its network id if the ith input of the cth hardware compositor is a compositor. If c or i is not a valid index or if the ith input of the cth compositor is not a compositor, –1 is returned. | |
Returns a pointer to the pfCompositor object managing the cth hardware compositor if one exists and c is a valid index. Otherwise, NULL is returned. |
A pfCompositor is created through new pfCompositor(netId), where netId is the network ID for the hardware compositor device that will be managed by the new pfCompositor. If netId is PFCOMP_SOFTWARE, no hardware compositor device will be involved, and composition will be carried out through software readbacks.
This chapter refers to pfCompositors utilizing software composition as software compositors while pfCompositors associated with a hardware compositor device will be referred to as hardware compositors.
You can use the methods described in Table 14-3 to configure pfCompositors that have been created.
Table 14-3. Methods Used in Creating pfCompositors
Methods | Description |
|---|---|
Returns the network id identifying the hardware compositor device managed by a pfCompositor object or PFCOMP_SOFTWARE if the pfCompositor uses software composition. | |
Adds a pipe child (input) to a pfCompositor. If the pfCompositor is a hardware compositor, pipe_name must match the display string of one of the hardware pipes physically connected to the compositor device. If the compositor is a software compositor, then pipe_name can be any valid display string. The pfPipes configured by the software compositor will be created on the specified displays through calls to pfPipe::setWSConnectionName(). The pipe_name value can also be "" (empty string) for software compositors; in this case, pipes will be created on the default screens (:0.0, :0.1, and so on). | |
Adds a compositor child to a pfCompositor, creating a compositor hierarchy. Currently only hardware compositor parents and software compositor children are supported. Care must be taken in configuring compositor hierarchies to ensure that the first child of the software compositor child (its master pipe) is physically connected to the compositor device managed by the parent pfCompositor. | |
Configures a pfCompositor with the desired number of inputs. For hardware compositors, num_inputs cannot exceed the number of inputs physically connected to the hardware device. A zero or negative value for num_inputs will cause all physically connected inputs to be configured. For software compositors, num_inputs will be clamped to the number of available hardware pipes. If num_inputs is less than one, all available hardware pipes on the system will be configured. Note that autoSetup() will take no action at all if pfCompositor already has one or more children. The call autoSetup(–1) is made within a pfConfig for all pfCompositor objects in order to automatically configure them if the application has not done so already. |
The methods described in Table 14-4 can be used to query compositors.
Table 14-4. Methods for Querying pfCompositors
Method | Description |
|---|---|
Returns the number of children (inputs) that have been added to a pfCompositor. Each child can either be a single pipe or a pfCompositor. | |
Returns PFCOMP_INPUTTYPE_PIPE if the ith child is a single pipe or PFCOMP_INPUTTYPE_COMPOSITOR if it is a pfCompositor. If i is not a valid index, 0 is returned. | |
Returns a pointer to the ith child of a pfCompositor if the child is a pfCompositor. If i is not a valid index, or if the ith child is not a compositor, NULL is returned. | |
Returns a pointer to the ith child of a pfCompositor if the child is a single pipe. This can only be called after pfConfig(). | |
Returns the display string for the ith child of a pfCompositor if the child is a single pipe. Note that for software compositors, getChildPipeName() returns an empty string ("") for all children unless a display string was explicitly assigned by the application through a call to addChild( pipe_name ). | |
Returns the OpenGL Performer ID of the pipe child and should only be called after pfConfig(). | |
Returns a pointer to a pfCompositor parent (another pfCompositor) if the first has been added to the latter as a child through a call to addChild( comp ). If a pfCompositor has no parent, NULL is returned. | |
Sets the number of active children. Not all configured children must contribute to the composited image at all times. There must be at least one active child and no more than the total number of configured children. Note that children are activated from first to last; this means that when there are n active children, these will be children 0 to (n-1); thus, child 0 is always active. | |
Returns the number of currently active children. | |
Returns a pointer to the master pfPipe for a pfCompositor. The master pipe is the pipe that the application should use to create a pipe window and one or more channels. The pfPipeWindows and pfChannels are created automatically on all other composited pipes (slave pipes) by the pfCompositor class. In a single-tier compositor (one with no compositor parent and no compositor children), the master pipe will be its first child. In a compositor hierarchy, all pfCompositors will share a single master pipe. | |
Returns the OpenGL Performer pipe ID of pfCompositor's master pipe. Each pfCompositor object maintains a list of all the pfPipes contributing to its output. This includes all single-pipe children, as well as all single pipes connected to compositor children. | |
Returns the total number of pfPipes contributing to a pfCompositor. For a single-tier compositor, this value is equal to the number of its children. In a compositor hierarchy, pipes contributing to leaf compositors (bottom of the hierarchy) also contribute to the root compositor; therefore, if called on the root compositor of a compositor hierarchy, getnumPipes() returns the total number of pipes in hierarchy. | |
Returns a pointer to the pth pfPipe in a pfCompositor's pipe list. If p is an invalid index, NULL is returned. | |
Returns a pointer to the pfPipeWindow on the pth pipe in a pfCompositor's pipe list. Currently only one (full-screen) pipe window is supported on composited pipes. If p is an invalid index, NULL is returned. | |
Returns a pointer to the cth pfChannel on the pth pipe in a pfCompositor's pipe list. If p or c are invalid indexes, NULL is returned. | |
Returns a pointer to the pfCompositor at the root of the compositor hierarchy to which compositor belongs. For a parent-less pfCompositor, getRoot() returns a pointer to the compositor itself. For a compositor child, getRoot() returns parent->getRoot. |
In addition to the methods shown in Table 14-4, the static methods shown in Table 14-5 are also available.
Table 14-5. Static Methods for Querying pfCompositors
Method | Description |
|---|---|
Returns the number of pfCompositor objects in this list. | |
Returns a pointer to the ith pfCompositor object from the global list of pfCompositors. The pfCompositors are added to this list in the order of creation. | |
Returns the total number of pfPipes that are (or will be) managed by pfCompositor objects. This is known for certain only after a pfConfig() call because, until then, pipes may be added to existing compositors. However, if called before pfConfig(), this method will attempt to make a reasonable guess by assuming that pfCompositors with no explicitly assigned children will end up being (automatically) configured with all the inputs that are physically connected to them. This can be useful when an application creates one or more single pipes in addition to pipes managed by pfCompositors. In such cases, the application is required to make a call to pfMultipipe() to provide the total number of pipes to be created. Method getNumCompositedPipes() returns the total number of composited pipes to which the desired number of single pipes may be added. |
A pfCompositor requires a pfLoadBalance object for carrying out load balancing computations. The pfLoadBalance class determines the resulting workload for each of the compositor's children. The behavior can be customized by subclassing pfLoadBalance and overriding the appropriate methods. A pfCompositor can use a customized pfLoadBalance object specified through the setLoadBalancer() method. If a load balancer is not specified, one will be automatically created and used. The method getLoadBalancer() returns a pointer to the pfLoadBalancer object used by the compositor.
The two methods in Table 14-6 can be used to control the transition between load balancing states.
Table 14-6. Methods to Control the Load Balancing Transitions
Method | Description |
|---|---|
Accepts only PFLOAD_COEFF and passes the value to the pfLoadBalance class. This coefficient determines how quickly the balancer transitions from the current state to the desired balanced state. This load balancing filter coefficient should be in the range [0..1]. The smaller its value, the slower load balancing follows pipe loading, and the less noise-sensitive it is. | |
Accepts only PFLOAD_COEFF and returns the current value of the filter coefficient used by the pfLoadBalance object associated with the pfCompositor. |
For more information, see the pfLoadBalance man page.
The method setMode() accepts the following tokens as its first argument:
| PFLOAD_BALANCE | Enables or disables dynamic load balancing. The second argument must be PF_ON or PF_OFF. | |
| PFCOMP_CLIPPING | Enables or disables channel clipping for all channels on all pipes managed by this compositor. By default, channel clipping is enabled, and the viewports of pfChannels in composited pipes are clipped to the screen region assigned to each pipe by the compositor. If channel clipping is disabled, all pipes will render all channels in their full (original) size.Note that clipping is not carried out when in antialias mode. | |
| PFCOMP_SWAPBARRIER | Specifies the swap barrier to which pipes contributing to pfCompositor should bind. The second argument should be a valid swap barrier ID (see the glXQueryMaxSwapBarriersSGIX man page). By default, all pfCompositors will bind to swap barrier 1 if the swap barrier extension is supported. Binding to a swap barrier can be disabled by passing a value smaller than 1. If the specified barrier_id is out of range, the call to setMode() has no effect. | |
| PFCOMP_COMPOSITION_MODE | Specifies the composition mode used by the pfCompositor. The second argument can be one of the following:PFCOMP_COMPMODE_HORIZ_STRIPES |
All composition modes are valid for any number of active children.
Figure 14-6 illustrates how one to four inputs are laid out for PFCOMP_COMPMODE_HORIZ_STRIPES mode.
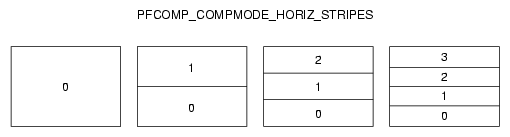
Figure 14-7 illustrates how one to four inputs are laid out for PFCOMP_COMPMODE_VERT_STRIPES mode.
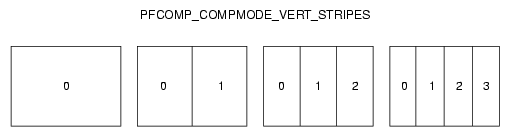
Figure 14-8 illustrates how one to four inputs are laid out for PFCOMP_COMPMODE_LEFT_TILES mode.
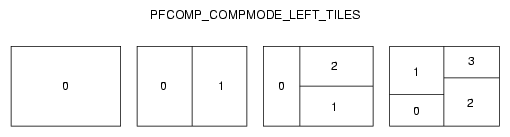
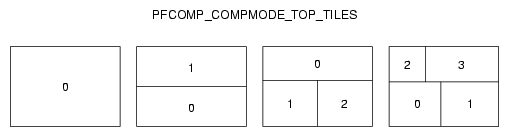
Figure 14-9 illustrates how one to four inputs are laid out for PFCOMP_COMPMODE_RIGHT_TILES mode.
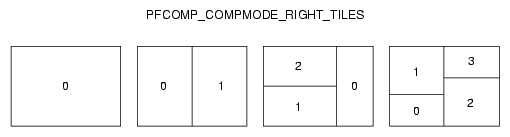
Figure 14-10 illustrates how one to four inputs are laid out for PFCOMP_COMPMODE_BOTT_TILES mode.
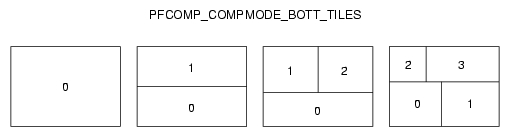
Figure 14-11 illustrates how one to four inputs are laid out for PFCOMP_COMPMODE_TOP_TILES mode.
The method getMode() can be called to query the compositor mode. You can use the following tokens:
| PFLOAD_BALANCE | The returned value is 1 if dynamic load balancing is enabled or 0 if it is disabled. | |
| PFCOMP_CLIPPING | The returned value is 1 if channel clipping is enabled or 0 if it is disabled. | |
| PFCOMP_SOFTWARE | The returned value is 1 if pfCompositor uses software composition or 0 if pfCompositor controls a hardware compositor device. | |
| PFCOMP_SWAPBARRIER | The returned value is the index of the swap barrier to which pipes will bind (or have bound). If binding to swap barriers has been (or will be) skipped, return value is 0. | |
| PFCOMP_COMPOSITION_MODE | The returned value is the current composition mode used by the pfCompositor and can be one of the following: |
You can use the methods described in Table 14-7 to manage screen space, channel clipping, and antialiasing.
Table 14-7. Methods for Managing Screen Space, Channel Clipping, and Antialiasing
Method | Description |
|---|---|
Specifies the screen-space bounds of the region managed by a pfCompositor. The viewports assigned to all pipes managed by this compositor will be clipped to this region. The default viewport for a pfCompositor is 0.0, 1.0, 0.0, 1.0 (the whole screen). Do not call setViewport() for compositor children in compositor hierarchies; use setChildViewport() on the parent compositor instead. | |
Returns the screen-space bounds of the region managed by a pfCompositor. | |
Specifies the screen-space bounds of the 2D region assigned to the ith child of the pfCompositor. The specified viewport is automatically clipped to the viewport of the compositor and aligned horizontally to a four-pixel boundary (required by hardware compositor devices). The default viewports of a pfCompositor's children are determined based on the number of active children and on the current composition mode; see the preceding description for setMode(). Note that when dynamic load balancing is active, setting children viewports through setChildViewport() will have no affect. | |
Returns the screen-space bounds of the 2D region managed by the ith child of the pfCompositor. This region will always be contained by the viewport of the pfCompositor itself. | |
Specifies whether channel clipping should be enabled for the ith channel. Channel clipping is enabled on all channels by default. Channel clipping is not performed if it is globally disabled through a call to setMode(). Disabling clipping on a pfChannel can be useful in certain situations; for example, the GUI channel for Perfly has clipping disabled and is rendered entirely on the master pipe. | |
Returns 1 if channel clipping is enabled for the ith channel if i is a valid index or 0, otherwise. | |
Specifies the jitter pattern to be used for antialias composition when there are n active children. The parameter jitter must point to an array of floats containing 2*n values, specifying subpixel offsets (horizontal and vertical) for each of the n contributing inputs. A pfCompositor maintains a list of jitter patterns to be used for antialias mode, depending on the number of active children. A jitter pattern is encoded as an array of subpixel offsets with two floats (horizontal and vertical offset) for each contributing child. | |
Returns the jitter pattern to be used for antialias composition when there are n active children. The parameter jitter must point to an array of floats (with at least 2*n elements), which contains the queried jitter values. |
| Note: All viewports are specified in normalized screen coordinates with 0.0,0.0 as the bottom-left corner of the screen and 1.0,1.0 as the top-right corner. |
GPUs are used widely in commodity graphics hardware and also in graphics platforms like Onyx4 or Prism systems. OpenGL Performer supports GPU programming through the use vertex programs and fragment programs.
Vertex programs are used by the GPU to modify various parameters of each vertex. Similarly, fragment programs are used to modify the color and depth value of each fragment (pixel) as it is being rendered. A description of vertex and fragment program instruction sets is beyond the scope of this guide. You can find a description of these instruction sets in the OpenGL extension registry at http://oss.sgi.com/projects/ogl-sample/registry/ under GL_ARB_vertex_program and GL_ARB_fragment_program.
This chapter describes how you can use GPU programs in OpenGL Performer in the following sections:
OpenGL Performer implements GPU programming through the general class pfGProgram. This class allows you to set GPU programs, vertex programs and fragment programs.
The function pfNewGProgram() creates and returns a handle to a pfGProgram. The parameter arena specifies a malloc() arena out of which the pfGProgram is allocated or the value NULL specifies allocation off the process heap. pfGPrograms can be deleted with pfDelete().
The call new(arena) allocates a pfGProgram from the specified memory arena or from the heap if arena is NULL. The new() call allocates a pfGProgram from the default memory arena (see function pfGetSharedArena() in the pfSharedMem(3pf) man page). Like other pfObjects, pfGPrograms cannot be automatically created statically on the stack or in arrays. pfGPrograms should be deleted with pfDelete() rather than the delete operator.
The function pfGetGProgramClassType() returns the pfType* for the class pfGProgram. The pfType* returned by pfGetGProgramClassType() is the same as the pfType* returned by invoking pfGetType(), the virtual function getType() on any instance of class pfGProgram. Because OpenGL Performer allows subclassing of built-in types, when decisions are made based on the type of an object, it is usually better to use pfIsOfType(), the member function isOfType(), to test if an object is of a type derived from an OpenGL Performer type rather than to test for strict equality of the types.
A pfGProgram is a sequence of assembly-like instructions. You can specify the instructions in two ways:
In a string with new line characters separating instructions
In a text file
If the program is specified in a string, you use the function pfGProgramProgram() or pfGProgramProgramLen(). The first parameter of each is the string defining the program. In the second function, you can specify the length when you want to load only part of the string.
If the program is loaded from a text file, you use the function pfGProgramLoadProgram().
Using the function pfGProgramApplypfGProgram(), you can apply the pfGProgram but only in the draw process. Once the pfGProgram has been applied, you can query its state using the following functions:
| pfGetGProgramProgramLength() | Returns the number of instructions of the program. | |
| pfGetGProgramNativeProgramLength() | Returns the number of instructions used by the specific GPU. | |
| pfGProgramIsValidpfGProgram() | Returns 1 if the program has been successfully loaded into the GPU. |
You should not use a pfGProgram directly but one of its subclasses. There are two classes of specific GPU programs subclassed from pfGProgram: pfVertexProgram and pfFragmentProgram. A pfVertexProgram or a pfFragmentProgram is set in a pfGeoState and is enabled in a pfGeoState. The user parameters for the vertex and fragment programs can be defined using the class pfGProgramParams, which is described in the following section.
For sample code, see the following file:
/usr/share/Performer/src/pguide/libpf/C++/gprogram.C
(IRIX and Linux)
%PFROOT\Src\pguide\libpf\C++\gprogram.cxx
(Microsoft Windows)
The pfGProgramParms is a class that is used to store parameters of GPU programs, specifically of pfVertexPrograms and pfFragmentPrograms. The function pfNewGProgramParms() creates and returns a handle to a pfGProgramParms. The parameter arena specifies a malloc() arena out of which the pfGProgram is allocated or NULL for allocation off the process heap. You can delete pfGPrograms with pfDelete().
A pfGProgramParms is a set of indexed quadruples of floating point values that are used as parameters for vertex and fragment programs. You can specify the values using the function pfGPParamsParameters() which has the following syntax:
pfGPParamsParameters(pfGProgramParms* gpparams, int index, int type, int count, void* ptr); |
The parameter index specifies the first index of the specified parameters (the index by which the parameters are accessed in the GPU program) and the the parameter count specifies how many indices will be set.
The parameter type may be one of the following:
| PFGP_FRAGMENT_LOCAL | Local parameters of a single fragment program. | |
| PFGP_FRAGMENT_ENV | Environment parameters. Shared between all fragment programs. | |
| PFGP_VERTEX_LOCAL | Environment parameters of a single vertex program. | |
| PFGP_VERTEX_ENV | Environment parameters. Shared between all vertex programs. |
The pointer ptr points to the parameter data.
Using the following functions, you can query the existing parameters in a pfGProgramParms:
| pfGetGPParamsNumParameters() | Returns the number of parameters. | |
| pfGetGPParamsParameters() | Returns the parameters in the order of their specification. | |
| pfGetGPParamsParametersByIndex() | Returns the parameters by the index by which the parameters are accessed. |
You can apply the pfGProgramParms using pfGProgramParamsApply() but only in the draw process. If you modify the pfGProgramParms after they have been applied, you must call pfGProgramParamsUpdate() for the change to take effect.
A pfGProgramParms is set in a pfGeoState. Each pfGeoState can have one pfGProgramParms of each of the four types, two for the pfVertexProgram associated with the pfGeoState and two for the pfFragmentProgram.
The pfVertexProgram and pfFragmentProgram classes are derived from the class pfGProgram. These subclasses do not add any new methods. A vertex program or a fragment program is used by the GPU to modify various parameters of each vertex or fragment (pixel), respectively. The GPU allows you to specify a sequence of floating-point 4-component operations that are executed for each vertex or fragment. These operations transform an input set of per-vertex or per-fragment parameters to another set of per-vertex or per-fragment parameters.
A vertex program replaces the standard OpenGL set of lighting and texture coordinate generation modes. Consequently, the vertex program must take care of the basic transformation of vertex coordinates to the screen coordinates, the generation of texture coordinates, and the application of the lighting equation. This programming model allows you to modify the position of each vertex, producing, for example, a displacement mapping.
Similar to a vertex program, a fragment program replaces the standard OpenGL set of texture and fog application modes. The fragment program has to access the textures and to modulate the resulting color according to the fog equation, if necessary. This programming model allows you to modify the resulting color and depth of each pixel, making it possible, for example, to apply a complex per-pixel shading.
You can find the instruction sets for vertex and fragment programs in the OpenGL extension registry at http://oss.sgi.com/projects/ogl-sample/registry/ under the GL_ARB_vertex_program.
As subclasses of pfGProgram, pfVertexPrograms and pfFragmentPrograms can use the management methods of a pfGProgram to set, load, and apply programs. Section “The pfGProgram Class” describe these methods.
You set and enable pfVertexPrograms and pfFragmentPrograms in a pfGeoState. As described in section “The pfGProgramParms Class”, the user parameters for GPU programs can be defined using the pfGProgramParms class.
For sample code, see the following file:
/usr/share/Performer/src/pguide/libpf/C++/gprogram.C
(IRIX and Linux)
%PFROOT\Src\pguide\libpf\C++\gprogram.cxx
(Microsoft Windows)