Before writing a digital media application, it's essential to understand the basic attributes of digital image, video, and audio data. This chapter provides a foundation for understanding digital media data characteristics, and how to realize those qualities when creating your application. It begins by reviewing how data is represented digitally and then explains how to express data attributes in the Digital Media Libraries.
Data input from analog devices must be digitized in order to store to, retrieve from, and manipulate within a computer. Two of the most important concepts in digitizing are sampling and quantization.
Sampling involves partitioning a continuous flow of information, with respect to time or space (or both), into discrete pieces. Quantization involves representing the contents of such a sample as an integer value. Both operations are performed to obtain a digital representation.
The topic of exactly how many integers to use for quantizing and how many samples to take (and when or where to take them) in representing a given continuum is important because these choices affect the accuracy of the digital representation. Mathematical formulas exist for determining the correct amount of sampling and quantization needed to accurately re-create a continuous flow of data from its constituent pieces. A treatise on sampling theory is beyond the scope of this book, but you should be familiar with concepts such as the Nyquist theorem, pulse code modulation (PCM), and so on. For more information about digitization and related topics, see:
Poynton, Charles A. A Technical Introduction to Digital Video. New York: John Wiley & Sons, 1995 (ISBN 0-471-12253-X).
Watkinson, John. An Introduction to Digital Video. New York: Focal Press, 1994.
Quantities such as the sampling rate and number of quantization bits are called attributes; they describe a defining characteristic of the data that has a certain physical meaning. An important point about data attributes is that while they thoroughly describe data characteristics, they do not impose or imply a particular file format. In fact, one file format might encompass several types of data with several changeable attributes.
File format, also called container format, applies to data stored on disk or removable media. Data stored in a particular file format usually has a file header that contains information identifying the file format and auxiliary information about the data that follows it. Applications must be able to parse the header in order to recognize the file at a minimum, and to optionally open, read, or write the file. Similarly, data exported using a particular file format usually has a header prepended to it when output.
In contrast, data format, which is described by a collection of attributes, is meaningful for data I/O and exchange, and for data resident in memory. Because the Digital Media Libraries provide extensive data type and attribute specification facilities, they offer a lot of flexibility for recognizing, processing, storing, and retrieving a variety of data formats.
Parameters in the DM Library include files (dmedia/dm_*.h) provide a common language for specifying data attributes for the Digital Media Libraries. Not all of the libraries require or use all of the DM parameters.
Most of the Digital Media Libraries provide their own library-specific parameters for describing data attributes that are often meaningful only for the routines contained within each particular library. These library-specific parameters are prefaced with the initials of their parent library, rather than the initials DM. For example, the Video Library defines its own image parameters in vl.h, which are prefaced with the initials VL.
Many of the parameters defined in the DM Library have clones in the other libraries (except for the prefix initials). This makes it easy to write applications that use only one library. Some libraries provide convenience routines for converting a list of DM parameters to a list of library-specific parameters.
It's essential to understand the physical meaning of the attributes defined by each parameter. Knowing the meanings of the attributes helps you get the intended results from your application and helps you recognize and be able to use DM parameters and their clones throughout the family of Digital Media Libraries.
The sections that follow describe the essential attributes of digital image and audio data, their physical meanings, and the DM parameters that define them.
This section presents essential image concepts about color and video.
Important color concepts discussed in this section are:
Two dimensional digital images are composed of a number of individual picture elements (pixels) obtained by sampling an image in 2D space. Each pixel contains the intensity and, for color images, the color information for the region of space it occupies.
Color data is usually stored on a per component basis, with a number of bits representing each component. A color expressed in RGB values is said to exist in the RGB colorspace. To be more precise, a pixel is actually a vector in colorspace. There are other ways to encode color data, so RGB is just one type of colorspace.
There are four colorspaces to know about for the Digital Media Libraries:
full-range RGB with the following properties:
component R, G, B
each channel ranges from [0.0 - 1.0]; mapped onto [0..2^n-1]
alpha is [0.0 - 1.0]; mapped onto [0..2^n-1]
compressed-range RGB with the following properties:
component R, G, B
each channel ranges from [0.0 - 1.0]; mapped onto [64..940] (10-bit mode) and [16..235] (8-bit mode)
alpha ranges from[0.0 - 1.0]; mapped onto [64..940] (10-bit mode) and [16..235] (8-bit mode)
full-range YUV with the following properties:
component Y, Cr, Cb
Y (luma) channel ranges from [0.0 - 1.0] mapped onto [0..2^n-1]
Cb and Cr (chroma) channels range from [-0.5 - +0.5] mapped onto [0..2^n-1]
alpha ranges from [0.0 - 1.0] mapped onto [0..2^n-1]
colorspace is as defined in Rec 601 specification
compressed-range YUV with the following properties:
component Y, Cr, Cb
Y (luma) channel ranges [0.0 - 1.0] mapped onto [64..940] (10-bit mode) and [16..235] (8-bit mode)
Cb and Cr (chroma) channels range [-0.5 - +0.5] mapped onto [64..960] (10 bit mode) and [16..240] (8-bit mode)
alpha is [0.0 - 1.0] mapped onto [64..940] (1- bit mode) and [16..235] (8-bit mode)
colorspace is as defined in Rec. 601 specification
On the display screen, each pixel is actually a group of three phosphors (red, green, and blue) located in close enough proximity that they are perceived as a single color. There are some issues with anomalies related to the physical properties of screens and phosphors that are of interest for programmers. See “Freezing Video” in Chapter 4 for more information about these issues.
Humans perceive brightness in such a way that certain colors appear to be brighter or more intense than others. For example, red appears to be brighter than blue, and green appears to be brighter than either blue or red. Secondary colors (cyan, magenta, and yellow), each formed by combining two primary colors, appear to be even brighter still. This phenomenon is simulated in Figure 2-1.
Figure 2-1 is a plot that simulates the human eye's response to the light intensity of different wavelengths (colors) of light. Pure colors (red, green, blue, yellow, cyan, and magenta) are plotted in YCrCb colorspace with brightness plotted along the horizontal axis. The rightmost colors are perceived as brighter than the leftmost colors, even though all the colors are of equal brightness.

The brightness of a color is measured by a quantity called saturation. Figure 2-2 connects the maximum saturation points of each color. The lines tracing the path of maximum saturation from the values at each corner are called hue lines.
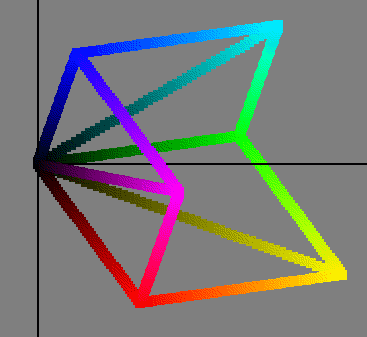
The program that generated Figure 2-1 and Figure 2-2, colorvu, uses the Colorspace API described in “The Color Space Library” in Appendix A.
Both the human visual perception of light intensity and the physical equipment used to convey the sensation of brightness in a computer display are inherently nonlinear, but in different ways. As it happens, the differences actually complement each other, so that the nonlinearity inherent in the way a computer display translates voltage to brightness almost exactly compensates for the way the human eye perceives brightness, but some correction is still necessary, as explained in the next section, “Gamma.”
Cameras, computer displays, and video equipment must account for both the human visual response and the physical realities of equipment in order to create a believable image. Typically a gamma factor is applied to color values to correctly represent the visual perception of color, but the way in which the gamma correction is applied, the reason for doing so, and the actual gamma value used depend on the situation.
It is helpful to understand when in the image processing path gamma is applied. Computers apply a gamma correction to output data to correctly reproduce intensity when displaying visual data. Cameras compensate for the nonlinearity of human vision by applying a gamma correction to the source image data as it is captured.
The key points to know when working with image data are whether the data has been (or should be) gamma-corrected, and what is the value of the gamma factor. Silicon Graphics monitors apply a default gamma correction of 1.7 when displaying RGB images.
You can customize the gamma function by specifying gamma coefficients for image converters as described in “The Digital Media Color Space Library” in Chapter 6.
Video uses a nonlinear quantity, referred to as luma, to convey brightness. Luma is computed as a weighted sum of gamma-corrected RGB components. Color science theory represents the sensation of brightness as a linear quantity called luminance, which is computed by adding the red, green, and blue components, each weighted by a linear gamma factor that mimics human visual response.
In video and software documentation, the terms luma and luminance are often used interchangeably, and the letter Y can represent either quantity. Some authors (Poynton and others) use a prime symbol to denote a nonlinear quantity, and so represent luma as Y', and luminance as Y. This type of notation emphasizes the difference between a nonlinear and linear quantity, but it is not common practice, so it is important to realize that there are differences. Unless otherwise noted, in this document and in the Digital Media Libraries, Y refers to the nonlinear luma.
To supply the color information for video signal encoding, the luma value (Y) is subtracted from the red and blue color components, giving two color difference signals: B–Y (B minus Y) and R–Y (R minus Y), which together are called chroma. As in the case of luma and luminance, the term chrominance is sometimes mistakenly used to refer to chroma, but the two terms signify different quantities. In the strictest sense, chrominance refers to a representation of a color value expressed independently of luminance, usually in terms of chromaticity.
Color science uses chromaticity values to express absolute color in the absence of brightness. Chromaticity is a mathematical abstraction that is not represented in the physical world, but is useful for computation. Chrominance is often expressed in terms of chromaticity. A CIE chromaticity diagram is an (x, y) plot of colors in the wavelengths of visible light (400 nm to 700 nm). Color matching and similar applications require an understanding of chromaticity, but you probably don't need to use it for most applications written using the Digital Media Libraries.
Important video concepts to be familiar with are the distinction between digital and analog video, video formats, black level, fields, and interlacing. This section contains these topics, which highlight key video concepts:
Because the human perception of brightness varies depending on color, some image encoding formats can take advantage of that difference by separating image data into separate components for brightness and color. One such method is the component digital video standard established by ITU-R BT.601 (also formerly known as CCIR Recommendation 601, or often simply Rec. 601).
For the digital video formats, Rec. 601 defines some basic properties common to digital component video, such as pixel sampling rate and colorspace, regardless of how it is transmitted. Then, the more specific documents (SMPTE 125M, SMPT259M, and ITU-R BT.656) define how the data format defined by Rec. 601 is to be transmitted over various kinds of links (serial, parallel) with various numbers of lines (525 or 625).
Component digital video uses scaled chroma values, called Cr and Cb, which are combined with luma into a signal format called YCrCb. This YCrCb refers to a signal format that is transmitted over a wire. It is related to, but separate from, the YCrCb colorspace used to store samples in computer memory.
Recommendation 601 defines methods for subsampling chroma values. The most common subsampling method is 4:2:2, where there is one pair of Cr, Cb samples for every other Y sample. In 4:4:4 subsampling, there is a luma sample for every chroma sample.
There are also composite analog video encoding signals, YUV and YIQ, which are based on color-difference signals. In analog composite video, the two color-difference signals (U,V or I,Q) are combined into a chroma signal, which is then combined with the luma for transmission. NTSC and PAL are the two main standards for encoding and transmitting analog composite video. See SMPTE 170M for more information about analog video broadcast standards.
The important point to realize about YUV is that, like YCrCb, it is calculated by scaling color difference values, but different scale factors are used to obtain YUV than are used for YCrCb. The YUV and YCrCb colorspaces are similar to each other; they differ primarily in the ranges of acceptable values for the three components when represented as digital integers. The values of Y, U and V are in the range 0..255 (the SMPTE YUV ranges), while the range for Rec. 601 YCrCb is 16..235/240.
It is important to keep these differences in mind when selecting the colorspace for storing data in memory. While the terms YUV and YCrCb are used interchangeably and describe both video signals and a colorspace for encoding data in computer memory, they are separate concepts. Knowing and being able to specify precisely the colorspace of input data and the memory format you want are the keys to obtaining satisfactory results.
Analog video input to your workstation through an analog video connector is digitized and often converted to YCrCb in memory. YCrCb is also the colorspace used in many compression schemes (for example, MPEG and JPEG). On some Silicon Graphics video devices and connectors, component analog such as BetaSP and MII formats are digitized into a full-range YUV representation.
When working with analog video, the main points to be aware of are:
bandwidth limitations (composite analog video uses a method devised to cope with bandwidth restrictions of early transmission methods for broadcast color television)
chroma/luma crosstalk
chroma aliasing
Refer to the video references listed in the introduction of this guide for more information.
A common problem when importing video data for computer graphics display (or outputting synthesized computer graphics to video) is that pictures can look darker than expected or can look somewhat hazy because video and computer graphics use a different color scale. In Rec. 601 video, the black level (blackest black) is 16, but in computer graphics, 0 is blackest black. If a picture whose blackest black is 16 is displayed by a system that uses 0 as the blackest black, the image colors are all grayed out as a result of shifting the colors to this new scale. The best results are obtained by choosing the correct colorspace. The black level is related to bias, which sets the reference level for a color scale.
Video is sampled both spatially and temporally. Video is sampled and displayed such that only half the lines needed to create a picture are scanned at a particular instant in time. This is a result of the historical bandwidth limitations of broadcast video, but it is an important video concept.
A video field is a set of image samples, practically coincident in time, that is composed of every other line of an image. Each field in a video sequence is sampled at a different time, determined by the video signal's field rate. Upon display, two consecutive fields are interlaced, a technique whereby a video display scans every other line of a video image at a rate fast enough to be undetectable to the human eye. The persistence of the phosphors on the display screen holds the impression of the first set of scan lines just long enough for them to be perceived as being shown simultaneously to the second set of scan lines. (Actually, this is only strictly true of tube-based display devices whose electron beams take a whole field time to scan each line across the screen (from left-to-right then top-to-bottom). Array-based display devices change the state of all the pixels on the screen (or all the pixels on a given line) simultaneously)
The human eye cannot detect and resolve the two fields in a moving image displayed in this manner, but it can detect them in a still image, such as that shown when you pause a videotape. When you attempt to photograph or videotape a computer monitor using a camera, this effect is visible.
Most video signals in use today, including the major video signal formats you are likely to encounter and work with on a Silicon Graphics computer (NTSC, PAL, and 525- and 625-line Rec. 601 digital video), are field-based rather than frame-based. Correctly handling fields in software involves understanding the effects of temporal and spatial sampling.
Suppose you have an automatic film advance camera that can take 60 pictures per second, with which you take a series of pictures of a moving ball. Figure 2-3 shows 10 pictures from that sequence (different colors are used to emphasize the different positions of the ball in time). The time delay between each picture is a 60th of a second, so this sequence lasts 1/6th of a second.

Now suppose you take a modern NTSC video camera and shoot the same sequence. NTSC video has 60 fields per second, so you might think that the video camera would record the same series of pictures as Figure 2-3, but it does not. The video camera does record 60 images per second, but each image consists of only half of the scanlines of the complete picture at a given time, as shown in Figure 2-4, rather than a filmstrip of 10 complete images.

Notice how the odd-numbered images contain one set of lines, and the even-numbered images contain the other set of lines (if you can't see this, click on the figure to bring up an expanded view).
Video data does not contain one complete image stored in every other frame, as shown in Figure 2-5.

Nor does video data contain two consecutive fields, each containing every other line of an identical image, as shown in Figure 2-6.

Data in video fields are temporally and spatially distinct. In any video sequence, half of the spatial information is omitted for every temporal instant. This is why you cannot treat video data as a sequence of intact image frames. See “Freezing Video” in Chapter 4 for methods of displaying still frames of motion video.
Other video formats, many of which are used for computer monitors, have only one field per frame (often the term field is not used at all in these cases), which is called noninterlaced or progressive scan. Sometimes, video signals have fields, but the fields are not spatially distinct. Instead, each field contains the information for one color basis vector (R, G, and B for example); such signals are called field sequential.
It is important to use precise terminology when writing software or communicating with others regarding fields. Some terminology for describing fields is presented next.
Interlaced video signals have a natural two-field periodicity. F1 and F2 are the names given to each field in the sequence. When viewing the waveform of a video field on an oscilloscope, you can tell whether it is an F1 field or an F2 field by the shape of its sync pulses.
ANSI/SMPTE 170M-1994 defines Field 1, Field 2, Field 3, and Field 4 for NTSC.
ANSI/SMPTE 125M-1992 defines the 525-line version of the bit-parallel digital Rec.-601 signal, using an NTSC waveform for reference. ANSI/SMPTE 259M-1993 defines the 525-line version of the bit-serial digital Rec.-601 signal in terms of the bit-parallel signal. 125M defines Field 1 and Field 2 for the digital signal.
Rec. 624-1-1978 defines Field 1 and Field 2 for 625-line PAL.
Rec. 656 Describes a 625-line version of the bit-serial and bit-parallel Rec.-601 digital video signal. It defines Field 1 and Field 2 for that signal.
The Digital Media Libraries define F1 as an instance of Field 1 or Field 3 and F2 as an instance of Field 2 or Field 4.
Field dominance is relevant when transferring data in such a way that frame boundaries must be known and preserved, such as:
GPI/VLAN/LTC-triggered capture or playback of video data
edits on a VTR
interpretation of fields in a VLBuffer for the purposes of interlacing or deinterlacing
Field dominance defines the order of fields in a frame and can be either F1 dominant or F2 dominant.
F1 dominant specifies a frame as an F1 field followed by an F2 field. This is the protocol recommended by all of the specifications listed at the end of the “Video Fields” section.
F2 dominant specifies a frame as an F2 field followed by an F1 field. This is the protocol followed by several New York production houses for the 525-line formats only.
Most older VTRs cannot make edits on any granularity finer than the frame. The latest generation of VTRs are able to make edits on arbitrary field boundaries, but can (and most often are) configured to make edits only on frame boundaries. Video capture or playback on a computer, when triggered, must begin on a frame boundary. Software must interlace two fields from the same frame to produce a picture. When software deinterlaces a picture, the two resulting fields are in the same frame.
Regardless of the field dominance, if there are two contiguous fields in a VLBuffer, the first field is always temporally earlier than the second one: Under no circumstances should the temporal ordering of fields in memory be violated.
The terms even and odd can refer to whether a field's active lines end up as the even scanlines of a picture or the odd scanlines of a picture. In this case, you need to additionally specify how the scanlines of the picture are numbered (beginning with 0 or beginning with 1), and you may need to also specify 525 vs. 625 depending on the context.
Even and odd could also refer to the number 1 or 2 in F1 and F2, which is of course a different concept that only sometimes maps to the notion of whether a field's active lines end up as the even scanlines of a picture or the odd scanlines of a picture. This definition seems somewhat more popular.
For example:
VL_CAPTURE_ODD_FIELDS captures F1 fields
VL_CAPTURE_EVEN_FIELDS captures F2 fields
The way in which two consecutive fields of video should be interlaced to produce a picture depends on
which field is an F1 field and which field is an F2 field
whether the fields are from a 525- or 625-line signal.
The interlacing does not depend on
the relative order of the fields, that is, which one is first
anything relating to field dominance
Line numbering in memory does not necessarily correspond to the line numbers in a video specification. Software line numbering can begin with either a 0 or 1. Picture line numbering scheme in software is shown both 0-based (like the Movie Library) and 1-based.
For 525-line analog signals, the picture should be produced in this manner (F1 has 243 active lines, F2 has 243 active lines, totaling 486 active lines):
field 1 field 2 0-based 1-based
(second half only)-----| l.283 0 1
l.21 |----------------------- | 1 2
| -----------------------| 2 3
|----------------------- |-- F2 3 4
F1 --| -----------------------| 4 5
|----------------------- | ... ...
| -----------------------| ... ...
|----------------------- | 483 484
| -----------------------| l.525 484 485
l.263 |------(first half only) 485 486
|
For official 525-line digital signals, the picture should be produced in this manner (F1 has 244 active lines, F2 has 243 active lines, totaling 487 active lines):
field 1 field 2 0-based 1-based
l.20 |----------------------- 0 1
| -----------------------| l.283 1 2
l.21 |----------------------- | 2 3
| -----------------------| 3 4
|----------------------- |-- F2 4 5
F1 --| -----------------------| 5 6
|----------------------- | ... ...
| -----------------------| ... ...
|----------------------- | 484 485
| -----------------------| l.525 485 486
l.263 |----------------------- 486 487
|
For practical 525-line digital signals, all current Silicon Graphics video hardware skips line 20 of the signal and pretends that the signal has 486 active lines. As a result, you can think of the digital signal as having exactly the same interlacing characteristics and line numbers as the analog signal (F1 has 243 active lines and F2 has 243 active lines, totaling 486 active lines):
field 1 field 2 0-based 1-based
-----------------------| l.283 0 1
l.21 |----------------------- | 1 2
| -----------------------| 2 3
|----------------------- |-- F2 3 4
F1 --| -----------------------| 4 5
|----------------------- | ... ...
| -----------------------| ... ...
|----------------------- | 483 484
| -----------------------| l.525 484 485
l.263 |----------------------- 485 486
|
For 625-line analog signals, the picture should be produced in this manner (F1 has 288 active lines, F2 has 288 active lines):
field 1 field 2 0-based 1-based
l.23 |--(second half only)--- 0 1
| -----------------------| l.336 1 2
|----------------------- | 2 3
F1 --| -----------------------| 3 4
|----------------------- |-- F2 4 5
| -----------------------| ... ...
|----------------------- | ... ...
| -----------------------| 573 574
l.310 |----------------------- | 574 575
----(first half only)--| l.623 575 576
|
For 625-line digital signals, the picture should be produced in this manner (F1 has 288 active lines, F2 has 288 active lines):
field 1 field 2 0-based 1-based
l.23 |----------------------- 0 1
| -----------------------| l.336 1 2
|----------------------- | 2 3
F1 --| -----------------------| 3 4
|----------------------- |-- F2 4 5
| -----------------------| ... ...
|----------------------- | ... ...
| -----------------------| 573 574
l.310 |----------------------- | 574 575
-----------------------| l.623 575 576
|
All Field 1 and Field 2 line numbers match those in SMPTE 170M and Rec. 624. Both of the digital specs use identical line numbering to their analog counterparts. However, Video Demystified and many chip specifications use nonstandard line numbers in some (not all) of their diagrams. A word of caution: 125M draws fictitious half-lines in its figure 3 in places that do not correspond to where the half-lines fall in the analog signal.
This section describes digital image data attributes and how to use them. Image attributes can apply to the image as a whole, to each pixel, or to a pixel component.
Parameters in dmedia/dm_image.h provide a common language for describing image attributes for the Digital Media Libraries. Not all of the libraries require or use all of the DM image parameters. Clones of some DM image parameters can be found in vl.h.
Digital image attributes described in this section are:
These attributes and the parameters that represent them are discussed in detail in the sections that follow.
Image size is measured in pixels: DM_IMAGE_WIDTH is the number of pixels in the x (horizontal) dimension, and DM_IMAGE_HEIGHT is the number of pixels in the y (vertical) dimension.
Video streams and movie files contain a number of individual images of uniform size. The image size of a video stream or a movie file refers to the height and width of the individual images contained within it, and is often referred to as frame size.
Some image formats require that the image dimensions be integral multiples of a factor, necessitating either cropping or padding of images that don't conform to those requirements.
| Note: To determine the size of an image in bytes, use dmImageFrameSize(3dm). |
Pixels aren't always perfectly square, in fact they often aren't. The shape of the pixel is defined by the pixel aspect ratio. The pixel aspect ratio is obtained by dividing the pixel height by the pixel width and is represented by DM_IMAGE_PIXEL_ASPECT.
Square pixels have a pixel aspect ratio of 1.0. Some video formats use nonsquare pixels, but computer display monitors typically have square pixels, so a square/nonsquare pixel conversion is needed for the image to look correct when displaying digital video images on the graphics monitor.
In general graphics rendering and display devices typically generate/accept only square pixels, but video I/O devices can typically generate/accept either square or nonsquare formats. It is probably preferable to use/retain a nonsquare format for an application whose purpose is to produce video, while it is probably preferable for an application whose ultimate intent is producing computer graphics to use/retain a square format. Whether a conversion is necessary or optimal depends on the original image source, the final destination, and, to a certain extent, the hardware path transporting the signal.
For example, the digital sampling of analog video in accordance to Rec. 601 yields a nonsquare pixel. On the other hand, graphics displays render each pixel as square. This means that a Rec. 601 nonsquare or video input stream sent directly (without filtering) to the workstation's video output displays correctly on an external video monitor, but does not display correctly when sent directly (without filtering) to an onscreen graphics window.
Conversely, computer-originated digital video (640x480 and 768x576) displays incorrectly when sent to video out in nonsquare mode, but displays correctly when sent to an onscreen graphics window or to video out in square mode.
Some Silicon Graphics video devices sample natively using only one format, either square or nonsquare, and some Silicon Graphics video devices filter signals on certain connectors. See the video device reference pages for details.
Some video options for Silicon Graphics workstations perform square/nonsquare filtering in hardware; refer to your owner's manual to determine whether your video option supports this feature. Software filtering is also possible.
Compression is a method of encoding data more efficiently without changing its content significantly.
A codec (compressor/decompressor) defines a compressed data format. In some cases such as MPEG, the codec also defines a standard file format in which to contain data of that format. Otherwise, there is a set of file formats that can hold data of that format.
A “stateful” algorithm works by encoding the differences between multiple frames, as opposed to encoding each frame independently of the others. Stateful codecs are hard to use in an editing environment but generally produce better compression results because they get access to more redundancy in the data.
A “tile-based” algorithm (such as MPEG) divides the image up into (what is usually) a grid of fixed sections, usually called blocks, macroblocks, or macrocells. The algorithm then compresses each region independently. Tile-based algorithms are notorious for producing output with visible blocking artifacts at the tile boundaries. Some algorithms specify that the output is to be blurred to help hide the artifacts.
A “transform-based” algorithm (such as JPEG) takes the pixels of the image (which constitute the spatial domain) and transforms them into another domain—one in which data is more easily compressed using traditional techniques (such as RLE, Lempel-Ziv, or Huffman) than the spatial domain. Such algorithms generally do a very good job at compressing images. The computational cost of the transformation is generally high, so:
Transform-based algorithms are typically more expensive than spatial domain algorithms.
Transform-based algorithms are typically also tile-based algorithms (since the computation is easier on small tiles), and thus suffer the artifacts of tile-based algorithms.
For most compression algorithms, the compressed data stream is designed so that the video can be played forward or backward, but some compression schemes, such as MPEG, are predictive and so are more efficient for forward playback.
Although any algorithm can be used for still video images, the JPEG (Joint Photographic Experts Group)-baseline algorithm, which is referred to simply as JPEG for the remainder of this guide, is the best for most applications. JPEG is denoted by the DM parameter DM_IMAGE_JPEG.
JPEG is a compression standard for compressing full-color or grayscale digital images. It is a lossy algorithm, meaning that the compressed image is not a perfect representation of the original image, but you may not be able to detect the differences with the naked eye. Because each image is coded separately (intra-coded), JPEG is the preferred standard for compressed digital nonlinear editing.
JPEG is based on psychovisual studies of human perception: Image information that is generally not noticeable is dropped out, reducing the storage requirement anywhere from 2 to 100 times. JPEG is most useful for still images; it is usable, but slow when performed in software, for video. (Silicon Graphics hardware JPEG accelerators are available for compressing video to and decompressing video from memory, or for compressing to and decompressing from a special video connection to a video board. These JPEG hardware accelerators implement a subset of the JPEG standard (baseline JPEG, interleaved YCrCb 8-bit components) especially for video-originated images on Silicon Graphics workstations.
The typical use of JPEG is to compress each still frame during the writing or editing process, with the intention of applying another type of compression to the final version of the movie or to leave it uncompressed. JPEG works better on high-resolution, continuous-tone images such as photographs, than on crisp-edged, high-contrast images such as line drawings.
The amount of compression and the quality of the resulting image are independent of the image data. The quality depends on the compression ratio. You can select the compression ratio that best suits your application needs.
For more information, see jpeg(4). See also Pennebaker, William B. and Joan L. Mitchell, JPEG Still Image Data Compression Standard, New York: Van Nostrand Reinhold, 1993 (ISBN 0-442-01272-1).
MPEG-1 (ISO/IEC 11172) is the Moving Pictures Expert Group standard for compressing audio, video, and systems bitstreams. The MPEG-1 systems specification defines multiplexing for compressed audio and video bitstreams without performing additional compression. An MPEG-1 encoded systems bitstream contains compressed audio and video data that has been packetized and interleaved along with timestamp and decoder buffering requirements. MPEG-1 allows for multiplexing of up to 32 compressed audio and 16 compressed video bitstreams. Each bitstream type has its own syntax, as defined by the standard.
MPEG-1 video (ISO/IEC 11172-2) is a motion video compression standard that minimizes temporal and spatial data redundancies to achieve good image quality at higher compression ratios than either JPEG or MVC1.
MPEG-1 video uses a technique called motion estimation or motion search, which compresses a video stream by comparing image data in nearby image frames. For example, if a video shows the same subject moving against a background, it's likely that the same foreground image appears in adjacent frames, offset by a few pixels. Compression is achieved by storing one complete image frame, which is called a keyframe or I frame, then comparing an n¥n block of pixels to nearby pixels in proximal frames, searching for the same (or similar) block of pixels, and then storing only the offset for the frames where a match is located. Images from the intervening frames can then be reconstructed by combining the offset data with the keyframe data.
There are two types of intervening frames:
P (predictive) frames, which require information from previous P or I frames in order to be decoded. P frames are also sometimes considered forward reference frames because they contain information needed to decode other P frames later in the video bitstream.
B (between) frames, which require information from both the previous and next P or I frame.
Figure 2-7 shows the relationships between I, P, and B frames.

For example, suppose an MPEG-1 video bitstream contains the sequence I0 P3 B1 B2 P6 B4 B5 P9 B7 B8, where the subscripts indicate the order in which the frames are to be displayed. You must first display I0 and retain its information in order to decode P3, but you cannot yet display P3 because you must first decode and display the two between frames (B1 and B2), which also require information from P3, as well as from each other, to be decoded. Once B1 and B2 have been decoded and displayed, you can display P3, but you must retain its information in order to decode P6, and so on.
MPEG is an asymmetric coding technique—compression requires considerably more processing power than decompression because MPEG examines the sequence of frames and compresses them in an optimized way, including compressing the difference between frames using motion estimation. This makes MPEG well suited for video publishing, where a video is compressed once and decompressed many times for playback. Because MPEG is a predictive scheme, it is tuned for random access (editing) due to its inter-coding, or for forward playback rather than backward. MPEG is used on Video CD, DVD, Direct TV, and is the proposed future standard for digital broadcast TV.
For more information, see mpeg(4).
Run-length encoding (RLE) compresses images by replacing pixel values that are repeated for several pixels in a row with a single pixel at the first occurrence of a particular value, followed by a run-length (a count of the number of subsequent pixels of the same value) every time the color changes. Although this algorithm is lossless, it doesn't save as much space as the other compression algorithms—typically less than 2:1 compression is achieved. It is a good technique for animations where there are large areas with identical colors. The Digital Media Libraries have two RLE methods:
| DM_IMAGE_RLE |
| |
| DM_IMAGE_RLE24 |
|
Motion Video Compressor (MVC) is a Silicon Graphics proprietary algorithm that is a good general-purpose compression scheme for movies. MVC is a color-cell compression technique that works well for video, but can cause fuzzy edges in high-contrast animation. There are 2 versions:
| DM_IMAGE_MVC1 |
| |
| DM_IMAGE_MVC2 |
|
QuickTime is an Apple Macintosh® system software extension that can be installed in the Macintosh system to extend its capabilities so as to allow time-based (audio, video, and animation) data for multimedia applications.
Movies compressed with QuickTime store and play picture tracks and soundtracks independently of each other, analogous to the way the Movie Library stores separate image and audio tracks. You can't work with pictures and sound as separate entities using the QuickTime Starter Kit utilities on the Macintosh, but you can use the Silicon Graphics Movie Library to work with the individual image and audio tracks in a QuickTime movie.
QuickTime movie soundtracks are playable on Macintosh and Silicon Graphics computers, but each kind of system has a unique audio data format, so audio playback is most efficient when using the native data format and rate for the computer on which the movie is playing.
The Macintosh QuickTime system software extension includes five codecs:
Apple None (uncompressed)
Apple Photo (JPEG standard)
Apple Compact Video (Cinepak)
Apple None creates an uncompressed movie and can be used to change the number of colors in the images and/or the recording quality. Both the number of colors and the recording quality can affect the size of the movie.
To create an uncompressed QuickTime movie on the Macintosh, click on the “Apple None” choice in the QuickTime Compression Settings dialog box.
| Note: Because the Macintosh software compresses QuickTime movies by default, you must set the compression to Apple None and save the movie again to create an uncompressed movie. |
Apple Photo uses the JPEG standard. JPEG is best suited for compressing individual still frames, because decompressing a JPEG image can be a time-consuming task, especially if the decompression is performed in software. JPEG is typically used to compress each still frame during the writing or editing process, with the intention of applying another type of compression to the final version of the movie or leaving it uncompressed.
Apple Animation uses a lossy run-length encoding (RLE) method, which compresses images by storing a color and its run-length (the number of pixels of that color) every time the color changes. Apple Animation is not a true lossless RLE method because it stores colors that are close to the same value as one color. This method is most appropriate for compressing images such as line drawings that have highly contrasting color transitions and few color variations.
Apple Video uses a method whose objective is to decompress and display movie frames as fast as possible. It compresses individual frames and works better on movies recorded from a video source than on animations.
| Note: Both Apple Animation and Apple Video compression have a restriction that the image width and height be a multiple of 4. Before transferring a movie from a Macintosh to a Silicon Graphics computer, make sure that the image size is a multiple of 4. |
Cinepak (developed by Radius, Inc.), otherwise known as “Compact Video,” is a compressed data format that can be stored inside QuickTime movies. It achieves better compression ratios than QuickTime but takes much more CPU time to compress.
The Cinepak format is designed to control its own bitrate, and thus it is extremely common on the World Wide Web and is also used in CD authoring.
Cinepak is not a transform-based algorithm. It uses techniques derived from “vector quantization” (which technically is also what color-cell compression techniques such as MVC1 and MVC2 use) to represent small tiles of pixels using a small set of scalars. Cinepak builds and constantly maintains a “codebook,” which it uses to map the compressed scalars back into pixel tiles. The codebook evolves over time as the image changes, thus this algorithm is stateful.
Compressed data isn't always a perfect representation of the original data. Information can be lost in the compression process. A lossless compression method retains all of the information present in the original data. Algorithms can be either numerically lossless or mathematically lossless. Numerically lossless means that the data is left intact. Mathematically lossless means that the compressed data is acceptably close to the original data.
A lossy compression method does not preserve 100% of the information in the original method.
Image quality is a measure of how true the compression is to the original image. Image quality is one of the conversion controls that you can specify for an image converter. Image quality is specified in both the spatial and temporal domains.
In a spatial approximation, pixels from a single image are compared to each other, and identical (or similar) pixels are noted as repeat occurrences of a stored representative pixel. Spatial quality, denoted by DM_IMAGE_QUALITY_SPATIAL, conveys the exactness of a spatial approximation.
In a temporal approximation, pixels from an image stream are compared across time, and identical (or similar) pixels are noted as repeat occurrences of a stored representative pixel, but offset in time. Temporal quality, denoted by DM_IMAGE_QUALITY_TEMPORAL, conveys the exactness of a temporal approximation.
Some lossless algorithms may require a quality factor, so specify DM_IMAGE_QUALITY_LOSSLESS.
Quality values range from 0 to 1.0, where 0 represents complete loss of the image fidelity and 1.0 represents lossless image fidelity. You can set both quality factors numerically, or you can use the following rule-of-thumb factors to set quality informally:
DM_IMAGE_QUALITY_MIN | approximately equal to 0 quality factor |
DM_IMAGE_QUALITY_LOW | approximately equal to 0.25 quality factor |
DM_IMAGE_QUALITY_NORMAL | approximately equal to 0.5 quality factor |
DM_IMAGE_QUALITY_HIGH | approximately equal to 0.75 quality factor |
DM_IMAGE_QUALITY_MAX | approximately equal to 0.99 quality factor |
Using these “fuzzy” quality factors can be useful if your application uses a thumbwheel or slider to let the user indicate quality. These quality factors can be assigned to intermediate steps in the slider or thumbwheel to give the impression of infinitely adjustable quality.
The compression ratio is a tradeoff between the quality and the bitrate. Adjusting either one of these parameters affects the other, and, if both are set, bitrate usually takes precedence in the Silicon Graphics Digital Media Libraries.
For applications that require a constant bitrate, such as applications that send data over fixed data rate carriers or playback image streams at a minimum threshold rate, set DM_IMAGE_BITRATE. The picture quality is then adjusted to achieve the stated rate. Some Silicon Graphics algorithms guarantee the bitrate, some try to achieve the stated rate, and some do not support a bitrate parameter.
Certain compression algorithms such as MPEG use a technique called motion estimation, which compresses an image stream by storing a complete keyframe and then encoding related image data in nearby image frames, as described in “MPEG-1.” Images from the encoded frames are decoded based on the keyframes or other encoded frames that precede or follow the frame being decoded.
The Digital Media Libraries have their own terminology to define three types of frames possible in a motion estimation compression method:
| Intra | depends only on itself; contains all data needed to construct a complete image. Also called I frame or keyframe. | |
| Inter | depends on a previous inter- or intra-frame. Also called reference frame, P (predictive) frame, or delta frame. | |
| Between | depends on previous and next inter- or intra-frame; cannot be reconstructed using another between frame. Also called B frame. |
There are two parameters for setting the distance between keyframes and reference frames:
DM_IMAGE_KEYFRAME_DISTANCE | specifies the distance between keyframes |
DM_IMAGE_REFFRAME_DISTANCE | specifies the distance between reference frames |
Image orientation refers to the relative ordering of the horizontal scan lines within an image. The scanning order depends on the image source and can be either top-to-bottom or bottom–to–top, but it is important to know which. The default DM_IMAGE_ORIENTATION for images created on a Silicon Graphics workstation is bottom-to-top, denoted by DM_IMAGE_BOTTOM_TO_TOP. Video and compressed video is typically oriented top-to-bottom.
Interlacing is a video display technique that minimizes the amount of video data necessary to display an image by exploiting human visual acuity limitations. Interlacing weaves alternate lines of two separate fields of video at half the scan rate. For an explanation of interlacing, see “Video Fields.”
Generally, interlacing refers to a technique for signal encoding or display, and interleaving refers to a method of laying out the lines of video data in memory.
Interleaving can also refer to how the samples of an image's different color basis vectors are arranged in memory, or how audio and video are arranged together in memory. Interleaving image pixel data is described in “Pixel Component Order and Interleaving.”
A movie file encodes pairs of fields into what it calls frames, and all data transfers are on frame boundaries. A two-field image in a movie file does not always represent a complete video frame because it could be clipped or not derived from video. This is further complicated by that fact that both top-to-bottom and bottom-to-top ordering of video lines in images are supported.
DM_IMAGE_INTERLACING describes the original interlacing characteristics of the signal that produced this image (or lack of interlacing characteristics).
In a zero-based picture line numbering scheme for noninterlaced images:
In a DM_IMAGE_INTERLACED_ODD image, the scanlines of the first field occupy the odd-numbered lines (1, 3, 5, 7, and so on).
In a DM_IMAGE_INTERLACED_EVEN image, the scanlines of the first field occupy the even-numbered lines (0, 2, 4, 8, and so on).
In this sense, first field means the image that is first temporally and in memory.
| Note: If the DM_IMAGE _ORIENTATION is DM_BOTTOM_TO_TOP instead of DM_TOP_TO_BOTTOM, then all temporal ordering and memory ordering rules are reversed. |
For an example of how DM_IMAGE_INTERLACING relates to video, consider a top-to-bottom buffer containing unclipped video data (a buffer containing all the video lines described for analog 525, practical digital 525, analog 625, and digital 625-line signals). The buffer's DM_IMAGE_INTERLACING depends on many factors.
For a signal with F1 dominance, a frame consists of an F1 field followed by an F2 field (temporally and in memory). The DM_IMAGE_INTERLACING parameter determines which picture lines contain the first field's data:
for an analog or practical digital 525-line image, DM_IMAGE_INTERLACED_ODD
for an analog or digital 625-line image, DM_IMAGE_INTERLACED_EVEN
However, if the signal has F2 dominance, where a frame consists of F2 followed by F1, the first field is now an F2 field so:
for an analog or practical digital 525-line image, DM_IMAGE_INTERLACED_EVEN
for an analog or digital 625-line image, DM_IMAGE_INTERLACED_ODD
DM_IMAGE_LAYOUT describes how pixels are arranged in an image buffer. In the DM_IMAGE_LAYOUT_LINEAR layout, lines of pixels are arranged sequentially. This is the typical image layout for most image data.
DM_IMAGE_LAYOUT_GRAPHICS and DM_IMAGE_LAYOUT_MIPMAP are two special layouts optimized for presentation to Silicon Graphics hardware. Both are passthrough formats; they are intended for use with image data that is passed untouched from a Silicon Graphics graphics or video input source directly to hardware. Use DM_IMAGE_LAYOUT_GRAPHICS to format image data sent to graphics display hardware. Use DM_IMAGE_LAYOUT_MIPMAP to format image data that represents a texture mipmap that is sent to texture memory, such as a video texture.
This section describes image attributes that are specified on a per-pixel or per-pixel-component basis. Understanding these attributes requires some familiarity with the color concepts described in “Digital Image Essentials.”
Pixel packing formats define the bit ordering used for packing image pixels in memory. Native packings are supported directly in hardware. In other words, native packings don't require a software conversion.
DM_IMAGE_PACKING parameters describe pixel packings recognized by the dmIC and Movie Library APIs. In addition to the DM_IMAGE_PACKING formats, there is also a set of VL_PACKING parameters in vl.h that describe image packings. There are some VL_PACKINGS that have no corresponding DM_IMAGE_PACKINGS.
For some packings, the DM_IMAGE_DATATYPE parameter controls how data is packed within the pixel. For example, 10-bit-per-pixel data can be left or right-justified in a 16-bit word.
The most common ways of packing data into memory are YCrCb and 32-bit RGBA.
YCrCb (4:2:2) Video Pixel Packing
Rec. 601 component digital video (4:2:2 subsampled) is composed of one 8-bit Y (luma) component per pixel, and two chroma samples coincident with alternate luma samples, supplying one 8-bit Cr component per two pixels, and one 8-bit Cb sample per two pixels. This results in 2 bytes per pixel. This is the Silicon Graphics native format for storing video image data in memory, which is represented by the DM_IMAGE_PACKING parameter DM_IMAGE_PACKING_CbYCrY, and the VL_PACKING parameter VL_PACKING_YVYU_422_8.
| Note: The SMPTE 259M (specification for transmitting Rec. 601 over a link) digital video stream contains 10 bits in each component. An 8-bit packing format such as VL_PACKING_YVYU_422_8 uses only 8 of the 10 bits. This often generates acceptable results for strictly video data, but in order to parse some forms of ancillary data (such as embedded audio data) from a video stream, it is necessary to input all 10 bits. Because 10 bits is an atypical quantity for computers, the most common technique is to left-shift each 10-bit quantity to a 16-bit value, resulting in a 4-byte per component format called VL_PACKING_YVYU_422_10, where the extra bits are zero-padded on input and ignored on output. Storing data in this format takes more memory space, but may be preferable to the cost of manipulating 10-bit packed data on the CPU. |
The pixel packing is independent of the colorspace. The use of a packing named “YUV” or “YVYU” does not imply that the data packed is YUV data, as opposed to YCrCb data. When YCrCb data is being packed with a YUV packing, the Cr component is packed as U, and the Cb component is packed as V. The VL_PACKING_YVYU_422_8 packing is the only packing that is natively supported in hardware (requiring no software conversion) on all VL video devices.
The 422 designation in the packing name means that the pixels are packed so that each horizontally adjacent pair of pixels share one common set of chroma (for example, UV, or alternatively, CrCb) data. Each pixel has its own value of luma (Y) data. So, data is packed in pairs of two pixels, two Y values, and one U and one V (or alternatively, one Cr and one Cb) value pair, in each pixel pair. This pixel packing always has an even number of pixels in each row.
The YUV and YCrCb colorspaces are similar, but they differ primarily in the ranges of acceptable values for the three components when represented as digital integers. The values of Y, U and V are in the range 0..255 (the SMPTE YUV ranges), while the range for Rec. 601 YCrCb is 16..235/240.
The set of VL packings presently defined does not enable the application to choose between the YUV and Rec. 601 YCrCb colorspaces. When an application specifies VL_PACKING_YVYU_422_8, the resultant colorspace is either YUV or YCrCb, depending on the device and the source node from which the data is coming. Most external digital sources produce YCrCb data. IndyCam produces Rec. 601-compliant YCrCb. There is no way to tell, from the VL_PACKING control, which of those two spaces (YUV or YCrCb) is used.
Each type of VL video device has a different set of colorspaces and packings implemented in hardware. Any other colorspaces and/or packings are implemented by means of a software conversion. Table 2-1 shows which color space and packing combinations are implemented in hardware or software, or not at all, for each device.
The chipset used in VINO and EV1 to convert analog input to digital pixels produces YUV output, not YCrCb output. That is, the values of Y, U and V are in the range 0..255 (the SMPTE YUV ranges), not the smaller 16..235/240 range specified for Rec. 601 YCrCb. For some devices that can't convert colorspace in hardware, such as EV1, the VL converts from YUV to RGBX/RGBA in software.
The VL routines used for this purpose assume the input is Rec. 601 YCrCb, not YUV, regardless of what the hardware actually produces. Therefore, if the hardware doesn't support the desired colorspace, and you require an accurate colorspace conversion, then specify pixels in a colorspace supported by the hardware, and do the colorspace conversion using dmIC or similar software converter, rather than relying on an automatic software colorspace conversion.
With Sirius Video, colorspace and packing are independent. Colorspace is chosen by the settings of the VL_FORMAT on the memory drain node, according to table below, and any packing can be applied to any colorspace, whether it makes sense or not. Colorspace conversion occurs when the VL_FORMAT of the video source node and the VL_FORMAT of the memory drain node imply different colorspaces.
32-Bit RGBA Graphics Pixel Packing
In 32-bit RGBA, the A may be a “don't care” or it may be an alpha channel, synthesized on the computer. This results in 4 bytes per pixel. In the VL, this is called VL_PACKING_RGBA_8, VL_PACKING_RGB_8, and VL_PACKING_ABGR_8.
Table 2-1 shows the results in memory of reading pixels (or the source for writing pixels) in various formats. Pixel 0 is the leftmost pixel read or written. An `x' means don't care (this bit is not used).
Memory layout is presented in 32-bit words, with the MSB on the left and the LSB on the right (read the bit numbers vertically).
Table 2-1. Pixel Packing Formats
MSB |
|
| LSB | Packing Format |
|---|---|---|---|---|
33222222 | 22221111 | 111111 |
|
|
bbgggrrr | bbgggrrr | bbgggrrr | bbgggrrr | DM_IMAGE_PACKING_8BGR |
aaaaaaaa | bbbbbbbb | gggggggg | rrrrrrrr | DM_IMAGE_PACKING_ABGR |
xxxxxxxx | bbbbbbbb | gggggggg | rrrrrrrr | DM_IMAGE_PACKING_XBGR |
uuuuuuuu | yyyyyyyy | vvvvvvvv | yyyyyyyy | DM_IMAGE_PACKING_CbYCrY |
|
|
|
| DM_IMAGE_PACKING_RBG323 |
xxxxxxxx | xxxxxxxx | xxxxxxxx | bbgggrrr | DM_IMAGE_PACKING_BGR233 |
xxxxxxxx | xxxxxxxx | xxxxxxxx | rrrgggbb | VL_PACKING_BGR_332 |
bbgggrrr | bbgggrrr | bbgggrrr | bbgggrrr | VL_PACKING_RGB_332_IP |
rrrgggbb | rrrgggbb | rrrgggbb | rrrgggbb | VL_PACKING_BGR332_P |
xxxxxxx | xxxxxxx | bbbbbggg | gggrrrrr | VL_PACKING_RGB-565 |
bbbbbggg | gggrrrrr | bbbbbggg | gggrrrrr | VL_PACKING_RGB_565_P |
rrrrrrrr | bbbbbbbb | gggggggg | rrrrrrrr | VL_PACKING_RGB_565_IP |
xxbbbbbb | bbbbgggg | ggggggrr | rrrrrrrr | VL_PACKING_RGB_10 |
yyyyyyyy | yyyyyyyy | yyyyyyyy | yyyyyyyy | DM_IMAGE_PACKING_LUMINANCE |
xxxxxxxx | uuuuuuuu | yyyyyyyy | vvvvvvvv | DM_IMAGE_PACKING_CbYCr |
aaaaaaaa | uuuuuuuu | yyyyyyyy | vvvvvvvv | VL_PACKING_YUV_4444_8 |
xxuuuuuu | uuuuyyyy | yyyyyyvv | vvvvvvvv | VL_PACKING_YUV_444_10 |
rrrrrrrr | gggggggg | bbbbbbbb | aaaaaaaa | DM_IMAGE_PACKING_RGBA |
vvvvvvvv | yyyyyyyy | uuuuuuuu | aaaaaaaa | DM_IMAGE_PACKING_CbYCrA |
rrrrrrrr | rrgggggg | ggggbbbb | bbbbbbaa | VL_PACKING_A_2_BGR_10 |
vvvvvvvv | vvyyyyyy | yyyyuuuu | uuuuuuaa | VL_PACKING_A_2_UYV_10 |
uuuuuuuu | uuyyyyyy | yyyyaaaa | aaaaaaxx | VL_PACKING_AYU_AYV_10 |
Table 2-2 lists DM_IMAGE_PACKING formats.
Table 2-2. DM Pixel Packing Formats
Pixel Packing Format |
|
|---|---|
DM_IMAGE_PACKING_RGB |
|
DM_IMAGE_PACKING_BGR |
|
DM_IMAGE_PACKING_RGBX |
|
DM_IMAGE_PACKING_RGBA |
|
DM_IMAGE_PACKING_XRGB |
|
DM_IMAGE_PACKING_ARGB |
|
DM_IMAGE_PACKING_XBGR |
|
DM_IMAGE_PACKING_ABGR |
|
DM_IMAGE_PACKING_RBG323 |
|
DM_IMAGE_PACKING_BGR233 |
|
DM_IMAGE_PACKING_XRGB1555 |
|
DM_IMAGE_PACKING_CbYCr |
|
DM_IMAGE_PACKING_CbYCrA |
|
DM_IMAGE_PACKING_CbYCrY |
|
DM_IMAGE_PACKING_CbYCrYYY |
|
DM_IMAGE_PACKING_LUMINANCE |
|
DM_IMAGE_PACKING_LUMINANCE_ALPHA |
|
DM_IMAGE_DATATYPE describes the number of bits per component and the alignment of the bits within the pixel. Table 2-3 lists the data type parameters and the attributes they describe.
Image Data Type Parameter | Attributes |
|---|---|
DM_IMAGE_DATATYPE_BIT | Nonuniform number of bits per component |
DM_IMAGE_DATATYPE_CHAR | 8 bits per component |
DM_IMAGE_DATATYPE_SHORT10L | 10 bits per component, left-aligned |
DM_IMAGE_DATATYPE_SHORT10R | 10 bits per component, right-aligned |
DM_IMAGE_DATATYPE_SHORT12L | 12 bits per component, left-aligned |
DM_IMAGE_DATATYPE_SHORT12R | 12 bits per component, right-aligned |
DM_IMAGE_ORDER describes the order of pixel components or blocks of components within an image and has one of the following formats:
DM_IMAGE_ORDER_INTERLEAVED orders pixels component by component.
DM_IMAGE_ORDER_SEQUENTIAL groups like components together line by line.
DM_IMAGE_ORDER_SEPARATE groups like components together per image.
Table 2-4 shows the resultant pixel component order for each interleaving method for some example image formats.
Table 2-4. Pixel Interleaving Examples
Packing Format | Interleaved | Sequential | Separate |
|---|---|---|---|
ABGR | ABGRABGR ABGRABGR ABGRABGR | AAABBBGGGRRR | AAAAAAAA |
444 YCrCb, with CbYCr packing | CbYCrCbYCr CbYCr | CbCbCbYYYCrCrCr CbCbCbYYYCrCrCr | CbCbCbCbCbCb |
420 YCrCb, with CbYCrY packing | CbYCrYYYCb YCrYYYCbY CrYYY | CbCbCbYYYYYYYYYYYYYCrCrCr | CbCbCbCbCbCb |
The digital representation of an audio signal is generated by periodically sampling the amplitude (voltage) of the audio signal. The samples represent periodic “snapshots” of the signal amplitude. The Nyquist Theorem provides a way of determining the minimum sampling frequency required to accurately represent the information (in a given bandwidth) contained in an analog signal. Typically, digital audio information is sampled at a frequency that is at least double the highest interesting analog audio frequency. See The Art of Digital Audio or a similar reference on digital audio for more information.
Parameters in dmedia/dm_audio.h provide a common language for describing digital audio attributes for the digital media libraries.
This section contains these topics, which describe digital audio attributes:
Audio Sample Format (for example, twos-complement binary, floating point)
Audio Sample Width (number of bits per sample)
A sample frame is a set of audio samples that are coincident in time. A sample frame for mono data is a single sample. A sample frame for stereo data consists of a left-right sample pair.
Stereo samples are interleaved; left-channel samples alternate with right-channel samples. 4-channel samples are also interleaved, with each frame usually having two left-right sample pairs, but there can be other arrangements.
Figure 2-8 shows the relationship between the number of channels and the frame size of audio sample data.
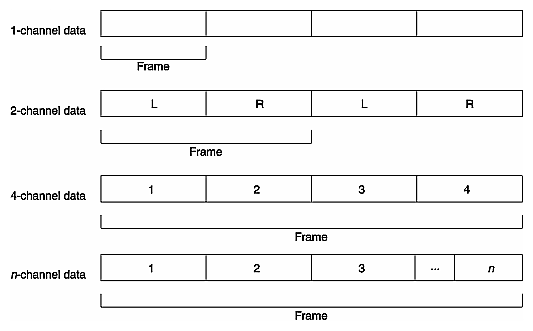
The sample rate is the frequency at which samples are taken from the analog signal. Sample rates are measured in hertz (Hz). A sample rate of 1 Hz is equal to one sample per second. For example, when a mono analog audio signal is digitized at a 48 kilohertz (kHz) sample rate, 48,000 digital samples are generated for every second of the signal.
To understand how the sample rate relates to sound quality, consider the fact that a telephone transmits voice-quality audio in a frequency range of about 320 Hz to 3.2 kHz. This frequency range can be represented accurately with a sample rate of 6.4 kHz. The range of human hearing, however, extends up to approximately 18–20 kHz, requiring a sample rate of at least 40 kHz.
The sample rate used for music-quality audio, such as the digital data stored on audio CDs is 44.1 kHz. A 44.1 kHz digital signal can theoretically represent audio frequencies from 0 kHz to 22.05 kHz, which adequately represents sounds within the range of normal human hearing. The most common sample rates used for DATs are 44.1 kHz and 48 kHz. Higher sample rates result in higher-quality digital signals; however, the higher the sample rate, the greater the signal storage requirement.
All audio data on Silicon Graphics systems is considered to have a compression scheme. The scheme may be an industry standard such as MPEG-1 audio, or it may be no compression at all. For more information, see “The Digital Media Color Space Library” in Chapter 6.
Uncompressed audio data is encoded in a digital data format called linear pulse code modulation (PCM) (see the audio references for a definition of this term) to represent digital audio samples.
The formats supported by the audio system are:
8-bit and 16-bit signed integer
24-bit signed, right-justified within a 32-bit integer
32-bit and 64-bit floating point
| Note: The audio hardware supports 16-bit I/O for analog data and 24-bit I/O for AES/EBU digital data. |
For floating point data, the application program specifies the desired range of values for the samples; for example, from -1.0 to 1.0. A method for relating data from one range of values to data with a different range of values is described next.
PCM mapping describes the relationship between data with differing sample ranges. If the input and output mappings are different, a conversion consisting of clipping and transformation of values is necessary.
PCM mapping defines a reference value, denoted by DM_AUDIO_PCM_MAP_INTERCEPT, that is the midway point between a signal swing. It is convenient to assign a value of zero to this point. Adding a slope value, denoted by DM_PCM_MAP_SLOPE, to the intercept obtains the full-scale deflection.
The values DM_AUDIO_PCM_MAP_MINCLIP and DM_AUDIO_PCM_MAXCLIP define the minimum and maximum legal PCM values. Input and output values are clipped to these values. If maxclip <= minclip, then no clipping is done because all PCM values are legal, even if they are outside the true full-scale range.
The native data format used by the audio hardware is 24-bit two's complement integers. The audio hardware sign-extends each 24-bit quantity into a 32-bit word before delivering the samples to the Audio Library.
Audio input samples delivered to the Audio Library from the Indigo, Indigo2™, and Indy™ audio hardware have different levels of resolution, depending on the input source that is currently active; the AL provides samples to the application at the desired resolution. You can also write your own conversion routine if desired.
Microphone/line-level input samples come from analog-to-digital (A/D) converters, which have 16-bit resolution. These samples are treated as 24-bit samples with 0's in the low 8 bits.
AES/EBU digital input samples have either 20-bit or 24-bit resolution, depending on the device connected to the digital input; for the 20-bit case (the most common), samples are treated as 24-bit samples, with 0's in the least significant 4 bits. The AL passes these samples through to the application if 24-bit two's complement is specified. If two's complement with 8-bit or 16-bit resolution is specified, the AL right-shifts the samples so that they fit into a smaller word size. For floating point data, the AL converts from the 24-bit format to floating point, using a scale factor specified by the application to map the peak integer values to peak float values.
For audio output, the AL delivers samples to the audio hardware as 24-bit quantities sign-extended to fill 32-bit words. The actual resolution of the samples from a given output port depends on the application program connected to the port. For example, an application may open a 16-bit output port, in which case the 24-bit samples arriving at the audio processor contains 0's in their least significant 8 bits.
The Audio Library is responsible for converting between the output sample format specified by an application and the 24-bit native format of the audio hardware. For 8-bit or 16-bit integer samples, this conversion is accomplished by left-shifting each sample written to the output port by 16 bits and 8 bits, respectively. For 32-bit or 64-bit floating point samples, this conversion is accomplished by rescaling each sample from the range of floating point values specified by the application to the full 24-bit range and then rounding the sample to the nearest integer value.
Table 2-5 lists the audio parameters and the valid values for each (not all values are supported by all libraries).
Parameter | Type | Values |
|---|---|---|
DM_AUDIO_CHANNELS | Integer | 1, 2, or 4 |
DM_AUDIO_COMPRESSION | String | DM_AUDIO_UNCOMPRESSED (default) |
DM_AUDIO_FORMAT | DMaudioformat | DM_AUDIO_TWOS_COMPLEMENT |
DM_AUDIO_RATE | Double | Native rates are 8000, 11025, 16000, 22050, 32000, 44100, and 48000 Hz |
DM_AUDIO_WIDTH | Integer | 8, 16, or 24 |
Most digital media applications use more than one medium at a time, for example, audio and video. This section explains how the data can be related for the various digital media functions that perform capture and presentation of concurrent media streams.
Timecodes are important for synchronizing and editing audio and video data.
There are different types of encoding methods and standards. In general, a timecode refers to a number represented as hours:minutes:seconds:frames. This numerical representation is used in a variety of ways (in both protocols and user interfaces), but in all cases the numbering scheme is the same. The SMPTE 12M standard provides definitions and specifications for a variety of timecodes and timecode signal formats.
The numerical ranges for each field in a timecode are as follows:
| hours | 00 to 23 | |
| minutes | 00 to 59 | |
| seconds | 00 to 59 | |
| frames | depends on the signal type |
Some signals use a drop-frame timecode, where some “hours:minutes:seconds:frame” combinations are not used; they are simply skipped in a normal progression of timecodes.
A timecode can refer to a
timer
timestamp
signal on wire
signal on tape
One example application where timecode is used merely as a way to express a time is mediaplayer, which displays the offset from the beginning of the movie either in seconds or as a timecode.
Another common computer application of timecode is as a timestamp on particular frames in a movie file. The Silicon Graphics movie file format and the QuickTime format offer the ability to associate each image in the file with a timecode. Sometimes these timecodes are synthesized by the computer, and sometimes they are captured with the source material. These timecodes are often used as markers so that edited or processed material can be later correlated with material edited or processed on another system. A/V professionals use an edit decision list (EDL) to indicate the timecodes frames to be recorded.
Longitudinal time code (LTC), sometimes ambiguously referred to as SMPTE time code, is a self-clocking signal defined separately for 525- and 625-line video signals, where the corresponding video signal itself is carried on another wire. The signal occupies its own channel and resembles an audio signal in voltage and bandwidth.
LTC is the most common way of slaving one system's transport to that of another system (by ensuring that both systems are on the same frame, not by genlocking signals on both machines). In some audio and MIDI applications, LTC is useful even though there is no video signal.
In an LTC signal, there is one codeword for each video frame. Each LTC codeword contains a timecode and other useful information.
See dmLTC(3dm) for routines for decoding LTC.
Vertical interval time code (VITC) is a standardized part of a 525- or 625-line video signal. The code itself occupies some lines in the vertical blanking interval of each field of the video signal (not normally visible on monitors). It's a good idea to provide data redundancy by recording the VITC on two nonconsecutive lines in case of video dropout.
Each VITC codeword contains a timecode and a group of flag bits that include
Dropframe
Colorframe
Parity
Field mark
The field mark bit is an F1/F2 field indicator; it is asserted for a specific field.
VITC also provides 32 user bits, where users can store information such as reel and shot number. This information can be used to help index footage after it is shot, and under the right circumstances (not always trivial), the original VITC recorded along with footage can even tag along with that footage as it is edited, allowing you to produce an edit list or track assets, given a final prototype edit.
See dmVITC(3dm) for routines for decoding VITC.
MIDI time code is part of the standard MIDI protocol, which is carried over a serial protocol that is also called MIDI. Production studios often need to synchronize the transports of computers with the transports of multitrack audio tape recorders and dedicated MIDI sequencers. Sometimes LTC is used for this, and sometimes the MIDI time code is the clock signal of choice.
The Digital Media Libraries provide their own temporal reference, called unadjusted system time (UST). The UST is an unsigned 64-bit number that measures the number of nanoseconds since the system was booted. UST values are guaranteed to be monotonically increasing and are readily available for all the Digital Media Libraries.
Typically, the UST is used as a timestamp, that is, it is paired with a specific item or location in a digital media stream. Because each type of media, and similarly each of the libraries, possesses unique attributes, the UST information is presented in a different manner in each library. Table 2-6 describes how UST information is provided by each of the libraries.
Table 2-6. Methods for Obtaining Unadjusted System Time
Library | UST Method |
|---|---|
Digital Media Library | dmGetUST() and dmGetUSTCurrentTimePair() |
Audio Library | ALgetframenumber() and ALgetframetime() |
MIDI Library | mdTell() and mdSetTimestampMode() |
Video Library | ustime field in the DMediaInfo structure |
The media stream count (MSC), with the UST, is used to synchronize buffered media data streams. UST/MSC pairs are used with libraries, such as the Audio Library and the Video Library, that provide timing information about the sampled data. The MSC is a monotonically increasing, unsigned 64-bit number that is applied to each sample in a media stream. This means the MSC of the most recent data sample has the largest value. By using the UST/MSC facility, an application can schedule accurately the use of data samples, and also can detect data underflow and overflow. To see how these things are done, here is some background.
A media stream can be seen as travelling a path. An input path comprises electrical signals on an input jack (an electrical connection) being converted by a device to digital data that is placed in an input buffer for use by an application. An output path goes from the application to an output jack via an output buffer. As implied by this description, the data placed in a buffer by the device (input path) or application (output path) has the highest MSC, and the data taken out by the application or device, respectively, has the lowest.
There are two kinds of MSCs, device and frontier. The device MSC is the basis for the other. An input device assigns a device MSC to a sample about to be placed in the input buffer. An output device assigns one to a sample about to be removed from the output buffer. The MSC of the sample at the application's end of a buffer is the frontier MSC. It is calculated based on the device MSC. In an input path, the frontier MSC is equal to the device MSC minus the number of samples waiting in the input buffer. In an output path, the frontier MSC equals the device MSC plus the number of waiting output buffer samples.
What does using MSCs enable your application to do? Assuming the data stream going to the buffer is not underflowing or overflowing, your application can precisely control the sample flow by using MSCs to determine corresponding USTs. Your application can synchronize data streams, such an audio stream and a video stream, by matching the USTs of their samples. Also, it can compensate for IRIX™ scheduling interruptions by using the USTs of the samples for controlling the contents of the buffer.
As shown in this Video Library code sample, you can determine the time (UST) a media stream sample came in from or went out to a jack by using the functions vlGetFrontierMSC() and vlGetUSTMSCPair().
double ust_per_msc; USTMSCpair pair; stamp_t frontier_msc, desired_ust; int err; ust_per_msc = vlGetUSTPerMSC(server, path); err = vlGetUSTMSCPair(server, path, video_node, &pair); frontier_msc = vlGetFrontierMSC(server, path, memNode); desired_ust = pair.ust + ((frontier_msc - pair.msc) * ust_per_msc); |
This sample works for both input and output paths. In either case, the sample indicated by desired_ust is the one with the frontier MSC. Thus for an input path, desired_ust is the UST of the next sample to be taken from the buffer by your application. For an output path, it is the UST of the next sample your application will place in the buffer. The USTs of other samples in the buffer can be found by adjusting the calculation on the last line.
These techniques assume that there is no data underflow or overflow to the buffer. If there is an underflow or overflow condition, calculations like these become unreliable. This is because the frontier MSC is based on the current device MSC. It is not a constant value attached to a specific data sample. For example, consider an overflow condition in an input path. The device MSC, and thus the frontier MSC, is increased by one every time the device is ready to place a sample in the input buffer. Because the buffer is full, the sample is discarded, but the MSCs retain their new values. Therefore, the UST/MSC pair associated with a given sample has changed and calculations like the one in the earlier code sample are no longer reliable.
This situation also demonstrates one of the advantages of the UST/MSC pairing. The design enables your application to determine buffer overflow or underflow immediately, based on the value of the frontier MSC. In the above example, your application can check for data overflow immediately after putting data samples into the buffer by checking if the difference between the current frontier MSC and the previous frontier MSC is greater than the number of samples just queued. If it is greater, there is an overflow condition. The size of the discrepancy is the actual magnitude of the overflow because putting the samples into the buffer relieved the overflow. Your application can make analogous determinations for input underflow, and output overflow and underflow. Notice that the overflow condition can be found without waiting for the samples with the discontinuous data to get to the front of the buffer. This allows your application to take corrective action immediately.
Table 2-7. Methods for Using UST/MSC
Function | Description |
|---|---|
vlGetFrontierMSC() | Get the frontier MSC associated with a particular node. See also vlGetFrontierMSC(3dm) and ALgetframenumber(3dm). |
vlGetUSTMSCPair() | Get the time at which a field or frame came in or will go out. See also vlGetUSTMSCPair(3dm) and ALgetframetime(3dm). |
vlGetUSTPerMSC() | Get the time interval between fields or frames in a path. See also vlGetUSTPerMSC(3dm). |
The VL presents field numbers to a VL application in two contexts:
For video-to-memory or memory-to-video paths whose VL_CAP_TYPE is set to VL_CAPTURE_NONINTERLEAVED (fields separate, each in its own buffer), the functions vlGetFrontierMSC() and vlGetUSTMSCPair() return MSCs that count fields (in other VL_CAP_TYPEs, the returned MSCs do not count fields).
For any video-to-memory path, the user can use vlGetDMediaInfo() to return the DMediaInfo structure contained in an entry in a VLBuffer. This structure contains a member called sequence, which always counts fields (regardless of VL_CAP_TYPE).
In both of these cases, there should be the following correlation:
These values should be 0%2 if they represent an F1 field
These values should be 1%2 if they represent an F2 field
This is a relatively new convention and is not yet implemented on all devices.
Currently, the Digital Media Libraries support the following file formats:
Raw audio data
AIFF/AIFC
Microsoft Waveform Audio Format WAVE (RIFF)
NeXT® .snd
Sun® .au
Berkeley IRCAM/CARL (BICSF)
Digidesign Sound Designer II™
Raw MPEG1 audio bitstream
Audio Visual Research AVR™
Amiga® IFF 8SVX™
Creative Labs VOC
Sample Vision
E-mu Systems® SoundFont2®
In addition, the Digital Media Libraries recognize but do not support
Sound Designer I
NIST Sphere
A movie is a collection of digital media data contained in tracks, temporally organized in a storage medium, which is captured from and played to audio and video devices. Saying that movies are composed of time-based data means that each piece of data is associated (and usually timestamped) with a particular instant in time, and has a certain duration in time. Movies can contain multiple tracks of different media.
Movies are generally stored in a file format that contains both a descriptive header and the movie data. When a movie is opened, only the header information exists in memory. A movie also has properties or attributes independent of the file format and may not necessarily be stored in a file.
Parameters in dmedia/dm_image.h and dmedia/dm_audio.h provide a common language for specifying movie data attributes. The Movie Library also provides its own parameters in libmovie/movifile.h.
The Movie Library currently supports these file formats:
QuickTime
MPEG-1 systems and video bitstreams
Silicon Graphics movie format