You can achieve higher frame rates by processing image data on multi-CPU platforms. Each stage of the graphics pipeline process can then run as a separate process on a separate CPU. Each pipeline can handle up to five processes. Although you can construct the processes as you like, the recommended processes include three synchronous processes:
APP—for updating node values.
CULL—for eliminating from rendering calculations any nodes outside of the view frustum.
DRAW—for rendering shapes.
The three recommended asynchronous processes include:
ISECT—for intersection calculations.
DBASE—for paging image data into system memory.
COMPUTE—for general, asynchronous computations.
This chapter describes how to use multiprocessing in the following sections:
The APP, CULL, and DRAW stages comprise the required stages of the graphic pipeline. There can be only one APP process for an application. There are, however, separate pairs of CULL and DRAW stages for each pfPipe, as shown in Figure 11-1.
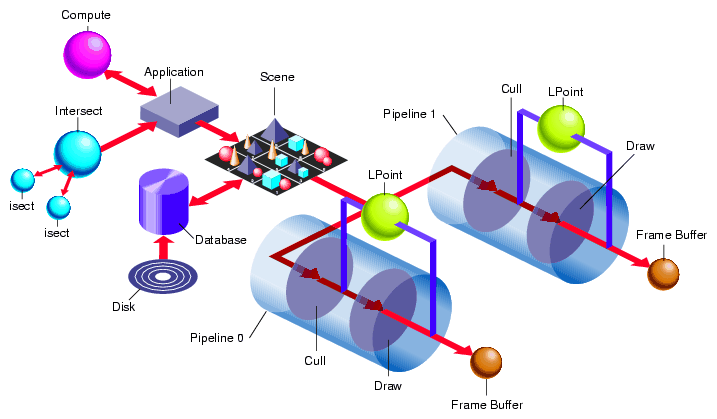
You can change the default behavior of the DRAW and CULL stages using callback functions.
If you do not fork off separate processes for intersection testing (ISECT), I/O (DBASE), or miscellaneous calculations (COMPUTE), the calculations are performed in the APP stage and will be performed serially.
Each of the asynchronous stages perform computationally intense calculations in parallel with the required stages to improve the overall speed of image processing.
The ISECT stage calculates intersection-related information. To do that calculation, it keeps a copy of the scene graph. Consequently, this stage can use a significant amount of memory, depending on the size of the scene graph.
For more information about intersection testing, see Chapter 13, “Intersection Testing”.
The DBASE stage deals with I/O issues of downloading scene graph data from the hard drive to system memory. This stage is lightweight because it does not keep a copy of the scene graph.
For more information about the DBASE process, see Chapter 12, “Database Paging”.
The COMPUTE stage is provided for general calculations. It does not contain a copy of the database, but it does contain general statistics and the number of the frame that is being processed.
When you fork off this process, pfASD is computed in this stage as is pfFlux, in addition to any calculations you place in this stage.
Multiprocessing enables parallel processing of image data in the graphics pipeline. If each of the three stages in the graphics pipeline, (APP, CULL, and DRAW) run sequentially, and each take 16 milliseconds, each frame would require 48 milliseconds for processing. If, however, each stage is processed in parallel, the processing time for a single frame is reduced to 16 milliseconds, as shown in Figure 11-2.
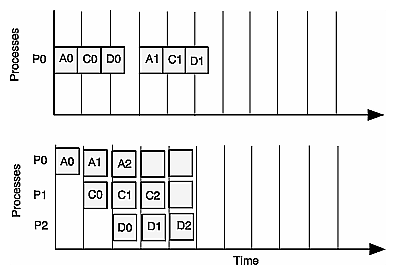
Figure 11-2 shows that three tasks running sequentially (in the upper figure) require three times the processing time of the three tasks running in parallel (in the lower figure), each in their own process.
The shorter processing time dramatically affects the frame rate at which the application can display its images.
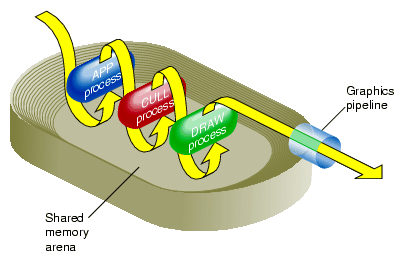
The shared memory arena contains a copy of the frame's data that is used by each process, in the following way:
After the APP process updates the frame, the process places a copy of unique data for the frame in the shared memory arena.
The CULL process takes the frame from the shared memory arena, culls out data invisible to the viewer, and places a revised copy of the frame back in the shared arena memory in the form of a libpr display list for that frame.
The DRAW process uses the updated frame and renders the scene to the display system.
Figure 11-3 shows how the shared memory arena is used by the different stages.
pfPrintProcessState() prints a description of OpenGL Performer processes to a file. The following shows a sample printout:
Proc: APP pid:11895
Proc: ISECT pid:11895
Proc: DBASE pid:11895
Proc: CLOCK pid:11896
Proc: COMPUTE pid:11895
Proc: SYNC pid:0
Pipe Proc: CULL Pipes:1
Thread Proc: CULL Pipe:0 Threads:0
Parent:Proc: CULL Pipe:0 pid:0
Pipe Proc: DRAW Pipes:1
Proc: DRAW Pipe:0 pid:0
Pipe Proc: LPOINT Pipes:1
Thread Proc: LPOINT Pipe:0 Threads:0
Parent:Proc: LPOINT Pipe:0 pid:0
|
OpenGL Performer simplifies setting up multiple processes by supplying the tokens shown in Table 11-1 for the following pfConfig method:
int pfMultiprocess(int mode); |
mode is one or more multiprocessing models ORed together. Table 11-1 lists the tokens to use for mode. These processing models are set at creation time and cannot be altered at run time.
You call pfMultiprocess between pfInit and pfConfig.
Table 11-1 lists the multiprocessing models available in OpenGL Performer.
Table 11-1. Multiprocessing Tokens
Token | Description |
|---|---|
PFMP_DEFAULT | Chooses a multiprocessing mode based on the number of pipelines required and the number of unrestricted, available processors. |
PFMP_FORK_ISECT | Fork an asynchronous ISECT process. |
PFMP_FORK_CULL | Place CULL in a separate process. |
PFMP_FORK_DRAW | Place DRAW in a separate process. |
PFMP_FORK_DBASE | Fork an asynchronous DBASE process. |
FMP_FORK_COMPUTE | Fork an asynchronous COMPUTE process. |
PFMP_CULLoDRAW | Overlap CULL and DRAW processes. |
PFMP_CULL_DL_DRAW | Force CULL to generate display list. |
PFMP_APPCULLDRAW | All stages are combined into a single process. A pfDispList is not used. pfDraw both culls and renders the scene. |
PFMP_APPCULL_DL_DRAW | All stages are combined into a single process. A pfDispList is built by pfCull and rendered by pfDraw. |
PFMP_APP_CULLDRAW | The CULL and DRAW stages are combined in a process that is separate from the application process. A pfDispList is not used. pfDraw both culls and renders the scene. Equivalent to (PFMP_FORK_CULL). |
PFMP_APP_CULL_DL_DRAW | The CULL and DRAW stages are combined in a process that is separate from the application process. A pfDispList is built by pfCull and rendered by pfDraw. Equivalent to (PFMP_FORK_CULL | PFMP_CULL_DL_DRAW). |
PFMP_APPCULLoDRAW | The APP and CULL stages are combined in a process that is separate from, but overlaps, the DRAW process. Equivalent to (PFMP_FORK_DRAW | PFMP_CULLoDRAW). |
PFMP_APP_CULL_DRAW | The APP, CULL, and DRAW stages are each separate processes. Equivalent to (PFMP_FORK_CULL | PFMP_FORK_DRAW). |
PFMP_APP_CULLoDRAW | The APP, CULL, and DRAW stages are each separate processes and the CULL and DRAW process are overlapped. Equivalent to (PFMP_FORK_CULL | PFMP_FORK_DRAW | PFMP_CULLoDRAW). |
PFMP_FORK_LPOINT | Fork a light process, pfLPointState. |
The “o” in PFMP_CULLoDRAW stands for “overlap.” The CULL and DRAW processes can overlap when they are separate. Figure 11-4 shows that the DRAW process acts on the first frame one screen refresh earlier in the PFMP_CULLoDRAW model than in the PFMP_APP_CULL_DRAW model.
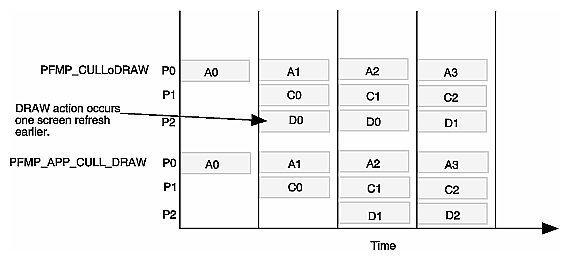
Figure 11-5 shows four common multiprocessing models.
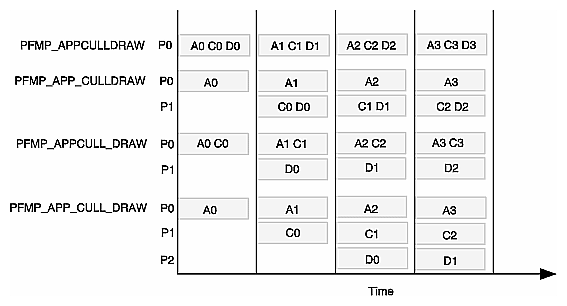
| Tip: In two-processor mode, fork off the stage that consumes the most time. |
The default multiprocessing model set up by PFMP_DEFAULT depends on the following:
Number of pfPipes
Number of unrestricted CPUs
If there is one pfPipe in the system, the default multiprocessing model depends upon the number of unrestricted CPUs, as described in Table 11-2.
Table 11-2. Default Multiprocessing Models
Number of CPUs | Default Multiprocessing Model |
|---|---|
1 | PFMP_APPCULLDRAW |
2 | PFMP_APPCULL_DRAW |
3 | PFMP_APP_CULL_DRAW |
An application only runs as fast as its slowest stage. To improve the performance of your application, you need to determine which stage acts as a bottleneck. Generally, of the three synchronous processes, the DRAW stage takes the most time. Place the stage that requires the longest time in its own process.
When you enable the Process Manager, pfuProcessManager, found in libpfutil, it automatically evaluates the number of processes and processors that you have and spreads the processes evenly over the processors. You enable pfuProcessManager with the routine pfuInitDefaultProcessManager().
| Note: pfuProcessManager obsoletes pfuLockCPU. |