Although I/O performance is one of the strengths of supercomputers, speeding up the I/O in a program is an often neglected area of optimization. A small optimization effort can often produce a surprisingly large gain.
The run-time I/O library contains low overhead, built-in instrumentation that can collect vital statistics on activities such as I/O. This run-time library, together with procstat(1) and other related commands, offers a powerful tool set that can analyze the program I/O without accessing the program source code.
A wide selection of optimization techniques are available through the flexible file I/O (FFIO) system. You can use the assign(1) command to invoke FFIO for these optimization techniques. This chapter stresses the use of assign and FFIO because these optimization techniques do not require program recompilation or relinking.
This chapter describes ways to identify code that can be optimized and the techniques that you can use to optimize the code.
I/O can be represented as a series of layers of data movement. Each layer involves some processing. Figure 12-1 shows typical output flow from the system to disk.
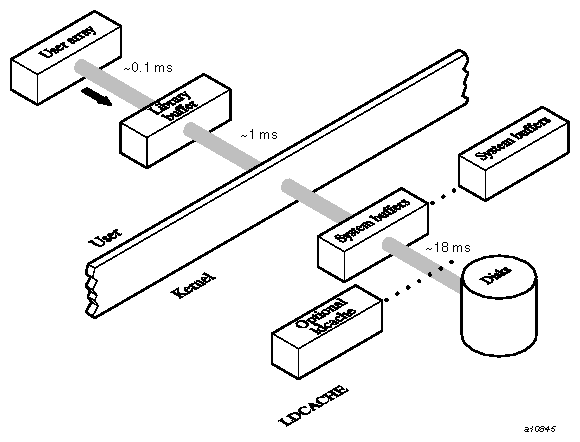
On output, data moves from the user space to a library buffer, where small chunks of data are collected into larger, more efficient chunks. When the library buffer is full, a system request is made and the kernel moves the data to a system buffer. From there, the data is sent through the I/O processor (IOP), perhaps through ldcache, to the device. On input, the path is reversed.
The times shown in Figure 12-1 may not be duplicated on your system because many variables exist that affect timing. These times do, however, give an indication of the times involved in each processing stage.
For optimization purposes, it is useful to differentiate between permanent files and temporary files. Permanent files are external files that must be retained after the program completes execution. Temporary files or scratch files are usually created and reused during the execution of the program, but they do not need to be retained at the end of the execution.
Permanent files must be stored on actual devices. Temporary files exist in memory and do not have to be written to a physical device. With temporary files, the strategy is to avoid using system calls (going to "lower layers" of I/O processing). If a temporary file is small enough to reside completely in memory, you can avoid using system calls.
Permanent files require system calls to the kernel; because of this, optimizing the I/O for permanent files is more complicated. I/O on permanent files may require the full complement of I/O layers. The goal of I/O optimization is to move data to and from the devices as quickly as possible. If that is not fast enough, you must find ways to overlap I/O with computation.
This section briefly describes the optimization techniques that are discussed in the remainder of this chapter.
The following types of optimization may improve I/O performance:
Specify the cache page size so that one or more records will fit on a cache page if the program is using unformatted direct access I/O (see “Using a Cache Layer”, for details).
Use file structures without record control information to bypass the overhead associated with records (see “Using Simpler File Structures”, for details).
Choose file processing with appropriate buffering strategies. The cos, bufa, and cachea FFIO layers implement asynchronous write-behind (see “Using Asynchronous Read-ahead and Write-behind”, for details). The cos and bufa FFIO layers implement asynchronous read-ahead; this is available for the cachea layer through use of an assign option.
Choose efficient library buffer sizes. Bypass the library buffers when possible by using the system or syscall layers (see “Changing Library Buffer Sizes”, for details).
Use the assign command to specify scratch files to prevent writes to disk and to delete the files when they are closed (see “Scratch Files”, for details).
“Enhancing Performance” in Chapter 10, also provides further information about using FFIO to enhance I/O performance.
The following source program changes may affect the I/O performance of a Fortran program:
Use unformatted I/O when possible to bypass conversion of data.
Use whole array references in I/O lists where possible. The generated code passes the entire array to the I/O library as the I/O list item rather than pass it through several calls to the I/O library.
Use special packages such as buffer I/O, random-access I/O, and asynchronous queued I/O.
Overlap CPU time and I/O time by using asynchronous I/O.
I/O optimization can often be accomplished by simply addressing I/O speed. The following storage systems are available, ranked in order of speed:
CPU main memory
Magnetic disk drives
Optional magnetic tape drives
Fast storage systems are expensive and have smaller capacities. You can specify a fast device through FFIO layers and use several FFIO layers to gain the maximum performance benefit from each storage medium. The remainder of this chapter discusses many of these FFIO optimizations. These easy optimizations are frequently those that yield the highest payoffs.
In a busy interactive environment, queuing for service is time consuming. In tuning I/O, the first step is to reduce the number of physical delays and the queuing that results by reducing the number of system requests, especially the number of system requests that require physical device activity.
System requests are made by the library to the kernel. They request data to be moved between I/O devices. Physical device activity consumes the most time of all I/O activities.
Typical requests are read, write, and seek. These requests may require physical device I/O. During physical device I/O, time is spent in the following activities:
Transferring data between disk and memory.
Waiting for physical operations to complete. For example, moving a disk head to the cylinder (seek time) and then waiting for the right 4096-byte block to come under the disk head (latency time).
System requests can require substantial CPU time to complete. The system may suspend the requesting job until a relatively slow device completes a service.
Besides the time required to perform a request, the potential for congestion also exists. The system waits for competing requests for kernel, disk, IOP, or channel services. System calls to the kernel can slow I/O by one or two orders of magnitude.
The information in this section summarizes some ways you can optimize system requests.
The FFIO cache layer keeps recently used data in fixed size main memory or cache pages in order to reuse the data directly from these buffers in subsequent references. It can be tuned by selecting the number of cache pages and the size of these pages.
The use of the cache layer is especially effective when access to a file is localized to some regions of the whole file. Well-tuned cached I/O can be an order of magnitude faster than the default I/O.
Even when access is sequential, the cache layer can improve the I/O performance. For good performance, use page sizes large enough to hold the largest records.
The cache layers work with the standard Fortran I/O types and the compiler extensions of BUFFER IN/OUT, READMS/WRITMS, and GETWA/PUTWA.
The following assign command requests 100 pages of 42 blocks each:
assign -F cache:42:100 f:filename |
Specifying cache pages of 42 blocks matches the track size of a DD-49 disk.
The Fortran standard uses the record concept to govern I/O. It allows you to skip to the next record after reading only part of a record, and you can backspace to a previous record. The I/O library implements Fortran records by maintaining an internal record structure.
In the case of a sequential unformatted file, it uses a COS blocked file structure, which contains control information that helps to delimit records. The I/O library inserts this control information on write operations and removes the information on read operations. This process is known as record translation, and it consumes time.
If the I/O performed on a file does not require this file structure, you can avoid using the blocked structure and record translation. However, if you must do positioning in the file, you cannot avoid using the blocked structure.
The information in this section describes ways to optimize your file structure overhead.
Scratch files are temporary and are deleted when they are closed. To decrease I/O time, move applications' scratch files from user file systems to high-speed file systems.
When optimizing, you should avoid writing the data to disk. This is especially important if most of the data can be held in main memory.
Fortran lets you open a file with STATUS='SCRATCH'. It also lets you close temporary files by using a STATUS='DELETE' . These files are placed on disk, unless the .scr specification for FFIO or the assign -t command is specified for the file. Files specified as assign -t or .scr are deleted when they are closed.
Several FFIO layers automatically enhance I/O performance by performing asynchronous read-ahead and write-behind. These layers include:
cos: default Fortran sequential unformatted file. Specified by assign -F cos.
bufa: specified by assign -F bufa .
cachea: default Fortran direct unformatted files. Specified by assign -F cachea. Default cachea behavior provides asynchronous write-behind. Asynchronous read-ahead is not enabled by default, but is available by an assign option.
If records are accessed sequentially, the cos and bufa layers will automatically and asynchronously pre-read data ahead of the file position currently being accessed. This behavior can be obtained with the cachea layer with an assign option; in that case, the cachea layer will also detect sequential backward access patterns and pre-read in the reverse direction.
Many user codes access the majority of file records sequentially, even with ACCESS='DIRECT' specified. Asynchronous buffering provides maximum performance when:
Access is mainly sequential, but the working area of the file cannot fit in a buffer or is not reused frequently.
Significant CPU-intensive processing can be overlapped with the asynchronous I/O.
Use of automatic read-ahead and write-behind may decrease execution time by half because I/O and CPU processing occur in parallel.
The following assign command specifies a specific cachea layer with 10 pages, each the size of a DD-40 track. Three pages of asynchronous read-ahead are requested. The read-ahead is performed when a sequential read access pattern is detected.
assign -F cachea:48:10:3 f:filename |
This command would work for a direct access or sequential Fortran file which has unblocked file structure.
Marking records incurs overhead. If a program reads all of the data in any record it accesses and avoids the use of BACKSPACE, you can make some minor performance savings by eliminating the overhead associated with records. This can be done in several ways, depending on the type of I/O and certain other characteristics.
For example, the following assign statements specify the unblocked file structure:
assign -s unblocked f:filename assign -s u f:filename assign -s bin f:filename |
When possible, avoid formatted I/O. Unformatted I/O is faster, and it avoids potential inaccuracies due to conversion. Formatted Fortran I/O requires that the library interpret the FORMAT statement and then convert the data from an internal representation to ASCII characters. Because this must be done for every item generated, it can be very time-consuming for large amounts of data.
Whenever possible, use unformatted I/O to avoid this overhead. Do not use edit-directed I/O on scratch files. Major performance gains are possible.
You can explicitly request data conversions during I/O. The most common conversion is through Fortran edit-directed I/O. I/O statements using a FORMAT statement, list-directed I/O, and namelist I/O require data conversions.
Conversion between internal representation and ASCII characters is time-consuming because it must be performed for each data item. When present, the FORMAT statement must be parsed or interpreted. For example, it is very slow to convert a decimal representation of a floating-point number specified by an E edit descriptor to an internal binary representation of that number.
For more information about data conversions, see Chapter 11, “Foreign File Conversion”.
The Fortran I/O libraries usually use main memory buffers to hold data that will be written to disk or was read from disk. The library tries to do I/O efficiently on a few large requests rather than in many small requests. This process is called buffering.
Overhead is incurred and time is spent whenever data is copied from one place to another. This happens when data is moved from user space to a library buffer and when data is moved between buffers. Minimizing buffer movement can help improve I/O performance.
The libraries generally have default buffer sizes. The default is suitable for many devices, but major performance improvements can result from requesting an efficient buffer size.
The optimal buffer size for very large files is usually a multiple of a device allocation for the disk. This may be the size of a track on the disk. If optimal size buffers are used and the file is contiguous, disk operations are very efficient. Smaller sizes require more than one operation to access all of the information on the allocation or track. Performance does not improve much with buffers larger than the optimal size, unless striping is specified.
When enough main memory is available to hold the entire file, the buffer size can be selected to be as large as the file for maximum performance.
The maximum length of a formatted record depends on the size of the buffer that the I/O library uses for a file. The size of the buffer depends on the following:
hardware system and OS level
Type of file (external or internal)
Type of access (sequential or direct)
Type of formatted I/O (edit-directed, list-directed, or namelist)
After a request is made, the library usually copies data between its own buffers and the user data area. For small requests, this may result in the blocking of many requests into fewer system requests, but for large requests when blocking is not needed, this is inefficient. You can achieve performance gains by bypassing the library buffers and making system requests to the user data directly.
To bypass the library buffers and to specify a direct system interface, use the assign -s u option or specify the FFIO system, or syscall layer, as is shown in the following assign command examples:
assign -s u f:filename assign -F system f:filename assign -F syscall f:filename |
The user data should be in multiples of the disk sector size (usually 4096 bytes) for best disk I/O performance.
If library buffers are bypassed, the user data should be on a 4096-byte boundary to prevent I/O performance degradation.
There are other optimizations that involve changing your program. The following sections describe these optimization techniques.
When a program produces a large amount of output used only as input to another program consider using pipes. If both programs can run simultaneously, data can flow directly from one to the next by using a pipe. It is unnecessary to write the data to the disk. See Chapter 4, “Named Pipe Support ”, for details about pipes.
Major performance improvements can result from overlapping CPU work and I/O work. This approach can be used in many high-volume applications; it simultaneously uses as many independent devices as possible.
To use this method, start some I/O operations and then immediately begin computational work without waiting for the I/O operations to complete. When the computational work completes, check on the I/O operations; if they are not completed yet, you must wait. To repeat this cycle, start more I/O and begin more computations.
As an example, assume that you must compute a large matrix. Instead of computing the entire matrix and then writing it out, a better approach is to compute one column at a time and to initiate the output of each column immediately after the column is computed. An example of this follows:
dimension a(1000,2000)
do 20 jcol= 1,2000
do 10 i= 1,1000
a(i,jcol)= sqrt(exp(ranf()))
10 continue
20 continue
write(1) a
end |
First, try using the assign -F cos.async f:filename command. If this is not fast enough, rewrite the previous program to overlap I/O with CPU work, as follows:
dimension a(1000,2000)
do 20 jcol= 1,2000
do 10 i= 1,1000
a(i,jcol)= sqrt(exp(ranf()))
10 continue
BUFFER OUT(1,0) (a(1,jcol),a(1000,jcol) )
20 continue
end |
The following Fortran statements and library routines can return control to the user after initiating I/O without requiring the I/O to complete:
BUFFER IN and BUFFER OUT statements (buffer I/O)
FFIO cos blocking asynchronous layer (available on IRIX systems)
FFIO cachea layer (available on IRIX systems)
FFIO bufa layer (available on IRIX systems)