Profiling reveals which code to tune. The most important tool for tuning is the compiler. Ideally, the compiler should convert your program to the fastest possible code automatically. But this isn't possible because the compiler does not have enough information to make optimal decisions.
As an example, if one loop iterates many times, it will run fastest if the compiler unrolls the loop and performs software pipelining on the unrolled code. However, if the loop iterates only a few times, the time spent in the elaborate housekeeping code generated by pipelining is never recovered, and the loop actually runs more slowly. With some Fortran DO loops and most C loops, the compiler cannot tell how many times a loop will iterate. What should it do? The answer, of course, is that you have to direct the compiler to apply the right optimizations. To do that, you need to understand the types of optimizations the compiler can make, and the command-line options (“compiler flags”) that enable or disable them. These are described in this chapter, in the following sections:
“Understanding Compiler Options” lists the compiler options, or flags, that should be used initially, and discusses the use of a Makefile.
“Exploiting Software Pipelining” describes the uses and control of this important optimization.
“Informing the Compiler” describes the use of compiler flags, pragmas, and coding techniques to give the compiler more information so that it can better optimize and pipeline loops.
“Exploiting Interprocedural Analysis” discusses the concepts and use of IPA and inlining.
The discussion of single-process tuning continues in Chapter 6, “Optimizing Cache Utilization”, covering the closely-related topics of loop nest optimization and memory access.
The SGI compilers are flexible and offer a wide variety of compiler options to control their operation. The options are documented in a multiple set of man pages, as well as in the compiler manuals listed in “Compiler Manuals”.
Because the optimizations the compilers can perform interact with each other, and because no two programs are alike, it is impossible to specify a fixed set of options that give the best results in all cases. Nevertheless, the following is a good set of compiler flags to start with:
-n32 -mips4 -O2 -OPT:IEEE_arithmetic=3 -lfastm -lm |
The meaning of these options is as follows:
-n32 | Use the new 32-bit ABI. Use -64 only when the program needs more than 2 GB of virtual address space. Always use the -64 option when MPI library routines are called. |
-mips4 | Compile code for the R10000 CPU. |
-O2 | Request the best set of conservative optimizations; that is, those that do not reorder statements and expressions. |
-OPT:IEEE_arithmetic=3 | Permit optimizations that favor speed over preserving precise numerical rounding rules. If the program proves numerically unstable or inaccurate use -OPT:IEEE_arithmetic=2 instead. |
-lfastm -lm | Link math routines from the optimized math library; take any remaining math routines from the standard library. |
The -n32 and -mips4 options are discussed in “Selecting an ABI and ISA” in Chapter 3; the library choice under “libfastm Library” in Chapter 3. The others are discussed in the topics in this chapter.
Using this set of flags for all modules of a large program suite may produce acceptable performance. If so, tuning is complete. Otherwise, the performance-critical modules will require compilation with higher levels of optimization than -O2. These levels are discussed under “Setting Optimization Level with -On”.
The compilers have many options that are specified in the conventional UNIX fashion, as a hyphen followed by a word. For example, optimization level -O2; ABI level -n32; separate compilation of a module -c; request assembler source file -S. These options are all documented in the compiler man pages cc(1) , f77(1) , f90(1) . (You will find that it is useful to keep a printed copy of your compiler's man page near your keyboard.)
The compilers categorize other options into groups. These groups of options are documented in separate man pages. The option groups are listed in Table 5-1.
Table 5-1. Compiler Option Groups
Group Heading | Reference Page | Use |
|---|---|---|
-LIST, -CLIST, -FLIST | cc(1), f77(1), f90(1) | Listing controls. |
-DEBUG | debug_group(5) | Options for debugging and error-trapping. |
-INLINE | ipa(5) | Options related to the standalone inliner. |
-IPA | ipa(5) | Options related to interprocedural analysis. |
-LANG | cc(1), f77(1), f90(1) | Language compatibility selections. |
-LNO | lno(5) | Options related to the loop-nest optimizer. |
-MP | cc(1), f77(1), f90(1) | Options related to multiprocessing. |
-OPT | opt(5) | Specific controls of the global optimizer. |
-TARG, -TENV | cc(1), f77(1), f90(1) | Specify target execution environment features. |
The syntax for an option within a group is:
-group:option[=value][:option[=value]]... |
You can specify a group heading more than once; the effects are cumulative. For example,
cc -CLIST:linelength=120:show=ON -TARG:platform=ip27 -TARG:isa=mips4 |
Many of the grouped options are documented in this and the following chapters. All compiler options mentioned are in the index under the heading “compiler option.”
The compiler has defaults for all options, but often they are not what you might expect. For example, the compiler optimizes the generated code for a particular hardware type as specified with the -TARG option group (detailed later in “Setting Target System with -TARG”). The default for the target hardware is not, as you might expect, the system on which the compiler runs, but the Power Challenge R10000—as of release 7.2.1. The default might change in a later release.
You can alter the compiler's choice of defaults for some, but not all, options by changing the file /etc/compiler.defaults, as documented in the MIPSpro Compiling and Performance Tuning Guide and the cc(1) documents listed in “Related Documents”. However, this changes the defaults for all compilations by all users on that system.
Because at least some defaults are in the control of the administrator of the system, you cannot be certain of the compiler's defaults on any given system. As a result, the only way to be certain of consistent results is to specify all important compiler options on every compile. The only convenient way of doing this is with a Makefile.
You want to use the many compiler options consistently, regardless of which computer you use to run the compilation; also, you want to experiment with alternative options in a controlled way. The best way to avoid confusion and to get consistent results is to use a Makefile in which you define all important compiler options as variables. Example C-4 shows a starting point for a Makefile.
For a straightforward program, a Makefile like the one in Example C-4 may be all you need. To use it, create a directory for your program and move the source files into the directory. Create a file named Makefile containing the lines of Example C-4. Edit the file and fill in the lines that define EXEC (the program name) and FOBJS and COBJS, the names of the component object files.
To build the program, enter
% make |
The make program compiles the source modules into object modules using the compiler flags specified in the variables defined in the first few lines, then links the executable program.
To remove the executable and objects, so as to force recompilation of all files, use
% make clean |
You can override the Makefile setting of any of the variables by specifying its value on the command line. For example, if the OLEVEL variable does not permit debugging (-Ofast=ip27 does not), you can compile a debugging version with the following commands:
% make clean; make OLEVEL="-O0 -g3" |
You can add extra compilation options with the DEFINES variable. For example,
% make DEFINES="-DDEBUG -OPT:alias=restrict" |
The basic optimization flag is -On, where n is 0, 1, 2, 3, or fast. This flag controls which optimizations the compiler will attempt: the higher the optimization level, the more aggressive the optimizations that will be tried. In general, the higher the optimization level, the longer compilation takes.
A good beginning point for program tuning is optimization level -O2 (or, equivalently, -O). This level performs extensive optimizations that are conservative; that is, they will not cause the program to have numeric roundoff characteristics different from an unoptimized program. Sophisticated (and time-consuming) optimizations such as software pipelining and loop nest optimizations are not performed.
In addition, the compiler does not rearrange the sequence of code very much at this level. At higher levels, the compiler can rearrange code enough that the correspondence between a source line and the generated code becomes hazy. If you profile a program compiled at the -O2 level, you can make use of a prof -heavy report (see “Including Line-Level Detail” in Chapter 4). When you compile at higher levels, it can be difficult to interpret a profile because of code motion and inlining.
Use the -O2 version of your program as the baseline for performance. For some programs, this may be the fastest version. The higher optimization levels have their greatest effects on loop-intensive code and math-intensive code. They may bring little or no improvement to programs that are strongly oriented to integer logic and file I/O.
You should identify the program modules that consume a significant fraction of the program's run time and compile them with the highest level of optimization. This may be specified with either -O3 or -Ofast. Both flags enable software pipelining and loop nest optimizations. The difference between the two is that -Ofast includes additional optimizations:
Interprocedural analysis (discussed later under “Exploiting Interprocedural Analysis”).
Arithmetic rearrangements that can cause numeric roundoff to be different from an unoptimized program (this can be controlled separately, see “Understanding Arithmetic Standards”).
Assumption that certain pointer variables are independent, not aliased (also controlled separately; see “Understanding Aliasing Models”).
With no argument, -Ofast assumes the default target for execution (see “Compiler Defaults”). You can specify which machine will run the generated code by naming the “ip” number of the CPU board. The complete list of valid board numbers is given in the cc(1) man page. The ip number of any system is displayed by the command hinv -c processor.For all SN0 systems, use -Ofast=ip27.
Use the lowest optimization level, -O0, when debugging your program. This flag turns off all optimizations, so there is a direct correspondence between the original source code and the machine instructions the compiler generates.
You can run a program compiled to higher levels of optimization under a symbolic debugger, but the debugger will have trouble showing you the program's progress statement by statement, because the compiler often merges statements and moves code around. An optimized program, under a debugger, can be made to stop on procedure entry, but cannot reliably be made to stop on a specified statement.
-O0 is the default when you don't specify an optimization level, so be sure to specify the optimization level you want.
Although the R10000, R8000, and R5000 CPUs all support the MIPS IV ISA (see “Selecting an ABI and ISA” in Chapter 3), their internal hardware implementations are quite different.
The compiler does not simply choose the machine instructions to be executed, which would be the same for any MIPS IV CPU. It carefully schedules the sequence of instructions so that the CPU will make best use of its parallel functional units. The ideal sequence is different for each of the CPUs that support MIPS IV. Code scheduled for one chip runs correctly, but not necessarily in optimal time, on another.
You can instruct the compiler to generate code optimized for a particular chip by using the CPU-type flags on the compiler's command line. These flags, when used while linking, cause libraries optimized for the specified chip, if available, to be linked. Specially optimized versions of libfastm exist for some CPUs (see the libfastm man page).
You can also specify the target chip using an alternative flag, -TARG:processor=N. This flag tells the compiler to generate code optimized for the specified chip. However, the flag is ignored at link time, so it does not affect which libraries are linked. If -r10000 has been used, -TARG:proc=r10000 is unnecessary.
In addition to specifying the target chip, you can also specify the target processor board. This gives the compiler information about hardware parameters such as cache sizes, which can be used in some optimizations. You can specify the target platform with the -TARG:platform=ipxx flag. For SN0, use -TARG:platform=ip27.
The -Ofast=ip27 flag implies the flags -r10000, -TARG:proc=r10000, and -TARG:platform=ip27.
For some applications, control of numeric error is paramount, and the programmer devotes great care to ordering arithmetic operations so that the finite precision of computer registers will not introduce and propagate errors. The IEEE 754 standard for floating-point arithmetic is conservatively designed to preserve accuracy, at the expense of speed if necessary, and conformance to it is a key element of a numerically-sensitive program—especially a program that must produce identical answers in different environments.
Many other programs and programmers are less concerned about preserving every bit of precision and more interested in getting answers that are in adequate agreement, as fast as possible. Two compiler options control these issues.
The nuances of mathematical accuracy are discussed in depth in the math(3) man page. The compiler options discussed in this section are detailed in the opt(5) man page.
The -OPT:IEEE_arithmetic option controls how strictly the generated code adheres to the IEEE 754 standard for floating-point arithmetic. The flexibility exists for a couple of reasons:
The MIPS IV ISA defines hardware instructions (such as reciprocal and reciprocal square root) that do not meet the accuracy specified by IEEE 754 standard. Although the inaccuracy is small (no more than two units in the last place, or 2 ulp), a program that uses these instructions is not strictly IEEE-compliant, and might generate a result that is different from a compliant program.
Some standard optimization techniques also produce different results from those of a strictly IEEE-compliant implementation.
For example, a standard optimization would be to lift the constant expression out of the following loop:
do i = 1, n b(i) = a(i)/c enddo |
This results in an optimized loop as follows:
tmp = 1.0/c do i = 1, n b(i) = a(i)*tmp enddo |
This is not allowed by the IEEE standard, because multiplying by the reciprocal (even a completely IEEE-accurate representation of the reciprocal) in place of division can produce results that differ in the least significant place.
You use the compiler flag -OPT:IEEE_arithmetic=n to tell the compiler how to handle these cases. The flag is documented (along with some other IEEE-related options) in the opt(5) man page. Briefly, the three allowed values of n mean:
n: | Description: |
1 | Full compliance with the standard. Use only when full compliance is essential. |
2 | Permits use of the slightly-inexact MIPS IV hardware instructions. |
3 | Permits the compiler to use any identity that is algebraically valid, including rearranging expressions. |
Unless you know that numerical accuracy is a priority for your program, start with level 3. If numerical instability seems to be a problem, change to level 2, so that the compiler will not rearrange your expressions. Use level 1 only when IEEE compliance is a priority.
A related flag is -OPT:IEEE_NaN_inf. When this flag specified as OFF, which it is by default, the compiler is allowed to make certain assumptions that the IEEE standard forbids, for example, assuming that x/x is 1.0 without performing the division.
The order in which arithmetic operations are coded into a program dictates the order in which they are carried out. The Fortran code in Example 5-1 specifies that the variable sum is calculated by first adding a(1) to sum, and to that result is added a(2), and so on until a(n) has been added in.
In most cases, including Example 5-1, the programmed sequence of operations is not necessary to produce a numerically valid result. Insisting on the programmed sequence can keep the compiler from taking advantage of the hardware resources.
For example, suppose the target CPU has a pipelined floating point add unit with a two-cycle latency. When the compiler can rearrange the code, it can unroll the loop, as shown in Example 5-2.
Example 5-2. Unrolled Summation Loop
sum1 = 0.0 sum2 = 0.0 do i = 1, n-1, 2 sum1 = sum1 + a(i) sum2 = sum2 + a(i+1) enddo do j= i, n sum1 = sum1 + a(j) enddo sum = sum1 + sum2 |
The compiler unrolls the loop to put two additions in each iteration. This reduces the index-increment overhead by half, and also supplies floating-point adds in pairs so as to keep the CPU's two-stage adder busy on every cycle. (The final wind-down loop finishes the summation when n is odd.)
The final result in sum is algebraically identical to the result produced in Example 5-1. However, because of the finite nature of computer arithmetic, these two loops can produce answers that differ in the final bits—bits that should be considered roundoff error places in any case.
The -OPT:roundoff=n flag allows you to specify how strictly the compiler must adhere to such coding-order semantics. As with the -OPT:IEEE_arithmetic flag previously described, there are several levels that are detailed in man page opt(5) . Briefly, these levels are as follows:
n: | Description: |
0 | Requires strict compliance with programmed sequence, thereby inhibiting most loop optimizations. |
1 | Allows simple reordering within expressions. |
2 | Allows extensive reordering like the unrolled reduction loop in Example 5-2. Default when -O3 is specified. |
3 | Allows any algebraically-valid transformation. Default when -Ofast is used. |
Start with level 3 in a program in which floating-point computations are incidental, otherwise with level 2.
Roundoff level three permits the compiler to transform expressions, and it also implies the use of inline machine instructions for float-to-integer conversion (separately controlled with the -OPT:fast_nint=on and -OPT:fast_trunc=on).These transformations can cause the roundoff characteristic of a program to change. For most programs, small differences in roundoff are not a problem, but in some instances the program's results can be different enough from what it produced previously to be considered wrong. That event might call into question the numeric stability of the algorithm, but the easiest course of action may be to use a lower roundoff level in order to generate the expected results.
If you are using -Ofast and want to reduce the roundoff level, you will need to set the desired level explicitly:
% cc -n32 -mips4 -Ofast=ip27 -OPT:roundoff=2 ... |
Loops imply parallelism. This ranges from, at minimum, instruction-level parallelism up to parallelism sufficient to carry out different iterations of the loop on different CPUs. Multiprocessor parallelism will be dealt with later; this section concentrates on instruction-level parallelism.
Consider the loop in Example 5-3, which implements the vector operation conventionally called DAXPY.
This adds a vector multiplied by a scalar to a second vector, overwriting the second vector. Each iteration of the loop requires the following instructions:
Two loads (of x(i) and y(i))
One store (of y(i))
One multiply-add
Two address increments
One loop-end test
One branch
The superscalar architecture of the CPU can execute up to four instructions per cycle. These time-slots can be filled by any combination of the following:
One load or store operation
One ALU 1 instruction
One ALU 2 instruction
One floating-point add
One floating-point multiply
In addition, most instructions are pipelined, and have associated pipeline latencies ranging from one cycle to dozens. Software pipelining is a compiler technique for optimally filling the superscalar time slots. The compiler figures out how best to schedule the instructions to fill up as many superscalar slots as possible, in order to run the loop at top speed.
In software pipelining, each loop iteration is broken up into instructions, as was done in the preceding examples for DAXPY. The iterations are then overlapped in time in an attempt to keep all the functional units busy. Of course, this is not always possible. For example, a loop that does no floating point will not use the floating-point adder or multiplier. And some units are forced to remain idle on some cycles because they have to wait for instructions with long pipeline latencies, or because only four instructions can be selected from the above menu. In addition, the compiler has to generate code to fill the pipeline on the first and second iterations, and code to wind down the operation on the last iteration, as well as special-case code to handle the event that the loop requires only 1 or 2 iterations.
The central part of the generated loop, meant to be executed many times, executes with the pipeline full and tries to keep it that way. The compiler can determine the minimum number of cycles required for this steady-state portion of the loop, and it tries to schedule the instructions so that this minimum-time performance is approached as the number of iterations in a loop increases.
In calculating the minimum number of cycles required for the loop, the compiler assumes that all data are in cache (specifically, in the primary data cache). If the data are not in cache, the loop takes longer to execute. (In this case, the compiler can generate additional instructions to prefetch data from memory into the cache before they are needed. See “Understanding Prefetching” in Chapter 6.) The remainder of this discussion of software pipelining considers only in-cache data. This may be unrealistic, but it is easier to determine if the software pipeline steady-state has achieved the peak rate that the loop is capable of.
To see how effective software pipelining is, return to the DAXPY example (Example 5-3) and consider its instruction schedule. The CPU is capable of, at most, one memory instruction and one multiply-add per cycle. Because three memory operations are done for each multiply-add, the optimal performance for this loop is one-third of the peak floating-point rate of the CPU.
In creating an instruction schedule, the compiler has to consider many hardware restrictions. The following is a sample of the restrictions that affect the DAXPY loop:
Only one load (ld) or store (st) can be performed on each CPU cycle.
A load of a floating-point datum from the primary cache has a latency of three cycles.
However, a madd instruction does a multiply followed by an add, and the load of the addend to the instruction can begin just one cycle before the madd, because two cycles will be expended on the multiply before the addend is needed.
It takes four cycles to complete a madd when the result is passed to another floating point operation, but five cycles when the output must be written to the register file, as is required to store the result.
The source operand of a store instruction is accessed two cycles after the address operand, so the store of the result of a madd instruction can be started 5 - 2 = 3 cycles after the madd begins.
Based on these considerations, the best schedule for an iteration of the basic DAXPY loop (Example 5-3) is shown in Table 5-2:
Table 5-2. Instruction Schedule for Basic DAXPY
Cycle | Inst 1 | Inst 2 | Inst 3 | Inst 4 |
|---|---|---|---|---|
0 | ld *x | ++x |
|
|
1 | ld *y |
|
|
|
2 |
|
|
|
|
3 |
|
|
| madd |
4 |
|
|
|
|
5 |
|
|
|
|
6 | st *y | br | ++y |
|
The simple schedule for this loop achieves two floating-point operations (multiply and add, in one instruction) each seven cycles, or one-seventh of the potential peak.
This schedule can be improved only by unrolling the loop so that it calculates two vector elements per iteration, as shown in Example 5-4.
Example 5-4. Unrolled DAXPY Loop
do i = 1, n-1, 2 y(i+0) = y(i+0) + a*x(i+0) y(i+1) = y(i+1) + a*x(i+1) enddo do j= i, n y(j+0) = y(j+0) + a*x(j+0) enddo |
The best schedule for the steady-state part of the unrolled loop is shown in Table 5-3
Table 5-3. Instruction Schedule for Unrolled DAXPY
Cycle | Inst 1 | Inst 2 | Inst 3 | Inst 4 |
|---|---|---|---|---|
0 | ld *(x+0) |
|
|
|
1 | ld *(x+1) |
|
|
|
2 | ld *(y+0) | x+=2 |
|
|
3 | ld *(y+1) |
|
| madd0 |
4 |
|
|
| madd1 |
5 |
|
|
|
|
6 | st *(y+0) |
|
|
|
7 | st *(y+1) | y+=2 | br |
|
This loop achieves four floating point operations in eight cycles, or one-fourth of peak; it is closer to the nominal rate for this loop, one-third of peak, but still not perfect.
A compiler-generated software pipeline schedule for the DAXPY loop is shown in Example 5-5.
Example 5-5. Compiler-Generated DAXPY Schedule
[ code to initially load registers omitted ]
loop:
Cycle 0: ld y4
Cycle 1: st y0
Cycle 2: st y1
Cycle 3: st y2
Cycle 4: st y3
Cycle 5: ld x5
Cycle 6: ld y5
Cycle 7: ld x6
Cycle 8: ld x7 madd4
Cycle 9: ld y6 madd5
Cycle 10: ld y7 y+=4 madd6
Cycle 11: ld x0 bne out madd7
Cycle 0: ld y0
Cycle 1: st y4
Cycle 2: st y5
Cycle 3: st y6
Cycle 4: st y7
Cycle 5: ld x1
Cycle 6: ld y1
Cycle 7: ld x2
Cycle 8: ld x3 madd0
Cycle 9: ld y2 madd1
Cycle 10: ld y3 y+=4 madd2
Cycle 11: ld x4 beq loop madd3
out:
[ code to store final results omitted]
|
This schedule is based on unrolling the loop four times. It achieves eight floating point operations in twelve cycles, or one-third of peak, so its performance is optimal. This schedule consists of two blocks of 12 cycles. Each 12-cycle block is called a replication since the same code pattern repeats for each block. Each replication accomplishes four iterations of the loop, containing four madds and 12 memory operations, as well as a pointer increment and a branch, so each replication achieves the nominal peak calculation rate. Iterations of the loop are spread out over the replications in a pipeline so that the superscalar slots are filled up.
Figure 5-1 shows the memory operations and madds for 12 iterations of the DAXPY loop. Time, in cycles, runs horizontally across the diagram.
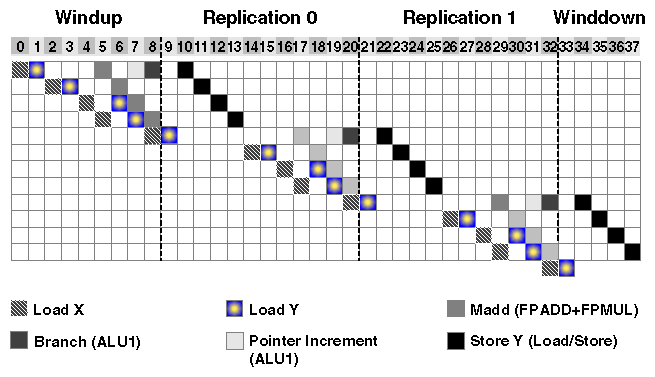
Cycles 0 through 8 fill the software pipeline. This is the windup stage; it was omitted from Example 5-5 for brevity. Cycles 9 through 20 make up the first replication; cycles 21 through 32, the second replication; and so on. The compiler has unrolled the loop four times, so each replication completes four iterations. Each iteration is spread out over several cycles: 15 for the first of the four unrolled iterations, 10 for the second, and 9 for each of the third and fourth iterations. Because only one memory operation can be executed per cycle, the four iterations must be offset from one another, and it takes 18 cycles to complete all four of them. Two replications are required to contain the full 18 cycles of work for the four iterations.
A test at the end of each iteration determines if all possible groups of four iterations have been started. If not, execution drops through to the next replication or branches back to the first replication at the beginning of the loop. If all groups of four iterations have begun, execution jumps out to code that finishes the in-progress iterations. This is the wind-down code; for brevity it was omitted from Example 5-5.
To help you determine how effective the compiler has been at software pipelining, the compiler can generate a report card for each loop. You can request that these report cards be written to a listing file, or assembler output can be generated to see them.
As an example, once again consider the DAXPY loop, as in Example 5-6.
Example 5-6. Basic DAXPY Loop Code
subroutine daxpy(n,a,x,y)
integer n
real*8 a, x(n), y(n)
do i = 1, n
y(i) = y(i) + a*x(i)
enddo
return
end
|
The software pipelining report card is produced as part of the assembler file that is an optional output of a compilation. Use the -S compiler flag to generate an assembler file; the report card will be mixed in with the assembly code, as follows (the flag -LNO:opt=0 prevents certain cache optimizations that would obscure the current study of software pipelining):
% f77 -n32 -mips4 -O3 -OPT:IEEE_arithmetic=3 -LNO:opt=0 -S daxpy.f |
An assembly listing is voluminous and confusing. You can use the shell script swplist (shown in Example C-5), which generates the assembler listing, extracts the report cards, and inserts each into a source listing file just above the loop it pertains to. The listing file is given the same name as the file compiled, but with the extension .swp. swplist is used with the same options one uses to compile:
% swplist -n32 -mips4 -O3 -OPT:IEEE_arithmetic=3 -LNO:opt=0 -c daxpy.f |
The report card generated by either of these methods resembles Example 5-7.
Example 5-7. Sample Software Pipeline Report Card
#<swps> #<swps> Pipelined loop line 1 steady state #<swps> #<swps> 50 estimated iterations before pipelining #<swps> 2 unrollings before pipelining #<swps> 6 cycles per 2 iterations #<swps> 4 flops ( 33% of peak) (madds count as 2) #<swps> 2 flops ( 16% of peak) (madds count as 1) #<swps> 2 madds ( 33% of peak) #<swps> 6 mem refs (100% of peak) #<swps> 3 integer ops ( 25% of peak) #<swps> 11 instructions ( 45% of peak) #<swps> 1 short trip threshold #<swps> 5 integer registers used. #<swps> 9 float registers used. #<swps> |
The report card tells you how effectively the CPU's hardware resources are being used in the schedule generated for the loop. There are lines showing how many instructions of each type there are per replication and what percentage of each resource's peak utilization has been achieved.
The report card in Example 5-7 is for the loop starting at line 1 of the source file (this line number may be approximate). The loop was unrolled two times and then software pipelined. The schedule generated by the compiler requires six cycles per replication, and each replication completes two iterations because of the unrolling.
The steady-state performance of the loop is 33% of the floating-point peak. The “madds count as 2” line counts floating-point operations. This indicates how fast the CPU can run this loop on an absolute scale. The peak rate of the CPU is two floating-point operations per cycle, or twice the CPU clock rate. Because this loop reaches 33% of peak, it has an absolute rate of two-thirds the CPU clock, or 133 MFLOPS in a 200 MHz CPU.
Alternatively, the “madds count as 1” line counts floating-point instructions. Since the floating point work in most loops does not consist entirely of madd instructions, this count indicates how much of the floating point capability of the chip is being utilized in the loop given its particular mix of floating point instructions. A 100% utilization here, even if the floating point operation rate is less than 100% of peak, means that the chip is running as fast as it can in this loop.
For the R10000 CPU, which has an adder unit and a multiplier, this line does not provide much additional information beyond the “madds count as 2” line. In fact, the utilization percentage is misleading in this example, because both of the floating-point instructions in the replication are actually madds, and these use both the adder and the multiplier. Here, the instruction is counted as if it simply uses one of the units. On an R8000 CPU—for which there are two complete floating point units, each capable of add, multiply, and madd instructions—this line provides better information. You can easily see cases in which the chip's floating point units are 100% utilized even though the CPU is not sustaining two floating-point operations per unit per cycle.
Each software pipeline replication described in Example 5-7 contains six memory references, the most possible in this many cycles (shown as “100% of peak”). Thus, this loop is memory-constrained. Sometimes that's unavoidable, and no additional (non-memory) resources can make the loop run faster. But in other situations, loops can be rewritten to reduce the number of memory operations, and in these cases performance can be improved. An example of such a loop is presented later.
Example 5-7 shows that only three integer operations are used (presumably a branch and two pointer increments). The total number of instructions for the replication is 11, so there are plenty of free superscalar slots—the theoretical limit would be 24, or 4 per cycle.
The report card indicates that there is a “short trip threshold” of one. This means that, for loops with fewer than one group of two iterations, a separate, non-pipelined piece of code is used. Building up and draining the pipeline imposes some overhead, so pipelining is avoided for very short loops.
Finally, Example 5-7 reports that five integer registers and nine floating-point registers were required by the compiler to schedule the code. Availability of registers is not an issue in this case, but bigger and more complicated loops require more registers, sometimes more than the CPU provides. In these cases, the compiler must either introduce some scratch memory locations to hold intermediate results, increasing the number of load and store operations for the loop, or stretch out the loop to allow greater reuse of the existing registers. When these problems occur, splitting the loop into smaller pieces can often eliminate them.
This report card provides you with valuable information. If a loop is running well, that is validated by the information it contains. If the speed of the loop is disappointing, it provides clues as to what should be done—either via the use of additional compiler flags or by modifying the code—to improve the performance.
The compiler does not use software pipelining on loops by default. To enable software pipelining, you must use the highest level of optimization, -O3. This can be specified with either -Ofast or with -O3; the difference is that -Ofast is a superset of -O3 and also turns on other optimizations such as interprocedural analysis (discussed later under “Exploiting Interprocedural Analysis”).
Software pipelining is not done by default, because it increases compilation time. Although finding the number of cycles in an optimal schedule is easy, producing a schedule given a finite number of registers is difficult. Heuristic algorithms are employed to try to find a schedule. In some instances they fail, and only a schedule with more cycles than optimal can be generated. The schedule that is found can vary depending on subtle code differences or the choice of compiler flags.
Some loops are well suited to software pipelining. In general, vectorizable loops, such as the DAXPY loop (see Example 5-6) compile well with no special effort from you. But getting some loops to software pipeline can be difficult. Fortunately, other optimizations—interprocedural analysis, loop nest optimizations—and compiler directives can help in these situations.
For an in-order superscalar CPU such as the R8000 CPU, the key loops in a program must be software pipelined to achieve good performance; the functional units sit idle if concurrent work is not scheduled for them. With its out-of-order execution, the R10000 CPU can be much more forgiving of the code generated by the compiler; even code scheduled for another CPU can still run well. Nevertheless, there is a limit to the instruction reordering the CPU can accomplish, so getting the most time-consuming loops in a program to software pipeline is still key to achieving top performance.
Not all loops software pipeline. One common cause of this is a subroutine or function call inside the loop. When a loop contains a call, the software pipelining report card is as follows:
#<swpf> Loop line 1 wasn't pipelined because: #<swpf> Function call in the loop body #<swpf> |
If the called subroutine contains loops of its own, then this software pipelining failure is inconsequential because it is the loops in the subroutine that need to be pipelined. If there are no loops in the subroutine, however, finding a way to get the loop containing it to software pipeline may be important for achieving good performance.
One way to remedy this is to replace the subroutine call with a copy of the subroutine's code. This is inlining, and although it can be done manually, the compiler can do it automatically as part of interprocedural analysis (“Exploiting Interprocedural Analysis”).
While-loops, and loops that contain goto statements that jump out of the loop, do not software pipeline. Non-pipelined loops can still run well on SN0 systems. For in-order CPUs such as the R8000, however, such loops could incur a significant performance penalty, so if an alternate implementation exists that converts the loop to a standard do- or for-loop, use it.
Finally, sometimes the compiler notes a “recurrence” in the SWP report card. This indicates that the compiler believes that the loop depends, or might depend, on a value produced in a preceding iteration of the loop. This kind of dependency between iterations inhibits pipelining. Sometimes it is real; more often it is only apparent, and can be removed by specifying a different aliasing model.
Optimization level -O3 enables a variety of optimizations including software pipelining and loop nest optimization. But a handful of other options and directives can improve the software pipelined schedules that the compiler generates and speed up non-pipelined code as well. These are described next, before delving into fine-tuning interprocedural analysis and loop nest optimizations.
The problem with a pointer is that it might point to anything, including a named variable or the value also addressed by a different pointer. The possibility of “aliasing”—the possibility that two unrelated names might refer to the identical memory—creates uncertainty that requires the compiler to make the most conservative assumptions about dependencies caused by dereferencing pointer variables.
Without assurance from the programmer, the compiler needs to be cautious and assume that any two pointers can point to the same location in memory. This caution removes many optimization opportunities, particularly for loops. When this is not the case, you can use the -OPT:alias= flag. The many possible aliasing models are detailed in the opt(5) man page.
When you are sure that different pointer variables never point to overlapping regions of memory, use the -OPT:alias=restrict to allow the compiler to generate the best-performing code. If you use this flag to compile code in which different pointers can alias the same data, incorrect code can be generated. That would not be a compiler problem; you provided the compiler with false information.
As an example, consider the C implementation of DAXPY in Example 5-8.
Example 5-8. C Implementation of DAXPY Loop
void
daxpy(int n, double a, double *x, double *y)
{
int i;
#pragma unroll(1)
for (i=0; i<n; i++) {
y[i] += a * x[i];
}
}
|
When Example 5-8 (including a pragma to prevent automatic unrolling) is compiled with the following command, it produces the software pipelining message as shown in Example 5-9:
% swplist -n32 -mips4 -O3 -OPT:IEEE_arithmetic=3 -LNO:opt=0 -c example5-8.c |
(The -LNO:opt=0 option is used to prevent certain cache optimizations that would obscure this study of software pipelining performance.)
Example 5-9. SWP Report Card for C Loop with Default Alias Model
#<swps> Pipelined loop line 5 steady state #<swps> #<swps> 100 estimated iterations before pipelining #<swps> Not unrolled before pipelining #<swps> 9 cycles per iteration #<swps> 2 flops ( 11% of peak) (madds count as 2) #<swps> 1 flop ( 5% of peak) (madds count as 1) #<swps> 1 madd ( 11% of peak) #<swps> 3 mem refs ( 33% of peak) #<swps> 3 integer ops ( 16% of peak) #<swps> 7 instructions ( 19% of peak) #<swps> 1 short trip threshold #<swps> 4 integer registers used. #<swps> 3 float registers used. #<swps> #<swps> 3 min cycles required for resources #<swps> 8 cycles required for recurrence(s) #<swps> 3 operations in largest recurrence #<swps> 9 cycles in minimum schedule found |
Note: If the #pragma unroll(1) is deleted from the example, the compiler automatically unrolls the loop to a depth of 2 and the following output is obtained:
#<swpf> Loop line 3 wasn't pipelined -- MII (16) exceeded 8 (it is no longer profitable to pipeline this loop). |
The compiler cannot determine the data dependencies between x and y, and has to assume that storing into y[i] could modify some element of x. The compiler therefore produces a schedule that is more than twice as slow as is ideal.
When the #pragma unroll(1) line is deleted from Example 5-8 and compiler option -OPT:alias=restrict is added to the swplist command, the report resembles Example 5-10.
Example 5-10. SWP Report Card for C Loop with Alias=Restrict
#<swps> Pipelined loop line 3 steady state #<swps> #<swps> 50 estimated iterations before pipelining #<swps> 2 unrollings before pipelining #<swps> 6 cycles per 2 iterations #<swps> 4 flops ( 33% of peak) (madds count as 2) #<swps> 2 flops ( 16% of peak) (madds count as 1) #<swps> 2 madds ( 33% of peak) #<swps> 6 mem refs (100% of peak) #<swps> 3 integer ops ( 25% of peak) #<swps> 11 instructions ( 45% of peak) #<swps> 1 short trip threshold #<swps> 5 integer registers used. #<swps> 9 float registers used. |
Because it knows that the x and y arrays are nonoverlapping, the compiler can generate an ideal schedule. As long as this subroutine has been specified so that this assumption is correct, the code is valid and runs significantly faster.
When the code uses pointers to pointers, -OPT:alias=restrict is insufficient to tell the compiler that data dependencies do not exist. If this is the case, using -OPT:alias=disjoint allows the compiler to ignore potential data dependencies (disjoint is a superset of restrict).
C code using multidimensional arrays is a good candidate for the -OPT:alias=disjoint flag. Consider the nest of loops shown in Example 5-11.
Example 5-11. C Loop Nest on Multidimensional Array
for ( i=1; i< size_x1-1 ;i++)
for ( j=1; j< size_x2-1 ;j++)
for ( k=1; k< size_x3-1 ;k++)
{
out3 = weight3*( field_in[i-1][j-1][k-1]
+ field_in[i+1][j-1][k-1]
+ field_in[i-1][j+1][k-1]
+ field_in[i+1][j+1][k-1]
+ field_in[i-1][j-1][k+1]
+ field_in[i+1][j-1][k+1]
+ field_in[i-1][j+1][k+1]
+ field_in[i+1][j+1][k+1] );
out2 = weight2*( field_in[i ][j-1][k-1]
+ field_in[i-1][j ][k-1]
+ field_in[i+1][j ][k-1]
+ field_in[i ][j+1][k-1]
+ field_in[i-1][j-1][k ]
+ field_in[i+1][j-1][k ]
+ field_in[i-1][j+1][k ]
+ field_in[i+1][j+1][k ]
+ field_in[i ][j-1][k+1]
+ field_in[i-1][j ][k+1]
+ field_in[i+1][j ][k+1]
+ field_in[i ][j+1][k+1] );
out1 = weight1*( field_in[i ][j ][k-1]
+ field_in[i ][j ][k+1]
+ field_in[i ][j+1][k ]
+ field_in[i+1][j ][k ]
+ field_in[i-1][j ][k ]
+ field_in[i ][j-1][k ] );
out0 = weight0* field_in[i ][j ][k ];
field_out[i][j][k] = out0+out1+out2+out3;
}
|
Here, the three-dimensional arrays are declared as
double ***field_out; double ***field_in; |
Without input from the user, the compiler cannot tell if there are data dependencies between different elements of one array, let alone both. Because of the multiple levels of indirection, -OPT:alias=restrict does not provide sufficient information. As a result, compiling Example 5-11 with the following options produces the following software pipeline report card shown in Example 5-12:
% swplist -n32 -mips4 -Ofast=ip27 -OPT:IEEE_arithmetic=3:alias=restrict -c stencil.c |
Example 5-12. SWP Report Card for Stencil Loop with Alias=Restrict (output obtained using version 7.2.1.3m compiler)
#<swps> Pipelined loop line 9 steady state #<swps> #<swps> 100 estimated iterations before pipelining #<swps> Not unrolled before pipelining #<swps> 38 cycles per iteration #<swps> 30 flops ( 39% of peak) (madds count as 2) #<swps> 27 flops ( 35% of peak) (madds count as 1) #<swps> 3 madds ( 7% of peak) #<swps> 28 mem refs (73% of peak) #<swps> 11 integer ops ( 14% of peak) #<swps> 66 instructions ( 43% of peak) #<swps> 2 short trip threshold #<swps> 13 integer registers used. #<swps> 17 float registers used. #<swps> #<swps> 28 min cycles required for resources. #<swps> 17 float registers used. |
However, you can instruct the compiler that even multiple indirections are independent with -OPT:alias=disjoint. Compiling with this aliasing model produces the results shown in Example 5-13.
Example 5-13. SWP Report Card for Stencil Loop with Alias=Disjoint (output obtained using version 7.3 compiler)
#<swps> #<swps> Pipelined loop line 5 steady state #<swps> #<swps> 100 estimated iterations before pipelining #<swps> Not unrolled before pipelining #<swps> 28 cycles per iteration #<swps> 30 flops ( 53% of peak) (madds count as 2) #<swps> 27 flops ( 48% of peak) (madds count as 1) #<swps> 3 madds ( 10% of peak) #<swps> 28 mem refs (100% of peak) #<swps> 11 integer ops ( 19% of peak) #<swps> 66 instructions ( 58% of peak) #<swps> 2 short trip threshold #<swps> 15 integer registers used. #<swps> 17 float registers used. #<swps> |
This is a 36% improvement in performance (28 cycles per iteration, down from 38), and all it took was a flag to tell the compiler that the pointers can't alias each other.
In some situations, code ambiguity goes beyond pointer aliasing. Consider the loop in Example 5-14.
Example 5-14. Indirect DAXPY Loop
void idaxpy(
int n,
double a,
double *x,
double *y,
int *index)
{
int i;
for (i=0; i<n; i++) {
y[index[i]] += a * x[index[i]];
}
}
|
You have seen this DAXPY operation before, except here the vector elements are chosen indirectly through an index array. (The same technique could as easily be used in Fortran.) Assume that the vectors x and y do not overlap; and compile as before (again with -LNO:opt=0 only to clarify the results).
% swplist -n32 -mips4 -Ofast=ip27 -OPT:IEEE_arithmetic=3:alias=restrict -LNO:opt=0 -c idaxpy.c |
The results, as shown in Example 5-15, are less than optimal.
Example 5-15. SWP Report Card on Indirect DAXPY (7.2.1.3 compiler)
#<swps> Pipelined loop line 7 steady state #<swps> 50 estimated iterations before pipelining #<swps> 2 unrollings before pipelining #<swps> 10 cycles per 2 iterations #<swps> 4 flops ( 20% of peak) (madds count as 2) #<swps> 2 flops ( 10% of peak) (madds count as 1) #<swps> 2 madds ( 20% of peak) #<swps> 8 mem refs ( 80% of peak) #<swps> 8 integer ops ( 40% of peak) #<swps> 18 instructions ( 45% of peak) #<swps> 1 short trip threshold #<swps> 10 integer registers used. #<swps> 4 float registers used. #<swps> #<swps> 8 min cycles required for resources #<swps> 10 cycles in minimum schedule found |
When run at optimal speed, this loop should be constrained by loads and stores. In that case, the memory references would be at 100% of peak. The problem is that, since the values of the index array are unknown, there could be data dependencies between loop iterations for the vector y. For example, if index[i] = 1 for all i, all iterations would update the same vector element. In general, if the values in index are not a permutation of unique integers from 0 to n-1 (1 to n, in Fortran), it could happen that a value stored on one iteration could be referenced on the next. In that case, the best pipelined code could produce a wrong answer.
If you know that the values of the array index are such that no dependencies will occur, you can inform the compiler of this via the ivdep compiler directive. For a Fortran program, the directive looks like Example 5-16.
Example 5-16. Indirect DAXPY in Fortran with ivdep
cdir$ ivdep
do i = 1, n
y(ind(i)) = y(ind(i)) + a * x(ind(i))
enddo
|
In C, the directive is a pragma and is used as shown in Example 5-17.
Example 5-17. Indirect DAXPY in C with ivdep
#pragma ivdep
for (i=0; i<n; i++) {
y[index[i]] += a * x[index[i]];
}
|
With this change, the schedule is improved by 25%, as shown in Example 5-18.
Example 5-18. SWP Report Card for Indirect DAXPY with ivdep
#<swps> 50 estimated iterations before pipelining #<swps> 2 unrollings before pipelining #<swps> 8 cycles per 2 iterations #<swps> 4 flops ( 25% of peak) (madds count as 2) #<swps> 2 flops ( 12% of peak) (madds count as 1) #<swps> 2 madds ( 25% of peak) #<swps> 8 mem refs (100% of peak) #<swps> 8 integer ops ( 50% of peak) #<swps> 18 instructions ( 56% of peak) #<swps> 2 short trip threshold #<swps> 18 integer registers used. #<swps> 6 float registers used. |
The ivdep pragma gives the compiler permission to ignore the dependencies that are possible from one iteration to the next. As long as those dependencies do not actually occur, the code produces correct answers. But if they do in fact occur, the output can be wrong. Just as when misusing the alias models, this is a case of user error.
There are a few subtleties in how the ivdep directive works. First, note that the directive applies only to inner loops. Second, it applies only to dependencies that are carried by the loop. Consider the code segment in Example 5-19.
Example 5-19. Loop with Two Types of Dependency
do i= 1, n a(index(1,i)) = b(i) a(index(2,i)) = c(i) enddo |
Two types of dependencies are possible in this loop. If index(1,i) is the same as index(1,i+k), or if index(2,i) is the same as index(2,i+k), for some value of k such that i+k is in the range 1 to n, there is a loop-carried dependency. Because the code is in a loop, some element of a will be stored into twice, inappropriately. (If the loop is parallelized, you cannot predict which assignment will take effect.)
If index(1,i) is the same as index(2,i) for some value of i, there is a non-loop-carried dependency. Some element of a will be assigned from both b and c, and this would happen whether the code was in a loop or not.
In Example 5-17 there is a potential loop-carried dependency. The ivdep directive informs the compiler that the dependency is not actually present—there are no duplicate values in the index array. But if the compiler detects a potential non-loop-carried dependency (a dependency between statements in one iteration), the ivdep directive does not instruct the compiler to ignore these potential dependencies. To force even these dependencies to be overlooked, extend the behavior of the ivdep directive by using the -OPT:liberal_ivdep=ON flag. When this flag is used, an ivdep directive means to ignore all dependencies in a loop.
With either variant of ivdep, the compiler issues a warning when the directive has instructed it to break an obvious dependence.
Example 5-20. C Loop with Obvious Loop-Carried Dependence
for (i=1; i<n; i++) {
a[i] = a[i-1] + 3;
}
|
In Example 5-20 the dependence is real. Forcing the compiler to ignore it almost certainly produces incorrect code. Nevertheless, an ivdep pragma breaks the dependence, and the compiler issues a warning and then schedules the code so that the iterations are carried out independently.
One more variant of ivdep is enabled with the flag -OPT:cray_ivdep=ON. This instructs the compiler to use the semantics that Cray Research specified when it originated this directive for its vectorizing compilers. That is, only “lexically backward” loop-carried dependencies are broken. Example 5-20 is an instance of a lexically backwards dependence. Example 5-21 is not.
Here, the dependence is from the load (a[i+1]) to the store (a[i]), and the load comes lexically before the store. In this case, a Cray semantics ivdep directive would not break the dependence.
The freedom of C looping syntax, as compared to Fortran loops, presents the compiler with some challenges. You provide extra information by specifying an alias model and the ivdep pragma, and these allow you to achieve good performance from C despite the language semantics. But a few other things can be done to improve the speed of programs written in C.
Global variables can sometimes cause performance problems, because it is difficult for the compiler to determine whether they alias other variables. If loops involving global variables do not software pipeline as efficiently as they should, you can often cure the problem by making local copies of the global variables.
Another problem arises from using dereferenced pointers in loop tests.
The loop in Example 5-22 will not software pipeline, because the compiler cannot tell whether the value addressed by n will change during the loop. If you know that this value is loop-invariant, you can inform the compiler by creating a temporary scalar variable to use in the loop test, as shown in Example 5-23.
Example 5-23. C Loop Test Using Local Copy of Dereferenced Pointer
int lim = *n;
for (i=0; i<lim; i++) {
y[i] += a * x[i];
}
|
When -OPT:alias=restrict is used, the loop in Example 5-23 should now pipeline comparably to Example 5-10.
Example 5-24 shows a different case of loop-invariant pointers leading to aliasing problems.
Example 5-24. C Loop with Disguised Invariants
void sub1(
double **dInputToHidden,
double *HiddenDelta,
double *Input,
double **InputToHidden,
double alpha,
double eta,
int NumberofInputs,
int NumberofHidden)
{
int i, j;
for (i=0; i<NumberofInputs; i++) {
for (j=0; j<NumberofHidden; j++) {
dInputToHidden[i][j] = alpha * dInputToHidden[i][j]
+ eta * HiddenDelta[j] * Input[i];
InputToHidden[i][j] += dInputToHidden[i][j];
}
}
}
|
This loop is similar to a DAXPY; after pipelining it should be memory bound with about a 50% floating-point utilization. But compiling with -OPT:alias=disjoint does not quite achieve this level of performance.
Example 5-25. SWP Report Card for Loop with Disguised Invariance
#<swps> Pipelined loop line 10 steady state #<swps> #<swps> 100 estimated iterations before pipelining #<swps> Not unrolled before pipelining #<swps> 9 cycles per iteration #<swps> 5 flops ( 27% of peak) (madds count as 2) #<swps> 4 flops ( 22% of peak) (madds count as 1) #<swps> 1 madd ( 11% of peak) #<swps> 5 mem refs (55% of peak) #<swps> 4 integer ops ( 22% of peak) #<swps> 13 instructions ( 36% of peak) #<swps> 2 short trip threshold #<swps> 6 integer registers used. #<swps> 9 float registers used. #<swps> #<swps> 5 min cycles required for resources #<swps> 8 cycles required for recurrence(s) #<swps> 3 operations in largest recurrence #<swps> 9 cycles in minimum schedule found |
The problem is the pointers indexed by i; they cause the compiler to see dependencies that aren't there. This problem can be fixed by hoisting the invariants out of the inner loop, as shown in the emphasized statements in Example 5-26.
Example 5-26. C Loop with Invariants Exposed
void sub2(
double **dInputToHidden,
double *HiddenDelta,
double *Input,
double **InputToHidden,
double alpha,
double eta,
int NumberofInputs,
int NumberofHidden)
{
int i, j;
double *dInputToHiddeni, *InputToHiddeni, Inputi;
for (i=0; i<NumberofInputs; i++) {
dInputToHiddeni = dInputToHidden[i];
InputToHiddeni = InputToHidden[i];
Inputi = Input[i];
for (j=0; j<NumberofHidden; j++) {
dInputToHiddeni[j] = alpha * dInputToHiddeni[j]
+ eta * HiddenDelta[j] * Inputi;
InputToHiddeni[j] += dInputToHiddeni[j] ;
}
}
}
|
When the loop is written this way, the compiler can see that dInputToHidden[i], InputToHidden[i], and Input[i] will not change during execution of the inner loop, so it can schedule that loop more aggressively, resulting in 5 cycles per iteration rather than 9.
Example 5-27. SWP Report Card for Modified Loop
#<swps> Pipelined loop line 16 steady state #<swps> 100 estimated iterations before pipelining #<swps> Not unrolled before pipelining #<swps> 5 cycles per iteration #<swps> 5 flops ( 50% of peak) (madds count as 2) #<swps> 4 flops ( 40% of peak) (madds count as 1) #<swps> 1 madd ( 20% of peak) #<swps> 5 mem refs (100% of peak) #<swps> 4 integer ops ( 40% of peak) #<swps> 13 instructions ( 65% of peak) #<swps> 3 short trip threshold #<swps> 8 integer registers used. #<swps> 9 float registers used. |
When extra information is conveyed to the compiler, it can generate faster code. One useful bit of information that the compiler can sometimes exploit is knowledge of which hardware exceptions can be ignored. An exception is an event that requires intervention by the operating system. Examples include floating-point exceptions such as divide by zero, and memory access exceptions such as segmentation fault. Any program can choose which exceptions it will pay attention to and which it will ignore. For example, floating-point underflows generate exceptions, but their effect on the numeric results is usually negligible, so they are typically ignored by flushing them to zero (via hardware). Divide by zero is generally enabled because it usually indicates a fatal error in the program.
How the compiler takes advantage of disabled exceptions is best seen through an example. Consider a program that is known not to make invalid memory references. It runs fine whether memory exceptions are enabled or disabled. But if they are disabled and the compiler knows this, it can generate code that may speculatively make references to potentially invalid memory locations; for example, a reference to an array element that might lie beyond the end of an array. Such code can run faster than nonspeculative code on a superscalar architecture, if it takes advantage of functional units that would otherwise be idle. In addition, the compiler can often reduce the amount of software pipeline wind-down code when it can make such speculative memory operations; this allows more of the loop iterations to be spent in the steady-state code, leading to greater performance.
When the compiler generates speculative code, it moves instructions in front of a branch that previously had protected them from causing exceptions. For example, accesses to memory elements beyond the end of an array are normally protected by the test at the end of the loop. Speculative code can be even riskier than this. For instance, a source line such as that in Example 5-28 might be compiled into the equivalent of Example 5-29.
In Example 5-29, the division operation is started first so that it can run in the floating point unit concurrently with the test of x. When x is nonzero, the time to perform the test essentially disappears. When x is zero, the invalid result of dividing by zero is discarded, and again no time is lost. However, division by zero is no longer protected by the branch; an exception can occur but should be ignored.
Allowing such speculation is the only way to get some loops to software pipeline. On an in-order superscalar CPU such as the R8000, speculation is critical to achieving top performance on loops containing branches. To allow this speculation to be done more freely by the compiler, most exceptions are disabled by default on R8000 based systems.
For the R10000 CPU, however, the hardware itself performs speculative execution. Instructions can be executed out of order. The CPU guesses which way a branch will go, and speculatively executes the instructions that follow on the predicted path. Executing code equivalent to Example 5-28, the R10000 CPU is likely to predict that the branch will find x nonzero, and to speculatively execute the division before the test is complete. When x is zero, an exception results that would not normally occur in the program. The CPU dismisses exceptions caused by a speculative instruction without operating system intervention. Thus, most exceptions can be enabled by default in R10000-based systems.
Because of the hardware speculation in the R10000 CPU, software speculation by the compiler is less critical from a performance point of view. Moreover, software speculation can cause problems, because exceptions encountered on a code path generated by the compiler are not simply dismissed—unlike speculative exceptions created by the hardware. In the best case, the program wastes time handling software traps.
For these reasons, when generating code for the R10000 CPU, the compiler by default only performs the safest speculative operations. Which operations it speculates on are controlled by the -TENV:X=n flag, where n has the following meanings, as described in the cc(1) , f77(1), or f90(1) man page:
0 | No speculative code movement. |
1 | Speculation that might cause IEEE-754 underflow and inexact exceptions. |
2 | Speculation that might cause any IEEE-754 exceptions except zero-divide. |
3 | Speculation that might cause any IEEE-754 exceptions. |
4 | Speculation that might cause any exception including memory access. |
The compiler generates code to disable software handling of any exception that is permitted by the -TENV:X flag.
The default is -TENV:X=1 for optimization levels of -O2 or below, and -TENV:X=2 for -O3 or -Ofast. Normally you should use the default values. Only when you have verified that the program never generates exceptions (see “Using Exception Profiling” in Chapter 4), should you use higher values, which sometimes provide a modest increase in performance.
A program that divides by zero in course of the execution is not correct and should be aborted with a divide by zero exception. Compiling such a program with -TENV:X=3 or -TENV:X=4 will continue execution after the division by zero, with the effect that NaN and Inf values will propagate through the calculations and show up in the results.
Division by zero generated by the compiler for optimization will be safely discarded under these circumstances and will not propagate. However, the compiler generated exceptions cannot be distinguished from the genuine program errors, which makes it diffucult to trap on the program errors (see “Understanding Treatment of Underflow Exceptions” in Chapter 4) when TENV:X=3 is used.
The runtime library assumes the most liberal exception setting, so programs linked with libraries compiled X=3 will have the division by zero exception disabled. This is currently the case with the scientific libraries SCSL and complib.sgimath. The fpe mechanism can still be used to trap errors. If any exceptions are generated by the libraries (as seen with the trace back) they are just an artifact of the compiler optimization and do not need to be analyzed.
The compiler tries to schedule looping and branching code for the CPU so that the CPU's speculative execution will be most effective. When scheduling code, the question arises: how often will a branch be taken? The compiler has only the source code, so it can only schedule branches based on heuristics (that is, on educated guesses). An example of a heuristic is the guess that the conditional branch that closes a loop is taken much more often than not. Another is that the then-part of an if is used more often than it is skipped.
As described under “Creating a Compiler Feedback File” in Chapter 4, you can create a file containing exact counts of the use of branches during a run of a program. Then you can feed this file to the compiler when you next compile the program. The compiler uses these counts to control how it schedules code around conditional branches.
After you create a feedback file, you pass it to the compiler using the -fb filename option. You would pass the feedback file for the entire program when compiling any module of that program, or you can pass it for the compilation of only the critical modules. The feedback information is optional, and the compiler ignores it when the statement numbers in the feedback file do not match the source code as it presently exists.
One difficulty with feedback files is that they must be created from a non-optimized executable. When the executable program is compiled with optimization, the simple relationship between executable code and source statements is lost. If you compile with -fb and the compiler issues a warning about mismatched statement numbers, the cause is that the feedback file came from a trace of an optimized program.
The proper sequence to make use a feedback file is as follows:
This rather elaborate process is best reserved for the final compilation before releasing a completed program.
Most compiler optimizations work within a single routine (function or procedure) at a time. This helps keep the problems manageable and is a key aspect of supporting separate compilation because it allows the compiler to restrict attention to the current source file.
However, this narrow focus also presents serious restrictions. Knowing nothing about other routines, the optimizer is forced to make worst-case assumptions about the possible effects of calls to them. For instance, at any function call it must usually generate code to save and then restore the state of all variables that are in registers.
Interprocedural analysis (IPA) analyzes more than a single routine—preferably the entire program—at once. It can transfer information across routine boundaries, and these results are available to subsequent optimization phases, such as loop nest optimization and software pipelining. The optimizations performed by the MIPSpro compilers's IPA facility include the following:
Inlining: replacing a call to a routine with a modified copy of the routine's code, when the called routine is in a different source file.
Constant propagation: When a global variable is initialized to a constant value and never modified, each use of its name is replaced by the constant value. When a parameter of a routine is passed as a particular constant value in every call, the parameter is replaced in the routine's code by the constant.
Common block array padding: Increasing the dimensions of global arrays in Fortran to reduce cache conflicts.
Dead function elimination: Functions that are never called can be removed from the program image, improving memory utilization.
Dead variable elimination: Variables that are never used can be eliminated, along with any code that initializes them.
PIC optimization: finding names that are declared external, but which can safely be converted to internal or hidden names. This allows simpler, faster function-call protocols to be used, and reduces the number of slots need in the global table.
Global name optimizations: Global names in shared code must normally be referenced via addresses in a global table, in case they are defined or preempted by another DSO. If the compiler knows it is compiling a main program and that the name is defined in another of the source files making up the main program, an absolute reference can be substituted, eliminating a memory reference.
Automatic global table sizing: IPA can optimize the data items that can be referenced by simple offsets from the GP register, instead of depending on the programmer to provide an ideal value through the -G compiler option.
The first two optimizations, inlining and constant propagation, have the effect of enabling further optimizations. Inlining removes function calls from loops (helping to eliminate dependencies) while giving the software pipeliner more statements to work with in scheduling. After constant propagation, the optimizer finds more common subexpressions to combine, or finds more invariant expressions that it can lift out of loops.
IPA is easy to use. Use an optimization level of -O2 or -O3 and add -IPA to both the compile and link steps when building your program. Alternatively, use -Ofast for both compile and link steps; this optimization flag enables IPA.
Unlike other IPA implementations, the MIPSpro compilers do not require that all the components of a program be present and compiled at once for IPA analysis. IPA works by postponing much of the compilation process until the link step, when all the program components can be analyzed together.
The compile step, applied to one or more source modules, does syntax analysis and places an intermediate representation of the code into the .o output file, instead of normal relocatable code. This intermediate code, called WHIRL code in some compiler documentation, contains preliminary IPA and optimization information (this is why all compiler flags must be given at the compile step).
When all source files have been compiled into .o files, the program is linked as usual with a call to the ld command (or to cc, f77, or f90 which in turn call ld). The linker recognizes that at least some of its input object files are incompletely-compiled WHIRL files. The link step can include object files (.o) and archives (.a) that have been compiled without IPA analysis, as well as referencing DSOs that, however they were compiled, cannot contribute detailed information because a DSO may be replaced with a different version after the program is built.
The linker invokes IPA, which analyzes and transforms all the input WHIRL objects, writing modified versions of the objects. The linker then invokes the compiler back end on each of the modified objects, so that it can complete the optimization phases and generate code to produce a normal relocatable object. Finally, when all input files have been reduced to object code, the linker can proceed to link the object files.
If there are modules that you would prefer to compile using an optimization level of -O1 or -O0, that's fine. Without IPA, modules are compiled to relocatable object files. They will link into the program with no problems, but no interprocedural analysis will be performed on them. The linker accepts a combination of WHIRL and object files, and IPA is applied as necessary.
However, all modules that are compiled with -IPA should also be compiled to the identical optimization level—normally -O3, or -Ofast which implies both -O3 and -IPA, but you can compile modules with -O2 and -IPA. The problem is that if the compiler inlines code into a module compiled -O2, the inlined code is not software pipelined or otherwise optimized, even though it comes from a module compiled -O3.
When IPA is used, the proportion of time spent in compiling and linking changes. The compile step is usually faster with IPA, because the majority of the optimizations are postponed until the link step. However, the link step takes longer, because it is now responsible for most of the compilation.
The total build time is likely to increase for two reasons: First, although the IPA step itself may not be expensive, inlining usually increases the size of the code, and therefore expands the time required by the rest of the compiler. Second, because IPA analysis can propagate information from one module into optimization decisions involving many other modules, even minor changes to a single component module cause most of the program compilation to be redone. As a result, IPA is best suited for use on programs with a stable source base.
One key feature of IPA is inlining, the replacement of a call to a routine with the code of that routine. This feature can improve performance in several ways:
By eliminating the subroutine call, the overhead in making the call, such as saving and restoring registers, is also eliminated.
Possible aliasing effects between routine parameters and global variables are eliminated.
A larger amount of code is exposed to later optimization phases of the compiler. So, for example, loops that previously could not be software pipelined now can be.
But there are some disadvantages to inlining:
Inlining expands the size of the source code and so increases compilation time.
The resulting object text is larger, taking more space on disk and more time to load.
The additional object code takes more room in the cache, sometimes causing more primary and secondary cache misses.
Thus, inlining does not always improve program execution time. As a result, there are flags you can use to control which routines will be inlined.
Inlining is available in FORTRAN 77, Fortran 90/95, C, and C++. There are a few restrictions on inlining. The following types of routines cannot be inlined:
Recursive routines.
Routines using static (SAVE in Fortran) local variables.
Routines with variable argument lists (varargs).
Calls in which the caller and callee have mismatched argument lists.
Routines written in one language cannot be inlined into a module written in a different language.
IPA supports two types of inlining: manual and automatic. The manual (also known as standalone) inliner is invoked with the -INLINE option group. It has been provided to support the C++ inline keyword but can also be used for C and Fortran programs using the command-line option. It inlines only the routines that you specify and they must be located in the same source file as the routine into which they are inlined. The automatic inliner is invoked whenever -IPA (or -Ofast) is used. It uses heuristics to decide which routines will be beneficial to inline, so you don't need to specify these explicitly. It can inline routines from any files that have been compiled with -IPA.
The manual inliner is controlled with the -INLINE option group. Use a combination of the following four options to specify which routines to inline:
-INLINE:all | Inline all routines except those specified to -INLINE:never. |
-INLINE:none | Inline no routines except those specified to -INLINE:must. |
-INLINE:must=name,... | Specify a list of routines to inline at every call. |
-INLINE:never=name,. | Specify a list of routines never to inline. |
Consider the code in Example 5-30.
Example 5-30. Code Suitable for Inlining
subroutine zfftp ( z, n, w, s )
real*8 z(0:2*n-1), w(2*(n-1)), s(0:2*n-1)
integer n
integer iw, i, m, j, k
real*8 w1r, w1i, w2r, w2i, w3r, w3i
iw = 1
c First iteration of outermost loop over k&m: n = 4*km.
i = 0
m = 1
k = n/4
if (k .gt. 1) then
do j = 0, k-1
call load4(w(iw),iw,w1r,w1i,w2r,w2i,w3r,w3i)
call radix4pa(z(2*(j+0*k)),z(2*(j+1*k)),
& z(2*(j+2*k)),z(2*(j+3*k)),
& s(2*(4*j+0)),s(2*(4*j+1)),
& s(2*(4*j+2)),s(2*(4*j+3)),
& w1r,w1i,w2r,w2i,w3r,w3i)
enddo
i = i + 1
m = m * 4
k = k / 4
endif
c ...
return
end
|
The loop in Example 5-30 contains two subroutine calls whose code is shown in Example 5-31.
Example 5-31. Subroutine Candidates for Inlining
subroutine load4 ( w, iw, w1r, w1i, w2r, w2i, w3r, w3i )
real*8 w(0:5), w1r, w1i, w2r, w2i, w3r, w3i
integer iw
c
w1r = w(0)
w1i = w(1)
w2r = w(2)
w2i = w(3)
w3r = w(4)
w3i = w(5)
iw = iw + 6
return
end
c---------------------------------------------------------------------
subroutine radix4pa ( c0, c1, c2, c3, y0, y1, y2, y3,
& w1r, w1i, w2r, w2i, w3r, w3i )
real*8 c0(0:1), c1(0:1), c2(0:1), c3(0:1)
real*8 y0(0:1), y1(0:1), y2(0:1), y3(0:1)
real*8 w1r, w1i, w2r, w2i, w3r, w3i
c
real*8 d0r, d0i, d1r, d1i, d2r, d2i, d3r, d3i
real*8 t1r, t1i, t2r, t2i, t3r, t3i
c
d0r = c0(0) + c2(0)
d0i = c0(1) + c2(1)
d1r = c0(0) - c2(0)
d1i = c0(1) - c2(1)
d2r = c1(0) + c3(0)
d2i = c1(1) + c3(1)
d3r = c3(1) - c1(1)
d3i = c1(0) - c3(0)
t1r = d1r + d3r
t1i = d1i + d3i
t2r = d0r - d2r
t2i = d0i - d2i
t3r = d1r - d3r
t3i = d1i - d3i
y0(0) = d0r + d2r
y0(1) = d0i + d2i
y1(0) = w1r*t1r - w1i*t1i
y1(1) = w1r*t1i + w1i*t1r
y2(0) = w2r*t2r - w2i*t2i
y2(1) = w2r*t2i + w2i*t2r
y3(0) = w3r*t3r - w3i*t3i
y3(1) = w3r*t3i + w3i*t3r
return
end
|
Both subroutines are straight-line code. Having this code isolated in subroutines undoubtedly makes the source code easier to read and to maintain. However, inlining this code reduces function call overhead; more important, inlining allows the calling loop to software pipeline.
If all the code is contained in the file fft.f, you can inline the calls with the following compilation command:
% f77 -n32 -mips4 -O3 -r10000 -OPT:IEEE_arithmetic=3:roundoff=3 -INLINE:must=load4,radix4pa -flist -c fft.f |
(Here, -O3 is used instead of -Ofast because the latter would invoke -IPA to inline the subroutines automatically.) The -flist flag tells the compiler to write out a Fortran file showing what transformations the compiler has done. This file is named fft.w2f.f (w2f stands for WHIRL-to-Fortran). You can confirm that the subroutines were inlined by checking the w2f file. It contains the code shown in Example 5-32.
Example 5-32. Inlined Code from w2f File
k = (n / 4)
IF(k .GT. 1) THEN
_ab0 = ((n / 4) + -1)
DO j = 0, _ab0, l
d0r = (z((j * 2) + 1) + z(((j +(k * 2)) * 2) + 1))
d0i = (z((j * 2) + 2) + z(((j +(k * 2)) * 2) + 2))
d1r = (z((j * 2) + 1) - z(((j +(k * 2)) * 2) + 1))
d1i = (z((j * 2) + 2) - z(((j +(k * 2)) * 2) + 2))
d2r = (z(((k + j) * 2) + 1) + z(((j +(k * 3)) * 2) + 1))
d2i = (z(((k + j) * 2) + 2) + z(((j +(k * 3)) * 2) + 2))
d3r = (z(((j +(k * 3)) * 2) + 2) - z(((k + j) * 2) + 2))
d3i = (z(((k + j) * 2) + 1) - z(((j +(k * 3)) * 2) + 1))
t1r = (d1r + d3r)
t1i = (d1i + d3i)
t2r = (d0r - d2r)
t2i = (d0i - d2i)
t3r = (d1r - d3r)
t3i = (d1i - d3i)
s((j * 8) + 1) = (d0r + d2r)
s((j * 8) + 2) = (d0i + d2i)
s((j * 8) + 3) = ((w((j * 6) + 1) * t1r) -(w((j * 6) + 2) * t1i))
s((j * 8) + 4) = ((w((j * 6) + 2) * t1r) +(w((j * 6) + 1) * t1i))
s((j * 8) + 5) = ((w((j * 6) + 3) * t2r) -(w((j * 6) + 4) * t2i))
s((j * 8) + 6) = ((w((j * 6) + 3) * t2i) +(w((j * 6) + 4) * t2r))
s((j * 8) + 7) = ((w((j * 6) + 5) * t3r) -(w((j * 6) + 6) * t3i))
s((j * 8) + 8) = ((w((j * 6) + 5) * t3i) +(w((j * 6) + 6) * t3r))
END DO
ENDIF
RETURN
|
There are two other ways to confirm that the routines have been inlined:
Use the option -INLINE:list to instruct the compiler to print out the name of each routine as it is being inlined.
Check the performance to verify that the loop software pipelines (you cannot check the assembler file because the -S option disables IPA).
Automatic inlining is a feature of IPA. The compiler performs inlining on must subroutine calls, but no longer considers inlining to be beneficial when it increases the size of the program by 100% or more, or if the extra code causes the Olimit option to be exceeded. This option specifies the maximum size, in basic blocks, of a routine that the compiler will optimize. Generally, you do not need to worry about this limit because, if it is exceeded, the compiler will print a warning message instructing you to recompile using the flag -OPT:Olimit=nn.
If one of these limits is exceeded, IPA will restrict the inlining rather than not do any at all. It decides which routines will remain inlined on the basis of their location in the call hierarchy. Routines at the lowest depth in the call graph are inlined first, followed by routines higher up in the hierarchy. This is illustrated in Figure 5-2.
The call tree for a small program is shown on the left. At the lowest depth, leaf routines (those that do not call any other routine) are inlined. In Figure 5-2, the routine E is inlined into routines D and C. At the next level, D is inlined into B and C is inlined into A. At the last level, which for this program is the top level, B is inlined into A. IPA stops automatic inlining at the level that causes the program size to double, or the level that exceeds the Olimit option.
You can increase or decrease the amount of automatic inlining with these three options:
-IPA:space=n | The largest acceptable percentage increase in code size. The default is 100 (100%). |
-IPA:forcedepth=n | All routines at depth n or less in the call graph must be inlined, regardless of the space limit. |
-IPA:inline=off | Turns off automatic inlining altogether. |
Automatic inlining inlines the calls to load4 and radix4pa in Example 5-30. But because most of IPA's actions are not performed until the link stage, you don't get a .w2f file with which to verify this until the link has been completed.
The -INLINE:must and -INLINE:never flags work in conjunction with automatic inlining. To block automatic inlining of specific routines, name them in an -INLINE:never list. To require inlining of specific routines regardless of code size or their position in the call graph, name them in an -INLINE:must list.
The -IPA option, whether given explicitly on compile and link lines or implicitly via -Ofast, is designed to work fairly automatically. Nevertheless, you can do a few things to enhance interprocedural analysis.
IPA needs to know which routines are being called in order to do its analysis, so it is limited by programming constructs that obscure the call graph. The use of function pointers, virtual functions, and C++ exception handling are all examples of things that limit interprocedural analysis.
The optimizations that IPA performs other than inlining should always benefit performance. Although inlining can often significantly improve performance, it can also hurt it, so it pays to experiment with the flags available for controlling automatic inlining.
This chapter has explored the concepts of SWP and IPA, and shown how these optimizations are constrained by the compiler's need to always generate code that is correct under the worst-case assumptions, with the result that opportunities for faster code are often missed. By giving the compiler more information, and sometimes by making minor adjustments in the source code, you can get the tightest possible machine code for the innermost loops.
The code schedule produced by pipelining does not take memory access delays into account. Cache misses and virtual page faults can destroy the timing of any code schedule. Optimizing access to memory takes place at a higher level of optimization, discussed in the next chapter.