This chapter explains how to determine what is limiting the performance of your Open Inventor application, and provides suggestions on how to improve its performance.
| Note: This chapter was previously available as a small booklet. The information has been updated to Inventor 2.1 as appropriate. |
The chapter discusses the following topics:
“Benchmarking Tips”—Describes a process for effectively investigating and improving performance—discovering where an application is spending its time is not a matter of random trial and error.
“Optimizing Rendering”—Provides for each step in the rendering process:
Information about that step.
A method for determining how much time your application is spending in that step.
Techniques for reducing that time.
“Optimizing Everything Else”—Suggests ways of structuring your scene and application for maximum performance when doing tasks other than rendering (for example, picking or modifying the scene).
For more information on Open Inventor programming in general and on specific nodes, see The Inventor Mentor.
Like fixing bugs or eliminating memory leaks, performance tuning is a necessary chore during application development. Proper organization and planning can speed up this chore and make it more pleasant.
This section looks at the steps to take when optimizing your application. discussing these topics:
Finally, measuring your application against your goal again and repeating steps 2, 3 and 4 above until performance meets your goal (see “Are You Finished Yet?”).
Setting a performance goal helps you use your time wisely. Typically, you should decide on a desired frame rate, such as running at 20 frames per second with a particular scene. A reasonable performance goal for interactive programs is a frame rate of at least 10 frames per second. Most users find that frame rate acceptable for most tasks (more is always better, of course).
When setting a goal, keep in mind the capabilities of your hardware. If the absolute top speed for drawing polygons on your system is 60,000 unlit, single-color triangles per second, don't try to get 10 frames per second while drawing 6,000 lit, color-per-vertex triangles. Write short OpenGL benchmark programs, or feed test scene graphs to ivview -p to help set your expectations.
It is important to have an objective way of measuring your application's performance. You're likely to waste time on insignificant optimizations if you just watch your application run and try to see if it seems faster.
Adding code to your application that measures the number of polygons in your scene and how fast they are being rendered is fairly simple; see, for example, the source code for ivview in /usr/share/src/Inventor/tools/ivview.
The osview utility can also be useful. The “swapbuf” number in the Graphics section tells you how many frames per second your application is getting (assuming that your application is double-buffered, and that it is the only double-buffered application running).
| Note: Don't confuse osview with its graphical counterpart, gr_osview, which doesn't have this feature. |
Be sure to keep good records of your application's performance before you start optimization. Comparing “before” and “after” performance numbers ensures that you are not making things worse.
Most applications spend most of their time executing a small part of the code. Optimizing a procedure that is taking up only 5% of the total time is probably not worthwhile: even if you manage to double the performance of the procedure, the application will speed up by only 2.5%. In fact, on some systems graphical operations can occur in parallel. For example, filling in polygons and transforming polygon vertices might occur at the same time. If the bottleneck is in the vertex transformation stage, increasing the pixel fill time may not increase performance at all! Find the bottlenecks first, and then work on improving them.
Finding bottlenecks is an experimental science. You should first come up with a theory on where the bottleneck might be, then devise an experiment that proves or disproves that theory. Create experiments that isolate one small part of your application's performance, and make sure you understand what you are measuring every time you run an experiment.
“Optimizing Rendering” and “Optimizing Everything Else” describe frequently encountered bottlenecks, show how to determine the amount of time your application is spending in each of them, and give suggestions on improving them. The following topics are discussed:
Feel free to start with bottlenecks you suspect are responsible for the most noticeable slowdown. You can look at the sections in any order; just make sure you always know what you are measuring and keep good records of your experiments.
When you apply a performance optimization, make sure that the modification is really an improvement: don't assume that all the suggestions made in this (or any other) document automatically apply to your application. For example, render culling usually increases performance. However, if you have an application in which all objects are always visible, render culling actually hurts performance.
Again, keep good records. Record what you do and how much it improves performance. Try to minimize the number of things you change at any one time; for example, if you make two “optimizations” and performance goes up by 10%, the speedup might be caused by a 5% improvement for each optimization, or might be caused by a 100% speedup caused by one optimization and a 90% slowdown caused by the other! It is tempting to read a document like this, make lots of changes, then see if the application gets faster. This not only wastes time, it can also be counter-productive.
One of the most frustrating things about optimizing an application's performance is that it can be difficult to determine when you are done. Once you have successfully eliminated one bottleneck, something else becomes the factor limiting performance. Before spending more time on optimization, you should ask yourself:
Did you meet your performance goal? If you did, go home early. If not, try to find other bottlenecks, consider eliminating features that hurt performance, or reexamine your goals.
Is your application running at 60 or 72 frames per second? Double-buffered programs never render faster than the refresh rate of your monitor.
Do you need to experiment on different systems? Different systems have different bottlenecks; on a system with very fast graphics, the bottleneck is more likely to be either in the application's code or in Inventor's code. On a system with slow graphics and a fast CPU, the bottleneck is more likely to be inside the OpenGL calls. If your application will be used on different types of systems, make sure performance is acceptable on all of them.
The main goal of performance tuning is to make the application look and feel faster. However, just because the goal is to make the application render faster, don't assume that rendering is the bottleneck.
To find out whether rendering is the problem, modify your application so that it does everything it normally does except render, and then measure its performance. An easy way of getting your application to do everything but rendering is to insert an SoSwitch node with its whichChild field set to SO_SWITCH_NONE (the default) above your scene. So, for example, modify your application's code from:
myViewer->setSceneGraph(root); |
To:
SoSwitch *renderOff = new SoSwitch; renderOff->ref(); renderOff->addChild(root); myViewer->setSceneGraph(renderOff); |
This experiment gives an upper limit on how much you can improve your application's performance by increasing rendering performance. If your application doesn't run much faster after this change, then rendering is not your bottleneck. See “Optimizing Everything Else” for information on optimizing the rest of your application.
If you have determined that your application is spending a significant amount of time rendering the scene, the next step is to isolate rendering from the rest of the things your application does. This makes it easier to find out where the bottleneck in rendering occurs. The easiest way to isolate rendering is to write your scene to a file and then use the ivperf program to perform a series of rendering experiments.
The code for writing your scene may look like the following:
SoOutput out;
if (!out.openFile(“myScene.iv”)) { ... error ... };
SoWriteAction wa(&out);
wa.apply(root);
|
The ivperf utility reads in a scene graph and analyzes its rendering performance. It estimates the time spent in each stage of the rendering process while rendering the scene graph.
The process of rendering a single frame can be decomposed into five main stages:
Clearing the graphics window
Traversing the Inventor scene graph
Changing the graphics state (including materials, transformations, and textures)
Transforming vertices in the graphics pipeline
Filling polygons
The sum of the times spent in these stages does not, in general, equal the total time it takes to render the scene. Depending on the underlying hardware platform and graphics pipeline, some or all of the above can overlap with each other. Thus, completely eliminating one of the stages does not necessarily speed up the application by the time taken by that stage. ivperf takes this into account; it answers questions of the type “if I could completely eliminate xxx from my scene, how much faster would rendering be?” For example, if ivperf indicates that 50% of your time is spent changing the material graphics state, then making your entire scene a single material would make it render twice as fast. Knowing that materials are taking up a significant part of your rendering time, you can then concentrate on minimizing the number of material changes made by your scene.
If you have created your own node classes, either create DSO's for them (see “DSO Directories and Versions”) or call their initClass() methods just after the call to SoInteraction:init() in the ivperf source and link their .o files into ivperf.
The camera control used by ivperf is simplistic: it calls viewAll() for the scene and just spins the scene around in front of the camera when benchmarking. If you have a sophisticated walk-through or fly-through application that uses level of detail and/or render culling, modify ivperf so that its camera motion is more appropriate for your application. For example, have ivperf use the following little scene instead of just SoPerspectiveCamera:
TransformSeparator {
Rotor { rotation 0 1 0 .1 speed .1 }
Translation { translation 100 0 0 }
PerspectiveCamera { nearDistance .1 farDistance 600 }
}
|
ivperf correctly reports the performance of changing scenes, as long as you give it enough information. It automatically deals with scenes containing engines and animation nodes, but if you are using an SoSensor to modify the scene, you should mark nodes that your application frequently changes by giving them the special name “NoCache.” For example, if your application is frequently changing a transformation in the scene, the transformation should appear in the file given to ivperf as:
DEF NoCache Transform { }
|
The first step in the rendering process is clearing the window. It is easy to forget this step, but depending on the size of your application's window and the type of system you are running on, clearing the window can take a surprisingly long time. If your application's main window is typically 1000 by 1000 pixels, run ivperf like this:
ivperf -w 1000,1000 myScene.iv |
ivperf performs many different rendering experiments, and eventually prints information on each rendering stage.
For example, on an Indigo2™ Extreme™ running IRIX 5.3, ivperf reports that for rendering a simple cube in a 1000 by 1000 pixel window 46% of the time is spent clearing the window.
Unfortunately, if clearing the window takes too much time, there is not a lot you can do. One possibility is to make the window's default size smaller (while still allowing users to resize the window if necessary).
After running ivperf, you know how much time your application spends clearing the color and depth buffers. The next experiment is designed to find out how much time Inventor spends traversing your scene. Traversal is the process of walking through the scene graph, deciding which render method needs to be called at each node. Inventor automatically caches the parts of your scene that aren't changing and that are expensive to traverse, building an OpenGL display list and eliminating the traversal overhead.
If most of your scene is changing, or if your scene is not organized for efficient caching, Inventor may not be able to build render caches, and traversal might be the bottleneck in your application. ivperf measures the difference between rendering your scene with nothing changing, and rendering with the camera, engines, and nodes named “NoCache” changing.
If traversing the scene is a bottleneck in your program, there are several ways of reducing the traversal overhead:
Reduce the number of nodes in the scene. For example, eliminate SoSeparator and SoGroup nodes that have only one child by replacing them with the child.
Use the vertexProperty field of the vertex-based shapes to specify coordinates, normals, texture coordinates, and colors. (See “SoVertexProperty Node”).
Beware of features that require multiple traversals of the scene graph for each render update. For example, avoid using accumulation buffer antialiasing and SoAnnotation nodes, and use the transparency type SoGLRenderAction::SCREEN_DOOR.
Organize your scene graph for caching. The next section discusses ways of doing this. If you are using SoLOD nodes or render culling, also see “Correcting Culling Bottlenecks” and “Correcting Level of Detail Bottlenecks” for hints on optimizing those features, which ivperf also reports as part of caching behavior.
You may be able to organize your scene so that Inventor can build and use render caches even if part of the scene is changing. Note that the following things inhibit caching:
Changing fields in the scene destroys caches inside all SoSeparator nodes above the node that changed. Even fields that do not affect rendering, such as fields in the SoLabel or SoPickStyle nodes, destroy caches if they are changed.

Tip: You can disable notification on these nodes using the SoNode::enableNotify() method to keep changes to them from destroying caches. The SoLOD node (and the older SoLevelOfDetail node) breaks caches above it whenever either the camera or any of the matrix nodes affecting it change. Make the children of the SoLOD node SoSeparator nodes, so that they will be cached. See “Correcting Level of Detail Bottlenecks” for more information on efficient use of the SoLOD node.
Any shape using SCREEN_SPACE complexity breaks caches above it whenever the camera or any of the matrix nodes affecting it change.
The SoText2 node breaks caches above it whenever the camera changes (in order to correctly position and justify each line of text, it must perform a calculation based on the camera). Since most applications change the camera frequently, try to separate SoText2 nodes from the other objects in your scene, to allow the other objects to be cached.
Tip: In Inventor 2.1, single-line, left-justified SoText2 nodes do not break render caches. Changing the override status of properties at the top of the scene, or changing global properties such as SoDrawStyle or SoComplexity that affect the rest of the scene, inhibits efficient caching. SoSeparator nodes build multiple render caches (by default, a maximum of two) to handle cases in which a small set of global properties are changed back and forth, but you should avoid continuously changing a global property; for example, putting an engine on the value field of an SoComplexity node at the top of your scene is bad for caching.
For more information on Inventor's render caching, see Chapter 9 of The Inventor Mentor.
If ivperf reports that material changes are the rendering bottleneck, try the following:
Use fewer material nodes. Group objects by material, and use one material node for several objects.
Tip: When the ivfix utility rearranges scene graphs, it groups objects by material. Changing between materials with different shininess values is much more expensive than changing any of the other material properties.
If you are using shapes with a materialIndex field, try to sort their parts by material index to minimize material changes. For example, try to change:
IndexedFaceSet { materialIndex [ 0,1,0,1,0,1,0,1 ] ... }to:
IndexedFaceSet { materialIndex [ 0,0,0,0,1,1,1,1 ] ... }This works only for PER_PART_INDEXED or PER_FACE_INDEXED material bindings.
For transformation, ivperf reports two numbers: the overhead of changing the OpenGL transformation matrix between rendering shapes and the time it takes to transform the vertices in your scene through that matrix. This section helps with the former, giving suggestions on how to make Inventor execute fewer OpenGL matrix operations. See “Optimizing Vertex Transformations” for hints on optimizing the transformation of vertices.
To measure how much time transformations might be taking, ivperf temporarily removes all transformations from your scene and then measures how much faster it runs. Beware! This sometimes gives unreliable results; for example, if all your objects become very large or very small without the transformations, then more (or less) time may be spent filling in pixels. If your scene uses render culling, removing the transformations makes more (or fewer) of the objects culled, distorting the results reported by ivperf.
Use SoRotation, SoRotationXYZ, SoScale, or SoTranslation nodes instead of the general SoTransform node. However, don't bother doing this if you have to replace the SoTransform node with more than one of the simpler nodes to get the same transformation.
For best performance when creating SoFaceSet and SoIndexedFaceSet shapes, arrange all the triangles first, then quads, and then other faces.
If your scene contains textures, ivperf reports two numbers: the time you would save if you could turn off textures completely, and the time you would save if you could make your scene use only one texture. On systems with texturing hardware, the number of textures used can dramatically affect performance; see “Optimizing Texture Management” for hints on optimizing texture management. On systems without texture mapping hardware, the bottleneck is probably filling in the textured polygons.
Inventor 2.1 automatically does two things to speed up rendering on systems without texture mapping hardware:
Inventor's viewers display the scene untextured during interaction by default.
Inventor uses lower-quality filters for minifying or magnifying textures.
If ivperf reports a lot of time is spent in texture management, then you are running out of hardware texture memory. Try the following:
Use smaller textures. Use the izoom utility to scale down the images you are using; inadvertently using one big image can easily fill up texture memory on many systems.
Make textures a power of 2 wide and high. Textures of those dimensions (for example 128 x 64 instead of 129 x 70) make startup faster.
Reuse nodes. Inventor allows you to modify a texture once it has been read into your application (using the image field of SoTexture2), and to change the search path for textures (using methods on SoInput). It therefore does not use the same texture memory for two different SoTexture2 nodes with the same filename field. Be sure to reuse the same SoTexture2 node instead of creating another node with the same filename.
For example, this scene is inefficient:
Separator { Texture2 { filename foo.rgb } Cube { } } Sphere { } Separator { Texture2 { filename foo.rgb } Text3 { string “Hello” } }This scene uses texture-memory efficiently:
Separator { DEF foo Texture Texture2 { filename foo.rgb } Cube { } } Sphere { } Separator { USE foo Text3 { string “Hello” } }Textures are not shared if they are below an SoSeparator with renderCaching turned on. Textures use less texture memory by building an OpenGL display list or texture object containing the OpenGL texture commands. However, if an OpenGL display list is already created the first time an SoTexture2 node is traversed, it must add the texture commands to the already open display list. Inventor's automatic caching algorithm handles this correctly; it is only a problem if you turn caching on explicitly. For example, this scene uses twice as much texture memory with the renderCaching field of the SoSeparator set to ON:
Separator { renderCaching ON # BAD DEF TEX Texture2 { filename foo.rgb } Cube { } ... more stuff, other textures, etc... USE TEX Cube { } }Use SoLOD nodes to create simpler versions of your objects that are not textured or use smaller texture images when the objects are far away.
Use render culling so the textures for textured objects outside the view volume are not used. For example, imagine a scene that contains 100 textured objects (each with a unique texture), but only 10 of them are in the view volume at any given time. When the scene is rendered, only 10 of the textures need to be in texture memory at any given time, resulting in much better texture management performance.
If the scene given to ivperf contains light sources, ivperf informs you how expensive they are compared to rendering your scene with just a single directional light. If ivperf reports that lights are a significant performance bottleneck, try to use fewer light sources, and use simpler lights (a DirectionalLight is simpler than a PointLight, which is simpler than a SpotLight). If possible, put lights inside separators so that they affect only part of the scene, increasing performance for the rest of the scene.
If ivperf reports that vertex transformations (which include per-vertex lighting calculations) take up a significant portion of the time it takes to render a frame, you can do the following to optimize per-vertex operations:
Use fewer vertices in your objects. Use SoComplexity to turn down complexity for Inventor's primitive objects. If you are using a system with hardware-accelerated texturing, texturing can be used to add visual complexity with very few vertices.
Create less detailed versions of your objects and use SoLOD nodes so that fewer vertices are drawn when objects are small. Use an empty SoInfo node as the lowest level of detail so that objects disappear when they get very small. A good rule of thumb for choosing levels of detail is that the switch between levels of detail should be fairly obvious if you are concentrating on the object; for most applications, the user concentrates on objects in the foreground and does not notice background objects “popping” between levels of detail. Beware that SoLOD nodes cause smaller caches to be built, which may slow down traversal. See “Correcting Level of Detail Bottlenecks” for more information on efficient use of level of detail.
Make your vertices simpler. Try to use OVERALL rather than PER_VERTEX material binding. Turn off fog. Note that these suggestions are system-specific; on systems with a lot of hardware for accelerated rendering, fogged vertices may be no slower than plain vertices. Be sure to do a quick ivperf test before spending time modifying your application.
Make sure you are not turning on two-sided lighting unnecessarily; avoid SoShapeHints nodes that:
set vertexOrdering fields to COUNTERCLOCKWISE or CLOCKWISE and
set shapeType fields to UNKNOWN_SHAPE_TYPE
If parts of your scene do not require lighting, use an SoLightModel node set to model BASE_COLOR to turn off lighting for those parts of the scene. However, be aware that turning lighting on and off can itself become a bottleneck if done too often.
If you are using SoFaceSet or SoIndexedFaceSet, try using ivfix to convert them into SoIndexedTriangleStripSet, which draws more triangles with fewer vertices. Note that ivfix cannot create a mesh if your objects have sharp facets or PER_FACE material or normal bindings.
Watch out for expensive primitives with lots of vertices, like SoText3 and SoSphere. ivperf reports the number of triangles in your scene; make sure the number is reasonable for your desired performance.
Organize your scene graph so that objects that are close to each other spatially are under the same SoSeparator, and turn on render culling so that Inventor won't send those objects' vertices when the objects are not in view. See The Inventor Mentor, Chapter 9, for more information on render culling.
See “Making Inventor Produce Efficient OpenGL” for hints on making Inventor produce more efficient OpenGL calls.
A common bottleneck on low-end systems is drawing the pixels in filled polygons. This is especially common for applications that have just a few large polygons, as opposed to applications that have lots of little polygons.
If ivperf reports that a large percentage of each frame is spent filling in pixels, try to optimize your scene as follows:
Render your scene, or parts of your scene, in wireframe or as points when possible. Viewers have “move wireframe” and “move points” modes built in for exactly this case.
Some systems can fill flat-shaded polygons faster that Gouraud-shaded polygons. Triangle strips and quad meshes set shademodel(FLAT) if they have PER_FACE normals and don't have PER_VERTEX materials (and vice versa).
SCREEN_DOOR transparency (the default) is faster than blended transparency on some systems (it is slower on other systems). Use the setTransparencyType() method on either SoXtRenderArea or SoGLRenderAction to change the transparency type.
There are several performance problems that ivperf doesn't catch. The following sections describe them, and give hints on how to improve them.
If your application is rendering only 10 frames per second with 1,000 triangles per frame, and you know that your graphics hardware is capable of rendering 100,000 triangles per second (10,000 triangles per frame at 10 frames/second), and ivperf reports that your bottleneck is vertex transformations, then your problem might be that Inventor is not making efficient OpenGL calls.
Inventor is much more efficient at rendering multiple triangles if they are all part of one node. For example, you can create a multifaceted polygonal shape using a number of different coordinate and face set nodes, as shown in the lower half of Figure 6-1. A much better technique is to put all the coordinates for the polygonal shape into one SoCoordinate or SoVertexProperty node, and the description of all the face sets into a second SoFaceSet node, as shown in the upper half of Figure 6-1.
| Tip: The ivfix utility program collapses multiple shapes into single triangle strip sets. |
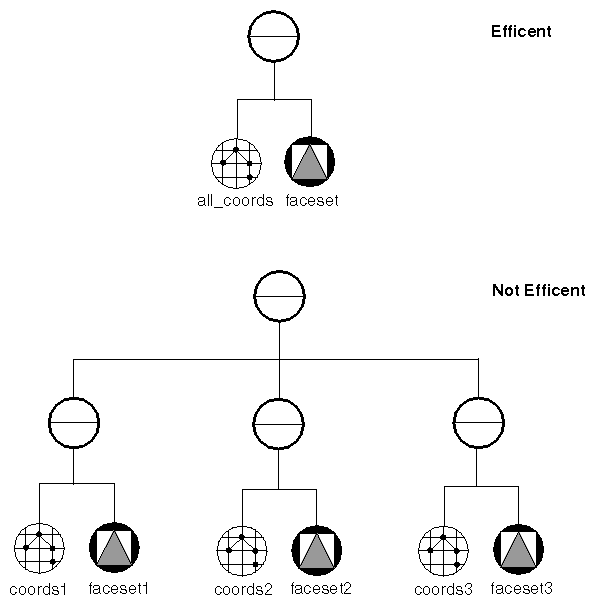
Using fewer nodes to get the same picture reduces traversal overhead for scenes that cannot be cached. Note also that Inventor optimizes on a node by node basis and generally can't optimize across nodes.
An SoFaceSet or SoIndexedFaceSet has special code for drawing 3 and 4-vertex polygons. To take advantage of that, you must arrange the polygons so that the 3-vertex polygons (if any) are first in the coordIndex array, followed by the 4-vertex polygons, followed by the polygons with more than 4 vertices.
For some applications, consider implementing your own nodes that implement the functionality of a subgraph of your scene. For example, a molecular modeling application might implement a BallAndStick node with fields specifying the atoms and bonds in a molecule, instead of using the more general SoSphere, SoCylinder, SoMaterial, SoTransform, and SoGroup nodes. If the molecular modeling application changes the molecule frequently so Inventor cannot cache the scene, using a specialized node could make traversal orders of magnitude faster (for example, a simple water molecule scene graph with three atoms and two bonds might consist of 20 nodes; replacing this with a single BallAndStick node would make traversal 20 times faster). The BallAndStick node could also perform application-specific optimizations not done by Inventor, such as not drawing bonds between spheres whose radii were large enough that they intersected, sorting the spheres and cylinders by color, and so on. See The Inventor Toolmaker for complete information on implementing your own nodes.
If your application uses render culling, it may be spending most of its time deciding whether or not objects should be culled. ivperf lumps this in with bad caching behavior. To find out whether this is the case, use prof, pixie, or the CaseVision™/WorkShop Performance Analyzer tools to look for a lot of CPU time being spent in the SoSeparator::cullTest() or SoBoundingBoxAction::apply() routines. See the reference pages for prof, pixie, or cvspeed for information on using these tools.
If a large percentage of the rendering time is spent doing cull tests, try to reorganize your scene so that more triangles are culled for each culling SoSeparator. For example, if you have a city scene with thousands of buildings, it may be better to perform one cull test for each city block rather than the thousands of cull tests needed to decide whether or not each individual building is visible. Doing this also allows Inventor to build larger render caches, which may increase traversal speed.
Also, remember that render culling breaks render caches when the camera or transformation matrices change, so double-check to make sure that no SoSeparator nodes above an SoSeparator doing render culling have their renderCaching fields set to ON.
If a lot of time is being spent inside SoGetBoundingBoxAction::apply(), something is breaking bounding box caches.
If your application uses SoLOD nodes, it might be spending a significant amount of time deciding which level of detail should be drawn. One way of testing to see if this is the case is to temporarily replace all of the SoLOD nodes in your scene with SoSwitch nodes set to traverse the highest level of detail. Then run ivperf again and compare the results. If the SoSwitch node scene is much faster, try doing the following:
Try to group objects so that one level of detail test determines the level of detail for several objects. For example, if you have a group of 10 buildings that are near each other, use one level of detail node instead of 10 level of detail nodes. Doing this also makes it easier for Inventor to build larger render caches, which may increase performance by increasing traversal speed.
Remember that level of detail nodes break render caches when the camera or transformation matrices change, so make sure that no SoSeparator nodes above an SoLOD have their renderCaching fields set to ON.
Make sure you use the SoLOD node introduced in Inventor 2.1 instead of the SoLevelOfDetail node. The SoLOD node is more efficient because it uses the distance to a point as the switching criterion. See the reference page for more detail.
Sometimes it is worthwhile to sacrifice features temporarily to make your application seem faster to the user. Inventor has several features that make this easier:
Use the SoGLRenderAction::setAbortCallback() method to interrupt rendering before the entire scene has been drawn. For this to be most effective, you must organize your scene so that the most important objects are drawn first, and you should abort only when it is important that rendering happen quickly, even if the rendering is not complete, such as when the user is interactively manipulating the scene.
Use one of the “Move ...” draw styles if you are using a viewer, so that a simpler version of the scene is drawn when the user is interacting with the viewer.
Use the start and finish callbacks of manipulators and components to temporarily modify the scene to make it simpler while the user is interacting with it.
If you have determined that rendering is not your bottleneck, or if you have already optimized rendering as much as possible and a significant amount of time is still being spent doing something other than rendering, it's time to look for other bottlenecks. This section helps you find other bottlenecks, and suggests Inventor-specific things to look for by discussing the following:
The standard performance analysis tools (prof, pixie, or the CaseVision/WorkShop Performance Analyzer) make performance analysis of the non-graphics part of your application easy. See the reference pages for prof, pixie, or cvspeed for information on using these tools.
First, make sure your application isn't running out of physical memory by running gr_osview with the -a flag and looking for “swap” in the “CPU Wait” usage bar. If your application is swapping, try to reduce its memory usage as follows:
Turn off render caching. Call SoSeparator::setNumRenderCaches(0) just after initializing Inventor to globally turn off automatic render caching. You can also turn off render caching for parts of your scene using the renderCaching field of SoSeparator.
The automatic caching algorithm in Inventor 2.1 avoids caching notes that contain a large number of polygons.
If you are using caching, avoid using PER_FACE or PER_FACE_INDEXED materials or normal bindings for SoTriangleStripSet, SoIndexedTriangleStripSet, and SoQuadMesh nodes. FACE bindings force Inventor to break each triangle or quad into an individual triangle or quad, more than doubling the space the node takes in the render cache.
If you have SoBaseColor or SoMaterial nodes containing just diffuse colors, change them to SoPackedColor nodes, which use less memory.
Use instancing instead of duplicating geometry or properties wherever possible. Instancing makes your scene graph take up less memory and enables Inventor to build OpenGL display lists that are used more than once. This is especially important for SoTexture2 nodes.
If memory is not the problem, start by looking at “inclusive” CPU times for your procedures (inclusive times include time spent in that procedure and all procedures it calls; exclusive times are just the time spent in that procedure). Ignore the very highest level routines like main() or SoXt::mainLoop(); look for Inventor beginTraversal() methods or for application routines that are taking a significant percentage of time. If a lot of time is spent in SoGLRenderAction::beginTraversal(), see “Optimizing Rendering” for information on improving rendering performance.
If your application is spending a lot of time in code written by you, you are on your own! The rest of this section describes Inventor routines that often show up on profile traces, describes what these routines do, and suggests ways of using them more efficiently.
Inventor actions perform a lot of work the first time they are applied to a scene (subsequent traversals are very fast). Therefore, if your performance traces show a lot of time being spent inside an action's constructor or the SoAction::setUpState() method, try to create an action once and reapply it instead of constructing a new action. For example, if you often compute the bounding boxes of some objects in the scene, keep an instance of an SoBoundingBoxAction around that is reused:
static SoGetBoundingBoxAction *bbAction = NULL; if (bbAction == NULL) bbAction = new SoGetBoundingBoxAction; bbAction->apply(myScene); |
instead of the much less efficient:
SoGetBoundingBoxAction bbAction;
// inefficient if called a lot!
bbAction.apply(myScene);
|
Every time you change a field in the scene, Inventor performs a process called notification. A notification message travels up the scene graph to the node's parents, scheduling sensors, causing caches to be destroyed, and marking any connections to engines or other fields as needing evaluation.
If your performance traces show a lot of time is being spent in a startNotify() method, try the following to decrease notification overhead:
If you are modifying several values in a multiple-valued field, use the setValues() methods or the startEditing()/finishEditing() methods instead of repeatedly calling the set1Value() method.
Build scenes from the bottom up. Set leaf nodes' fields first, then add them to their parents, then add the parents to their parents, and so on. For example, do this:
SoCube *myCube = new SoCube; c->width = 10.0; SoCylinder *myCylinder = new SoCylinder; myCylinder->radius = 4.0; SoSwitch *mySwitch = new SoSwitch; mySwitch->whichChild = 0; mySwitch->addChild(cube); mySwitch->addChild(cylinder); SoSeparator *root = new SoSeparator; root->ref(); root->addChild(mySwitch);
instead of the less efficient:
SoSeparator *root = new SoSeparator; root->ref(); SoSwitch *mySwitch = new SoSwitch; root->addChild(mySwitch); mySwitch->whichChild = 1; SoCube *myCube = new SoCube; mySwitch->addChild(myCube); myCube->width = 4.0; SoCylinder *myCylinder = new SoCylinder; mySwitch->addChild(myCylinder); myCylinder->radius = 4.0;
Using many path sensors can cause notification to become slow, since an SoPathSensor is notified whenever any change happens underneath the head node of the SoPath monitored by the SoPathSensor.

Note: SoPath itself does not have this problem in Inventor 2.X (but did in Inventor 1.X). Notification can be enabled or disabled on a per-node or per-engine basis. Beware that because caching, sensors, and connections rely on notification for proper operation, you must be very careful when using this feature. See the SoFieldContainer reference page for information on the enableNotify() method.
If your application profiles show a lot of time is spent inside the methods SoHandleEventAction::beginTraversal() or SoPickAction::beginTraversal(), try the following to improve picking and/or event handling performance:
Insert SoPickStyle::UNPICKABLE nodes in your scene to turn off picking for objects that should never be picked (for example “dead” background graphics).
Insert SoPickStyle::BOUNDING_BOX nodes in your scene if you do not need detailed picking information. This helps most for complicated objects like SoText3 or SoTriangleStripSets with many triangles.
If you have objects with a lot (thousands) of polygons in them, break them up into several objects under different separators, grouping polygons that are close to each other. This allows SoSeparator pick culling to quickly reject many of the triangles.
To speed up event handling, try to put active objects that respond to events toward the left and top of the scene graph. An SoHandleEventAction ends traversal as soon as a node reports that it has handled the event.
If you write your own event callback node, or implement a node that responds to events, be sure to use the grabEvents() method when appropriate. Because grabbing short-circuits traversal of the scene, it is a useful way to speed up event distribution.