The nodes in a FailSafe or CXFS cluster must act together to provide a service. To act in a coordinated fashion, each node must know about all the other nodes currently active and providing the service. The set of nodes that are currently working together to provide a service is called a membership. Cluster activity is coordinated by a configuration database that is replicated or at least accessible on all nodes in the cluster. The cluster software sends heartbeat messages between the nodes to indicate that a node is up and running. Heartbeat messages for each membership type are exchanged via a private network so that each node can verify each membership.
Nodes within the cluster must have the correct memberships in order to provide services. This appendix discusses the different types of membership and the effect they have on the operation of your cluster.
Nodes might not be able to communicate for reasons such as the following:
They are down
The communication daemons have failed or have been turned off
Software has not been configured, or has been misconfigured
The network is misconfigured (in this case, some heartbeat messages may fail while others succeed)
The network router or cable fails (in this case, all heartbeat messages will fail)
Nodes that cannot communicate must be excluded from the membership because the other nodes will not be able to verify their status.
It is critical that only one membership of each type exist at any one time, as confusion and corruption will result if two sets of nodes operate simultaneously but independently. There is a risk of this happening whenever a segmentation of the private network occurs, or any other network problem occurs that causes the nodes eligible for membership to be divided into two or more sets, where the nodes in each set can communicate with themselves, but not with nodes outside of the set. Thus, in order to form a membership, the nodes must have a quorum, the minimum number of nodes required to form a membership. The quorum is typically set at half the total eligible members.
For example, consider the case of six nodes eligible for a membership:
If all six nodes can communicate with each other, they will form a membership of six and begin offering the membership's services.
If a network segmentation occurs that causes four nodes to be in one set and two in another set, the two-node set will try to form its own membership but will be unable to do so because it does not have enough nodes to form a quorum; these nodes will therefore stop offering services. The four-node set will be able to form a new membership of four nodes and will continue to offer the membership's services.
If a network segmentation occurs that divides the nodes into three sets of two nodes each, no set will be able to form a membership because none contains enough nodes to form a quorum. In this case, the membership services will be unavailable; this situation is unavoidable, as each set of two nodes thinks that the four other nodes may have formed a quorum, and so no set may safely offer the membership's services.
If a network segmentation occurs that divides the nodes into two sets of three, then both could have a quorum, which could cause problems. To prevent this situation from occurring, some memberships may require a majority (>50%) of nodes or a tiebreaker node to form or maintain a membership. Tiebreaker nodes are used when exactly half the nodes can communicate with each other.
The following sections provide more information about the specific requirements for membership.
| Note: Because the nodes are unable to distinguish between a network segmentation and the failure of one or more nodes, the quorum must always be met, regardless of whether a partition has actually occurred or not. |
There are three types of membership:
Each provides a different service using a different heartbeat. Nodes are usually part of more than one membership.
The nodes that are part of the the cluster database membership (also known as fs2d membership) work together to coordinate configuration changes to the cluster database:
The potential cluster database membership is all of the administration nodes (installed with cluster_admin and running fs2d) that are defined using the GUI or the cmgr command as nodes in the pool. (CXFS client-only nodes are not eligible for cluster database membership.)
The actual membership is the subset of eligible nodes that are up and running and accessible to each other, as determined by heartbeats on the private network. If the primary private network is unavailable, the cluster database heartbeat will failover to the next available heartbeat network defined for the node, if any (CXFS nodes are limited to a single heartbeat network).
The cluster database heartbeat messages use remote procedure calls (RPCs). Heartbeats are performed among all nodes in the pool. You cannot change the heartbeat timeout or interval.
If a node loses its cluster database membership, the cluster database write-operations from the node will fail; therefore, FailSafe and CXFS configuration changes cannot be made from that node.
The cluster database membership quorum ensures atomic write-operations to the cluster database that fs2d replicates in all administration nodes in the pool.
The quorum allows an initial membership to be formed when a majority (>50%) of the eligible members are present. If there is a difference in the membership log between members, the cluster database tiebreaker node is used to determine which database is replicated. (See “Cluster Database Membership Logs”.) The tiebreaker node is always the administration node in the membership with the lowest node ID; you cannot reconfigure the tiebreaker for cluster database membership.
When the quorum is lost, the cluster database cannot be updated. This means that FailSafe and CXFS configuration changes cannot be made; although FailSafe and CXFS may continue to run, the loss of the cluster database quorum usually results in the loss of quorum for FailSafe and/or CXFS, because the nodes that drop from the cluster database membership will probably also drop from other memberships.
The nodes that are part of the CXFS kernel membership can share CXFS filesystems:
The potential CXFS kernel membership is the group of all CXFS nodes defined in the cluster and on which CXFS services have been enabled. Nodes are enabled when CXFS services are started. The enabled status is stored in the cluster database; if an enabled node goes down, its status will remain enabled to indicate that it is supposed to be in the membership.
The actual membership consists of the eligible nodes on which CXFS services have been enabled and that are communicating with other nodes using the heartbeat/control network. CXFS supports only one private network, and that network is the only network used for CXFS kernel membership heartbeats (but remember that the CXFS nodes may use multiple networks for the cluster database membership heartbeats).

Note: CXFS metadata also uses the private network. The multiple heartbeats on the private network therefore reduce the bandwidth available for CXFS metadata.
During the boot process, a CXFS node applies for CXFS kernel membership. Once accepted, the node can actively share the filesystems in the cluster.
The CXFS heartbeat uses multicast. Heartbeats are performed among all CXFS-enabled nodes in the cluster.
If a node loses its CXFS kernel membership, it can no longer share CXFS filesystems.
The CXFS kernel membership quorum ensures that only one metadata server is writing the metadata portion of the CXFS filesystem over the storage area network:
For the initial CXFS kernel membership quorum, a majority (>50%) of the server-capable administration nodes with CXFS services enabled must be available to form a membership. (Server-capable administration nodes are those that are installed with the cluster_admin product and are also defined with the GUI or cmgr as capable of serving metadata. Client administration nodes are those that are installed with the cluster_admin product but are not defined as server-capable.)
Note: Client administration nodes and client-only nodes can be part of the CXFS kernel membership, but they are not considered when forming a CXFS kernel membership quorum. Only server-capable nodes are counted when forming the quorum.
To maintain the existing CXFS kernel membership quorum requires at least half (50%) of the server-capable nodes that are eligible for membership. If CXFS kernel quorum is lost, the shared CXFS filesystems are no longer available.
If you do not use serial hardware reset or I/O fencing to prevent a problem node from accessing I/O devices, you should set a CXFS tiebreaker node to avoid multiple CXFS kernel memberships in the event of a network partition. In CXFS, there is no default tiebreaker. Any node in the cluster can be a CXFS tiebreaker node. You can set the tiebreaker node by using the GUI's Set Tiebreaker Node task or by using the set tie_breaker command in cmgr.
| Note: Suppose you have a cluster with only two server-capable nodes with one of them being the CXFS tiebreaker node. If the tiebreaker node fails or if the administrator stops CXFS services on the tiebreaker node, the other node will not be able to maintain a membership and will do a forced shutdown of CXFS services, which unmounts all CXFS filesystems. |
If I/O fencing or serial hardware reset is used, the quorum is maintained by whichever side wins the reset/fence race.
If a tiebreaker node is set and the network being used for heartbeat/control is divided in half, only the group that has the CXFS tiebreaker node will remain in the CXFS kernel membership. Nodes on any portion of the heartbeat/control network that are not in the group with the tiebreaker node will exit from the membership. Therefore, if the heartbeat/control network is cut in half, you will not have an active metadata server on each half of the heartbeat/control network trying to access the same CXFS metadata over the storage area network at the same time.
| Note: A tiebreaker node must be configured individually for CXFS and for FailSafe. In a coexecution cluster, these could be different nodes. |
The nodes that are part of the FailSafe membership provide highly available (HA) resources for the cluster:
The potential FailSafe membership is the set of all FailSafe nodes that are defined in the cluster and on which HA services have been enabled. Nodes are enabled when HA services are started. The enabled status is stored in the cluster database; if an enabled node goes down, its status will remain enabled to indicate that it is supposed to be in the membership.
The actual membership consists of the eligible nodes whose state is known and that are communicating with other FailSafe nodes using heartbeat and control networks. If the primary private network is unavailable, the FailSafe heartbeat will failover to the next available heartbeat network defined for the node.
The FailSafe heartbeat uses user datagram protocol (UDP). Heartbeats are performed among all FailSafe-enabled nodes in the cluster. You can change the FailSafe heartbeat timing with the GUI Set FailSafe HA Parameters task or the cmgr command modify ha_parameters (the node_timeout parameter is the heartbeat timeout and the heartbeat is the heartbeat interval).
If a node loses its FailSafe membership, FailSafe will fail over its HA resources to another node in the cluster.
The FailSafe membership quorum ensures that a FailSafe resource is available only on one node in the cluster. The quorum requires that the state of a majority (>50%) of eligible nodes to be known and that half (50%) of the eligible nodes be present to form or maintain membership.
If a network partition results in a tied membership, in which there are two sets of nodes (each consisting of 50% of the potential FailSafe membership), then a node from the set containing the FailSafe tiebreaker node will attempt to perform a serial hardware reset on a node in the other set. Serial hardware reset is the failure action that performs a system reset via a serial line connected to the system controller.
If the node can verify that the other node was reset, then the membership will continue on the set with the tiebreaker. However, containing the tiebreaker is not a guarantee of membership; for more information, see the IRIS FailSafe Version 2 Administrator's Guide. The default FailSafe tiebreaker is the node with the lowest node ID in the cluster.
When FailSafe membership quorum is lost, the resources will continue to run but they are no longer highly available.
Each fs2d daemon keeps a membership log that contains a history of each database change (write transaction), along with a list of nodes that were part of the membership when the write transaction was performed. All nodes that are part of the cluster database membership will have identical membership logs.
When a node is defined in the database, it must obtain a current copy of the cluster database and the membership log from a node that is already in the cluster database membership. The method used to choose which node's database is replicated follows a hierarchy:
If the membership logs in the pool share a common transaction history, but one log does not have the most recent transactions and is therefore incomplete, the database from a node that has the complete log will be chosen to be replicated.
If there are two different sets of membership logs, the database from the set with the most number of nodes will be chosen.
If there are two different sets of membership logs, and each set has an equal number of nodes, then the set containing the node with the lowest node ID will be chosen.
To ensure that the complete transaction history is maintained, do not make configuration changes on two different administration nodes in the pool simultaneously. You should connect the CXFS or FailSafe GUI to (or run the cmgr command on) a single administration node in the pool when making changes. However, you can use any node in the pool when requesting status or configuration information.
The following figures describe potential scenarios using the hierarchies.
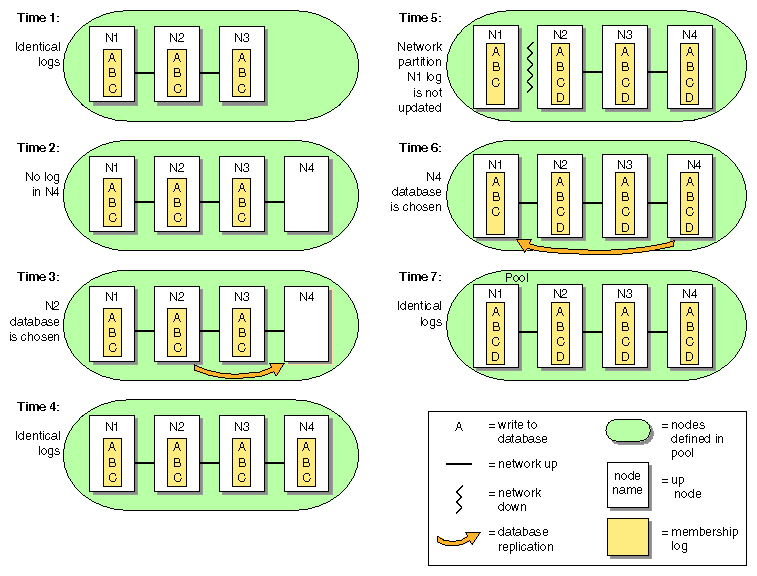
Figure B-1, shows:
Time 1: An established pool of three administration nodes sharing heartbeats, with node IDs 1-3, represented by the node names N1-N3. The tiebreaker node is the node in the membership with the lowest node ID. Each successive database write is identified by a letter in the membership log.
Time 2: A new node, N4, is defined using cmgr or the GUI connected to node N1. Node N4 (node ID = 4) joins the pool. Its membership log is empty.
Time 3: Because N1/N2/N3 have identical membership logs, the database is replicated from one of them. In this case, N2 is randomly chosen.
Time 4: All nodes in the pool have identical membership logs.
Time 5: A network partition occurs that isolates N1. Therefore, N1 can no longer receive database updates. Configuration changes are made by connecting the GUI to N2 (or running cmgr on node N2); this results in updates to the membership logs in N2, N3, and N4, but not to N1 because it is isolated.
Time 6: The partition is resolved and N1 is no longer isolated. Because N2/N3/N4 have identical membership logs, and share the beginning history with N1, the database is replicated from one of them. N4 is chosen at random.
Time 7: All nodes in the pool have identical membership logs.
Recall that a node can be in only one pool at a time. If there are two separate pools, and from a node in one pool you define one or more nodes that are already in the other pool, the result will be that nodes from one of the pools will move into the other pool. This operation is not recommended, and determining which nodes will move into which other pool can be difficult. Figure B-2 illustrates what to expect in this situation.
Time 1: There are two pools that do not share membership log contents. One pool has two nodes (N1/N2), the other has three (N3/N4/N5).
Time 2: N1 and N2 are defined as part of the second pool by running cmgr or connecting the GUI to node N3, N4, or N5. This results in a new pool with five nodes with different membership logs.
Time 3: The database from the larger set of nodes is the one that must be replicated. N3 is chosen at random from the N3/N4/N5 set.
Time 4: All nodes in the pool have identical membership logs.
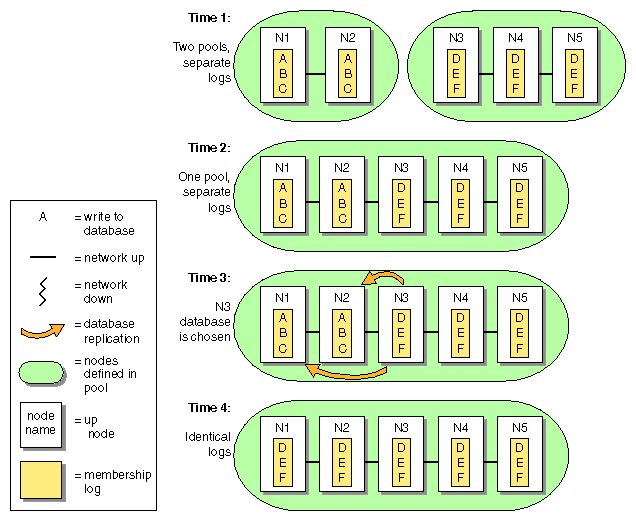
Figure B-3, shows a similar situation in which two nodes are defined in two pools, but the pools are of equal size:
Time 1: There are two pools that do not share membership log contents. Each pool has two nodes (N1/N2 in pool 1, and N3/N4 in pool 2).
Time 2: N1 and N2 are defined as part of the second pool by connecting the GUI or running cmgr on node N3 or N4. This results in a new pool with four nodes with different membership logs.
Time 3: Because each set has the same number of nodes, the tiebreaker node (the node with the lowest node ID in the membership) must be used to determine whose database will be chosen. Because node N1 is the lowest node ID (node ID=1), the database from N1 is chosen.
Time 4: All nodes in the pool have identical membership logs.
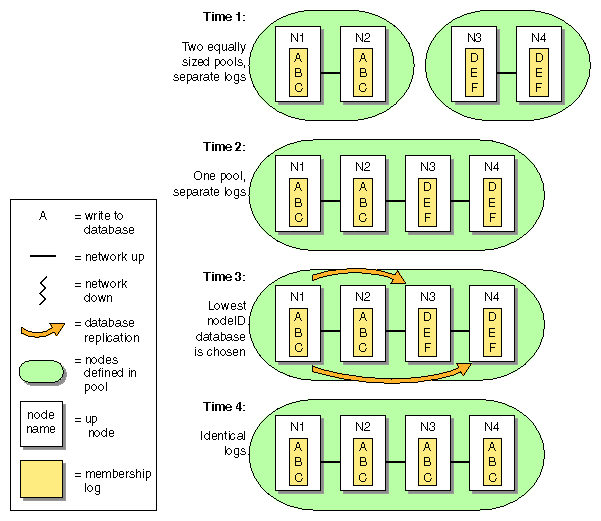
Figure B-4, shows an example of a changing CXFS kernel membership quorum. It shows a pool of:
Five CXFS server-capable administration nodes (A, B, C, D, and E)
Two client-only nodes (F and G)
One client admin node (H)
All nodes except E are defined as part of the cluster. Assume that CXFS services have been enabled on A, B, C, D, F, G, and H.
Of the seven nodes eligible for CXFS kernel membership, four are server-capable nodes (A, B, C, and D). Therefore, at least three of these four nodes must be able to communicate with each other to form an initial CXFS kernel quorum (>50% of the eligible server-capable nodes). Once the quorum has been reached, a membership will form with the nodes in the quorum plus all other eligible nodes that can communicate with the nodes in the quorum.
Figure B-4, shows the following:
Time 1: The CXFS kernel membership quorum is formed with three server-capable nodes, A, B, and C. The membership is A, B, C, F, G, and H.
Time 2: Node B shuts down and leaves the membership. The remaining nodes in the quorum are A and C. The membership is still be available in this case because it satisfies the quorum requirement to maintain 50% of the eligible server-capable nodes (that is, two of the four server-capable nodes). The membership is A, C, F, G, and H.
Time 3: Node A also shuts down and leaves the membership. Therefore, the quorum requirement is no longer met because quorum cannot be maintained with fewer than 50% of the eligible server-capable nodes. Without a quorum, the membership cannot continue, and so the CXFS filesystems in the cluster would not be available.
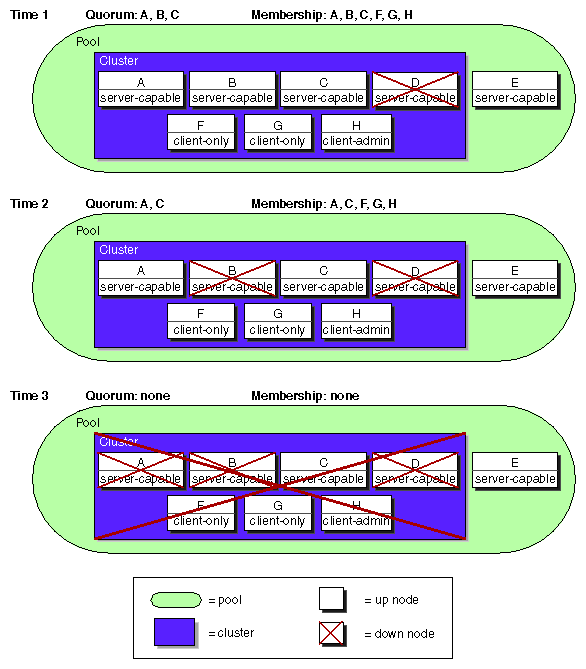
Figure B-5, shows an example of the different memberships in a cluster running CXFS and FailSafe. The pool contains 15 nodes (named N1 through N15). N1 has the lowest node ID number. There are CXFS nodes running IRIX, Solaris, and Windows; only the nodes running IRIX are administration nodes containing the cluster database. The FailSafe nodes are those where HA services are enabled; each of these is an administration node.
Cluster database membership:
Eligible: N1, N2, N3, N5, N9, and N10 (that is, all nodes containing the cluster database)
Actual: N1, N2, N3, N4, and N10 (because N5 and N9 are down)
Quorum: N1, N2, N3, and N10 (>50% of eligible nodes)
FailSafe membership:
Eligible: N1, N2, and N3 (that is, those nodes with HA services enabled and defined as part of the cluster)
Actual: N1, N2, N3
Quorum: N1, N2, N3 (>50% of eligible nodes)
CXFS kernel membership:
Eligible: N1-N8 and N11-N15 (N9 and N10 are not defined as part of the cluster)
Actual: N1, N2, N3, N4, N6, and N11-N15 (because N5, N7, and N8 are down)
Quorum: N1, N2 (>50% of server-capable eligible nodes)
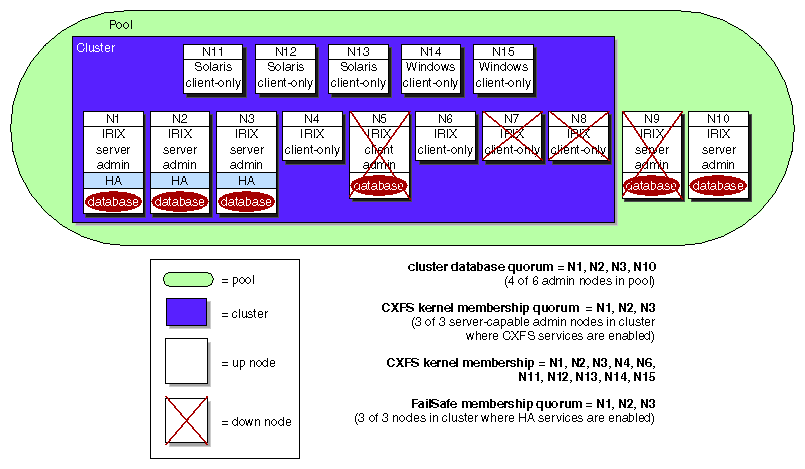
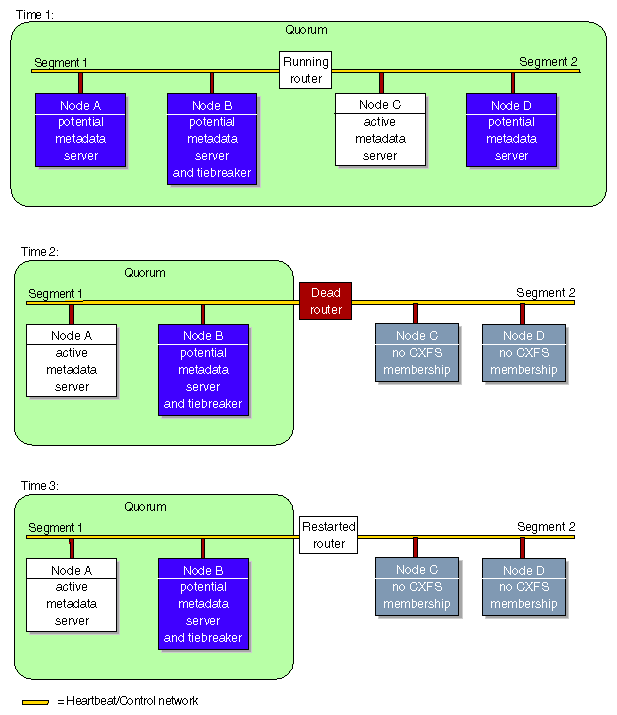
Figure B-6, displays a situation in which a router dies and the heartbeat/control network is effectively split in two. The potential CXFS kernel membership is defined to be nodes A, B, C, and D. The nodes on network segment 2 (nodes C and D) will leave the CXFS kernel membership because they do not contain the CXFS tiebreaker node, and therefore do not have a quorum. On network segment 1, one of the other two potential metadata servers will become active and the membership will only include the systems on network segment 1. The nodes that were on network segment 2 will remain out of the membership until CXFS services are restarted on them and the router is repaired.
There are different heartbeats for each membership type, and each uses a different networking method. Therefore, certain network misconfiguration can cause one heartbeat to fail while another succeeds.
At least two networks should be designated as FailSafe heartbeat networks. FailSafe uses only the highest priority working network for heartbeats; the other network is for heartbeat failover. Usually the private network is used as the highest priority heartbeat network.
In a coexecution cluster, there must be two networks as required by FailSafe; at least one private network is recommended for FailSafe and a private network is required by CXFS.
In a coexecution cluster, CXFS metadata, CXFS heartbeat, and FailSafe heartbeat can use the same network. The heartbeat intervals and timeouts should be appropriately adjusted, if possible, so that all network traffic has sufficient bandwidth. You cannot change the heartbeat timeout or interval for the cluster database membership. Before you adjust the heartbeat settings for the FailSafe membership or CXFS kernel membership, you should consider the impact on the other heartbeats.
If the highest priority network fails, the FailSafe and cluster database memberships will continue using just the next priority network, but the CXFS kernel membership will fail.
A cluster with an odd number of server-capable nodes is recommended for a production environment. However, if you use a production cluster with an even number of server-capable nodes (especially only two server-capable nodes), you must do one of the following:
Use serial hardware reset lines or I/O fencing to ensure protection of data and guarantee that only one node is running in error conditions. The reset capability or I/O fencing is mandatory to ensure data integrity for clusters with only two server-capable nodes and it is highly recommended for all server-capable nodes. Larger clusters should have an odd number of server-capable nodes, or must have serial hardware reset lines or I/O fencing with switches if only two of the nodes are server-capable.
Set a CXFS tiebreaker node. If the tiebreaker node is a server-capable administration node, there will be a loss of CXFS kernel membership, and therefore CXFS filesystems, if the tiebreaker node goes down. If the tiebreaker is an administration node, the cluster database membership may also be lost.
However, even with these methods, there are recovery and relocation issues inherent to a cluster with only two server-capable nodes.