This chapter contains the following sections:
The Tools.h++ class library includes three types of collection classes:
The template-based collection classes, which we call collection class templates, or just templates, for short;
The generic collection classes, modeled after Stroustrup (1986), Chapter 7.3.5;
The Smalltalk-like collection classes.
Despite their different implementations, their functionality and user interfaces (member function names, etc.) are similar.
In the following chapters, we'll discuss each type of collection class in turn. In this chapter, we'll discuss basic concepts of collection classes, and translate some of the jargon you may encounter here and in the literature of C++.
The general objective of collection classes, called collections for short, is to store and retrieve objects. In fact, you can classify collection classes according to how they store objects. Value-based collections store the object itself; reference-based collections store a pointer or reference to the object. The difference between the two will influence how you use some features of collection classes in Tools.h++.
Value-based collection classes are simpler to understand and manipulate. You create a linked list of integers or doubles, for example, or a hash table of shorts. Stored types can be more complicated, like the RWCStrings, but the important point is that they act just like values, even though they may contain pointers to other objects. When an object is inserted into a value-based collection class, a copy is made. The procedure is similar to C's pass-by-value semantics in function calls.
In a reference-based collection class, you store and retrieve pointers to other objects. For example, you could create a linked list of pointers to integers or doubles, or a hash table of pointers to RWCStrings.
Let's look at two code fragments that demonstrate the difference between the value-based and the reference-based procedures:
Value-based Example |
Reference-based Example |
/* A vector of RWCStrings: */ |
/* A vector of pointers to
RWCStrings: */ |
Both code fragments insert an RWCString into vector v. In the first example, s is an RWCString object containing "A string". The statement v.insert(s) copies the value of s into the vector. The object that lies within the vector is distinct and separate from the original object s. In the second example, p is a pointer to the RWCString object. When the procedure v.insert(p) is complete, the new element in v will refer to the same RWCString object as p.
A reference-based collection can be very efficient because pointers are small and inexpensive to manipulate. However, with a reference-based collection, you must always remember that you are responsible for memory management: the creation, maintenance, and destruction of the actual objects themselves. If you create two pointers to the same object and prematurely delete the object, you'll leave the second pointer pointing into nonsense. By the same token, you must never insert a nil pointer into a reference-based collection, since the collection has methods which must dereference its contained values.
Despite the added responsibility, don't avoid reference-based collections when you need them. Tools.h++ classes have member functions to help you, and in most cases, the ownership of the contained objects is obvious anyway. You should choose a reference-based collection if you need performance and size advantages: here the size of all pointers is the same, allowing a large degree of code reuse. Also choose the reference-based collection if you just want to point to an object rather than contain it (a set of selected objects in a dialog list, for example). Finally, for certain heterogeneous collections, the reference-based approach may be the only one viable.
Copying classes is a common software procedure. It happens every time a copy constructor is applied, or whenever a process needs a copy to work on. Copying value-based collection classes is straightforward. But special considerations arise in copying reference-based classes, and we deal with them here.
What happens when you make a copy of a reference-based collection class, or any class that references another object, for that matter? It depends which of the two general approaches you choose: shallow copying or deep copying.
A shallow copy of an object is a new object whose instance variables are identical to the old object. For example, a shallow copy of a Set has the same members as the old Set, and shares objects with the old Set through pointers. Shallow copies are sometimes said to use reference semantics.

Note: The copy constructors of all reference-based Rogue Wave collection classes make shallow copies. A deep copy of an object is a new object with entirely new instance variables; it does not share objects with the old. For example, a deep copy of a Set not only makes a new Set, but also inserts items that are copies of the old items. In a true deep copy, this copying is done recursively. Deep copies are sometimes said to use value semantics.
Note that some reference-based collection classes have a copy() member function that returns a new object with entirely new instance variables. This copying is not done recursively, and the new instance variables are shallow copies of the old instance variables.
Here's a graphical example of the differences between shallow and deep copies. Imagine Bag, an unordered collection class of objects with duplicates allowed, that looks like this before a copy :
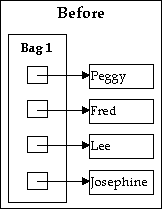
Making a shallow copy and a deep copy of Bag would produce the following results:
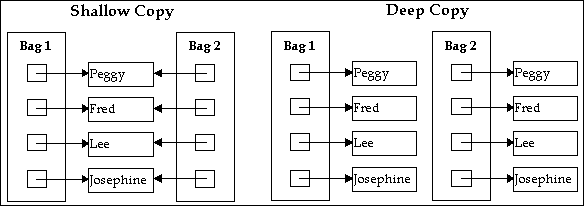
You can see that the deep copy copies not only the bag itself, but recursively all objects within it.
The copying approach you choose is important. For example, shallow copies can be useful and fast, because less copying is done, but you must be careful because two collections now reference the same object. If you delete all the items in one collection, you will leave the other collection pointing into nonsense.
You also need to consider the approach when writing an object to disk. If an object includes two or more pointers or references to the same object, it is important to preserve this morphology when the object is restored. Classes that inherit from RWCollectable inherit algorithms that guarantee to preserve an object's morphology. You'll see more on this in Chapter 14.
Let us now contrast the results of copying the reference-based collection with the value-based collection. Consider the class:
RWTValOrderedVector<RWCString>
that is, an ordered vector template instantiated for RWCString. In this case, each string is embedded within the collection. When a copy of the collection class is made, not only the collection class itself is copied, but also the objects in it. This results in distinct new copies of the collected objects:
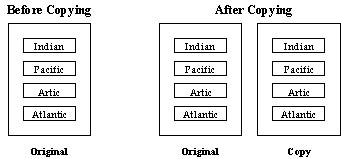
We have defined the major objective of collection classes as storing and retrieving objects. How you retrieve or find an object depends on its properties. Every object you create has three properties associated with it:
Type: for example, an RWCString or a double. In C++, the type of an object is set at creation, and cannot change.
State: the value of the string. The values of all the instance variables or attributes of an object determine its state. These can change.
Identity: the unique definition of the object for all time. Languages use different methods for establishing an object's identity. C++ always uses the object's address. Each object is associated with one and only one address. Note that the reverse is not always true, because of inheritance. Generally, an address and a type[8] are both necessary to disambiguate the object you mean within an inheritance hierarchy.
Based on the properties of an object, there are two general methods for finding or retrieving it. Some collection classes can support either, some only one. The important thing for you to keep in mind is which one you mean. The two methods are:
Find an object with a particular state. For example, test two strings for the same value. In the literature, this is variously referred to as two objects testing isEqual, having equality, compares equal, having the same value, or testing true for the == operator. Here, we refer to the two objects testing equal as isEqual. In general, we need some knowledge of the type of each object—or subtype, in the case of inheritance—in order to find the appropriate instance variables to test for equality[9] .
Find a particular object; that is, one with the same identity as the object being compared. In the literature, this is referred to as two objects testing isSame, having the same identity, or testing true for the == operator. We refer to this as two objects having the same identity. Note that because value-based collection classes make a copy of an inserted object, finding an object in a value-based collection class with a particular identity is meaningless.
In C++, to test for identity—that is, to test whether two objects are the same object—you must see if they have the same address. Because of multiple inheritance, the address of a base class and its associated derived class may not be the same. Therefore, if you compare two pointers (addresses) to test for identity, the types of the two pointers should be the same.
Smalltalk uses the operator = to test for equality, and the operator == to test for identity. In the C++ world, however, operator = is firmly attached to assignment, and operator == to some kind of equality of values. We have taken the C++ approach. At Rogue Wave, the operator == generally means test for equality of values (isEqual) when applied to two classes, and test for identity when applied to two pointers.
Whether to test for equality or identity depends on the context of your problem. Here are some examples that can clarify which to choose.
Here's an example when you should test for equality. Suppose you are maintaining a mailing list. Given a person's name, you want to find his or her address. In this case, you search for a name that is equal to the name at hand. An RWHashDictionary would be appropriate. The key to the dictionary would be the name, the value would be the address.
In the next example, you would test for identity. Suppose you are writing a hypertext application, and need to know in which document a particular graphic occurs. You could keep an RWHashDictionary of graphics and their corresponding documents. In this case, however, you need an RWIdentityDictionary because you need to know in which document a particular graphic occurs. The graphic acts as the key, the document as the value.
Maintaining a disk cache? You might want to know whether a particular object is resident in memory. In this case, an RWIdentitySet is appropriate. Given an object, you can check to see whether it exists in memory—another identity test.
Many of the collection classes have an associated iterator. The advantage of the iterator is that it maintains its own internal state, thus allowing two important benefits:
More than one iterator can be constructed from the same collection class;
All of the items need not be visited in a single sweep.
Iterators are always constructed from the collection class itself, as in the following example:
RWBinaryTree bt; . . . RWBinaryTreeIterator bti(bt); |
Immediately after construction, or after reset() is called, the state of the iterator is undefined. You must either advance it or position it before using its current state or position.
For traditional Tools.h++ iterators—those declared as a distinct class related to the collection class—the rule is "advance and then return."[10] However, iterators obtained directly from classes implemented using the Standard C++ Library differ. In keeping with the standard for container classes, they follow the precept: If you obtain an iterator using the begin() or end() method, or using an algorithm which returns an iterator, you have a "Standard Library" iterator.[11] A Standard Library iterator must always be compared against that collection's end() iterator to discover if it references an item in the container.
Traditional Tools.h++ iterators have a number of unique features.
You recall that the state of the iterator is undefined immediately following construction or the calling of reset(). You also trigger the undefined state if you change the collection class directly[12] by adding or deleting objects while an iterator is active. Using an iterator at that point can bring unpredictable results. You must then use the member function reset() to restart the iterator, as if it had just been constructed.
At any given moment, the iterator marks an object in the collection class—think of it as the current object. There are various methods for moving this mark. For example, most of the time you will probably be using member function operator(). In Tools.h++, it is designed to always advance to the next object, then return either TRUE or a pointer to the next object, depending on whether the associated collection class is value-based or reference-based, respectively. It always returns FALSE (i.e., zero) when the end of the collection class is reached. Hence, a simple canonical form for using an iterator is:
RWSlistCollectable list;
.
.
.
RWSlistCollectableIterator iterator(list);
RWCollectable* next;
while (next = iterator()) {
.
. // (use next)
.
} |
As an alternative, you can also use the prefix increment operator ++X. Some iterators have other member functions for manipulating the mark, such as findNext() or removeNext().
Member function key() always returns either the current object or a pointer to the current object, again depending on whether the collection class is value-based or reference-based, respectively.
For most collection classes, using member function apply() to access every member is much faster than using an iterator. This is particularly true for the sorted collection classes—usually a tree has to be traversed here, requiring that the parent of a node be stored on a stack. Function apply() uses the program's stack, while the sorted collection class iterator must maintain its own. The former is much faster.
[8] Because of multiple inheritance, it may be necessary to know not only an object's type, but also its location within an inheritance tree in order to disambiguate which object you mean.
[9] The Rogue Wave collection classes allow a generalized test of equality; it is up to you to define what it means for two objects to "be equal". A bit-by-bit comparison of the two objects is not done. You could define "equality" to mean that a panda is the same as a deer because, in your context, they are both mammals.
[10] This is actually patterned after Stroustrup (1986, Section 7.3.2).
[11] The draft ANSI standard describes container iterators in great detail. Briefly, such iterators are valid in the range "first-element" to "one-past-last-element", which are returned respectively by the methods begin() and end(). The "end" iterator, however, does not reference an item in the container, but acts as a sentinel.
[12] It's OK to change a collection via the iterator itself.