When planning a complex program, you must understand how IRIX creates the virtual address space of a process, and how you can modify the normal behavior of the address space. The major topics covered here are as follows:
“Defining the Address Space” tells what the address space is and how it is created.
“Interrogating the Memory System” summarizes the ways your program can get information about the address space.
“Mapping Segments of Memory” documents the different ways that you can create new memory segments with predefined contents.
“Locking and Unlocking Pages in Memory” discusses when and how to lock pages of virtual memory to avoid page faults.
“Additional Memory Features” summarizes functions for address space management.
“Using Origin2000 Nonuniform Memory” describes the use of CC-NUMA memory in the Origin2000 and Onyx2 systems.
Each user-level process has a virtual address space. This term means simply: the set of memory addresses that the process can use without error. When 32-bit addressing is in use, addresses can range from 0 to 0x7fffffff; that is, 2^31 possible numbers, for a total theoretical size of 2 gigabytes. (Numbers greater than 2^31 are in the IRIX kernel's address space.)
When 64-bit addressing is used, a process's address space can encompass 2^40 numbers. (The numbers greater than 2^40 are reserved for kernel address spaces.) For more details on the structure of physical and virtual address spaces, see the IRIX Device Driver Programmer's Guide and the MIPS architecture documents listed on page xxxvi.
Although the address space includes a vast quantity of potential numbers, usually only a small fraction of the addresses are valid.
A segment of the address space is any range of contiguous addresses. Certain segments are created or reserved for certain uses.
The address space is called “virtual” because the address numbers are not directly related to physical RAM addresses where the data resides. The mapping from a virtual address to the corresponding real memory location is kept in a table created by the IRIX kernel and used by the MIPS processor chip.
A process has at least three segments of usable addresses:
A text segment contains the executable image of the program. Another text segment is created for each dynamic shared object (DSO) with which a process is linked.Text segments are always read-only.
A data segment contains the “heap” of dynamically allocated data space. A process can create additional data segments in various ways described later.
A stack segment contains the function-call stack. This segment is extended automatically as needed.
Although the address space begins at location 0, by convention the lowest segment is allocated at 0x0040 0000 (4 MB). Addresses less than this are intentionally left undefined so that any attempt to use them (for example, through an uninitialized pointer variable) causes a hardware exception and stops the program.
Typically, text segments are at smaller virtual addresses and stack and data segments at larger ones, although you should not write code that depends on this.
| Tip: The boundaries of all distributed DSOs are declared in the file /usr/lib/so_locations. When IRIX loads a DSO that is not declared in this file, it seeks a segment of the address space that does not overlap any declared DSO and that will not interfere with growth of the stack segment. To learn more about DSOs, see the rld(1) and dso(5) reference pages, and the MIPSpro Compiling, Linking, and Performance Tuning Guide. |
IRIX manages memory in units of a page. The size of a page can differ from one system to another. In systems such as the O2 workstation, which support only 32-bit addressing, the page size is always 4,096 bytes. In each 32-bit virtual address,
In systems that support 64-bit addressing the page size is greater than 4,096 bytes. The page size is configurable, and in fact different programs can have different page sizes, and a single program can have different size pages for the text segment, stack segment, and data segments. However, the page size is always a power of 2, and the bits of the virtual address are used in the same way: the least-significant bits of an address specify an offset within a page, while the most-significant bits specify the VPN.
You can learn the actual size of a page in the present system with getpagesize(), as noted under “Interrogating the Memory System”.
Page tables, built by IRIX during a fork() or exec() call, define the address space for a process by specifying which VPNs are defined. These tables are consulted by the hardware. Recently-used table entries are cached for instant lookup in the processor chip, in an array called the Translation Lookaside Buffer (TLB).
Most of the possible addresses in an address space are undefined; that is, not defined in the page tables, not related to contents of any kind, and not available for use. A reference to an undefined address causes a SIGSEGV error.
Addresses are defined—that is, made available for potential use—in one of five ways:
Fork | When a process is created using fork(), the new process is given a duplicate copy of the parent process's page table, so that any addresses that were defined in the parent's address space are defined the same way in the address space of the new process. (See the fork(2) reference page.) |
Exec | The exec() function creates a new address space in which to execute a specified program or interpreter. (See the exec(2) reference page.) |
Stack | The call stack is created and extended automatically. When a function is entered and more stack space is needed, IRIX makes the stack segment larger, defining new addresses if required. |
Mapping | A process can ask IRIX to map (associate byte for byte) a segment of address space to one of a number of special objects, for example, the contents of a file. This is covered further under “Mapping Segments of Memory”. |
Allocation | The brk() function extends the heap, the segment devoted to data, to a specific virtual address. The malloc() function allocates memory for use, calling brk() as required. (See the brk(2), malloc(3), and malloc(3x) reference pages). |
An address is defined by an entry in the page tables. A defined address is always related to a backing store, a source from which its contents can be refreshed. A page in a text segment is related to the executable file. A page of a data or stack segment is related to a page in a swap partition on disk.
The total size of the defined pages in an address space is its virtual size, displayed by the ps command under the heading SZ (see the ps(1) reference page).
Once addresses have been defined in the address space by allocation, there is no way to undefine them except to terminate the process. To free allocated memory makes the freed memory available for reuse within the process, but the pages are still defined in the page tables and the swap space is still allocated.
The segments of the address space have maximum sizes that are set as resource limits on the process. Hard limits are set by these variables:
rlimit_vmem_max | Total size of the address space of a process |
rlimit_data_max | Size of the portion of the address space used for data |
rlimit_stack_max | Size of the portion of the address space used for stack |
The limits active during a login session can be displayed and changed using the C-shell command limits. A program can query the limits with getrlimit() and change them with setrlimit() (see the getrlimit(2) reference page).
The initial default value and the possible range of a resource limit is established in the kernel tuning parameters. For a quick look at the kernel limits, use
fgrep rlimit /var/sysgen/mtune/kernel |
To examine and change the limits, use systune (see the systune(1) reference page):
Example 1-1. Using systune to Check Address Space Limits
systune -i
Updates will be made to running system and /unix.install
systune-> rlimit_vmem_max
rlimit_vmem_max = 536870912 (0x20000000) ll
systune-> resource
group: resource (statically changeable)
...
rlimit_vmem_max = 536870912 (0x20000000) ll
rlimit_vmem_cur = 536870912 (0x20000000) ll
...
rlimit_stack_max = 536870912 (0x20000000) ll
rlimit_stack_cur = 67108864 (0x4000000) ll
...
|
| Tip: These limits interact in the following way: each time your program creates a process with sproc() and does not supply a stack area (see the sproc(2) reference page), an address segment equal to rlimit_stack_max is dedicated to the stack of the new process. When rlimit_stack_max is set high, a program that creates many processes can quickly run into the rlimit_vmem_max boundary. |
IRIX supports two radically different ways of defining segments of address space.
The conventional behavior of UNIX systems, and the default behavior of current releases of IRIX, is that space created using brk() or malloc() is immediately defined. Page table entries are created to define the addresses, and swap space is allocated as a backing store. Three results follow from the conventional method:
A program can detect immediately when swap space is exhausted. A call to malloc() returns NULL when memory cannot be allocated. A program can test the limits of swap space by making repeated calls to malloc().
A large memory allocation by one program can fill the swap disk partition, causing other programs to see out-of-memory errors—whether the program ever uses its allocated memory or not.
A fork() or exec() call fails unless there is free space in swap equal to the data and stack sizes of the new process.
By default in IRIX 5.2, and optionally in later releases, IRIX uses a different method sometimes called “virtual swap.” In this method, the definition of new segments is delayed until the space is actually used. Functions like brk() and malloc() merely test the new size of the data segment against the resource limits. They do not actually define the new addresses, and they do not cause swap disk space to be allocated. Addresses are reserved with brk() or malloc(), but they are only defined and allocated in swap when your program references them.
When IRIX uses delayed definition (“virtual swap”), it has the following effects:
A program cannot find the limits of swap space using malloc()—it never returns NULL until the program exceeds its resource limit, regardless of available swap.
Instead, when a program finally accesses a new page of allocated space and there is at that time no room in the swap partition, the program receives a SIGKILL signal.
A large memory allocation by one program cannot monopolize the swap disk until the program actually uses the allocated memory, if it ever does.
Much less swap space is required for a successful fork() call.
You can test whether the system uses virtual swap with the chkconfig command (as described in the chkconfig(1) reference page):
# chkconfig vswap; echo $status 0 |
As you write a new program, assume that virtual swap may be used. Do not allocate memory merely to find out if you can. Allocate no more memory than your program needs, and use the memory immediately after allocating it.
If you are porting a program written for a conventional UNIX system, you might discover that it tests the limits of allocatable memory by calling malloc() until malloc() returns a NULL, and then does not use the memory. In this case you have several choices:
Recode this part of the program to derive the maximum memory size in some more reasonable and portable way, for instance from an environment variable or the size of an input file.
Using setrlimit(), set a lower maximum for rlimit_data_max, so that malloc() returns NULL at a reasonable allocation size, independent of the swap disk allocation (see the getrlimit(2) reference page).
Restore the conventional UNIX behavior for the whole system. Use chkconfig to turn off the variable vswap, and reboot (see the chkconfig(1) reference page).
Although an address is defined, the corresponding page is not necessarily loaded in physical memory. The sum of the defined address spaces of all processes is normally far larger than available real memory. IRIX keeps selected pages in real memory. A page that is not present in real memory is marked as “invalid” in the page tables. When the program refers to an address on an invalid page, the CPU traps to the kernel, which supplies the page.
The contents of invalid pages can be supplied in one of the following ways:
Text | Pages of program text—executable code of programs and dynamically linked libraries—can be retrieved on demand from the program file or library files on disk. |
Data | Pages of data from the heap and stack can be retrieved from the swap partition or file on disk. |
Mapped | When a segment is created by mmap(), a backing store file is specified by the program (see “Mapping Segments of Memory”). |
Never used | Pages that have been defined but never used can be created as pages of binary zero when they are needed. |
When a process refers to a VPN that is defined but invalid, a hardware interrupt occurs. The interrupt handler in the IRIX kernel chooses a page of physical RAM to hold the page. In order to acquire this space, the kernel might have to invalidate some other page belonging to your process or to another process. The contents of the needed page are read from the appropriate backing store into memory, and the process continues to execute.
Page validation takes from 10 to 50 milliseconds. Most applications are not impeded by page fault processing, but a real-time program cannot tolerate these delays.
The total size of all the defined pages in an address space is displayed by the ps command under the heading SZ. The aggregate size of the pages that are actually in memory is the resident set size, displayed by ps under the heading RSS.
| Tip: A sophisticated IRIX user might know that the daemon responsible for reading and writing pages from disk was called vhand, and its activity could be monitored. However, starting with IRIX 6.4 all such system daemons became “kernel threads” and are no longer visible to commands such as ps or gr_top. |
A page of memory can be marked as valid for reading but invalid for writing. Program text is marked this way because program text is read-only; it is never changed. If a process attempts to modify a read-only page, a hardware interrupt occurs. When the page is truly read-only, the kernel turns this into a SIGSEGV signal to the program. Unless the program is handling this signal, the result is to terminate the program with a segmentation fault.
When fork() is executed, the new process shares the pages of the parent process under a rule of copy-on-write. The pages in the new address space are marked read-only. When the new process attempts to modify a page, a hardware interrupt occurs. The kernel makes a copy of that page, and changes the new address space to point to the copied page. Then the process continues to execute, modifying the page of which it now has a unique copy.
You can apply the copy-on-write discipline to the pages of an arena shared with other processes (see “Mapping a File for Shared Memory”).
You can get information about the state of the memory system with the system calls shown in Table 1-1.
Table 1-1. Memory System Calls
Memory Information | System Call Invocation |
|---|---|
Size of a page (in a data segment) | uiPageSize = getpagesize(); |
Virtual and resident sizes of a process | syssgi(SGI_PROCSZ, pid, &uiSZ, &uiRSS); |
Maximum stack size of a process | uiStackSize = prctl(PR_GETSTACKSIZE) |
Free swap space in 512-byte units | swapctl(SC_GETFREESWAP, &uiBlocks); |
Total physical swap space in 512-byte units | swapctl(SC_GETSWAPTOT, &uiBlocks); |
Total real memory | sysmp(MP_KERNADDR, MPSA_RMINFO, &rmstruct); |
Free real memory | sysmp(MP_KERNADDR, MPSA_RMINFO, &rmstruct); |
Total real memory + swap space | sysmp(MP_KERNADDR, MPSA_RMINFO, &rmstruct); |
The structure used with the sysmp() call shown above has this form (a more detailed layout is in sys/sysmp.h):
struct rminfo {
__uint32_t freemem; /* pages of free memory */
__uint32_t availsmem; /* total real+swap memory space */
__uint32_t availrmem; /* available real memory space */
__uint32_t bufmem; /* not useful */
__uint32_t physmem; /* total real memory space */
};
|
Your process can create new segments within the address space. Such a “mapped” segment can represent
the contents of a file
a segment initialized to binary zero
a POSIX shared memory object
a view of the kernel's private address space or of physical memory
a portion of VME A24 or A32 bus address space (when a VME bus exists on the system)
A mapped segment can be private to one address space, or it can be shared between address spaces. When shared, it can be
read-only to all processes
read-write to the creating process and read-only to others
read-write to all sharing processes
copy-on-write, so that any sharing process that modifies a page is given its own unique copy of that page
| Note: Some of the memory-mapping capabilities described in this section are unique to IRIX and nonportable. Some of the capabilities are compatible with System V Release 4 (SVR4). IRIX also supports the POSIX 1003.1b shared memory functions. Compatibility issues with SVR4 and POSIX are noted in the text of this section. |
The mmap() function (see the mmap(2) reference page) creates shared or unshared segments of memory. The syntax and most basic features of mmap() are compatible with SVR4 and with POSIX 1003.1b. A few features of mmap() are unique to IRIX.
The mmap() function performs many kinds of mappings based on six parameters. The function prototype is
void * mmap(void *addr, size_t len, int prot, int flags, int fd, off_t off) |
The function returns the base address of a new segment, or else -1 to indicate that no segment was created. The size of the new segment is len, rounded up to a page. An attempt to access data beyond that point causes a SIGBUS signal.
Three of the mmap() parameters describe the object to be mapped into memory (which is the backing store of the new segment):
fd | A file descriptor returned by open() or by the POSIX-defined function shm_open() (see the open(2) and shm_open(2) reference pages). All mmap() calls require a file descriptor to define the backing store for the mapped segment. The descriptor can represent a file, or it can be based on a pseudo-file that represents kernel memory or a device special file. |
off | The offset into the object represented by fd where the mapped data begins. When fd describes a disk file, off is an offset into the file. When fd describes memory, off is an address in that memory. off must be an integral multiple of the memory page size (see “Interrogating the Memory System”). |
len | The number of bytes of data from fd to be mapped. The initial size of the segment is len, rounded up to a multiple of whole pages. |
Three parameters of mmap() describe the segment to be created:
addr | Normally 0 to indicate that IRIX should pick a convenient base address, addr can specify a virtual address to be the base of the segment. See “Choosing a Segment Address”. |
prot | Access control on the new segment. You use constants to specify a combination of read, write, and execute permission. The access control can be changed later (see “Changing Memory Protection”). |
flags | Options on how the new segment is to be managed. |
The elements of flags determine the way the segment behaves, and are as follows:
MAP_FIXED | Take addr literally. |
MAP_PRIVATE | Changes to the mapped data are visible only to this process. |
MAP_SHARED | Changes to the mapped data are visible to all processes that map the same object. |
MAP_AUTOGROW | Extend the object when the process stores beyond its end (not a POSIX feature) |
MAP_LOCAL | Map is not visible to other processes in share group (not POSIX) |
MAP_AUTORESRV | Delay reserving swap space until a store is done (not POSIX). |
The MAP_FIXED element of flags modifies the meaning of addr. Discussion of this is under “Choosing a Segment Address”.
The MAP_AUTOGROW element of flags specifies what should happen when a process stores data past the current end of the segment (provided storing is allowed by prot). When flags contains MAP_AUTOGROW, the segment is extended with zero-filled space. Otherwise the initial len value is a permanent limit, and an attempt to store more than len bytes from the base address causes a SIGSEGV signal.
Two elements of flags specify the rules for sharing the segment between two address spaces when the segment is writable:
MAP_SHARED specifies that changes made to the common pages are visible to other processes sharing the segment. This is the normal setting when a memory arena is shared among multiple processes.
When a mapped segment is writable, any changes to the segment in memory are also written to the file that is mapped. The mapped file is the backing store for the segment.
When MAP_AUTOGROW is specified also, a store beyond the end of the segment lengthens the segment and also the file to which it is mapped.
MAP_PRIVATE specifies that changes to shared pages are private to the process that makes the changes.
The pages of a private segment are shared on a copy-on-write basis—there is only one copy as long as they are unmodified. When the process that specifies MAP_PRIVATE stores into the segment, that page is copied. The process has a private copy of the modified page from then on. The backing store for unmodified pages is the file, while the backing store for modified pages is the system swap space.
When MAP_AUTOGROW is specified also, a store beyond the end of the segment lengthens only the private copy of the segment; the file is unchanged.
The difference between MAP_SHARED and MAP_PRIVATE is important only when the segment can be modified. When the prot argument does not include PROT_WRITE, there is no question of modifying or extending the segment, so the backing store is always the mapped object. However, the choice of MAP_SHARED or MAP_PRIVATE does affect how you lock the mapped segment into memory, if you do; see “Locking Program Text and Data”.
Processes created with sproc() normally share a single address space, including mapped segments (see the sproc(2) reference page). However, if flags contains MAP_LOCAL, each new process created with sproc() receives a private copy of the mapped segment on a copy-on-write basis.
When the segment is based on a file or on /dev/zero (see “Mapping a Segment of Zeros”), mmap() normally defines all the pages in the segment. This includes allocating swap space for the pages of a segment based on /dev/zero. However, if flags contains MAP_AUTOGROW, the pages are not defined until they are accessed (see “Delayed and Immediate Space Definition”).
| Note: The MAP_LOCAL and MAP_AUTOGROW flag elements are IRIX features that are not portable to POSIX or to System V. |
You can use mmap() as a simple, low-overhead way of reading and writing a disk file. Open the file using open(), but instead of passing the file descriptor to read() or write(), use it to map the file. Access the file contents as a memory array. The memory accesses are translated into direct calls to the device driver, as follows:
An attempt to access a mapped page, when the page is not resident in memory, is translated into a call on the read entry point of the device driver to read that page of data.
When the kernel needs to reclaim a page of physical memory occupied by a page of a mapped file, and the page has been modified, the kernel calls the write entry point of the device driver to write the page. It also writes any modified pages when the file mapping is changed by munmap() or another mmap() call, when the program applies msync() to the segment, or when the program ends.
When mapping a file for input only (when the prot argument of mmap() does not contain PROT_WRITE), you can use either MAP_SHARED or MAP_PRIVATE. When writing is allowed, you must use MAP_SHARED, or changes will not be reflected in the file.
| Tip: Memory mapping provides an excellent way to read a file containing precalculated, constant data used by an interactive program. Time-consuming calculation of the data elements can be done offline by another program; the other program also maps the file in order to fill it with data. |
You can lock a mapped file into memory. This is discussed further under “Locking and Unlocking Pages in Memory”.
Because the potential 32-bit address space is more than 2000 megabytes (and the 64-bit address space vastly greater), you can in theory map very large files into memory. However, many segments of the virtual address space are preassigned to DSOs (see “Address Space Boundaries” and the file /usr/lib/so_locations), and this restricts the available size of maps in 32-bit space. To map an entire file, follow these steps:
When you map a large file into memory, the space is counted as part of the virtual size of the process. This can lead to very large apparent sizes. For example, under IRIX 5.3 and 6.2, the Object Server maps a large database into memory, with the result that a typical result of ps -l looks like this:
70 S 0 566 1 0 26 20 * 33481:225 80272230 ? 0:45 objectser |
The total virtual size of 33481 certainly gets your attention! However, note the more modest real storage size of 225. Most of the mapped pages are not in physical memory. Also realize that the backing store for pages of a mapped file is the file itself—no swap space is used.
You do not have to map the entire file; you can map any portion of it, from one page to the file size. Simply specify the desired length as len and the starting offset as off.
You can remap a file to a different segment by calling mmap() again. In this way you can use the off parameter of mmap() as the logical equivalent of lseek(). That is, to map a different segment of the file, specify
The old segment is replaced with a new segment at the same address, now containing data from a different offset in the file.
| Note: Each time you replace a segment with mmap(), the previous segment is discarded. The new segment is not locked in memory, even if the old segment was locked. |
Access to a file for mapping is controlled by the same file permissions that control I/O to the file. The protection in prot must agree with the file permissions. For example, if the file is read-only to the process, mmap() does not allow prot to specify write or execute access.
| Note: When a program runs with superuser privilege for other reasons, file permissions are not a protection against accidental updates. |
The file that is mapped can be local to the machine, or can be mounted by NFS. In either case, be aware that changes to the file are buffered and are not immediately reflected on disk. Use msync() to force modified pages of a segment to be written to disk (see “Synchronizing the Backing Store”).
If IRIX needs to read a page of a mapped, NFS mounted file, and an NFS error occurs (for example, because the file server has gone down), the error is reflected to your program as a SIGBUS exception.
| Caution: When two or more processes in the same system map an NFS-mounted file, their image of the file will be consistent. But when two or more processes in different systems map the same NFS-mounted file, there is no way to coordinate their updates, and the file can be corrupted. |
Any change to a file is immediately visible in the mapped segment. This is always true when flags contains MAP_SHARED, and initially true when flags contains MAP_PRIVATE. A change to the file can be made by another process that has mapped the same file.
A mapped file can also be changed by a process that opens the file for output and then applies either write() to update the file or ftruncate() to shorten it (see the write(2) and ftruncate(3) reference pages). In particular, if any process truncates a mapped file, an attempt to access a mapped memory page that corresponds to a now-deleted portion of the file causes a bus error signal (SIGBUS) to be sent.
When MAP_PRIVATE is specified, a private copy of a page of memory is created whenever the process stores into the page (copy-on-write). This prevents the change from being seen by any other process that uses or maps the same file, and it protects the process from detecting any change made to that page by another process. However, this applies only to pages that have been written into.
Frequently you cannot use MAP_PRIVATE because it is important to see data changes and to share them with other processes that map the same file. However, it is also important to prevent an unrelated process from truncating the file and so causing SIGBUS exceptions.
The one sure way to block changes to the file is to install a mandatory file lock. You place a file lock with the lockf() function (see Chapter 7, “File and Record Locking”). However, a file lock is normally “advisory”; that is, it is effective only when every process that uses the file also calls lockf() before changing it.
You create a mandatory file lock by changing the protection mode of the file, using the chmod() function to set the mandatory file lock protection bit (see the chmod(2) reference page). When this is done, a lock placed with lockf() is recognized and enforced by open().
You can use mmap() simply to create a segment of memory that can be shared among unrelated processes.
In one process, create a file or a POSIX shared memory object to represent the segment.
Typically a file is located in /var/tmp, but it can be anywhere. The permissions on the file or POSIX object determine the access permitted to other processes.
Map the file or POSIX object into memory with mmap(); initialize the segment contents by writing into it.
In another process, get a file descriptor using open() or the POSIX function shm_open(), specifying the same pathname.
In that other process, use mmap() specifying the file descriptor of the file.
After this procedure, both processes are using the identical segment of memory pages. Data stored by one is immediately visible to the other.
This is the most basic method of sharing a memory segment. More elaborate methods with additional services are discussed in Chapter 3, “Sharing Memory Between Processes.”
You can use mmap() to create a segment of zero-filled memory. Create a file descriptor by applying open() to the special device file /dev/zero. Map this descriptor with addr of 0, off of 0, and len set to the segment size you want.
A segment created this way cannot be shared between unrelated processes. However, it can be shared among any processes that share access to the original file descriptor—that is, processes created with sproc() using the PR_SFDS flag (see the sproc(2) reference page). For more information about /dev/zero, see the zero(7) reference page.
The difference between using mmap() of /dev/zero and calloc() is that calloc() defines all pages of the segment immediately. When you specify MAP_AUTOGROW, mmap() does not actually define a page of the segment until the page is accessed. You can create a very large segment and yet consume swap space in proportion to the pages actually used.
| Note: This feature is unique to IRIX. The file /dev/zero may not exist in other versions of UNIX. Since the feature is nonportable, you should not use the POSIX function shm_open() with /dev/zero (or any device special file). |
You can use mmap() to create a segment that is a window on physical memory. To do so you create a file descriptor by opening the special file /dev/mem. For more information, see the mem(7) reference page.
Obviously the use of such a segment is nonportable, hardware-dependent, and dependent on the OS release.
You can use mmap() to create a segment that is a window on the kernel's virtual address space. To do so you create a file descriptor by opening the special file /dev/mmem (note the double “m”). For more information, see the mem(7) (single “m”) reference page.
The acceptable off and len values you can use when mapping /dev/mmem are defined by the contents of /var/sysgen/master.d/mem. Normally this file restricts possible mappings to specific hardware registers such as the high-precision clock. For an example of mapping /dev/mmem, see the example code in the syssgi(2) reference page under the SGI_QUERY_CYCLECNTR argument.
You can use mmap() to create a segment that is a window on the bus address space of a particular VME bus adapter. This allows you to do programmed I/O (PIO) to VME devices.
To do PIO, you create a file descriptor by opening one of the special devices in /dev/vme. These files correspond to VME devices. For details on the naming of these files, see the usrvme(7) reference page.
The name of the device that you open and pass as the file descriptor determines the bus address space (A16, A24, or A32). The values you specify in off and len must agree with accessible locations in that VME bus space. A read or write to a location in the mapped segment causes a call to the read or write entry of the kernel device driver for VME PIO. An attempt to read or write an invalid location in the bus address space causes a SIGBUS exception to all processes that have mapped the device.
| Note: On the CHALLENGE and Onyx hardware, PIO reads and writes are asynchronous. Following an invalid read or write, as much as 10 milliseconds can elapse before the SIGBUS signal is raised. |
For a detailed discussion of VME PIO, see the IRIX Device Driver Programmer's Guide.
| Note: Mapping of devices through mmap() is an IRIX feature that is not defined by POSIX standard. Do not use the POSIX shm_open() function with device special files. |
Normally there is no need to map a segment to any particular virtual address. You specify addr as 0 and IRIX picks an unused virtual address. This is the usual method and the recommended one.
You can specify a nonzero value in addr to request a particular base address for the new segment. You specify MAP_FIXED in flags to say that addr is an absolute requirement, and that the segment must begin at addr or not be created. If you omit MAP_FIXED, mmap() takes a nonzero addr as a suggestion only.
In rare cases you may need to create two or more mapped segments with a fixed relationship between their base addresses. This would be the case when there are offset values in one segment that refer to the other segment, as diagrammed in Figure 1-1.
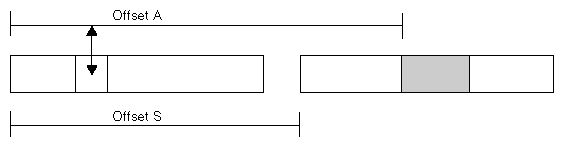
In Figure 1-1, a word in one segment contains an offset value A giving the distance in bytes to an object in a different mapped segment. Offset A is accurate only when the two segments are separated by a known distance, offset S.
You can create segments in such a relationship using the following procedure.
Map a single segment large enough to encompass the lengths of all segments that need fixed offsets. Use 0 for addr, allowing IRIX to pick the base address. Let this base address be B.
Map the smaller segments over the larger one. For the first (the one at the lowest relative position), specify B for addr and MAP_FIXED in flags.
For the remaining segments, specify B+S for addr and MAP_FIXED in flags.
The initial, large segment establishes a known base address and reserves enough address space to hold the other segments. The later mappings replace the first one, which cannot be used for its own sake.
You can specify any value for addr. IRIX creates the mapping if there is no conflict with an existing segment, or returns an error if the mapping is impossible. However, you cannot normally tell what virtual addresses will be available for mapping in any particular installation or version of the operating system.
There are three exceptions. First, after IRIX has chosen an address for you, you can always map a new segment of the same or shorter length at the same address. This allows you to map different parts of a file into the same segment at different times (see “Mapping Portions of a File”).
Second, the low 4 MB of the address space are unused (see “Address Space Boundaries”). It is a very bad idea to map anything into the 0 page because that makes it hard to trap the use of uninitialized pointers. But you can use other parts of the initial 4 MB for mapping.
Third, the MIPS Application Binary Interface (ABI) specification (an extension of the System V ABI published by AT&T) states that addresses from 0x3000 0000 through 0x3ffc 0000 are reserved for user-defined segment base addresses.
You may specify values in this range as addr with MAP_FIXED in flags. When you map two or more segments into this region, no two segments can occupy the same 256-KB unit. This rule ensures that segments always start in different pages, even when the maximum possible page size is in use. For example, if you want to create two segments each of 4096 bytes, you can place one at 0x30000000 through 0x3000 0fff and the other at 0x3004 0000 through 0x3004 0fff. (256 KB is 0x0004 0000.)
| Note: If two programs in the same system attempt to map different objects to the same absolute address, the second attempt fails. |
A page fault interrupts a process for many milliseconds. Not only are page faults lengthy, their occurrence and frequency are unpredictable. A real-time application cannot tolerate such interruptions. The solution is to lock some or all of the pages of the address space into memory. A page fault cannot occur on a locked page.
You can use any of the functions summarized in Table 1-2 to lock memory.
Table 1-2. Functions for Locking Memory
Function Name | Compatibility | Purpose and Operation |
|---|---|---|
mlock(3C) | POSIX | Lock a specified range of addresses. |
mlockall(3C) | POSIX | Lock the entire address space of the calling process. |
mpin(3C) | IRIX | Lock a specified range of addresses. |
plock(3C) | SVR4 | Lock all program text, or all data, or the entire address space. |
Locking memory causes all pages of the specified segments to be defined before they are locked. When virtual swap is in use, it is possible to receive a SIGKILL exception while locking because there was not enough swap space to define all pages (see “Delayed and Immediate Space Definition”).
Locking pages in memory of course reduces the memory that is available for all other programs in the system. Locking a large program increases the rate of page faults for other programs.
Using mpin() and mlock() you have to calculate the starting address and the length of the segment to be locked. It is relatively easy to calculate the starting address and length of global data or of a mapped segment, but it can be awkward to learn the starting address and length of program text or of stack space.
Using mlockall() you lock all of the program text and data as it exists at the time of the call. You specify a flag, either MCL_CURRENT or MCL_FUTURE, to give the scope in time. One possible way to lock only program text is to call mlockall() with MCL_CURRENT early in the initialization of a program. The program's text and static data are locked, but not any dynamic or mapped pages that may be created subsequently. Specific ranges of dynamic or mapped data can be locked with mlock() as they are created.
Using plock() you specify whether to lock text, data, or both. When you specify the text option, the function locks all executable text as loaded for the program, including shared objects (DSOs). (It does not lock segments created with mmap() even when you specify PROT_EXEC to mmap(). Use mlock() or mpin() to lock executable, mapped segments.)
When you specify the data option, plock() locks the default data (heap) and stack segments, and any mapped segments made with MAP_PRIVATE, as they are defined at the time of the call. If you extend these segments after locking them, the newly defined pages are also locked as they are defined.
Although new pages are locked when they are defined, you still should extend these segments to their maximum size while initializing the program. The reason is that it takes time to extend a segment: the kernel must process a page fault and create a new page frame, possibly writing other pages to backing store to make space.
One way to ensure that the full stack is created before it is locked is to call plock() from a function like the function in Example 1-2.
Example 1-2. Function to Lock Maximum Stack Size
#define MAX_STACK_DEPTH 100000 /* your best guess */
int call_plock()
{
char dummy[MAX_STACK_DEPTH];
return plock(PROCLOCK);
}
|
The large local variable forces the call stack to what you expect will be its maximum size before plock() is entered.
The plock() function does not lock mapped segments you create with MAP_SHARED. You must lock them individually using mpin(). You need to do this from only one of the processes that shares the segment.
It may be better for your program to not lock the entire address space, but to lock only a particular mapped segment.
Immediately after calling mmap() you have the address and length of the mapped segment. This is a convenient time to call either mpin() or mlock() to lock the mapped segment.
The mmap() flags MAP_AUTOGROW and MAP_AUTORESRV are unique to IRIX and not defined by POSIX. However, the POSIX mlock() function for IRIX does recognize autogrow segments. If you lock an autogrow segment with mpin(), mlock(), or mlockall() with the MCL_FUTURE flag, additional pages are locked as they are added to the segment. If you lock the segment with mlockall() with the MCL_CURRENT flag, the segment is locked for its current size only and added pages are not locked.
If you map a file before you use mlockall(MCL_CURRENT) or plock() to lock the data segment into memory (see “Mapping a File for I/O”), the mapped file is read into the locked pages during the lock operation. If you lock the program with mlockall(MCL_FUTURE) and then map a file into memory, the mapped file is read into memory and the pages locked.
If you map a file after locking the data segment with plock() or mlockall(MCL_CURRENT), the new mapped segment is not locked. Pages of file data are read on demand, as the program accesses them.
From these facts you can conclude the following:
You should map small files before locking memory, thus getting fast access to their contents without paging delays.
Conversely, if you map a file after locking memory, your program could be delayed for input on any access to the mapped segment.
However, if you map a large file and then try to lock memory, the attempt to lock could fail because there is not enough physical memory to hold the entire address space including the mapped file.
One alternative is to map an entire file, perhaps hundreds of megabytes, into the address space, but to lock only the portion or portions that are of interest at any moment. For example, a visual simulator could lock the parts of a scenery file that the simulated vehicle is approaching. When the vehicle moves away from a segment of scenery, the simulator could unlock those parts of the file, and possibly use madvise() to release them (see “Releasing Unneeded Pages”).
The function summarized in Table 1-3 are used to unlock memory.
Table 1-3. Functions for Unlocking Memory
Function Name | Compatibility | Purpose and Operation |
|---|---|---|
munlock(3C) | POSIX | Unlock a specified range of locked addresses. |
mlockall(3C) | POSIX | Unlock the entire address space of the calling process. |
munpin(3C) | IRIX | Unlock a specified range of addresses. |
punlock() | SVR4 | Unlock addresses locked by plock(). |
You should avoid mixing function families; for example, if you lock memory with the POSIX function mlock(), do not unlock the memory using munpin().
The mpin() function maintains a counter for each locked page showing how many times it has been locked. You must call munpin() the same number of times before the page is unlocked. This feature is not available through the POSIX and SVR4 interfaces.
Locked pages of an address space are unlocked when the last process using the address space terminates. Locked pages of a mapped segment are unlocked when the last process that mapped the segment unmaps it or terminates.
Your program can work with the IRIX memory manager to change the handling of the address space.
You can change the memory protection of specified pages using mprotect() (see the mprotect(2) reference page). For a segment that contains a whole number of pages, you can specify protection of these types:
| Note: The mprotect() function changes the access rights only to the memory image of a mapped file. You can apply it to the pages of a mapped file in order to control access to the file image in memory. However, mprotect() does not affect the access rights to the file itself, nor does it prevent other processes from opening and using the file as a file. |
IRIX writes modified pages to the backing store as infrequently as possible, in order to save time. When pages are locked, they are never written to backing store. This does not matter when the pages are ordinary data.
When the pages represent a file mapped into memory, you may want to force IRIX to write any modifications into the file. This creates a checkpoint, a known-good file state from which the program could resume.
The msync() function (see the msync(2) reference page) asks IRIX to write a specified segment to backing store. The segment must be a whole multiple of pages. You can optionally request
synchronous writes, so the call does not return until the disk I/O is complete—ensuring that the data has been written
page invalidation, so that the memory pages are released and will have to be reloaded from backing store if they are referenced again
Using the madvise() function (see the madvise(2) reference page), you can tell IRIX that a range of pages is not needed by your process. The pages remain defined in the address space, so this is not a means of reducing the need for swap space. However, IRIX puts the pages at the top of its list of pages to be reclaimed when another process (or the calling process) suffers a page fault.
The madvise() function is rarely needed by real-time programs, which are usually more concerned with keeping pages in memory than with letting them leave memory. However, there could be a use for it in special cases
In the Origin2000 systems (which include the Origin200 and Onyx2 product lines) physical memory is implemented using a cache-coherent nonuniform memory architecture, abbreviated CC-NUMA (or sometimes simply NUMA).
For almost all programs, the CC-NUMA hardware makes no difference at all. The virtual address space as described in this chapter is implemented exactly the same in all versions of IRIX. Your program cannot tell whether the memory hardware is bus-based as in a CHALLENGE system, or uses CC-NUMA as in the Origin2000 (except that in a heavily-loaded multiprocessor, your program will run faster in an Origin than in a CHALLENGE).
However, when you implement a program that has critical performance requirements, uses multithreading, and needs a large memory space—all three conditions must be present—you may need to control the placement of virtual pages in physical memory for best performance.
You need to understand the Origin hardware at a high level in order to understand memory placement.
The basic building block of an Origin system is a node, a single board containing
Two MIPS R10000 CPUs, each with a secondary cache of 1 MB or 4 MB.
Some amount of main memory, from 64 MB to 4 GB.
One hub custom ASIC that manages all access to memory in the node.
Nodes are packaged into a module. A module contains
One to four node boards.
One or two routers, high-bandwidth switches that connect nodes and modules.
Crossbow I/O interface chips.
The Crossbow chips are used to connect I/O devices of all sorts: SCSI, PCI, FDDI, and other types. Each Crossbow chip connects to the hub of one or two nodes, so any I/O card is closely connected to as many as two main-memory banks and as many as four CPUs.
An Origin2000 or Onyx2 system can consist of a single module, or multiple modules can be connected to make a larger system. Modules are connected by their routers. Routers in different modules are connected by special cables, the CrayLink interconnection fabric. Routers form a hypercube topology to minimize the number of hops from any node to any other.
Physical memory is distributed throughout an Origin system, with some memory installed at each node. However, the system maintains a single, uniform, physical address space. Each CPU translates memory addresses from virtual to physical, and presents the physical address to its hub. A few high-order bits in the physical address designate the node where the physical memory is found. The hub uses these bits to direct the memory request as required: to the local memory in its own node, or through a router to another node.
All translation and routing of physical addresses is entirely transparent to software, which operates in a uniform virtual memory space.
Two aspects of memory mapping are not uniform. First, the physical memory map can contain gaps. Not all nodes have the same amount of memory installed. Indeed, there is no requirement that all nodes be present in the system, and in future releases of IRIX it will be possible to remove and replace nodes while the system remains up.
Second, the access time to memory differs, depending on the distance between the memory and the CPU that requests it:
Memory in the same node is accessed fastest.
Memory located on another node in the same module costs one or two router hops.
Memory in another module costs additional router hops.
Normally, memory location relative to a program has an insignificant effect on performance, because
IRIX takes is careful to locate a process in a CPU near the process's data.
Most programs are so written that 90% or more of the memory accesses are satisfied from the secondary cache, which is connected directly to the CPU.
The CrayLink interconnection fabric has an extremely high bandwidth (in excess of 600MB/sec sustained bidirectionally on every link), so each router hop adds only a small fraction of a microsecond to the access time.
Performance problems only arise when multithreaded programs defeat the caching algorithms or place high-bandwidth memory demands from multiple CPUs to a single node.
Each CPU in an Origin system has an independent secondary cache, organized as a set of 128-byte cache lines. The memory lines that were most recently used by the CPU are stored here for high-speed access.
When two or more CPUs access the same memory, each has an independent copy of that data. There can be as many copies of a data item as there are CPUs; and for some important tables in the IRIX kernel, this may often be the case.
Cache coherency means that the system hardware ensures that every cached copy remains a true reflection of the memory data, without software intervention.
Cache coherency requires no effort as long as all CPUs merely read the memory data. The hardware must intervene when a CPU attempts to modify memory. Then, that CPU must be given exclusive ownership of the modified cache line, and all other copies of the same data must be marked invalid, so that when the other CPUs need this data, they will fetch a fresh copy.
The CHALLENGE and Onyx systems are designed around a central bus over which all memory requests pass. Each CPU board in a CHALLENGE system monitors the bus. When a board observes a write to memory, it checks its own cache and, if it has a copy of that same line, it invalidates the copy. This design, often called a “snoopy cache” because each CPU reads its neighbors' mail, works well when all memory access moves on a single bus.
The cache coherency design of the Origin systems is fundamentally different, because in the Origin machines there is no central bus. Memory access packets can flow within a node or between any two nodes. Instead, cache coherence is implemented using what is called a directory-based scheme. The following is a simplified account of it.
Each 128-byte line of main memory is supplied with extra bits, one for each possible node, plus an 8-bit integer for the number of the node that owns the line exclusively. These extra bits are called directory bits. The directory bits are managed as part of memory by the hub chip in the node that contains the memory. The directory bits are not accessible to user-level software. (The kernel can read and write the directory bits using privileged instructions.)
When a CPU accesses an unmodified cache line for reading, the request is routed to the node that contains the memory. The hub chip in that node returns the memory data, and also sets the bit for the reading CPU to 1. When a CPU discards a cached line for any reason, the corresponding bit is set to 0. Thus the directory bits reflect the existence of cached copies of data. As long as all CPUs only read the data, there is no time cost for directory management.
When a CPU wants to modify a cache line, two things happen. The hub chip in the node that contains the memory sends a message to every CPU whose directory bit for that line is 1, telling the CPU to discard its copy because it is no longer valid. And the modifying CPU is noted as the exclusive owner of that line. Any further requests for that line's data are rerouted to the owning CPU, so that it can supply the latest version of the data.
Eventually the owning CPU updates memory and discards the cache line, and the directory status returns to its original condition.
Most programs operate with good performance when they simply treat the system as having a single large, uniform, memory. When this is not the case, IRIX contains tools you can use to exploit the hardware.
Clearly it is a performance advantage for a process to execute on a CPU that is as close as possible to the data used by the process. Default IRIX policies ensure this for most programs:
Memory is usually allocated on a “first touch” basis; that is, it is allocated in the node where the program that first defines that page is executing. When that is not possible, the memory is allocated as close as possible (in router hops) to the CPU that first accessed the page.
The IRIX scheduler maintains process affinity to CPUs based on both cache affinity (as in previous versions) and on memory affinity. When a process is ready to run it is dispatched to
The CPU where it last ran, if possible
The other CPU in the same node, if possible
A CPU in a nearby node
The great majority of commands and user programs have memory requirements that fit comfortably in a single node; and most execute at least as well, usually faster, than in any previous Silicon Graphics system.
Only one memory performance issue arises with a single-threaded program. When the program allocates much more virtual memory than is physically available in its node, at least some of its virtual address space is allocated in other nodes. The program pays an access time penalty on some segments of its address space. When this occurs, the penalty is usually unnoticeable as long as the program has good cache behavior.
Typically, IRIX allocates the first-requested memory in the requester's node. When the first-requested memory is also the most-used, average access time still remains low. When this is not the case, there are tools you can use to ensure that specific memory segments are located next to specific CPUs.
IRIX supports parallel processing under several different models (see Chapter 10, “Models of Parallel Computation”). When a program uses multiple, parallel threads of execution, additional performance issues can arise:
Cache contention can occur as multiple threads, running in different CPUs, invalidate each other's cached data.
Default allocation policies can place memory segments in different nodes from the CPUs the threads that use the data.
Default allocation to a single node, when threads are running in many nodes, can saturate the node with memory requests, slowing access.
These issues are discussed in the following topics.
When one CPU updates a cache line, all other CPUs that refer to the same data must fetch a fresh copy. When a line is used often from multiple CPUs and is also updated frequently, the data is effectively not cached, but accessed at memory speeds.
In addition, when more than one CPU updates the same cache line, the CPUs are forced to execute in turn. Each waits until it can have exclusive ownership of the line. When multiple CPUs update the same line concurrently, the data is accessed at a fraction of memory speeds, and all the CPUs are forced to idle for many cycles.
An update of one 64-bit word invalidates the 15 other words in the same cache line. When the other words are not related to the new data, false sharing occurs; that is, variables are invalidated and have to be reloaded from memory merely by the accident of their address, with no logical need.
These cache contention issues are not new to the Origin architecture; they arise in any multiprocessor that supports cache coherency.
The first problem with cache contention is to recognize that it is occurring. In earlier systems you diagnosed cache contention by elimination. Now you can use software tools and the hardware features of the MIPS R10000 CPU to detect it directly.
The R10000 includes hardware registers that can count a variety of discrete events during execution, at no performance cost. The R10000 can count individual clock cycles, numbers of loads, stores, and floating-point instructions executed, as well as cache invalidation events.
The IRIX kernel contains support for “virtualizing” the R10000 counter registers, so that each IRIX process appears to have its own set of counters (just as the kernel ensures that each process has its own unique set of other machine register contents).
Included with IRIX is the perfex profiling tool (see the perfex(1) reference page). It executes a specified program after setting up the kernel to count the events you specify. At the end of the test run, perfex displays the profile of counts. You can use perfex to count the number of instructions a program executes, or the number of page faults it encounters, and so on. No recompilation or relinking is required, and the program runs only fractionally slower than normal.
Using perfex you can discover approximately how much time a program, or a single thread of a program, loses to cache invalidations, and how many invalidations there were. This allows you to easily distinguish cache contention from other performance problems.
Cache contention is corrected by changing the layout of data in the source program. In general terms, the available strategies are these:
Minimize the number of variables that are accessed by more than one thread.
Segregate nonvolatile data items into different cache lines from volatile items.
Isolate volatile items that are not related into separate cache lines to eliminate false sharing.
When volatile items are updated together, group them into single cache lines.
A common design for a large program is to define a block of global status variables that is visible to all parallel threads. In the normal course of the program, every CPU caches all or most of such a common area. Read-only access does no harm, but if the items in the block are volatile, contention occurs. For example a global area might contain the anchor for a LIFO queue of some kind. Every time a thread puts or takes an item from the queue, it updates the queue anchor, and invalidates that cache line for every other thread.
It is inevitable that a queue anchor variable will be frequently invalidated. However, the time cost can be isolated to queue access by applying strategy 2: allocate the queue anchor in separate memory from the global status area. Put a nonvolatile pointer to the queue in the status area. Now the cost of fetching the queue anchor is born only by threads that access the queue.
If there are other items that are updated with the queue anchor, such as the lock that controls exclusive access to the queue (see Chapter 4, “Mutual Exclusion”), place those items adjacent to the queue anchor so that all are in the same cache line (strategy 4). However, if there are two queues that are updated at unrelated times, place each in its own cache line (strategy 3).
The locks, semaphores, and message queues that are used to synchronize threads (see “Types of Interprocess Communication Available”) are global variables that must be updated by any CPU that uses them. It is best to assume that such objects are accessed at memory speeds. Two things can be done to reduce contention:
Minimize contention for locks and semaphores through algorithmic design. In particular, use more rather than fewer semaphores, and make each stand for the smallest possible resource. (Of course, this makes it more difficult to avoid deadlocks.)
Never place unrelated synchronization objects in the same cache line (strategy 3). A lock or semaphore can be in the same cache line as the data that it controls, because an update of one usually follows an update of the other (strategy 4).
Carefully review the design of any data collection that is used by parallel code. For example, the root and the first few branches of a binary tree or B-tree are likely to be visited by every CPU that searches that tree, and therefore will be cached by every CPU. Elements at higher levels in the tree may be visited and cached by only a few CPUs.
Other classic data structures can cause cache contention (computer science textbooks on data structures are generally still written from the standpoint of a single-level mainframe memory architecture). For example, a hash table can be implemented compactly, with only a word or two in each entry. But that creates false sharing by putting several table entries (which are unrelated by definition) in the same cache line. To avoid false sharing in a hash table, make each table entry a full 128 bytes, cache-aligned. You can take advantage of the extra bytes in each entry to store a list of overflow hits—such a list can be quickly scanned because the entire cache line is fetched as one memory access.
Suppose a Fortran program allocates a 1000 by 1000 array of complex numbers. By default IRIX places this 16 MB memory allocation in the node where the program starts up. But what if the program contains the C$DOACROSS directive to parallelize the DO-loop that processes the array? (See Chapter 11, “Statement-Level Parallelism.”) Some number threads—say, four—execute blocks of the DO-loop in parallel, using four CPUs located in two, three, or even four different nodes. Two problems arise:
At least two of the threads have to pay a penalty of at least one router hop to get the data.
It would be better to allocate parts of the array in the nodes where those threads are running.
A single hub chip can easily keep up with the memory demands of two CPUs, but when four CPUs are generating constant memory requests, one hub may saturate, slowing access.
It would be better to distribute the array data among other nodes—any other nodes—to prevent a single hub from being a bottleneck.
Unfortunately none of the counter values reported by perfex provide a direct diagnosis of bad memory placement. You can suspect memory placement problems from a combination of circumstances:
Performance does not improve as expected when more parallel threads and CPUs are added.
The perfex report shows a relatively low percentage of cache line reuse (less than 85% secondary cache hits, to pick a common number).
This is a performance problem you can address for its own sake; but it demonstrates that the program depends on a high memory bandwidth.
The program has a high CPU utilization, so it is not being delayed for I/O or by synchronization with other threads.
The program has no other performance problems that can be detected with perfex of the Speedshop tools (see the speedshop(1) reference page).
There are two issues: to make sure that each thread concentrates memory access on some definable subset of the data; and second, to make sure that this data is allocated on or near the node where the thread executes.
The first issue is algorithmic. It is not possible for a page of data to be in two nodes at once. When data is used simultaneously by two or more threads, that data must be closer to some threads than to others, and it must be delivered to all threads from a single hub chip. (Parenthetically, what is true of data is not necessarily true of program text, which is read-only. The kernel can and does replicate the pages of common DSOs in every node so that there is no time penalty for fetching instructions from common DSOs like the C or Fortran runtime libraries.)
When you have a clear separation of data between parallel threads, there are several tools for placing pages near the threads that use them. The tool you use depends on the model of parallel computation you use.
Using the Fortran compiler, specify how array elements are distributed among the threads of a parallelized loop using compiler directives. The C compiler supports pragma statements for the same purpose.
Take advantage of IRIX memory-allocation rules to ensure that memory is allocated next to the threads that use it.
Enable dynamic page migration to handle slowly-changing access patterns.
Use the dprof tool to learn the memory-use patterns of a program (see the dprof(1) reference page).
Use the dplace tool to set the initial memory layout of any program, without needing to modify the source code (see the dplace(1) reference page).
Code dynamic calls to dplace within the program, to request dynamic relocation of data between one program phase and the next.
The Silicon Graphics Fortran 77 and Fortran 90 compilers support compiler directives for data placement. You use compiler directives to specify parallel processing over loops. You can supplement these with directives specifying how array sections should be distributed among the nodes that execute the parallel threads.
You use the Fortran directives to declare a static placement for array sections. You can also use directives to specify redistribution of data at runtime, when access patterns change in the course of the program. For details on these directives, see the Fortran programmer's guides cited under “Other Useful References”.
The Silicon Graphics C and C++ compilers support some pragma statements for data placement. These are documented in the C Language Reference Manual (see “Other Useful References”).
By default, IRIX places memory pages in the nodes where they are first “touched,” that is, referenced by a CPU. In order to take advantage of this rule you have to be aware of when a first touch can take place. With reference to the different means of “Address Definition”,
The system call fork() duplicates the address space, including the placement of all its pages.
The system call exec() creates initial stack and data pages in the node where the new program will run.
The system calls brk() and sbrk() extend the virtual address space but do not “touch” new, complete pages.
The standard and optional library functions malloc(), when called to allocate more than a page size aligned on a page boundary, do not touch any new pages they allocate. (Space that has been allocated, touched, and freed can be reused, and it stays where it was first touched.)
The system call mmap() does not touch the pages it maps (see “Mapping Segments of Memory”).
The library call calloc() touches the pages it allocates to fill them with zero.
The system functions to lock memory pages (see “Locking and Unlocking Pages in Memory”) do touch the pages they lock.
It is typical to allocate all memory, including work areas used by subprocesses or threads, in the parent process. This practice ensures that all memory is allocated in the node where the parent runs. Instead, the parent process should allocate and touch only data space that is used by multiple threads. Work areas that are unique to a thread should be allocated and touched first by that thread; then they are placed in the node where the thread runs.
Shared memory arenas (see Chapter 3, “Sharing Memory Between Processes”) are based on memory-mapping. However, the library function or system call that creates an arena will typically touch at least the beginning of the arena in order to initialize it. If each thread is to have a private data area within an arena, make the private area at least a page in size, allocated on a page-size boundary; and allocate it from the thread that uses it.
When a Fortran or C program uses statement-level parallelism (based on the multiprocessing library libmp—see “Managing Statement-Parallel Execution”), you can replace the first-touch allocation rule with round-robin allocation. When you set an environment variable _DSM_ROUND_ROBIN, libmp distributes all data memory for the program across the nodes in which the program runs. Each new virtual page is allocated in a different node.
Round-robin allocation does not produce optimal placement because there is no relationship between the threads and the pages they use. However, it does ensure that the data will be served by multiple hub chips.
Dynamic page migration can be enabled for a specific program, or for all programs. When migration is enabled, IRIX keeps track of the source of the references to each page of memory. When a page is being used predominately from a different node, IRIX copies the page contents to the node that is using it, and resets the page tables to direct references to the new location.
Dynamic migration is a relatively expensive operation: besides the overhead of a daemon that uses hardware counters to monitor page usage, a migration itself entails a memory copy of data and the forced invalidation of translate lookaside registers in all affected nodes (see “Page Numbers and Offsets”). For this reason, migration is not enabled by default. (The system administrator can turn it on for all programs using the sn command as described in the sn(1) reference page, but this is not recommended.)
You can experiment to see whether dynamic page migration helps a particular program. It is likely to help when the initial placement of data is not optimal, and when the program maintains consistent access patterns for long periods (many seconds to minutes). When the program has variable, inconsistent access patterns, migration can hurt performance by causing frequent, unhelpful page movements.
To enable migration for a Fortran or C program using libmp, set the _DSM_MIGRATION environment variable, as described in mp(3). In order to enable migration for another type of program, run the program under the dplace command with the -migration option.
The dplace execution monitor is a powerful tool that runs any program (other than programs that use libmp; dplace and libmp manage the same facilities and cannot be used together) using a custom memory-placement policy that you define using a simple control file. The program you run does not have to be recompiled or modified in any way to take advantage of the memory placement, and it runs at full speed once started.
The dplace tool is documented in three reference pages: dplace(1) describes the command syntax and options; dplace(5) documents the control file syntax; and dplace(3) describes how you can call on dplace dynamically, from within a program.
Using dplace you can:
Establish the virtual page size of the stack, heap, and text segments individually at sizes from 16 KB to 16 MB. For example, if the perfex monitor shows the program is suffering many TLB misses, you can increase the size of a data page, effectively increasing the span of addresses covered by each TLB entry.
Turn on dynamic page migration for the program, and set the threshold of local to remote accesses that triggers migration.
Place each process within the program on a specific node, either by node number or with respect to the node where a certain I/O device is attached.
Distribute the processes of a program among any available cluster of nodes having a specified topology (usually cube topology to minimize router distances between nodes).
Place specified segments of the virtual address space in designated nodes.
The dprof profiler (see the dprof(1) reference page) complements dplace. You use dprof to run a program and get a trace report showing which pages are read and written by each process in the program.
When you have control of the source code of a program, you can place explicit calls to dplace within the code. The program can call dplace to move specific processes to specific nodes, or to migrate specific ranges of addresses to nodes.