The Auto-Parallelizing Option is a compiler extension controlled with options in the command line that invokes the MIPSpro auto-parallelizing compilers. It is an optional software product for programs written for the N32 and N64 application binary interfaces (see the ABI(5) reference page for information on the N32 and N64 ABIs). Although their runtime performance suffers slightly on single-processor systems, parallelized programs can be created and debugged with the MIPSpro auto-parallelizing compilers on any Silicon Graphics system that uses a MIPS processor.
The MIPSpro APO is an extension integrated into the compiler; it is not a source-to-source preprocessor as was used prior to the MIPSpro 7.2 release. If the Auto-Parallelizing Option is installed, the compiler is considered a auto-parallelizing compiler and is referred to as the MIPSpro Auto-Parallelizing Fortran 77 compiler.
Parallelization is the process of analyzing sequential programs for parallelism and restructuring them to run efficiently on multiprocessor systems. The goal is to minimize the overall computation time by distributing the computational workload among the available processors. Parallelization can be automatic or manual.
During automatic parallelization, the Auto-Parallelizing Option extension of the compiler analyzes and restructures the program with little or no intervention by you. The MIPSpro APO automatically generates code that splits the processing of loops among multiple processors. An alternative is manual parallelization, in which you perform the parallelization using compiler directives and other programming techniques.
Starting with the 7.2 release, the auto-parallelizing compilers integrate automatic parallelization, provided by the MIPSpro APO, with other compiler optimizations, such as interprocedural analysis (IPA) and loop nest optimization (LNO). Releases prior to 7.2 relied on source-to-source preprocessors; the 7.2 and later versions internalize automatic parallelization into the optimizer of the MIPSpro compilers. As seen in Figure C-1, the MIPSpro APO works on an intermediate representation generated during the compiling process. This provides several benefits:
Automatic parallelization is integrated with the optimizations for single processors.
The options and compiler directives of the MIPSpro APO and the MIPSpro compilers are consistent.
Support for C++ is now possible.
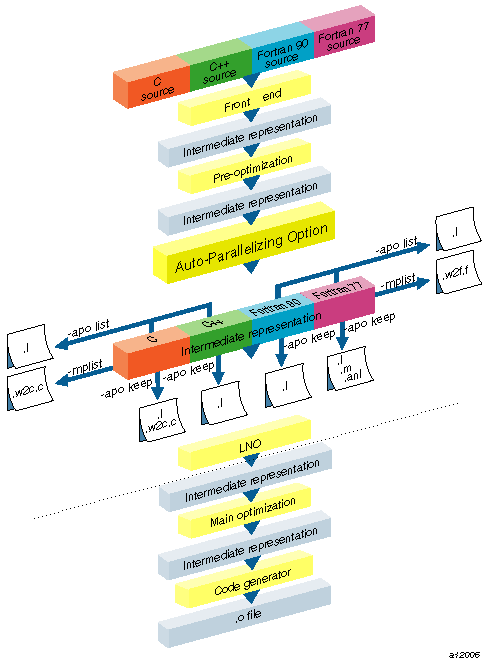
These benefits were not possible with the earlier MIPSpro compilers, which achieved parallelization by relying on the Power Fortran and Power C preprocessors to provide source-to-source conversions before compilation.
You invoke the Auto-Parallelizing Option by including the -apo flag with -n32 or -64 compiles, on the compiler command line. When using the -o32 option, the -apo option invokes Power Fortran. Additional flags allow you to generate reports to aid in debugging. The syntax for compiling programs with the MIPSpro APO is as follows:
f77 options -apo apo_options -mplist filename |
The auto-parallelizing compilers may also be invoked using the -pca flags (for C) or -pfa (for Fortran). These options are provided for backward compatibility and their use is not recommended.
The following arguments are used with the compiler command line:
| options | The MIPSpro Fortran 77 compiler command-line options. The -O3 optimization option is recommended for using the APO. See the f77(1) man page for details about these options. | |
| -apo | Invoke the Auto-Parallelizing Option. | |
| apo_options | apo_options can be one of the following values: list: Invoke the MIPSpro APO and produce a listing of those parts of the program that can run in parallel and those that cannot. The listing is stored in a .list file. keep: Invoke the MIPSpro APO and generate .list, .w2c.c , .m, and .anl files. Because of data conflicts, do not use with -mplist or the LNO options -FLIST and -CLIST. See “Output files”, for details about all output files. | |
| -mplist | Generate the equivalent parallelized program for Fortran 77 in a .w2f.f file. These files are discussed in the section “The .w2f.f File”. Do not use with -apo keep, -FLIST, or -CLIST. | |
| filename | The name of the file containing the source code. |
Starting with the 7.2.1 release of the MIPSpro compilers, the -apo keep and -mplist options cause Auto-Parallelizing Fortran 77 to generate .m and w2f.f files based on OpenMP directives.
The following is a typical compiler command line:
f77 -apo -O3 -n32 -mips4 -c -mplist myProg.f |
This command uses Auto-Parallelizing Fortran 77 (f77 -apo) to compile (-c) the file myProg.f with the MIPSpro compiler options -O3, -n32, and -mips4. The -n32 option requests an object with an N32 ABI; -mips4 requests that the code be generated with the MIPS IV instruction set. Using -mplist requests that a parallelized Fortran 77 program be created in the file myProg.w2f.f. If you are using WorkShop Pro MPF, you may want to use -apo keep instead of -mplist to produce a .anl file.
To use the Auto-Parallelizing Option correctly, remember these points:
The MIPSpro APO can be used only with -n32 or -64 compiles. With -o32 compiles, the -pfa and the -pca flags invoke the older, Power parallelizers, and the -apo flag is not supported.
If you link separately, you must have one of the following in the link line:
the -apo option
the -mp option
Because of data set conflicts, you can use only one of the following in a compilation:
-apo keep
-mplist
-FLIST or -CLIST
Prior to MIPSpro 7.2, parallelization was done by the Power Fortran and Power C preprocessors, which had their own set of options. Starting with MIPSpro 7.2, the Auto-Parallelizing Option does the parallelization and recognizes the same options as the compilers. This has reduced the number of options you need to know and has simplified their use.
The following sections discuss the compiler command-line options most commonly needed with the Auto-Parallelizing Option.
The -O3 optimization option performs aggressive optimization and its use is recommended to run the MIPSpro APO. The optimization at this level maximizes code quality even if it requires extensive compile time or requires relaxing of the language rules. The -O3 option uses transformations that are usually beneficial but can sometimes hurt performance. This optimization may cause noticeable changes in floating-point results due to the relaxation of operation-ordering rules. Floating-point optimization is discussed further in “Other Optimization Options”.
Interprocedural analysis (IPA) is invoked by the -IPA command-line option. It performs program optimizations that can only be done by examining the whole program, rather than processing each procedure separately. The following are typical IPA optimizations:
procedure inlining
identification of global constants
dead function elimination
dead variable elimination
dead call elimination
interprocedural alias analysis
interprocedural constant propagation
As of the MIPSpro 7.2.1 release, the Auto-Parallelizing Option with IPA is able to optimize only those loops whose function calls are determined to be "safe" to be parallelized.
If IPA expands subroutines inlined in a calling routine, the subroutines are compiled with the options of the calling routine. If the calling routine is not compiled with -apo, none of its inlined subroutines are parallelized. This is true even if the subroutines are compiled separately with -apo, because with IPA automatic parallelization is deferred until link time.
The loop nest optimizer (LNO) performs loop optimizations that better exploit caches and instruction-level parallelism. The following are some of the optimizations of the LNO:
loop interchange
loop fusion
loop fission
cache blocking and outer loop unrolling
The LNO runs when you use the -O3 option. It is an integrated part of the compiler, not a preprocessor. There are three LNO options of particular interest to users of the MIPSpro APO:
-LNO:parallel_overhead=n. This option controls the auto-parallelizing compiler's estimate of the overhead incurred by invoking parallel loops. The default value for n varies on different systems, but is typically in the low thousands of processor cycles.
-LNO:auto_dist=on. This option requests that the MIPSpro APO insert data distribution directives to provide the best memory utilization on the S2MP (Scalable Shared-Memory Parallel) architecture of the Origin2000 platform.
-LNO:ignore_pragmas. This option causes the MIPSpro APO to ignore all of the directives and assertions discussed in “Compiler Directives for Automatic Parallelization”. This includes the C*$* NO CONCURRENTIZE directive.
You can view the transformed code in the original source language after the LNO performs its transformations. Two translators, integrated into the compiler, convert the compiler's internal representation into the original source language. You can invoke the desired translator by using the f77 -FLIST:=on or -flist option (these are equivalent commands). For example, the following command creates an a.out object file and the Fortran file test.w2f.f:
f77 -O3 -FLIST:=on test.f |
Because it is generated at a later stage of the compilation, this .w2f.f file differs somewhat from the .w2f.f file generated by the -mplist option (see “The .w2f.f File”). You can read the .w2f.f file, which is a compilable Fortran representation of the original program after the LNO phase. Because the LNO is not a preprocessor, recompiling the .w2f.f file may result in an executable that differs from the original compilation of the .f file.
The -OPT:roundoff=n option controls floating-point accuracy and the behavior of overflow and underflow exceptions relative to the source language rules. The default for -O3 optimization is -OPT:roundoff=2. This setting allows transformations with extensive effects on floating-point results. It allows associative rearrangement across loop iterations, and the distribution of multiplication over addition and subtraction. It disallows only transformations known to cause overflow, underflow, or cumulative round-off errors for a wide range of floating-point operands.
With the -OPT:roundoff=2 or 3 level of optimization, the MIPSpro APO may change the sequence of a loop's floating-point operations in order to parallelize it. Because floating-point operations have finite precision, this change may cause slightly different results. If you want to avoid these differences by not having such loops parallelized, you must compile with the -OPT:roundoff=0 or -OPT;roundoff=1 command-line option. In this example, at the default setting of -OPT:roundoff=2 for the -O3 level of optimization, the MIPSpro APO parallelizes this loop.
REAL A, B(100)
DO I = 1, 100
A = A + B(I)
END DO |
At the start of the loop, each processor gets a private copy of A in which to hold a partial sum. At the end of the loop, the partial sum in each processor's copy is added to the total in the original, global copy. This value of A may be different from the value generated by a version of the loop that is not parallelized.
The MIPSpro APO provides a number of options to generate listings that describe where parallelization failed and where it succeeded. With these listings, you may be able to identify small problems that prevent a loop from being made paralle; then you can often remove these data dependences, dramatically improving the program's performance.
When looking for loops to run in parallel, focus on the areas of the code that use most of the execution time. To determine where the program spends its execution time, you can use tools such as SpeedShop and the WorkShop Pro MPF Parallel Analyzer View described in “About the .m and .anl Files”.
The 7.2.1 release of the MIPSpro compilers is the first to incorporate OpenMP, a cross-vendor API for shared-memory parallel programming in Fortran. OpenMP is a collection of directives, library routines, and environment variables and is used to specify shared-memory parallelism in source code. Additionally, OpenMP is intended to enhance your ability to implement the coarse-grained parallelism of large code sections. On Silicon Graphics platforms, OpenMP replaces the older Parallel Computing Forum (PCF) and SGI DOACROSS directives for Fortran. .
The MIPSpro APO interoperates with OpenMP as well as with the older directives. This means that an Auto-Parallelizing Fortran 77 or Auto-Parallelizing Fortran 90 file may use a mixture of directives from each source. As of the 7.2.1 release, the only OpenMP-related changes that most MIPSpro APO users see are in the Auto-Parallelizing Fortran 77 w2f.f and .m files, generated using the -mplist and -apo keep flags, respectively. The parallelized source programs contained in these files now contain OpenMP directives. None of the other MIPSpro auto-parallelizing compilers generate source programs based on OpenMP.
The -apo list and -apo keep options generate files that list the original loops in the program along with messages indicating if the loops were parallelized. For loops that were not parallelized, an explanation is given.
Example C-1 shows a simple Fortran 77 program. The subroutine is contained in a file named testl.f.
Example C-1. Subroutine in File testl.f
SUBROUTINE sub(arr, n)
REAL*8 arr(n)
DO i = 1, n
arr(i) = arr(i) + arr(i-1)
END DO
DO i = 1, n
arr(i) = arr(i) + 7.0
CALL foo(a)
END DO
DO i = 1, n
arr(i) = arr(i) + 7.0
END DO
END |
When testl.f is compiled with the following command, the APO produces the file testl.list, shown in Example C-2.
f77 -O3 -n32 -mips4 -apo list testl.f -c |
Example C-2. Listing in File testl.list
Parallelization Log for Subprogram sub_
3: Not Parallel
Array dependence from arr on line 4 to arr on line 4.
6: Not Parallel
Call foo on line 8.
10: PARALLEL (Auto) __mpdo_sub_1 |
The last line (10) is important to understand. Whenever a loop is run in parallel, the parallel version of the loop is put in its own subroutine. The MIPSpro profiling tools attribute all the time spent in the loop to this subroutine. The last line indicates that the name of the subroutine is __mpdo_sub_1.
The .w2f.f file contains code that mimics the behavior of programs after they undergo automatic parallelization. The representation is designed to be readable so that you can see what portions of the original code were not parallelized. You can use this information to change the original program.
The compiler creates the .w2f.f file by invoking the appropriate translator to turn the compilers' internal representations into Fortran 77. In most cases, the files contain valid code that can be recompiled, although compiling a .w2f.f file with a standard MIPSpro compiler does not produce object code that is exactly the same as that generated by an auto-parallelizing compiler processing the original source. This is because the MIPSpro APO is an internal phase of the MIPSpro auto-parallelizing compilers, not a source-to-source preprocessor, and does not use a .w2f.f source file to generate the object file.
The -flist option tells Auto-Parallelizing Fortran 77 to compile a program and generate a .w2f.f file. Because it is generated at an earlier stage of the compilation, this .w2f.f file is more easily understood than the .w2f.f file generated using the -FLIST:=on option (see “Loop Nest Optimizer Options”). By default, the parallelized program in the .w2f.f file uses OpenMP directives.
Consider the subroutine in Example C-3, contained in a file named testw2.f.
Example C-3. Subroutine in File testw2.f
SUBROUTINE trivial(a)
REAL a(10000)
DO i = 1,10000
a(i) = 0.0
END DO
END |
After compiling testw2.f using the following command, you get an object file, testw2.o, and a file, testw2.w2f.f, that contains the code shown in Example C-4.
f77 -O3 -n32 -mips4 -c -apo -apokeep testw2.f |
Example C-4. Listing in File testw2.w2f.f
C ***********************************************************
C Fortran file translated from WHIRL Sun Dec 7 16:53:44 1997
C ***********************************************************
SUBROUTINE trivial(a)
IMPLICIT NONE
REAL*4 a(10000_8)
C
C **** Variables and functions ****
C
INTEGER*4 i
C
C **** statements ****
C
C PARALLEL DO will be converted to SUBROUTINE __mpdo_trivial_1
C$OMP PARALLEL DO private(i), shared(a)
DO i = 1, 10000, 1
a(i) = 0.0
END DO
RETURN
END ! trivial |
 | Note: WHIRL is the name for the compiler's intermediate representation. |
As explained in “The .list File”, parallel versions of loops are put in their own subroutines. In this example, that subroutine is __mpdo_trivial_1. C$OMP PARALLEL DO is an OpenMP directive that specifies a parallel region containing a single DO directive.
The f77 -apo keep option generates two files in addition to the .list file:
A .m file, which is similar to the .w2f.f file. It is based on OpenMP and mimics the behavior of the program after automatic parallelization. It is also annotated with information that is used by Workshop ProMPF.
A .anl file, which is used by Workshop ProMPF.
Silicon Graphics provides a separate product, WorkShop Pro MPF, that provides a graphical interface to aid in both automatic and manual parallelization for Fortran 77. In particular, the WorkShop Pro MPF Parallel Analyzer View helps you understand the structure and parallelization of multiprocessing applications by providing an interactive, visual comparison of their original source with transformed, parallelized code. Refer to the Developer Magic: WorkShop Pro MPF User's Guide and the Developer Magic: Performance Analyzer User's Guide for details.
SpeedShop, another Silicon Graphics product, allows you to run experiments and generate reports to track down the sources of performance problems. SpeedShop consists of an API, a set of commands that can be run in a shell, and a number of libraries to support the commands. For more information, see the SpeedShop User's Guide.
You invoke a parallelized version of your program using the same command line as that used to run a sequential one. The same binary can be executed on various numbers of processors. The default is to have the run-time environment select the number of processors to use based on how many are available.
You can change the default behavior by setting the OMP_NUM_THREADS environment variable, which tells the system to use a particular number of processors. The following statement causes the program to create two threads regardless of the number of processors available:
setenv OMP_NUM_THREADS 2 |
Using OMP_NUM_THREADS is preferable to using MP_SET_NUMTHREADS and its older synonym NUM_THREADS, which preceded the release of the MIPSpro APO with OpenMP.
The OMP_DYNAMIC environment variable allows you to control whether the run-time environment should dynamically adjust the number of threads available for executing parallel regions to optimize the use of system resources. The default value is TRUE. If OMP_DYNAMIC is set to FALSE, dynamic adjustment is disabled.
A program's performance may be severely constrained if the APO cannot recognize that a loop is safe to parallelize. A loop is safe if there is no data dependence, such as a variable being assigned in one iteration of a loop and used in another. The MIPSpro APO analyzes every loop in a sequential program; if a loop does not appear safe, it does not parallelize that loop. It also often does not parallelize loops containing any of the following constructs:
function calls in loops, discussed in “Function Calls in Loops”
GO TO statements in loops, discussed in “GO TO Statements in Loops”
problematic array subscripts, discussed in “Problematic Array Subscripts”
conditionally assigned local variables, discussed in “Local Variables”
However, in many instances such loops can be automatically parallelized after minor changes. Reviewing your program's .list file, described in “The .list File”, can show you if any of these constructs are in your code.
By default, the Auto-Parallelizing Option does not parallelize a loop that contains a function call because the function in one iteration of the loop may modify or depend on data in other iterations. You can, however, use interprocedural analysis (IPA), specified by the -IPA command-line option, to provide the MIPSpro APO with enough information to parallelize some loops containing subroutine calls by inlining those calls. For more information on IPA, see “Interprocedural Analysis”, and the MIPSpro Compiling and Performance Tuning Guide.
You can also direct the MIPSpro APO to ignore the dependences of function calls when analyzing the specified loops by using the CONCURRENT CALL directive.
GO TO statements are unstructured control flows. The Auto-Parallelizing Option converts most unstructured control flows in loops into structured flows that can be parallelized. However, GO TO statements in loops can still cause two problems:
Unstructured control flows the MIPSpro APO cannot restructure. You must either restructure these control flows or manually parallelize the loops containing them.
Early exits from loops. Loops with early exits cannot be parallelized, either automatically or manually.
There are cases where array subscripts are too complicated to permit parallelization:
The subscripts are indirect array references. The MIPSpro APO is not able to analyze indirect array references. The following loop cannot be run safely in parallel if the indirect reference IB(I) is equal to the same value for different iterations of I:
DO I = 1, N A(IB(I)) = ... END DOIf every element of array IB is unique, the loop can safely be made parallel. To achieve parallelism in such cases, you can use either manual or automatic methods to achieve parallelism. For automatic parallelization, the C*$* ASSERT PERMUTATION assertion, discussed in “C*$* ASSERT PERMUTATION”, is appropriate.
The subscripts are unanalyzable. The MIPSpro APO cannot parallelize loops containing arrays with unanalyzable subscripts. Allowable subscripts can contain four elements: literal constants (1, 2, 3, ...); variables (I, J, K, ...); the product of a literal constant and a variable, such as N*5 or K*32; or a sum or difference of any combination of the first three items, such as N*21+K-251
In the following case, the MIPSpro APO cannot analyze the division operator (/) in the array subscript and cannot reorder the loop:
DO I = 2, N, 2 A(I/2) = ... END DOUnknown information. In the following example there may be hidden knowledge about the relationship between the variables M and N:
DO I = 1, N A(I) = A(I+M) END DOThe loop can be run in parallel if M > N, because the array reference does not overlap. However, the MIPSpro APO does not know the value of the variables and therefore cannot make the loop parallel. Using the C*$* ASSERT DO (CONCURRENT) assertion, explained in “C*$* ASSERT DO (CONCURRENT)”, lets the MIPSpro APO parallelize this loop. You can also use manual parallelization.
When parallelizing a loop, the Auto-Parallelizing Option often localizes (privatizes) temporary scalar and array variables by giving each processor its own non-shared copy of them. In the following example, the array TMP is used for local scratch space:
DO I = 1, N
DO J = 1, N
TMP(J) = ...
END DO
DO J = 1, N
A(J,I) = A(J,I) + TMP(J)
END DO
END DO |
To successfully parallelize the outer (I) loop, the MIPSpro APO must give each processor a distinct, private TMP array. In this example, it is able to localize TMP and, thereby, to parallelize the loop.
The MIPSpro APO runs into trouble when a conditionally assigned temporary variable might be used outside of the loop, as in the following example:
SUBROUTINE S1(A, B)
COMMON T
...
DO I = 1, N
IF (B(I)) THEN
T = ...
A(I) = A(I) + T
END IF
END DO
CALL S2()
END |
If the loop were to be run in parallel, a problem would arise if the value of T were used inside subroutine S2() because it is not known which processor's private copy of T should be used by S2(). If T were not conditionally assigned, the processor that executed iteration N would be used. Because T is conditionally assigned, the MIPSpro APO cannot determine which copy to use.
The solution comes with the realization that the loop is inherently parallel if the conditionally assigned variable T is localized. If the value of T is not used outside the loop, replace T with a local variable. Unless T is a local variable, the MIPSpro APO must assume that S2() might use it.
The Auto-Parallelizing Option parallelizes a loop by distributing its iterations among the available processors. When parallelizing nested loops, such as I, J, and K in the example below, the MIPSpro APO distributes only one of the loops:
DO I = 1, L
...
DO J = 1, M
...
DO K = 1, N
... |
Because of this restriction, the effectiveness of the parallelization of the nest depends on the loop that the MIPSpro APO chooses. In fact, the loop the MIPSpro APO parallelizes may be an inferior choice for any of three reasons:
It is an inner loop, as discussed in “Inner Loops”.
It has a small trip count, as discussed in “Small Trip Counts”.
It exhibits poor data locality, as discussed in “Poor Data Locality”.
The MIPSpro APO's heuristic methods are designed to avoid these problems. The next three sections show you how to increase the effectiveness of these methods.
With nested loops, the most effective optimization usually occurs when the outermost loop is parallelized. The effectiveness derives from more processors processing larger sections of the program, saving synchronization and other overhead costs. Therefore, the Auto-Parallelizing Option tries to parallelize the outermost loop, after possibly interchanging loops to make a more promising one outermost. If the outermost loop attempt fails, the MIPSpro APO parallelizes an inner loop if possible.
The .list file, described in “The .list File”, tells you which loop in a nest was parallelized. Because of the potential for improved performance, it is useful for you to modify your code so that the outermost loop is the one parallelized.
The trip count is the number of times a loop is executed. Loops with small trip counts generally run faster when they are not parallelized. Consider how this affects this Fortran example:
DO I = 1, M
DO J = 1, N |
The Auto-Parallelizing Option may try to parallelize the I loop because it is outermost. If M is very small, it would be better to interchange the loops and make the J loop outermost before parallelization. Because the MIPSpro APO often cannot know that M is small, you can use a C*$* ASSERT DO PREFER CONCURRENT assertion to indicate that it is better to parallelize the J loop, or use manual parallelization.
Computer memory has a hierarchical organization. Higher up the hierarchy, memory becomes closer to the CPU, faster, more expensive, and more limited in size. Cache memory is at the top of the hierarchy, and main memory is further down in the hierarchy. In multiprocessor systems, each processor has its own cache memory. Because it is time consuming for one processor to access another processor's cache, a program's performance is best when each processor has the data it needs in its own cache.
Programs, especially those that include extensive looping, often exhibit locality of reference; if a memory location is referenced, it is probable that it or a nearby location will be referenced in the near future. Loops designed to take advantage of locality do a better job of concentrating data in memory, increasing the probability that a processor will find the data it needs in its own cache.
To see the effect of locality on parallelization, consider Example C-5 and Example C-6. Assume that the loops are to be parallelized and that there are p processors.
Example C-5. Distribution of Iterations
DO I = 1, N
...A(I)
END DO
DO I = N, 1, -1
...A(I)...
END DO |
In the first loop of Example C-5, the first processor accesses the first N/p elements of A, the second processor accesses the next N/p elements, and so on. In the second loop, the distribution of iterations is reversed: The first processor accesses the last N/p elements of A, and so on. Most elements are not in the cache of the processor needing them during the second loop. This example should run more efficiently, and be a better candidate for parallelization, if you reverse the direction of one of the loops.
Example C-6. Two Nests in Sequence
DO I = 1, N
DO J = 1, N
A(I,J) = B(J,I) + ...
END DO
END DO
DO I = 1, N
DO J = 1, N
B(I,J) = A(J,I) + ...
END DO
END DO |
In Example C-6, the Auto-Parallelizing Option may parallelize the outer loop of each member of a sequence of nests. If so, while processing the first nest, the first processor accesses the first N/p rows of A and the first N/p columns of B. In the second nest, the first processor accesses the first N/p columns of A and the first N/p rows of B. This example runs much more efficiently if you parallelize the I loop in one nest and the J loop in the other. You can instruct the MIPSpro APO to do this with the C*$* ASSERT DO PREFER assertions.
There is overhead associated with distributing the iterations among the processors and synchronizing the results of the parallel computations. There can also be memory-related costs, such as the cache interference that occurs when different processors try to access the same data. One consequence of this overhead is that not all loops should be parallelized. As discussed in “Small Trip Counts”, loops that have a small number of iterations run faster sequentially than in parallel. The following are two other cases of unnecessary overhead:
unknown trip counts: If the trip count is not known (and sometimes even if it is), the Auto-Parallelizing Option parallelizes the loop conditionally, generating code for both a parallel and a sequential version. By generating two versions, the MIPSpro APO can avoid running a loop in parallel that may have small trip count. The MIPSpro APO chooses the version to use based on the trip count, the code inside the loop's body, the number of processors available, and an estimate of the cost to invoke a parallel loop in that run-time environment.
You can control this cost estimate by using the -LNO:parallel_overhead=n option. The default value of n varies on different systems, but a typical value is several thousand machine cycles.
You can avoid the overhead incurred by having a sequential and parallel version of the loop by using the C*$* ASSERT DO PREFER assertions. These compiler directives ensure that the MIPSpro APO knows in advance whether or not to parallelize the loop.
nested parallelism: nested parallelism is not supported by the Auto-Parallelizing Option. Thus, for every loop that could be parallelized, the MIPSpro APO must generate a test that determines if the loop is being called from within either another parallel loop or a parallel region. While this check is not very expensive, it can add overhead. The following example demonstrates nested parallelism:
SUBROUTINE CALLER DO I = 1, N CALL SUB END DO ... END SUBROUTINE SUB ... DO I = 1, N ... END DO ENDIf the loop inside CALLER() is parallelized, the loop inside SUB() cannot be run in parallel when CALLER() calls SUB(). In this case, the test can be avoided. If SUB() is always called from CALLER(), you can use the C*$* ASSERT DO (SERIAL) or the C*$* ASSERT DO PREFER (SERIAL) assertion to force the sequential execution of the loop in SUB(). For more information on these compiler directives, see “C*$* ASSERT DO (SERIAL)” and “C*$* ASSERT DO PREFER (SERIAL)”.
There are circumstances that interfere with the Auto-Parallelizing Option's ability to optimize programs. Problems are sometimes caused by coding practices or the MIPSpro APO may not have enough information to make good parallelization decisions. You can pursue three strategies to address these problems and to achieve better results with the MIPSpro APO.
The first approach is to modify your code to avoid coding practices that the MIPSpro APO cannot analyze well. Specific problems and solutions are discussed in “Failing to Parallelize Safe Loops” and “Parallelizing the Wrong Loop”.
The second strategy is to assist the MIPSpro APO with the manual parallelization directives. They are described in the MIPSpro Compiling and Performance Tuning Guide, and require the -mp compiler option. The MIPSpro APO is designed to recognize and coexist with manual parallelism. You can use manual directives with some loop nests, while leaving others to the MIPSpro APO. This approach has both positive and negative aspects.
Positive: The manual parallelization directives are well defined and deterministic. If you use a manual directive, the specified loop is run in parallel. This assumes that the trip count is greater than one and that the specified loop is not nested in another parallel loop.
Negative: You must carefully analyze the code to determine that parallelism is safe. Also, you must mark all variables that need to be localized.
The third alternative is to use the automatic parallelization compiler directives to give the MIPSpro APO more information about your code. The automatic directives are described in “Compiler Directives for Automatic Parallelization”. Like the manual directives, they have positive and negative features.
Positive: The automatic directives are easier to use. They allow you to express the information you know without needing to be certain that all the conditions for parallelization are met.
Negative: The automatic directives are tips and thus do not impose parallelism. In addition, as with the manual directives, you must ensure that you are using them safely. Because they require less information than the manual directives, automatic directives can have subtle meanings.
The Auto-Parallelizing Option recognizes three types of compiler directives:
Fortran directives, which enable, disable, or modify features of the MIPSpro APO
Fortran assertions, which assist the MIPSpro APO by providing it with additional information about the source program
Pragmas, the C and C++ counterparts to Fortran directives and assertions (discussed in the documentation with your C compiler).
In practice, the MIPSpro APO makes little distinction between Fortran assertions and Fortran directives. The automatic parallelization compiler directives do not impose parallelism; they give hints and assertions to the MIPSpro APO to assist it in choosing the right loops. Table C-1 lists the directives, assertions, and pragmas that the MIPSpro APO recognizes.
Table C-1. Auto-Parallelizing Option Directives and Assertions
Compiler Directive | Meaning and Notes |
|---|---|
C*$* NO CONCURRENTIZE | Varies with placement. Either do not parallelize any loops in a subroutine, or do not parallelize any loops in a file. |
C*$* CONCURRENTIZE | Override C*$* NO CONCURRENTIZE. |
C*$* ASSERT DO (CONCURRENT) | Do not let perceived dependences between two references to the same array inhibit parallelizing. Does not require -apo. |
C*$* ASSERT DO (SERIAL) | Do not parallelize the following loop. |
C*$* ASSERT CONCURRENT CALL | Ignore dependences in subroutine calls that would inhibit parallelizing. Does not require -apo. |
C*$* ASSERT PERMUTATION (array_name) | Array array_name is a permutation array. Does not require -apo. |
C*$* ASSERT DO PREFER (CONCURRENT) | Parallelize the following loop if it is safe. |
C*$* ASSERT DO PREFER (SERIAL) | Do not parallelize the following loop. |
Three compiler directives affect the compiling process even if -apo is not specified: C*$* ASSERT DO (CONCURRENT) may affect optimizations such as loop interchange; C*$* ASSERT CONCURRENT CALL also may affect optimizations such as loop interchange; and C*$* ASSERT PERMUTATION may affect any optimization that requires permutation arrays..
The general compiler option -LNO:ignore_pragmas causes the MIPSpro APO to ignore all of the directives, assertions, and pragmas discussed in this section.
The C*$* NO CONCURRENTIZE directive prevents parallelization. Its effect depends on its placement.
When placed inside subroutines and functions, the directive prevents their parallelization. In the following example, no loops inside SUB1() are parallelized.
SUBROUTINE SUB1 C*$* NO CONCURRENTIZE ... ENDWhen placed outside of a subroutine, C*$* NO CONCURRENTIZE prevents the parallelization of all subroutines in the file, even those that appear ahead of it in the file. Loops inside subroutines SUB2() and SUB3() are not parallelized in this example:
SUBROUTINE SUB2 ... END C*$* NO CONCURRENTIZE SUBROUTINE SUB3 ... END
Placing the C*$* CONCURRENTIZE directive inside a subroutine overrides a C*$* NO CONCURRENTIZE directive placed outside it. Thus, this directive allows you to selectively parallelize subroutines in a file that has been made sequential with C*$* NO CONCURRENTIZE.
C*$* ASSERT DO (CONCURRENT) instructs the MIPSpro APO, when analyzing the loop immediately following this assertion, to ignore all dependences between two references to the same array. If there are real dependences between array references, C*$* ASSERT DO (CONCURRENT) may cause the MIPSpro APO to generate incorrect code. The following example is a correct use of the assertion when M>N:
C*$* ASSERT DO (CONCURRENT)
DO I = 1, N
A(I) = A(I+M) |
Be aware of the following points when using this assertion:
If multiple loops in a nest can be parallelized, C*$* ASSERT DO (CONCURRENT) causes the MIPSpro APO to prefer the loop immediately following the assertion.
Applying this directive to an inner loop may cause the loop to be made outermost by the MIPSpro APO's loop interchange operations.
The assertion does not affect how the MIPSpro APO analyzes CALL statements. See “C*$* ASSERT CONCURRENT CALL”.
The assertion does not affect how the MIPSpro APO analyzes dependences between two potentially aliased pointers.
This assertion affects the compilation even when -apo is not specified.
The compiler may find some obvious real dependences. If it does so, it ignores this assertion.
C*$* ASSERT DO (SERIAL) instructs the Auto-Parallelizing Option not to parallelize the loop following the assertion. However, the MIPSpro APO may parallelize another loop in the same nest. The parallelized loop may be either inside or outside the designated sequential loop.
The C*$* ASSERT CONCURRENT CALL assertion instructs the MIPSpro APO to ignore the dependences of subroutine and function calls contained in the loop that follows the assertion. Other points to be aware of are the following:
The assertion applies to the loop that immediately follows it and to all loops nested inside that loop.
The assertion affects the compilation even when -apo is not specified.
The MIPSpro APO ignores the dependences in subroutine FRED() when it analyzes the following loop:
C*$* ASSERT CONCURRENT CALL
DO I = 1, N
CALL FRED
...
END DO
SUBROUTINE FRED
...
END |
To prevent incorrect parallelization, make sure the following conditions are met when using C*$* ASSERT CONCURRENT CALL:
A subroutine inside the loop cannot read from a location that is written to during another iteration. This rule does not apply to a location that is a local variable declared inside the subroutine.
A subroutine inside the loop cannot write to a location that is read from or written to during another iteration. This rule does not apply to a location that is a local variable declared inside the subroutine.
The following code shows an illegal use of the assertion. Subroutine FRED() writes to variable T, which is also read from by WILMA() during other iterations.
C*$* ASSERT CONCURRENT CALL
DO I = 1,M
CALL FRED(B, I, T)
CALL WILMA(A, I, T)
END DO
SUBROUTINE FRED(B, I, T)
REAL B(*)
T = B(I)
END
SUBROUTINE WILMA(A, I, T)
REAL A(*)
A(I) = T
END |
By localizing the variable T, you can manually parallelize the above example safely. But the MIPSpro APO does not know to localize T, and it illegally parallelizes the loop because of the assertion.
When placed inside a subroutine, C*$* ASSERT PERMUTATION (array_name) tells the MIPSpro APO that array_name is a permutation array. Every element of the array has a distinct value. The assertion does not require the permutation array to be dense. While every IB(I) must have a distinct value, there can be gaps between those values, such as IB(1) = 1, IB(2) = 4, IB(3) = 9, and so on.
Array IB is asserted to be a permutation array for both loops in SUB1() in this example.
SUBROUTINE SUB1
DO I = 1, N
A(IB(I)) = ...
END DO
C*$* ASSERT PERMUTATION (IB)
DO I = 1, N
A(IB(I)) = ...
END DO
END |
Note the following points about this assertion:
As shown in the example, you can use this assertion to parallelize loops that use arrays for indirect addressing. Without this assertion, the MIPSpro APO cannot determine that the array elements used as indexes are distinct.
C*$* ASSERT PERMUTATION (array_name) affects every loop in a subroutine, even those that appear ahead it.
The assertion affects compilation even when -apo is not specified.
C*$* ASSERT DO PREFER (CONCURRENT) instructs the Auto-Parallelizing Option to parallelize the loop immediately following the assertion, if it is safe to do so. This assertion is always safe to use. Unless it can determine the loop is safe, the MIPSpro APO does not parallelize a loop because of this assertion.
The following code encourages the MIPSpro APO to run the I loop in parallel:
C*$* ASSERT DO PREFER (CONCURRENT)
DO I = 1, M
DO J = 1, N
A(I,J) = B(I,J)
END DO
...
END DO |
When dealing with nested loops, the Auto-Parallelizing Option follows these guidelines:
If the loop specified by this assertion is safe to parallelize, the MIPSpro APO chooses it to parallelize, even if other loops in the nest are safe.
If the specified loop is not safe to parallelize, the MIPSpro APO uses its heuristics to choose among loops that are safe.
If this directive is applied to an inner loop, the MIPSpro APO may make it the outermost loop.
If this assertion is applied to more than one loop in a nest, the MIPSpro APO uses its heuristics to choose one of the specified loops.
The C*$* ASSERT DO PREFER (SERIAL) assertion instructs the Auto-Parallelizing Option not to parallelize the loop that immediately follows. It is essentially the same as C*$* ASSERT DO (SERIAL). In the following case, the assertion requests that the J loop be run serially:
DO I = 1, M
C*$* ASSERT DO PREFER (SERIAL)
DO J = 1, N
A(I,J) = B(I,J)
END DO
...
END DO |
The assertion applies only to the loop directly after the assertion. For example, the MIPSpro APO still tries to parallelize the I loop in the code shown above. The assertion is used in cases like this when the value of N is very small.