This chapter outlines techniques for tuning the performance of your R8000 and R10000 applications. It contains five sections:
The first section provides an architectural overview of the R8000 and R10000. This will serve as background for the software pipelining discussion.
The second section presents the compiler optimization technique of software pipelining, which is crucial to getting optimal performance on the R8000. It shows you how to read your software pipelined code and how to understand what it does.
The third section uses matrix multiplies as a case study on loop unrolling.
The fourth section describes how the IVDEP directive can be used in Fortran to gain performance.
The final section describes how using vector intrinsic functions can improve the performance of your program.
Table 6-1 illustrates the main architectural features of the R8000 and R10000 microprocessors. Both can execute the MIPS IV instruction set and both can issue up to four instructions per cycle, of which two can be integer instructions and two can be floating point instructions. The R8000 can execute up to two madd instructions per cycle, while the R10000 can only execute one per cycle.The R8000 can issue two memory instructions per cycle while the R10000 can issue one per cycle. On the other hand, the R10000 operates at a much faster clock frequency and is capable of out-of-order execution. This makes it a better candidate for executing programs that were not explicitly tuned for it.
Table 6-1. Architectural Features of the R8000 and R10000
Feature | R8000 | R10000 |
|---|---|---|
ISA | MIPS IV | MIPS IV |
Frequency | 90 Mhz | 200 Mhz |
Peak MFLOPS | 360 | 400 |
Total Number of Instructions per cycle | 4 | 4 |
Number of Integer Instructions per cycle | 2 | 2 |
Number of Floating Point Instructions per cycle | 2 | 2 |
Number of Multiply-Add Instructions per cycle. | 2 | 1 |
Number of Load/Store Instructions per cycle | 2 | 1 |
Out-of-order Instruction execution | No | Yes |
The purpose of this section is to give you an overview of software pipelining and to answer these questions:
Why software pipelining delivers better performance
How software pipelined code looks
How to diagnose what happened when things go wrong
To introduce the topic of software pipelining, let's consider the simple DAXPY loop (double precision a times x plus y) shown below.
DO i = 1, n
v(i) = v(i) + X * w(i)
ENDDO |
On the MIPS IV architecture, this can be coded as two load instructions followed by a madd instruction and a store. See Figure 6-1.
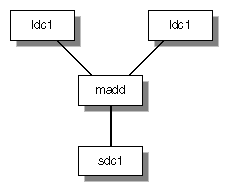
This simplest schedule achieves the desired result after five cycles. Since the R8000 architecture can allow up to two memory operations and two floating point operations in the same cycle, this simple example uses only one tenth of the R8000's peak megaflops. There is also a delay of three cycles before the results of the madd can be stored.
0: ldc1 ldc1 madd 1: 2: 3: 4: sdc1 |
A loop unrolling by four schedule improves the performance to one quarter of the R8000's peak megaflops.
0: ldc1 ldc1 madd 1: ldc1 ldc1 madd 2: ldc1 ldc1 madd 3: ldc1 ldc1 madd 4: sdc1 5: sdc1 6: sdc1 7: sdc1 |
But this schedule does not take advantage of the R8000's ability to do two stores in one cycle.The best schedule that could be achieved would look like the following:
0: ldc1 ldc1 1: ldc1 ldc1 madd madd 2: sdc1 sdc1 |
It uses 1/3 of the R8000's peak megaflops. But there still is a problem with the maddsdc1 interlock delay. Software pipelining addresses this problem.
Software pipelining allows you to mix operations from different loop iterations in each iteration of the hardware loop. Thus the store instructions (which would interlock) in the above example could be used to store the results of different iterations. This can look like the following:
L1: 0: t1 = ldc1 t2 = ldc1 t3 = madd t1 X t2 1: t4 = ldc1 t5 = ldc1 t6 = madd t4 X t5 2: sdc1 t7 sdc1 t8 beq DONE 3: t1 = ldc1 t2 = ldc1 t7 = madd t1 X t2 4: t4 = ldc1 t5 = ldc1 t8 = madd t4 X t5 5: sdc1 t3 sdc1 t6 bne L1 DONE: |
The stores in this loop are storing the madd results from previous iterations. But, in general, you could mix any operations from any number of different iterations. Also, note that every loop replication completes two loop iterations in 3 cycles.
In order to properly prepare for entry into such a loop, a windup section of code is added. The windup section sets up registers for the first stores in the main loop. In order to exit the loop properly, a winddown section is added. The winddown section performs the final stores. Any preparation of registers needed for the winddown is done in the compensation section. The winddown section also prevents speculative operations.
windup: 0: t1 = ldc1 t2 = ldc1 t7 = madd t1 X t2 1: t4 = ldc1 t5 = ldc1 t8 = madd t4 X t5 L1: 0: t1 = ldc1 t2 = ldc1 t3 = madd t1 X t2 1: t4 = ldc1 t5 = ldc1 t6 = madd t4 X t5 2: sdc1 t7 sdc1 t8 beq compensation1 3: t1 = ldc1 t2 = ldc1 t7 = madd t1 X t2 4: t4 = ldc1 t5 = ldc1 t8 = madd t4 X t5 5: sdc1 t3 sdc1 t6 bne L1 winddown: 0: sdc1 t7 sdc1 t8 br ALLDONE compensation1: 0: t7 = t3 t8 = t6 1: br winddown ALLDONE: |
Our example loop always does loads from at least 4 iterations, so we don't want to start it if we don't want speculative operations and if the trip count is less than 4. The following generalizes our example into a map of a software pipelined loop:
/* Precondition for unroll by 2 */
do i = 1, n mod 2
original loop
enddo
if ( n-i < 4 ) goto simple_loop
windup:
...
/* fp - fence post */
fp = fp - peel_amount
...
swp replication 0:
...
if ( i == fp ) goto compensation 0
...
swp replication n - 1:
...
if ( i != fp ) goto swp replication 0
compensation n-1:
winddown:
...
goto done
compensation 0:
/* Move registers to set up winddown */
rx = ry
...
goto winddown
...
compensation n - 2:
...
/* Move registers to set up winddown */
rx = ry
goto winddown
simple_loop:
do i = i,n
original_loop
enddo
done: |
In practice, software pipelining can make a huge difference. Sample benchmark performances see more than 100% improvement when compiled with software pipelining. This makes it clear that in order to get the best performance on the R8000 (-mips4), you should compile your application to use software pipelining (-O3 -r8000).
Scheduling for the R10000 (-r10000) is somewhat different. First of all, since the R10000 can execute instructions out-of-order, static scheduling techniques are not as critical to its performance. On the other hand, the R10000 supports the prefetch (pref) instruction. This instruction is used to load data into the caches before it is needed, reducing memory delays for programs that access memory predictably. In the schedule below, the compiler generates prefetch instructions.
Since the R10000 can execute only one memory instruction and only one madd instruction per cycle, there are two open slots available for integer instructions. The R10000 has a delay of three cycles before the results of the madd can be stored. It also has delays of three cycles and one cycle before the madd can use the result of a load for multiplication and addition, respectively.
The following schedule shows four replications from a daxpy inner loop scheduled for the R10000. Notice how the operands of the madd instruction are loaded well ahead of the actual execution of the instruction itself. Notice also that the final replication contains two prefetch instructions. Use of the prefetch instruction is enabled by default with the -r10000 flag. The other replications each have a hole where the first prefetch instruction is placed. Had prefetch been turned off through the -LNO:prefetch=0 option, each replication could have been scheduled in three cycles.
L1: 0: t0 = ldc1 1: 2: t7 = ldc1 3: sdc1 t2 4: t2 = madd t4 X t5 beq compensation0 0: t4 = ldc1 1: 2: t3 = ldc1 3: sdc1 t2 4: t2 = madd t0 X t1 beq compensation1 0: t0 = ldc1 1: 2: t5 = ldc1 3: sdc1 t2 4: t2 = madd t4 X t7 beq compensation2 0: t4 = ldc1 1: pref 2: t1 = ldc1 3: sdc1 t2 4: t2 = madd t0 X t3 bne L1 pref |
The proper way to look at the assembly code generated by software pipelining is to use the -S compiler switch. This is vastly superior to using the disassembler (dis) because the -S switch adds annotations to the assembly code which name out the sections described above.
The annotations also provide useful statistics about the software pipelining process as well as reasons why certain code did not pipeline. To get a summary of these annotations do the following:
%f77 -64 -S -O3 -mips4 foo.f |
This creates an annotated .s file
%grep '#<swp' foo.s |
#<swpf is printed for loops that failed to software pipeline. #<swps is printed for statistics and other info about the loops that did software pipeline.
%cat test.f
program test
real*8 a x(100000),y(100000)
do i = 1, 2000
call daxpy(3.7, x, y, 100000)
enddo
stop
end
subroutine daxpy(a, x, y, nn)
real*8 a x(*),y(*)
do i = 1, nn, 1
y(i) = y(i) + a * x(i)
enddo
return
end
%f77 -64 -r8000 -mips4 -O3 -S test.f
%grep swps test.s
#<swps>
#<swps> Pipelined loop line 12 steady state
#<swps>
#<swps> 25 estimated iterations before pipelining
#<swps> 4 unrollings before pipelining
#<swps> 6 cycles per 4 iterations
#<swps> 8 flops ( 33% of peak) (madds count as 2)
#<swps> 4 flops ( 33% of peak) (madds count as 1)
#<swps> 4 madds ( 33% of peak)
#<swps> 12 mem refs (100% of peak)
#<swps> 3 integer ops ( 25% of peak)
#<swps> 19 instructions( 79% of peak)
#<swps> 2 short trip threshold
#<swps> 7 integer registers used
#<swps> 14 float registers used
#<swps> |
This example was compiled with scheduling for the R8000. It shows that the inner loop starting at line 12 was software pipelined. The loop was unrolled four times before pipelining. It used 6 cycles for every four loop iterations and calculated the statistics as follows:
If each madd counts as two floating point operations, the R8000 can do four floating point operations per cycle (two madds), so its peak for this loop is 24. Eight floating point references are 8/24 or 33% of peak. The figure for madds is likewise calculated.
If each madd counts as one floating point operation, the R8000 can do two floating point operations per cycle, so its peak for this loop is 12. Four floating point operations are 4/12 or 33% of peak.
The R8000 can do two memory operations per cycle, so its peak for this loop is 12. Twelve memory references are 12/12 or 100% of peak.
The R8000 can do two integer operations per cycle, so its peak for this loop is 12. Three integer references are 3/12 or 25% of peak.
The R8000 can do four instructions per cycle, so its peak for this loop is 24. Nineteen instructions are 19/24 or 79% of peak. The statistics also point out that loops of less than 2 iterations would not go through the software pipeline replication area, but would be executed in the simple_loop section shown above and that a total of seven integer and eight floating point registers were used in generating the code.
If the example would have been compiled with scheduling for the R10000, the following results would have been obtained.
%f77 -64 -r10000 -mips4 -O3 -S test.f %grep swps test.s #<swps> #<swps> Pipelined loop line 12 steady state #<swps> #<swps> 25 estimated iterations before pipelining #<swps> 4 unrollings before pipelining #<swps> 14 cycles per 4 iterations #<swps> 8 flops ( 28% of peak) (madds count as 2) #<swps> 4 flops ( 14% of peak) (madds count as 1) #<swps> 4 madds ( 28% of peak) #<swps> 12 mem refs ( 85% of peak) #<swps> 3 integer ops ( 10% of peak) #<swps> 19 instructions( 33% of peak) #<swps> 2 short trip threshold #<swps> 7 integer registers used #<swps> 15 float registers used #<swps> |
The statistics are tailored to the R10000 architectural characteristics. They show that the inner loop starting at line 12 was unrolled four times before being pipelined. It used 14 cycles for every four loop iterations and the percentages were calculated as follows:
The R10000 can do two floating point operations per cycle (one multiply and one add), so its floating point operations peak for this loop is 28. If each madd instruction counts as a multiply and an add, the number of operations in this loop are 8/28 or 28% of peak.
If each madd counts as one floating point instruction, the R10000 can do two floating point operations per cycle (one multiply and one add), so its peak for this loop is 28. Four floating point operations (four madds) are 4/28 or 14% of peak.
The R10000 can do one madd operation per cycle, so its peak for this loop is 14. Four madd operations are 4/14 or 28% of peak.
The R10000 can do one memory operation per cycle, so its peak for this loop is 14. Three memory references are 12/14 or 85% of peak.
 | Note: prefetch operations are sometimes not needed in every replication. The statistics will miss them if they are not in replication 0 and they will understate the number of memory references per cycle while overstating the number of cycles per iteration. |
The R10000 can do two integer operations per cycle, so its peak for this loop is 28. Three integer operations are 3/28 or 10% of peak.
The R10000 can do four instructions per cycle, so its peak for this loop is 56. Nineteen instructions are 19/56 or 33% of peak. The statistics also point out that loops of less than 2 iterations would not go through the software pipeline replication area, but would be executed in the simple_loop section shown above and that a total of seven integer and fifteen floating point registers were used in generating the code.
When you don't get much improvement in your application's performance after compiling with software pipelining, you should ask the following questions and consider some possible answers:
Did it software pipeline at all?
Software pipelining works only on inner loops. What is more, inner loops with subroutine calls or complicated conditional branches do not software pipeline.
How well did it pipeline?
Look at statistics in the .s file.
What can go wrong in code that was software pipelined?
Your generated code may not have the operations you expected.
Think about how you would hand code it.
What operations did it need?
Look at the loop in the .s file.
Is it very different? Why?
Sometimes this is human error. (Improper code, or typo.)
Sometimes this is a compiler error.
Perhaps the compiler didn't schedule tightly. This can happen because there are unhandled recurrence divides (Divides in general, are a problem) and because there are register allocation problems (running out of registers).
Matrix multiplication illustrates some of the issues in compiling for the R8000 and R10000. Consider the simple implementation.
do j = 1,n
do i = 1,m
do k = 1 , p
c(i,j) = c(i,j) - a(i,k)*b(k,j) |
As mentioned before, the R8000 is capable of issuing two madds and two memory references per cycle. This simple version of matrix multiply requires 2 loads in the inner loop and one madd. Thus at best, it can run at half of peak speed. Note, though, that the same locations are loaded on multiple iterations. By unrolling the loops, we can eliminate some of these redundant loads. Consider for example, unrolling the outer loop by 2.
do j = 1,n,2
do i = 1,m
do k = 1 , p
c(i,j) = c(i,j) - a(i,k)*b(k,j)
c(i,j+1) = c(i,j+1) - a(i,k)*b(k,j+1) |
We now have 3 loads for two madds. Further unrolling can bring the ratio down further. On the other hand, heavily unrolled loops require many registers. Unrolling too much can lead to register spills. The loop nest optimizer (LNO) tries to balance these trade-offs.
Below is a good compromise for the matrix multiply example on the R8000. It is generated by LNO using the -O3 and -r8000 flags. The listing file is generated using -FLIST:=ON option.
%f77 -64 -O3 -r8000 -FLIST:=ON mmul.f
%cat mmul.w2f.f
C ***********************************************************
C Fortran file translated from WHIRL Mon Mar 22 09:31:25 1999
C ***********************************************************
PROGRAM MAIN
IMPLICIT NONE
C
C **** Variables and functions ****
C
REAL*8 a(100_8, 100_8)
REAL*8 b(100_8, 100_8)
REAL*8 c(100_8, 100_8)
INTEGER*4 j
INTEGER*4 i
INTEGER*4 k
C
C **** Temporary variables ****
C
REAL*8 mi0
REAL*8 mi1
REAL*8 mi2
REAL*8 mi3
REAL*8 mi4
REAL*8 mi5
REAL*8 mi6
REAL*8 mi7
REAL*8 mi8
REAL*8 mi9
REAL*8 mi10
REAL*8 mi11
REAL*8 c_1
REAL*8 c_
REAL*8 c_0
REAL*8 c_2
REAL*8 c_3
REAL*8 c_4
REAL*8 c_5
REAL*8 c_6
REAL*8 c_7
REAL*8 c_8
REAL*8 c_9
REAL*8 c_10
INTEGER*4 i0
REAL*8 mi12
REAL*8 mi13
REAL*8 mi14
REAL*8 mi15
INTEGER*4 k0
REAL*8 c_11
REAL*8 c_12
REAL*8 c_13
REAL*8 c_14
C
C **** statements ****
C
DO j = 1, 8, 3
DO i = 1, 20, 4
mi0 = c(i, j)
mi1 = c((i + 3), (j + 2))
mi2 = c((i + 3), (j + 1))
mi3 = c(i, (j + 1))
mi4 = c((i + 3), j)
mi5 = c((i + 2), (j + 2))
mi6 = c((i + 2), (j + 1))
mi7 = c(i, (j + 2))
mi8 = c((i + 2), j)
mi9 = c((i + 1), (j + 2))
mi10 = c((i + 1), (j + 1))
mi11 = c((i + 1), j)
DO k = 1, 20, 1
c_1 = mi0
mi0 = (c_1 -(a(i, k) * b(k, j)))
c_ = mi3
mi3 = (c_ -(a(i, k) * b(k, (j + 1))))
c_0 = mi7
mi7 = (c_0 -(a(i, k) * b(k, (j + 2))))
c_2 = mi11
mi11 = (c_2 -(a((i + 1), k) * b(k, j)))
c_3 = mi10
mi10 = (c_3 -(a((i + 1), k) * b(k, (j + 1))))
c_4 = mi9
mi9 = (c_4 -(a((i + 1), k) * b(k, (j + 2))))
c_5 = mi8
mi8 = (c_5 -(a((i + 2), k) * b(k, j)))
c_6 = mi6
mi6 = (c_6 -(a((i + 2), k) * b(k, (j + 1))))
c_7 = mi5
mi5 = (c_7 -(a((i + 2), k) * b(k, (j + 2))))
c_8 = mi4
mi4 = (c_8 -(a((i + 3), k) * b(k, j)))
c_9 = mi2
mi2 = (c_9 -(a((i + 3), k) * b(k, (j + 1))))
c_10 = mi1
mi1 = (c_10 -(a((i + 3), k) * b(k, (j + 2))))
END DO
c((i + 1), j) = mi11
c((i + 1), (j + 1)) = mi10
c((i + 1), (j + 2)) = mi9
c((i + 2), j) = mi8
c(i, (j + 2)) = mi7
c((i + 2), (j + 1)) = mi6
c((i + 2), (j + 2)) = mi5
c((i + 3), j) = mi4
c(i, (j + 1)) = mi3
c((i + 3), (j + 1)) = mi2
c((i + 3), (j + 2)) = mi1
c(i, j) = mi0
END DO
END DO
DO i0 = 1, 20, 4
mi12 = c(i0, 10_8)
mi13 = c((i0 + 1), 10_8)
mi14 = c((i0 + 3), 10_8)
mi15 = c((i0 + 2), 10_8)
DO k0 = 1, 20, 1
c_11 = mi12
mi12 = (c_11 -(a(i0, k0) * b(k0, 10_8)))
c_12 = mi13
mi13 = (c_12 -(a((i0 + 1), k0) * b(k0, 10_8)))
c_13 = mi15
mi15 = (c_13 -(a((i0 + 2), k0) * b(k0, 10_8)))
c_14 = mi14
mi14 = (c_14 -(a((i0 + 3), k0) * b(k0, 10_8)))
END DO
c((i0 + 2), 10_8) = mi15
c((i0 + 3), 10_8) = mi14
c((i0 + 1), 10_8) = mi13
c(i0, 10_8) = mi12
END DO
WRITE(6, '(F18.10)') c(9_8, 8_8)
STOP
END ! MAIN |
The outermost loop is unrolled by three as suggested above and the second loop is unrolled by a factor of four. Note that we have not unrolled the inner loop. The code generation phase of the compiler back end can effectively unroll inner loops automatically to eliminate redundant loads.
In optimizing for the R10000, LNO also unrolls the outermost loop by three, but unrolls the second loop by 5. LNO can also automatically tile the code to improve cache behavior. You can use the -LNO: option group flags to describe your cache characteristics to LNO. For more information, please consult the MIPSpro Compiling, Debugging and Performance Tuning Guide.
%f77 -64 -O3 -r10000 -FLIST:=ON mmul.f
%cat mmul.w2f.f
C ***********************************************************
C Fortran file translated from WHIRL Mon Mar 22 09:41:39 1999
C ***********************************************************
PROGRAM MAIN
IMPLICIT NONE
C
C **** Variables and functions ****
C
REAL*8 a(100_8, 100_8)
REAL*8 b(100_8, 100_8)
REAL*8 c(100_8, 100_8)
INTEGER*4 j
INTEGER*4 i
INTEGER*4 k
C
C **** Temporary variables ****
C
REAL*8 mi0
REAL*8 mi1
REAL*8 mi2
REAL*8 mi3
REAL*8 mi4
REAL*8 mi5
REAL*8 mi6
REAL*8 mi7
REAL*8 mi8
REAL*8 mi9
REAL*8 mi10
REAL*8 mi11
REAL*8 mi12
REAL*8 mi13
REAL*8 mi14
INTEGER*4 i0
REAL*8 mi15
REAL*8 mi16
REAL*8 mi17
REAL*8 mi18
REAL*8 mi19
INTEGER*4 k0
REAL*8 mi20
REAL*8 mi21
REAL*8 mi22
REAL*8 mi23
REAL*8 mi24
C
C **** statements ****
C
DO j = 1, 8, 3
DO i = 1, 20, 5
mi0 = c(i, j)
mi1 = c((i + 4), (j + 2))
mi2 = c((i + 4), (j + 1))
mi3 = c(i, (j + 1))
mi4 = c((i + 4), j)
mi5 = c((i + 3), (j + 2))
mi6 = c((i + 3), (j + 1))
mi7 = c(i, (j + 2))
mi8 = c((i + 3), j)
mi9 = c((i + 2), (j + 2))
mi10 = c((i + 2), (j + 1))
mi11 = c((i + 1), j)
mi12 = c((i + 2), j)
mi13 = c((i + 1), (j + 2))
mi14 = c((i + 1), (j + 1))
DO k = 1, 20, 1
mi0 = (mi0 -(a(i, k) * b(k, j)))
mi3 = (mi3 -(a(i, k) * b(k, (j + 1))))
mi7 = (mi7 -(a(i, k) * b(k, (j + 2))))
mi11 = (mi11 -(a((i + 1), k) * b(k, j)))
mi14 = (mi14 -(a((i + 1), k) * b(k, (j + 1))))
mi13 = (mi13 -(a((i + 1), k) * b(k, (j + 2))))
mi12 = (mi12 -(a((i + 2), k) * b(k, j)))
mi10 = (mi10 -(a((i + 2), k) * b(k, (j + 1))))
mi9 = (mi9 -(a((i + 2), k) * b(k, (j + 2))))
mi8 = (mi8 -(a((i + 3), k) * b(k, j)))
mi6 = (mi6 -(a((i + 3), k) * b(k, (j + 1))))
mi5 = (mi5 -(a((i + 3), k) * b(k, (j + 2))))
mi4 = (mi4 -(a((i + 4), k) * b(k, j)))
mi2 = (mi2 -(a((i + 4), k) * b(k, (j + 1))))
mi1 = (mi1 -(a((i + 4), k) * b(k, (j + 2))))
END DO
c((i + 1), (j + 1)) = mi14
c((i + 1), (j + 2)) = mi13
c((i + 2), j) = mi12
c((i + 1), j) = mi11
c((i + 2), (j + 1)) = mi10
c((i + 2), (j + 2)) = mi9
c((i + 3), j) = mi8
c(i, (j + 2)) = mi7
c((i + 3), (j + 1)) = mi6
c((i + 3), (j + 2)) = mi5
c((i + 4), j) = mi4
c(i, (j + 1)) = mi3
c((i + 4), (j + 1)) = mi2
c((i + 4), (j + 2)) = mi1
c(i, j) = mi0
END DO
END DO
DO i0 = 1, 20, 5
IF(IAND(i0, 31) .EQ. 16) THEN
mi15 = c(i0, 10_8)
mi16 = c((i0 + 1), 10_8)
mi17 = c((i0 + 4), 10_8)
mi18 = c((i0 + 2), 10_8)
mi19 = c((i0 + 3), 10_8)
DO k0 = 1, 20, 1
mi15 = (mi15 -(a(i0, k0) * b(k0, 10_8)))
mi16 = (mi16 -(a((i0 + 1), k0) * b(k0, 10_8)))
mi18 = (mi18 -(a((i0 + 2), k0) * b(k0, 10_8)))
mi19 = (mi19 -(a((i0 + 3), k0) * b(k0, 10_8)))
mi17 = (mi17 -(a((i0 + 4), k0) * b(k0, 10_8)))
END DO
c((i0 + 3), 10_8) = mi19
c((i0 + 2), 10_8) = mi18
c((i0 + 4), 10_8) = mi17
c((i0 + 1), 10_8) = mi16
c(i0, 10_8) = mi15
ELSE
mi20 = c(i0, 10_8)
mi21 = c((i0 + 1), 10_8)
mi22 = c((i0 + 4), 10_8)
mi23 = c((i0 + 2), 10_8)
mi24 = c((i0 + 3), 10_8)
DO k0 = 1, 20, 1
mi20 = (mi20 -(a(i0, k0) * b(k0, 10_8)))
mi21 = (mi21 -(a((i0 + 1), k0) * b(k0, 10_8)))
mi23 = (mi23 -(a((i0 + 2), k0) * b(k0, 10_8)))
mi24 = (mi24 -(a((i0 + 3), k0) * b(k0, 10_8)))
mi22 = (mi22 -(a((i0 + 4), k0) * b(k0, 10_8)))
END DO
c((i0 + 3), 10_8) = mi24
c((i0 + 2), 10_8) = mi23
c((i0 + 4), 10_8) = mi22
c((i0 + 1), 10_8) = mi21
c(i0, 10_8) = mi20
ENDIF
END DO
WRITE(6, '(F18.10)') c(9_8, 8_8)
STOP
END ! MAIN |
The IVDEP (Ignore Vector Dependencies) directive was started in Cray Fortran. It is a Fortran or C pragma that tells the compiler to be less strict when it is deciding whether it can get parallelism between loop iterations. By default, the compilers do the safe thing: they try to prove to that there is no possible conflict between two memory references. If they can prove this, then it is safe for one of the references to pass the other.
In particular, you need to be able to perform the load from iteration i+1 before the store from iteration i if you want to be able to overlap the calculation from two consecutive iterations.
Now suppose you have a loop like:
do i = 1, n a(l(i)) = a(l(i)) + ... enddo |
The compiler has no way to know that
&a(l(i)) != &a(l(i+1)) |
without knowing something about the vector l. For example, if every element of l is 5, then
&a(l(i)) == &a(l(i+1)) |
for all values of i.
But you sometimes know something the compiler doesn't. Perhaps in the example above, l is a permutation vector and all its elements are unique. You'd like a way to tell the compiler to be less conservative. The IVDEP directive is a way to accomplish this.
Placed above a loop, the statement:
cdir$ ivdep |
tells the compiler to assume there are no dependencies in the code.
The MIPSpro v7.x compilers provide support for three different interpretations of the IVDEP directive, because there is no clearly established standard.Under the default interpretation, given two memory references, where at least one is loop variant, the compiler will ignore any loop-carried dependences between the two references. Some examples:
do i = 1,n b(k) = b(k) + a(i) enddo |
Use of IVDEP will not break the dependence since b(k) is not loop variant.
do i=1,n a(i) = a(i-1) + 3. enddo |
Use of IVDEP does break the dependence but the compiler warns the user that it's breaking an obvious dependence.
do i=1,n a(b(i)) = a(b(i)) + 3. enddo |
Use of IVDEP does break the dependence.
do i = 1,n a(i) = b(i) c(i) = a(i) + 3. enddo |
Use of IVDEP does not break the dependence on a(i) since it is within an iteration.
The second interpretation of IVDEP is used if you use the -OPT:cray_ivdep=TRUE command line option. Under this interpretation, the compiler uses Cray semantics. It breaks all lexically backwards dependences. Some examples:
do i=1,n a(i) = a(i-1) + 3. enddo |
Use of IVDEP does break the dependence but the compiler warns the user that it's breaking an obvious dependence.
do i=1,n a(i) = a(i+1) + 3. enddo |
Use of IVDEP does not break the dependence since the dependence is from the load to the store, and the load comes lexically before the store.
The third interpretation of IVDEP is used if you use the -OPT:liberal_ivdep=TRUE command line option. Under this interpretation, the compiler will break all dependences.
| Note: IVDEP IS DANGEROUS! If your code really isn't free of vector dependences, you may be telling the compiler to perform an illegal transformation which will cause your program to get wrong answers. But, IVDEP is also powerful and you may very well find yourself in a position where you need to use it. You just have to be very careful when you do this. |
The MIPSpro 64-bit compilers support both single and double precision versions of the following vector instrinsic functions: asin(), acos(), atan(), cos(), exp(), log(), sin(), tan(), sqrt(). In C they are declared as follows:
/* single precision vector routines */ extern __vacosf( float *x, float *y, int count, int stridex, int stridey ); extern __vasinf( float *x, float *y, int count, int stridex, int stridey ); extern __vatanf( float *x, float *y, int count, int stridex, int stridey ); extern __vcosf( float *x, float *y, int count, int stridex, int stridey ); extern __vexpf( float *x, float *y, int count, int stridex, int stridey ); extern __vlogf( float *x, float *y, int count, int stridex, int stridey ); extern __vsinf( float *x, float *y, int count, int stridex, int stridey ); extern __vtanf( float *x, float *y, int count, int stridex, int stridey ); /* double precision vector routines */ extern __vacos( double *x, double *y, int count, int stridex, int stridey ); extern __vasin( double *x, double *y, int count, int stridex, int stridey ); extern __vatan( double *x, double *y, int count, int stridex, int stridey ); extern __vcos( double *x, double *y, int count, int stridex, int stridey ); extern __vexp( double *x, double *y, int count, int stridex, int stridey ); extern __vlog( double *x, double *y, int count, int stridex, int stridey ); extern __vsin( double *x, double *y, int count, int stridex, int stridey ); extern __vtan( double *x, double *y, int count, int stridex, int stridey ) |
The variables x and y are assumed to be pointers to non-overlapping arrays. Each routine is functionally equivalent to the following pseudo-code fragment:
do i = 1, count-1
y[i*stridey] = func(x[i*stridex])
enddo |
where func() is the scalar version of the vector intrinsic.
The vector intrinsics are optimized and software pipelined to take advantage of the R8000's performance features. Throughput is several times greater than that of repeatedly calling the corresponding scalar function though the result may not necessarily agree to the last bit. For further information about accuracy and restrictions of the vector intrinsics please refer to your IRIX Compiler_dev Release Notes.
All of the vector intrinsics can be called explicitly from your program. In Fortran the following example invokes the vector intrinsic vexpf().
real*4 x(N), y(N)
integer*8 N, i
i = 1
call vexpf$( %val(%loc(x(1))),
& %val(%loc(y(1))),
& %val(N),%val(i),%val(i))
end |
The compiler at optimization level -O3 also recognizes the use of scalar versions of these intrinsics on array elements inside loops and turns them into calls to the vector versions. If you need to turn this feature off to improve the accuracy of your results, add -LNO:vint=OFF to your compilation command line or switch to a lower optimization level.