The Auto-Parallelizing Option (APO) enables the MIPSpro 7 Fortran 90 compiler to optimize parallel codes and enhances performance on multiprocessor systems. APO is controlled with command line options and source directives.
 | Note: APO is licensed and sold separately from the MIPSpro 7 Fortran 90 compiler. APO features in your code are ignored unless you are licensed for this product. For sales and licensing information, contact your Silicon Graphics sales representative. |
APO is integrated into the compiler; it is not a source-to-source preprocessor. Although runtime performance suffers slightly on single-processor systems, parallelized programs can be created and debugged with APO enabled.
Parallelization is the process of analyzing sequential programs for parallelism and restructuring them to run efficiently on multiprocessor systems. The goal is to minimize the overall computation time by distributing the computational workload among the available processors. Parallelization can be automatic or manual.
During automatic parallelization, the compiler analyzes and restructures the program with little or no intervention by you. With APO, the compiler automatically generates code that splits the processing of loops among multiple processors. An alternative is manual parallelization, in which you perform the parallelization using compiler directives and other programming techniques.
As the following figure shows, APO integrates automatic parallelization with other compiler optimizations, such as interprocedural analysis (IPA), optimizations for single processors, and loop nest optimization (LNO):
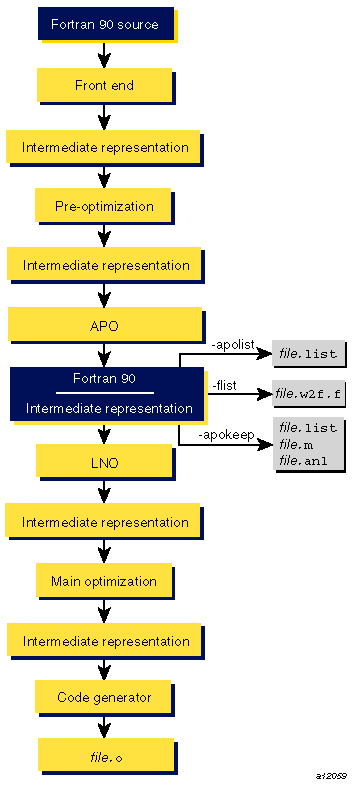
Several f90(1) command line options described in Chapter 2, “Invoking MIPSpro 7 Fortran 90”, control APO's effect on your program. The following command line, for example, invokes APO and requests aggressive optimization:
f90 -apo -O3 zebra.f |
The following subsections describe the effects that various f90(1) command line options have on APO.
| Note: If you invoke the loader separately, you must specify the -apo option on the ld(1) command line. |
The -apo option invokes APO. When this option is enabled, the compiler automatically converts sequential code into parallel code by inserting parallel directives where it it safe and beneficial to do so. Specifying -apo also enables the -mp option, which enables recognition of the parallel directives inserted into your code.
The -apokeep and -apolist options control output files. Both options generate file.list, which is a listing file that contains information on the loops that were executed in parallel and explains why others were not executed in parallel.
When -apokeep is specified, the compiler writes file.list, and in addition, it retains file.anl and file.m. The ProDev ProMP tools use file.anl. For more information on ProDev ProMP, see the ProDev ProMP User's Guide. file.m is an annotated version of your source code that shows the insertion of multiprocessing directives.
For more information on the content of file.list, file.anl, and file.m, see “The file.w2f.f File”.
| Note: Because of data conflicts, do not specify the -mplist or -FLIST options when -apokeep is specified. |
This option generates a Fortran listing and directs the compiler to write the transformed source code and multiprocessing directives to file.w2f.f. For more information on the content of file.w2f.f, see “Files”.
Interprocedural analysis (IPA) is invoked by the -IPA command line option. It performs program optimizations that can only be done by examining the whole program rather than processing each procedure separately.
When APO is invoked with IPA, only those loops with calls determined to be safe are parallelized.
If IPA expands subroutines inline in a calling routine, the subroutines are compiled with the options of the calling routine. If the calling routine is not compiled with -apo, none of its inlined subroutines are parallelized. This is true even if the subroutines are compiled separately with -apo because with IPA, automatic parallelization is deferred until link time.
If -apokeep or -pfakeep are specified in conjunction with -ipa or -IPA, the default settings for IPA suboptions are used with the exception of the inline=setting suboption. For that suboption, the default becomes OFF.
For more information on the effect of IPA, see “Loops Containing Function Calls”. For more information on IPA itself, see the ipa(5) man page.
The -LNO options control the Loop Nest Optimizer (LNO). LNO is enabled by default at -O3. LNO performs loop optimizations that better exploit caches and instruction-level parallelism. The following LNO options are of particular interest to APO users:
-LNO:auto_dist=on. This option requests that APO insert data distribution directives to provide the best memory utilization on Origin2000 systems.
-LNO:ignore_pragmas=setting. This option directs APO to ignore all of the directives and assertions described in “Compiler Directives”.
-LNO:parallel_overhead=num_cycles. This option allows you to override certain compiler assumptions regarding the efficiency to be gained by executing certain loops in parallel rather than serially. Specifically, changing this setting changes the default estimate of the cost to invoke a parallel loop in your runtime environment. This estimate varies depending on your particular runtime environment, but it is typically several thousand machine cycles.
To obtain maximum performace, specify -O3 when compiling with APO enabled. The optimizations at this level maximize code quality even if they require extensive compile time or relax the language rules. In addition, LNO is enabled by default at this -O level.
The -O3 option uses transformations that are usually beneficial but can sometimes hurt performance. This optimization may cause noticeable changes in floating-point results due to the relaxation of operation-ordering rules. Floating-point optimization is discussed further in “-OPT:...”.
For more information on the -O3 option, see “-Olevel” in Chapter 2.
The -OPT command line option controls general optimizations that are not associated with a distinct compiler phase.
The -OPT:roundoff=n option controls floating-point accuracy and the behavior of overflow and underflow exceptions relative to the source language rules.
When -O3 is in effect, the default rounding setting is -OPT:roundoff=2. This setting allows transformations with extensive effects on floating-point results. It allows associative rearrangement across loop iterations and the distribution of multiplication over addition and subtraction. It disallows only transformations known to cause overflow, underflow, or cumulative round-off errors for a wide range of floating-point operands.
At -OPT:roundoff=2 or 3, APO can change the sequence of a loop's floating-point operations in order to parallelize it. Because floating-point operations have finite precision, this change can cause slightly different results. If you want to avoid these differences by not having such loops parallelized, you must compile with -OPT:roundoff=0 or -OPT:roundoff=1.
Example. APO parallelizes the following loop when compiled with the default settings of -OPT:roundoff=2 and -O3:
REAL A, B(100)
DO I = 1, 100
A = A + B(I)
END DO |
At the start of the loop, each processor gets a private copy of A in which to hold a partial sum. At the end of the loop, the partial sum in each processor's copy is added to the total in the original, global copy. This value of A can be different from the value generated by a version of the loop that is not parallelized.
For more information on the -OPT option, see “-OPT:...” in Chapter 2.
The -pfa option invokes APO. The -pfalist option produces a listing.
| Note: These options are outmoded. The preferred way of invoking APO is through the -apo option, and the preferred way to obtain a listing is through the -apolist option. |
Your input file.
For information on files used and generated when APO is enabled, see “Files”. For information on Fortran input files, see “file.suffix90file.suffix90...” in Chapter 2.
APO provides a number of options to generate listings that describe where parallelization failed and where it succeeded. You can use these listings to identify constructs that inhibit parallelization. When you remove these constructs, you can often improve program performance dramatically.
When looking for loops to run in parallel, focus on the areas of the code that use most of the execution time. To determine where the program spends its execution time, you can use tools such as SpeedShop and the ProDev ProMP Parallel Analyzer View described in the ProDev ProMP User's Guide.
The following sections describe the content of the files generated by APO.
The -apolist and -apokeep options generate files that list the original loops in the program along with messages indicating if the loops were parallelized. For loops that were not parallelized, an explanation is provided.
Example. The following subroutine resides in file testl.f:
SUBROUTINE SUB(ARR, N) REAL(KIND=8), DIMENSION(N) :: ARR INTEGER :: N, I ARR(2:N) = ARR(1:N-1) + ARR(2:N) DO I = 1, N ARR(I) = ARR(I) + 7.0 CALL FOO(A) END DO ARR = ARR + 7.0 END |
The preceding code produces the following APO list file:
Parallelization Log for Subprogram sub_
5: Not Parallel
Array dependence from ARR on line 5 to ARR on line 5.
7: Not Parallel
Call foo_ on line 9.
12: PARALLEL (Auto) __mpdo_sub_1 |
The -flist option generates file.w2f.f. File file.w2f.f contains code that mimics the behavior of programs after they undergo automatic parallelization. The representation is designed to be readable so that you can see what portions of the original code were not parallelized. You can use this information to change the original program.
The compiler creates file.w2f.f by invoking the appropriate translator to turn the compiler's internal representations into FORTRAN 77 (not Fortran 95). In most cases, the files contain valid code that can be recompiled, although compiling file.w2f.f without APO enabled does not produce object code that is exactly the same as that generated when APO is enabled on the original source.
By default, the parallelized program in file.w2f.f uses OpenMP directives. To generate a parallelized program that uses the outmoded MIPS multiprocessing directives, described in Appendix D, “Multiprocessing Directives (Outmoded)”, specify -FLIST:emit_omp=OFF.
Example. File testw2.f is compiled with the following command:
f90 -O3 -n32 -mips4 -c -apo -apokeep testw2.f |
SUBROUTINE INIT(A) REAL(KIND=4), DIMENSION(10000) :: A A = 0.0 END |
Compiling testw2.f generates an object file, testw2.o, and listing file testw2.w2f.f, which contains the following code:
C **********************************
C Fortran file translated from WHIRL
C **********************************
CSGI$ start 1
SUBROUTINE init(A)
IMPLICIT NONE
REAL(4) A(10000_8)
C
C **** Temporary variables ****
C
INTEGER(4) f90li_0_1
C
C **** statements ****
C
C PARALLEL DO will be converted to SUBROUTINE __mpdo_init_1
CSGI$ start 2
C$OMP PARALLEL DO private(f90li_0_1), shared(A)
DO f90li_0_1 = 0, 9999, 1
A(f90li_0_1 + 1) = 0.0
END DO
CSGI$ end 2
RETURN
END
CSGI$ end 1 |
| Note: WHIRL is the name for the compiler's intermediate representation. It is written in the style of the FORTRAN 77 standard, not the Fortran 95 standard. |
As explained in “The file.list File”, parallel versions of loops are put in their own subroutines. In this example, that subroutine is __mpdo_init_1. C$OMP PARALLEL DO is an OpenMP directive that specifies a parallel region containing a single DO directive.
The -apokeep option generates file.list. It also generates file.m and file.anl, which are used by Workshop Pro MP.
file.m is similar to the file.w2f.f file; it is based on OpenMP and mimics the behavior of the program after automatic parallelization.
ProDev ProMP is a Silicon Graphics product that provides a graphical interface to aid in both automatic and manual parallelization for Fortran. The ProDev ProMP Parallel Analyzer View helps you understand the structure and parallelization of multiprocessing applications by providing an interactive, visual comparison of their original source with transformed, parallelized code. For more information, see the ProDev ProMP User's Guide and the Developer Magic: Performance Analyzer User's Guide.
SpeedShop, another Silicon Graphics product, allows you to run experiments and generate reports to track down the sources of performance problems. SpeedShop includes a set of commands and a number of libraries to support the commands. For more information, see the SpeedShop User's Guide.
| Note: The code in file.m is written in the style of the FORTRAN 77 standard, not the Fortran 95 standard. |
You invoke a parallelized version of your program using the same command line as a sequential one. The same binary output file can be executed on various numbers of processors. The default is to have the run-time environment select the number of processors to use based on how many are available.
You can change the default behavior by setting the OMP_NUM_THREADS environment variable, which tells the system to use a particular number of processors. The following statement causes the program to create two threads regardless of the number of processors available:
setenv OMP_NUM_THREADS 2 |
The OMP_DYNAMIC environment variable allows you to control whether the run-time environment should dynamically adjust the number of threads available for executing parallel regions to optimize use of system resources. The default value is TRUE. If OMP_DYNAMIC is set to FALSE, dynamic adjustment is disabled.
For more information on these and other environment variables, see the pe_environ(5) man page.
Some loops cannot be safely parallelized and others are written in ways that inhibit APO's efficiency. The following subsections describe the steps you can take to make APO more effective:
“Constructs That Inhibit Parallelization”, describes constructs that inhibit parallelization.
“Constructs That Slow Down Parallelized Code”, describes constructs that inhibit APO's effectiveness.
A program's performance can be severely constrained if APO cannot recognize that a loop is safe to parallelize. APO analyzes every loop in a program. If a loop does not appear safe, it does not parallelize that loop. The following sections describe constructs that can inhibit parallelization:
“Loops Containing Data Dependencies”, describes basic data dependencies.
“Loops Containing Function Calls”, describes function calls.
“Loops Containing GO TO Statements”, describes GO TO statements.
“Loops Containing Problematic Array Constructs”, describes problematic array subscripts.
“Loops Containing Local Variables”, describes conditionally assigned local variables.
In many instances, loops containing the previous constructs can be parallelized after minor changes. Reviewing the information generated in program file.list, described in “The file.list File”, can show you if any of these constructs are in your code.
Generally, a loop is safe if there are no data dependencies, such as a variable being assigned in one iteration of a loop and used in another. APO does not parallelize loops for which it detects data dependencies.
For example, APO cannot parallelize loop I in the following subroutine because it contains a data dependence on variable X:
SUBROUTINE SUB(N, A, B) INTEGER :: I, N REAL :: X, A(N), B(N) X = 0.0 DO I = 1, N A(I) = X IF (I .GT. N / 2) X = 1.0 END DO END |
Many times, such dependences can be removed by making simple modifications to the source code. In this case, we can assign to X in each iteration before we read X, as follows:
SUBROUTINE SUB(N, A, B)
INTEGER :: I, N
REAL :: X, A(N), B(N)
DO I = 1, N
IF (I .LE. N / 2) THEN
X = 0.0
ELSE
X = 1.0
END IF
A(I) = X
END DO
END |
APO now can parallelize loop I.
By default, APO does not parallelize a loop that contains a function call because the function in one iteration of the loop can modify or depend on data in other iterations.
You can, however, use interprocedural analysis (IPA) to provide APO with enough information to parallelize some loops containing subroutine calls by inlining those calls. IPA is specified by the -IPA command line option. For more information on IPA, see the ipa(5) man page and the MIPSpro Compiling and Performance Tuning Guide.
You can also direct APO to ignore function call dependencies when analyzing the specified loops by using the !*$* ASSERT CONCURRENT CALL directive described in “!*$* ASSERT CONCURRENT CALL”.
GO TO statements are unstructured control flows. APO converts most unstructured control flows in loops into structured flows that can be parallelized. However, GO TO statements in loops can still cause the following problems:
Unstructured control flows. APO is unable to restructure all types of flow control in loops. You must either restructure these control flows or manually parallelize the loops containing them.
Early exits from loops. Loops with early exits cannot be parallelized, either automatically or manually.
For improved performance, remove GO TO statements from loops to be considered candidates for parallelization.
The following array constructs inhibit parallelization and should be removed whenever APO is used:
Arrays with subscripts that are indirect array references. APO cannot analyze indirect array references. The following loop cannot be run safely in parallel if the indirect reference IB(I) is equal to the same value for different iterations of I:
DO I = 1, N A(IB(I)) = ... END DOIf every element of array IB is unique, the loop can safely be made parallel. To achieve automatic parallelism in such cases, use the !*$* ASSERT PERMUTATION directive, discussed in “!*$* ASSERT PERMUTATION (array_name)”.
Arrays with unanalyzable subscripts. APO cannot parallelize loops containing arrays with unanalyzable subscripts. Allowable subscripts can contain the following elements:
Literal constants (1, 2, 3, ...)
Variables (I, J, K, ...)
The product of a literal constant and a variable, such as N*5 or K*32
A sum or difference of any combination of the first three items, such as N*21+K-251
In the following case, APO cannot analyze the division operator (/) in the array subscript and cannot reorder the loop:
DO I = 2, N, 2 A(I/2) = ... END DOUnknown information. In the following example there may be hidden knowledge about the relationship between variables M and N:
DO I = 1, N A(I) = A(I+M) END DOThe loop can be run in parallel if M > N because the array reference does not overlap. However, APO does not know the value of the variables and therefore cannot make the loop parallel. You can use the !*$* ASSERT DO (CONCURRENT) directive to have APO automatically parallelize this loop. For more information on this directive, see “!*$* ASSERT DO (CONCURRENT)”.
When parallelizing a loop, APO often localizes (privatizes) temporary scalar and array variables by giving each processor its own nonshared copy of them. In the following example, array TMP is used for local scratch space:
DO I = 1, N
DO J = 1, N
TMP(J) = ...
END DO
DO J = 1, N
A(J,I) = A(J,I) + TMP(J)
END DO
END DO |
To successfully parallelize the outer loop (I), APO must give each processor a distinct, private copy of array TMP. In this example, it is able to localize TMP and, thereby, to parallelize the loop.
APO cannot parallalize a loop when a conditionally assigned temporary variable might be used outside of the loop, as in the following example:
SUBROUTINE S1(A, B)
COMMON T
...
DO I = 1, N
IF (B(I)) THEN
T = ...
A(I) = A(I) + T
END IF
END DO
CALL S2()
END |
If the loop were to be run in parallel, a problem would arise if the value of T were used inside subroutine S2() because it is not known which processor's private copy of T should be used by S2(). If T were not conditionally assigned, the processor that executed iteration N would be used. Because T is conditionally assigned, APO cannot determine which copy to use.
The solution comes with the realization that the loop is inherently parallel if the conditionally assigned variable T is localized. If the value of T is not used outside the loop, replace T with a local variable. Unless T is a local variable, APO assumes that S2() might use it.
APO parallelizes a loop by distributing its iterations among the available processors. Loop nesting, loops with low trip counts, and other program characteristics can affect the efficiency of APO. The following sections describe the effect that these and other programming constructs can have on APO's ability to parallelize:
“Parallelizing Nested Loops”, describes parallelizing nested loops.
“Parallelizing Loops with Small or Indeterminate Trip Counts”, describes parallelizing loops with small or indeterminate trip counts.
“Parallelizing Loops with Poor Data Locality”, describes parallelizing loops that exhibit poor data locality.
APO can parallelize only one loop in a loop nest. In these cases, the most effective optimization usually occurs when the outermost loop is parallelized. The effectiveness derives from that fact that more processors end up processing larger sections of the program. This saves synchronization and other overhead costs.
Example 1. Consider the following simple loop nest:
DO I = 1, L
...
DO J = 1, M
...
DO K = 1, N
... |
When parallelizing nested loops I, J, and K, APO distributes only one of the loops. Effective loop nest parallelization depends on the loop that APO chooses, but it is possible for APO to choose an inferior loop to be parallelized. APO may attempt to interchange loops to make a more promising one the outermost. If the outermost loop attempt fails, APO attempts to parallelize an inner loop. Because of the potential for improved performance, it is useful for you to modify your code so that the outermost loop is the one parallelized.
“The file.list File”, describes file.list. This output file contains information that tells you which loop in a nest was parallelized.
For every loop that could be parallelized, APO generates a test to determine whether the loop is being called from within either another parallel loop or from within a parallel region. In some cases, you can minimize the extra testing that APO must perform by inserting directives into your code to inhibit parallization testing. The following example demonstrates this:
Example 2:
SUBROUTINE CALLER
DO I = 1, N
CALL SUB
END DO
...
END
SUBROUTINE SUB
...
DO I = 1, N
...
END DO
END |
If the loop inside CALLER() is parallelized, the loop inside SUB() cannot be run in parallel when CALLER() calls SUB(). In this case, the test can be avoided.
If SUB() is always called from CALLER(), you can use the !*$* ASSERT DO (SERIAL) directive to force the sequential execution of the loop in SUB(). With the addition of the directive, the subroutine would be written as follows:
SUBROUTINE CALLER
DO I = 1, N
CALL SUB
END DO
...
END
SUBROUTINE SUB
...
!*$* ASSERT DO (SERIAL)
DO I = 1, N
...
END DO
END |
For more information on this compiler directive, see “!*$* ASSERT DO (SERIAL)”.
The trip count is the number of times a loop is executed. Loops with large trip counts are the best candidates for parallelization. The following paragraphs show how to modify your program if your program contains loops with small trip counts or loops with indeterminate trip counts:
Loops with small trip counts generally run faster when they are not parallelized. Consider the following loop nest:
DO I = 1, M DO J = 1, NAPO may try to parallelize loop I because it is outermost. If M is very small, it would be better to interchange the loops and make loop J outermost before parallelization. Because APO often cannot know that M is small, you can use a !*$* ASSERT DO PREFER (CONCURRENT) directive to indicate to APO that it is better to parallelize loop J, as follows:
DO I = 1, M !*$* ASSERT DO PREFER (CONCURRENT) DO J = 1, NIf the trip count is not known (and sometimes even if it is), APO parallelizes the loop conditionally, generating code for both a parallel and a sequential version. By generating two versions, APO can avoid running a loop in parallel that may have small trip count. APO chooses the version to use based on the trip count, the code inside the loop's body, the number of processors available, and an estimate of the cost to invoke a parallel loop in that runtime environment.
You can avoid the overhead incurred by having APO generate both sequential and parallel versions of a loop by using the !*$* ASSERT DO PREFER (SERIAL) directive.
Computer memory has a hierarchical organization. Higher up the hierarchy, memory becomes closer to the CPU, faster, more expensive, and more limited in size. Cache memory is at the top of the hierarchy, and main memory is further down in the hierarchy. In multiprocessor systems, each processor has its own cache memory. Because it is time consuming for one processor to access another processor's cache, a program's performance is best when each processor has the data it needs in its own cache.
Programs, especially those that include extensive looping, often exhibit locality of reference, which means that if a memory location is referenced, it is probable that it or a nearby location will be referenced in the near future. Loops designed to take advantage of locality do a better job of concentrating data in memory, increasing the probability that a processor will find the data it needs in its own cache.
The following examples show the effect of locality on parallelization. Assume that the loops are to be parallelized and that there are p processors.
Example 1. Distribution of Iterations.
DO I = 1, N
...A(I)
END DO
DO I = N, 1, -1
...A(I)...
END DO |
In the first loop, the first processor accesses the first N/p elements of A; the second processor accesses the next N/p elements; and so on. In the second loop, the distribution of iterations is reversed. That is, the first processor accesses the last N/p elements of A, and so on. Most elements are not in the cache of the processor needing them during the second loop. This code fragment would run more efficiently, and be a better candidate for parallelization, if you reverse the direction of one of the loops.
Example 2. Two Nests in Sequence.
DO I = 1, N
DO J = 1, N
A(I,J) = B(J,I) + ...
END DO
END DO
DO I = 1, N
DO J = 1, N
B(I,J) = A(J,I) + ...
END DO
END DO |
In example 2, APO may parallelize the outer loop of each member of a sequence of nests. If so, while processing the first nest, the first processor accesses the first N/p rows of A and the first N/p columns of B. In the second nest, the first processor accesses the first N/p columns of A and the first N/p rows of B. This example runs much more efficiently if you parallelize the I loop in one nest and the J loop in the other. You can instruct APO to do this with the !*$* ASSERT DO PREFER (CONCURRENT) directive, as follows:
DO I = 1, N
!*$* ASSERT DO PREFER (CONCURRENT)
DO J = 1, N
A(I,J) = B(J,I) + ...
END DO
END DO
!*$* ASSERT DO PREFER (CONCURRENT)
DO I = 1, N
DO J = 1, N
B(I,J) = A(J,I) + ...
END DO
END DO |
APO works in conjunction with the OpenMP Fortran API directives described in Chapter 4, “OpenMP Fortran API Multiprocessing Directives”, and with the Origin series directives described in Chapter 5, “Parallel Processing on Origin Series Systems”. You can use these directives to manually parallelize some loop nests, while leaving others to APO. This approach has the following positive and negative aspects:
As a positive aspect, the OpenMP and Origin series directives are well defined and deterministic. If you use a directive, the specified loop is run in parallel. This assumes that the trip count is greater than one and that the specified loop is not nested in another parallel loop.
The negative side to this is that you must carefully analyze the code to determine that parallelism is safe. Also, you must mark all private variables.
In addition to the OpenMP and Origin series directives, you can also use the APO-specific directives described in this section. These directives give APO more information about your code.
| Note: APO also recognizes the Silicon Graphics multiprocessing directives described in Appendix D, “Multiprocessing Directives (Outmoded)”. These directives are outmoded. The OpenMP directive set is the preferred directive set for multiprocessing. You must include the -mp option on the f90(1) command line in order for the compiler to recognize the Silicon Graphics multiprocessing directives. |
The APO directives can affect certain optimizations, such as loop interchange, during the compiling process. To direct the compiler to disregard any of the preceding directives, use the -xdirlist option described in “-xdirlist” in Chapter 2.
The APO directives are as follows:
!*$* ASSERT CONCURRENT CALL. This directive directs APO to ignore dependencies in subroutine calls that would inhibit parallelization. For more information on this directive, see “!*$* ASSERT CONCURRENT CALL”.
!*$* ASSERT DO (CONCURRENT). This directive asserts that APO should not let perceived dependencies between two references to the same array inhibit parallelizing. For more information on this directive, see “!*$* ASSERT DO (CONCURRENT)”.
!*$* ASSERT DO (SERIAL). This directive requests that the following loop be executed in serial mode. For more information on this directive, see “!*$* ASSERT DO (SERIAL)”.
!*$* ASSERT DO PREFER (CONCURRENT). This directive parallelizes the following loop if it is safe. For more information on this directive, see “!*$* ASSERT DO PREFER (CONCURRENT)”.
!*$* ASSERT PERMUTATION (array_name). This directive asserts that array array_name is a permutation array. For more information on this directive, see “!*$* ASSERT PERMUTATION (array_name)”.
!*$* NO CONCURRENTIZE and !*$* CONCURRENTIZE. The !*$* NO CONCURRENTIZE directive inhibits either parallelization of all loops in a subroutine or parallelization of all loops in a file. The !*$* CONCURRENTIZE directive overrides the !*$* NO CONCURRENTIZE directive, and its effect varies with its placement. For more information on these directives, see “!*$* NO CONCURRENTIZE and !*$* CONCURRENTIZE”.
| Note: The compiler honors the following APO directives even if the -apo option is not included on your command line:
|
The !*$* ASSERT CONCURRENT CALL directive instructs APO to ignore the dependencies of subroutine and function calls contained in the loop that follows the assertion. The directive applies to the loop that immediately follows it and to all loops nested inside that loop.
| Note: The directive affects the compilation even when -apo is not specified. |
APO ignores the dependencies in subroutine FRED() when it analyzes the following loop:
!*$* ASSERT CONCURRENT CALL
DO I = 1, N
CALL FRED
...
END DO
SUBROUTINE FRED
...
END |
To prevent incorrect parallelization, make sure the following conditions are met when using !*$* ASSERT CONCURRENT CALL:
A subroutine inside the loop cannot read from a location that is written to during another iteration. This rule does not apply to a location that is a local variable declared inside the subroutine.
A subroutine inside the loop cannot write to a location that is read from or written to during another iteration. This rule does not apply to a location that is a local variable declared inside the subroutine.
Example. The following code shows an illegal use of the directive. Subroutine FRED() writes to variable T, which is also read from by WILMA() during other iterations:
!*$* ASSERT CONCURRENT CALL
DO I = 1,M
CALL FRED(B, I, T)
CALL WILMA(A, I, T)
END DO
SUBROUTINE FRED(B, I, T)
REAL B(*)
T = B(I)
END
SUBROUTINE WILMA(A, I, T)
REAL A(*)
A(I) = T
END |
By localizing the variable T, you can manually parallelize the preceding example safely. However, APO does not know to localize T, so it illegally parallelizes the loop because of the directive.
The !*$* ASSERT DO (CONCURRENT) directive instructs APO, when analyzing the loop immediately following this directive, to ignore all dependencies between two references to the same array. If there are real dependencies between array references, the !*$* ASSERT DO (CONCURRENT) directive can cause APO to generate incorrect code.
| Note: This directive affects the compilation even when -apo is not specified. |
The following example shows correct use of this directive when M > N:
!*$* ASSERT DO (CONCURRENT)
DO I = 1, N
A(I) = A(I+M) |
Be aware of the following points when using this directive:
If multiple loops in a nest can be parallelized, !*$* ASSERT DO (CONCURRENT) causes APO to parallelize the loop immediately following the assertion.
Applying this directive to an inner loop can cause the loop to be made outermost by APO's loop interchange operations.
This directive does not affect how APO analyzes CALL statements. For more information on APO's interaction with CALL statements, see “!*$* ASSERT CONCURRENT CALL”.
This directive does not affect how APO analyzes dependencies between two potentially aliased pointers.
The compiler may find some obvious real dependencies. If it does so, it ignores this directive.
The !*$* ASSERT DO (SERIAL) directive instructs APO not to parallelize the loop following the assertion; the loop is executed in serial mode. APO can, however, parallelize another loop in the same nest. The parallelized loop can be either inside or outside the designated sequential loop.
| Note: This directive has the same effect as the !*$* ASSERT DO PREFER (SERIAL) directive. In order for the !*$* ASSERT DO PREFER (SERIAL) directive to be honored, however, the -apo option must appear on the f90(1) command line. The !*$* ASSERT DO PREFER (SERIAL) directive is outmoded.
The !*$* ASSERT DO (SERIAL) directive affects the compilation even when the -apo option is not specified. |
Example. The following code fragment contains a directive that requests that loop J be run serially:
DO I = 1, M
!*$* ASSERT DO (SERIAL)
DO J = 1, N
A(I,J) = B(I,J)
END DO
...
END DO |
The directive applies only to the loop that immediately follows it. For example, APO still tries to parallelize loop I. This directive is useful in cases like this when the value of N is known to be very small.
The !*$* ASSERT DO PREFER (CONCURRENT) directive instructs APO to parallelize the loop immediately following the directive if it is safe to do so.
Example. The following code fragment encourages APO to run loop I loop in parallel:
!*$* ASSERT DO PREFER (CONCURRENT)
DO I = 1, M
DO J = 1, N
A(I,J) = B(I,J)
END DO
...
END DO |
When dealing with nested loops, APO follows these guidelines:
If the loop specified by the !*$* ASSERT DO PREFER (CONCURRENT) directive is safe to parallelize, APO parallelizes the specified loop even if other loops in the nest are safe.
If the specified loop is not safe to parallelize, APO parallelizes a different loop that is safe.
If this directive is applied to an inner loop, APO can interchange the loop and make the specified loop the outermost loop.
If this directive is applied to more than one loop in a nest, APO parallelizes one of the specified loops.
When placed inside a subroutine, the !*$* ASSERT PERMUTATION (array_name) directive informs APO that array_name is a permutation array. A permutation array is one in which every element of the array has a distinct value.
This directive does not require the permutation array to be dense. That is, within the array, every IB(I) must have a distinct value, but there can be gaps between the values, such as IB(1) = 1, IB(2) = 4, IB(3) = 9, and so on.
| Note: This directive affects compilation even when -apo is not specified. |
Example. In the following code fragment, array IB is declared to be a permutation array for both loops in SUB1():
SUBROUTINE SUB1
DO I = 1, N
A(IB(I)) = ...
END DO
!*$* ASSERT PERMUTATION (IB)
DO I = 1, N
A(IB(I)) = ...
END DO
END |
Note the following points about this directive:
As shown in the example, you can use this directive to parallelize loops that use arrays for indirect addressing. Without this directive, APO cannot determine that the array elements used as indexes are distinct.
!*$* ASSERT PERMUTATION (array_name) affects every loop in a subroutine, even those that appear ahead of it.
The !*$* NO CONCURRENTIZE and !*$* CONCURRENTIZE directives toggle parallelization. Their effects depend on their placement.
When placed inside subroutines and functions, !*$* NO CONCURRENTIZE inhibits parallelization. In the following example, no loops inside SUB1() are parallelized:
SUBROUTINE SUB1 !*$* NO CONCURRENTIZE ... ENDWhen placed outside of a subroutine, !*$* NO CONCURRENTIZE prevents the parallelization of all procedures in the file, even those that appear ahead of it in the file. Loops inside subroutines SUB2() and SUB3() are not parallelized in the following example:
SUBROUTINE SUB2 ... END !*$* NO CONCURRENTIZE SUBROUTINE SUB3 ... END
The !*$* CONCURRENTIZE directive, when placed inside a subroutine, overrides a !*$* NO CONCURRENTIZE directive that is placed outside of it. Thus, this directive allows you to selectively parallelize subroutines in a file that has been made sequential with a !*$* NO CONCURRENTIZE directive.