This chapter provides information for maximizing the performance of the SGI MPI library. This information includes automatic or default optimizations, optimizations that the user can perform through the use of environment variables, optimizations for using MPI on IRIX clusters, and some general tips and tools for optimization.
The optimizations described in this section are performed by the MPI library automatically without changes from the user. For these optimizations to be effective, you must use the suggested MPI functions.
The MPI library has been optimized to achieve low latency and high bandwidth for programs that use MPI_Send/MPI_Recv or MPI_Isend/MPI_Irecv point-to-point message passing. MPI_Rsend is treated the same as MPI_Send in this implementation. In addition, these point-to-point calls have been optimized for a high repeat rate. This allows applications that exchange data with the other processors to handle the requests at the same time without unnecessary waiting.
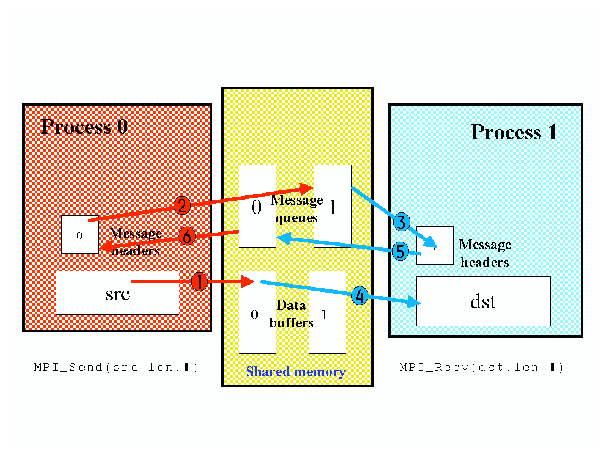
The diagram in Figure 6-1 shows what happens within the library when a message is sent from one process to another. In this example, a medium sized message (between 64 and 16384 bytes) is passed from one process to another on the same IRIX or Linux host. The numbers on the arrows indicate the order in which the following steps occur.
Procedure 6-1. Message passing process
The sender aquires a shared memory buffer and copies the src data into that buffer.
The sender performs a fetch and add operation of the fetchop variable that controls the receiver's message queue. The value obtained from this operation indicates the slot in which a message header can be placed in the receiver's queue. The message header contains MPI related data, such as tag, communicator, location of data, and so on. The sender then copies the message header into the receiver's queue.
The receiver, which is polling on its message queue, finds the message header and copies the message header out of the message queue.
The receiver copies the data from the shared memory buffer into the dst buffer specified by the application.
The receiver performs a fetch and add operation of the fetchop variable that controls the sender's message queue. The receiver then copies a message header to the sender's message queue, which acknowledges (ACK) that the message has been received.
The sender receives the ACK and marks the shared memory buffer and other internal data structures for reuse.
Short messages (64 bytes or less) are further optimized but do not need to use the shared memory buffers because the data actually fits in the message header itself.
The MPI_Send/MPI_Recv are blocking calls and are not required to be buffered. This is important for single copy optimization, described in “Single Copy Optimization”.
The MPI collective calls are frequently layered on top of the point-to-point primitive calls. For small process counts, this can be reasonably effective. However, for higher process counts (32 processes or more) or for clusters, this approach can become less efficient. For this reason, the MPI library has optimized a number of the collective operations to make use of shared memory.
The MPI_Alltoall collective has been optimized to make use of symmetric data and the global heap. When the NAS FT parallel benchmark comparing two different versions of the SGI MPI library was run, the optimized MPI_Alltoall operation was almost an order of magnitude faster on high process counts than the nonoptimized buffered point-to-point MPI_Alltoall.
The MPI_Barrier call makes use of the fetchop barrier method for MPI_COMM_WORLD and similar communicators. Because it is the primary mechanism for synchronization, the barrier collective operation is critical for MPI-2 one-sided applications and SHMEM programs. The MPI library uses a tree or dissemination barrier mechanism for programs with 64 or more MPI processes. This implementation uses multiple fetch operations to minimize contention for HUB caches as well as to confine uncached loads to individual nodes to reduce traffic on the NUMA links.
Both the MPI_Alltoall collective and the MPI_Barriercall are also optimized for clusters. In addition, the MPI_Bcast and MPI_Allreduce collectives are optimized for clusters.
The MPI library takes advantage of NUMA placement functions that are available from IRIX. When running on IRIX 6.5.11 and later releases, the default topology (MPI_DSM_TOPOLOGY) is cpucluster. This allows IRIX to place the memories for that processor on any group of memory nodes of the hardware. IRIX attempts to place the group numbers close to one another, taking into account nodes with disabled processors.
If the user is running within a cpuset, only those CPUs and memory nodes specified within that cpuset are used.
In addition, MPI does NUMA placement optimization of key internal data structures to ensure it has good locality with respect to each CPU and does not create any unnecessary bottlenecks on specific memory nodes.
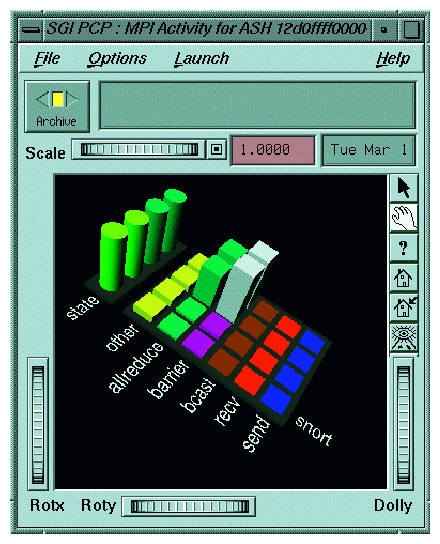
The oview command from Performance-CoPilot was used to generate Figure 6-2, which shows the placement of a 32 processor MPI job run on an 512 PE Origin 3000. Notice that the jobs (white bars) were placed on eight memory nodes near one another.

You can tune the MPI library for performance by using environment variables described in the MPI man page. This section describes some of the common runtime optimizations.
The MPI statistic counters (-stats option or MPI_STATS environment variable) can be used to tune the runtime environment of an MPI application. These counters are always accumulating statistics, so turning them on simply displays them.
One of these statistics is the number of retries. A retry indicates that the library spent time waiting for shared memory buffers to be made available before sending a message. The number of buffers can be increased to eliminate retries by adjusting the corresponding MPI environment variable. The most common ones that may need to be increased are MPI_BUFS_PER_PROC and MPI_BUFS_PER_HOST.
The following partial -stats output shows that 5672 retries were attempted for PER PROC data buffers for rank 3. In this case, the user should increase the MPI_BUFS_PER_PROC environment variable.
mpirun -stats -prefix "%g:" -np 8 a.out ... 3: *** Dumping MPI internal resource statistics... 3: 3: 0 retries allocating mpi PER_PROC headers for collective calls 3: 0 retries allocating mpi PER_HOST headers for collective calls 3: 0 retries allocating mpi PER_PROC headers for point-to-point calls 3: 0 retries allocating mpi PER_HOST headers for point-to-point calls 3: 0 retries allocating mpi PER_PROC buffers for collective calls 3: 0 retries allocating mpi PER_HOST buffers for collective calls 3: 5672 retries allocating mpi PER_PROC buffers for point-to-point calls 3: 0 retries allocating mpi PER_HOST buffers for point-to-point calls 3: 0 send requests using shared memory for collective calls 3: 6357 send requests using shared memory for point-to-point calls 3: 0 data buffers sent via shared memory for collective calls 3: 2304 data buffers sent via shared memory for point-to-point calls 3: 0 bytes sent using single copy for collective calls 3: 0 bytes sent using single copy for point-to-point calls 3: 0 message headers sent via shared memory for collective calls 3: 6357 message headers sent via shared memory for point-to-point calls 3: 0 bytes sent via shared memory for collective calls 3: 15756000 bytes sent via shared memory for point-to-point calls ... |
One of the most significant optimizations for bandwidth sensitive applications that has been made in the MPI library has been single copy optimization. This section describes three types of single copy optimization. Each one of these utilize the fact that the library is not required to buffer the data. For this reason some nonstandard MPI codes that require buffering for their MPI_Send/MPI_Recv calls may experience program hangs. This is why this optimization is not enabled by default.
The MPI data type on the send side must also be a contiguous type.
Since single copy optimization does not use the shared memory data buffers, enabling it eliminates the problem described in “Eliminating Retries” concerning retries caused by too few per process data buffers (MPI_BUFS_PER_PROC).
For jobs that are run across a cluster, the messages sent between processes within a host use single copy optimization, if enabled.
Single copy transfers for point-to-point as well as collective operations are listed in the -stats output. Checking those statistics when attempting to use this optimization can be very helpful to determine if single copy was used.
The traditional approach requires that users make sure the senders data resided in globally accessible memory and that they set the MPI_BUFFER_MAX environment variable. This optimization uses special cross-mapping of memory from the SHMEM library and thus is available only for ABI 64.
Globally accessible memory includes common block or static memory and memory allocated with the Fortran 90 allocate statement (with the SMA_GLOBAL_ALLOC environment variable set). In addition, applications linked against the SHMEM library may also access the LIBSMA symmetric heap via the shpalloc or shmalloc functions.
Setting the MPI_BUFFER_MAX variable to any value will enable this optimization. However, you should use a value near 2000 because this optimization for messages of smaller size will often not yield better performance and sometimes may decrease performance slightly.
For a simple bandwidth test involving two MPI processors and large message lengths, the traditional single copy showed about 60% improvement in MB/sec.
One MPI library feature takes advantage of a special IRIX device driver known as XPMEM (cross partition) that allows the operating system to make a very fast copy between two processes within the same host or across partitions. This feature requires IRIX 6.5.15 or greater. The XPMEM driver has been used by the MPI library to enhance single copy optimization (within a host) to eliminate some of the restrictions with only a slight (less that 5 percent) performance cost over the more restrictive traditional single copy optimization. You can enable this optimization if you set the MPI_XPMEM_ON and the MPI_BUFFER_MAX environment variables. The library tries to use the traditional single copy before trying to use this form of single copy. Using the XPMEM form of single copy is less restrictive in that the sender's data is not required to be globally accessible and it is available for ABI N32 as well as ABI 64. Also, this optimization can be used to transfer data between two different executable files on the same host or two different executable files across IRIX partitions.
In certain conditions, the XPMEM driver can take advantage of the block transfer engine (BTE) to provide increased bandwidth. In addition to having MPI_BUFFER_MAX and MPI_XPMEM_ON set, the send and receive buffers must be cache-aligned and the amount of data to transfer must be greater than or equal to MPI_XPMEM_THRESHOLD. The default value for MPI_XPMEM_THRESHOLD is 8192.
For the same bandwidth test mentioned in “ Traditional Single Copy Optimization and Restrictions ”, using the BTE showed more than a two-fold improvement in MB/sec over the traditional single copy.
Occasionally, it is useful to control NUMA placement. The dplace command can be very effective but sometimes difficult to use. Using cpusets can be effective in controlling NUMA placement, but to set up cpusets, you need to have root access.
The MPI library has introduced several environment variables to allow dplace and cpuset functionality when running on a quiet system. You can assign your MPI ranks to specific CPUs by using the MPI_DSM_CPULIST environment variable. You can use the MPI_DSM_VERBOSE environment variable to determine what CPUs and memory nodes were used, and which sysAD bus was used.
If you have a memory bound code that uses the memory of nodes in which the CPUs are idle, it might make sense to assign fewer CPUs per node to the application. You can do this by using the MPI_DSM_PPM environment variable. Note that the MPI_DSM_MUSTRUN environment variable must be set to ensure the MPI processes are pinned to the processors specified in the MPI_DSM_CPULIST.
If you are experiencing frequent TLB misses, you can increase the PAGESIZE_DATA environment variable. It is best to increase it slowly because setting it too high could cause even worse performance. Using the perfex or ssrun tools can help determine if TLB misses are excessive.
When you are running an MPI application across a cluster of IRIX hosts, there are additional runtime environment settings and configurations that you can consider when trying to improve application performance.
IRIX hosts can be clustered using a variety of high performance interconnects. Origin 300 and Origin 3000 series servers can be clustered as partitioned systems using the XPMEM interconnect. Other high performance interconnects include GSN and Myrinet. The older HIPPI 800 interconnect technology is also supported by the SGI MPI implementation. If none of these interconnects is available, MPI relies on TCP/IP to handle MPI traffic between hosts.
When launched as a distributed application, MPI probes for these interconnects at job startup. Launching a distributed application is described in Chapter 3, “Using mpirun to Execute Applications”. When a high performance interconnect is detected, MPI attempts to use this interconnect if it is available on every host being used by the MPI job. If the interconnect is not available for use on every host, the library attempts to use the next slower interconnect until this connectivity requirement is met. Table 6-1, specifies the order in which MPI probes for available interconnects.
Table 6-1. Inquiry Order for Available Interconnects
Interconnect | Default Order of Selection | Environment Variable to Require Use | Environment Variable for Specifying Device Selection |
|---|---|---|---|
XPMEM* | 1 | MPI_USE_XPMEM | NA |
GSN | 2 | MPI_USE_GSN | MPI_GSN_DEVS |
Myrinet(GM)* | 3 | MPI_USE_GM | MPI_GM_DEVS |
HIPPI 800 | 4 | MPI_USE_HIPPI | MPI_BYPASS_DEVS |
TCP/IP | 5 | MPI_USE_TCP | NA |
*These interconnects are available only on Origin 300 and Origin 3000 series computers.
The third column of Table 6-1 also indicates the environment variable you can set to pick a particular interconnect other than the default. For example, suppose you want to run an MPI job on a cluster supporting both GSN and HIPPI interconnects. By default, the MPI job would try to run over the GSN interconnect. If for some reason, you wanted to use the HIPPI 800 interconnect, you would set the MPI_USE_HIPPI shell variable before launching the job. This would cause the MPI library to attempt to run the job using the HIPPI interconnect. The job will fail if the HIPPI interconnect cannot be used.
The XPMEM interconnect is exceptional in that it does not require that all hosts in the MPI job need to be reachable via the XPMEM device. Message traffic between hosts not reachable via XPMEM will go over the next fastest interconnect. Also, when you specify a particular interconnect to use, you can set the MPI_USE_XPMEM variable in addition to one of the other four choices.
In general, to insure the best performance of the application, you should allow MPI to pick the fastest available interconnect.
In addition to the choice of interconnect, you should know that multihost jobs use different buffers from those used by jobs run on a single host. In the SGI implementation of MPI, all of the previously mentioned interconnects rely on the 'per host' buffers to deliver long messages. The default setting for the number of buffers per host might be too low for many applications. You can determine whether this setting is too low by using the MPI statistics described earlier in this section. In particular, the 'retries allocating mpi PER_HOST' metric should be examined. High retry counts indicate that the MPI_BUFS_PER_HOST shell variable should be increased. For example, when using Myrinet(GM), it has been observed that 256 or 512 are good settings for the MPI_BUFS_PER_HOST shell variable.
When considering these MPI statistics, GSN and HIPPI 800 users should also examine the 'retries allocating mpi PER_HOST headers' counters. It might be necessary to increase the MPI_MSGS_PER_HOST shell variable in cases in which this metric indicates high numbers of retries. Myrinet(GM) does not use this resource.
When using GSN, Myrinet, or HIPPI 800 high performance networks, MPI attempts to use all available adapters (cards) available on each host in the job. You can modify this behavior by specifying specific adpter(s) to use. The fourth column of Table 6-1 indicates the shell variable to use for a given network. For details on syntax, see the MPI man page. Users of HIPPI 800 networks have additional control over the way in which MPI uses multiple adapters via the MPI_BYPASS_DEV_SELECTION variable. For details on the use of this environment variable, see the MPI man page.
When using the TCP/IP interconnect, unless specified otherwise, MPI uses the default IP adpater for each host. To use a non-default adapter, the adapterr-specific host name can be used on the mpirun command line.
Hybrid MPI/OpenMP applications might require special memory placement features to operate efficiently on cc-NUMA Origin servers. A preliminary method for realizing this memory placement is available. The basic idea is to space out the MPI processes to accomodate the OpenMP threads associated with each MPI process. In addition, assuming a particular ordering of library init code (see the DSO(5) man page), procedures are employed to insure that the OpenMP threads remain close to the parent MPI process. This type of placement has been found to improve the performance of some hybrid applications significantly when more than four OpenMP threads are used by each MPI process.
To take partial advantage of this placement option, the following requirements must be met:
The user must set the MPI_OPENMP_INTEROP shell variable when running the application.
The user must use a MIPSpro compiler and the -mp option to compile the application. This placement option is not available with other compilers.
To take full advantage of this placement option, the user must be able to link the application such that the libmpi.so init code is run before the libmp.so init code. This is done by linking the MPI/OpenMP application as follows:
cc -64 -mp compute_mp.c -lmp -lmpi f77 -64 -mp compute_mp.f -lmp -lmpi f90 -64 -mp compute_mp.f -lmp -lmpi CC -64 -mp compute_mp.C -lmp -lmpi++ -lmpi
This linkage order insures that the libmpi.so init runs procedures for restricting the placement of OpenMP threads before the libmp.so init is run. Note that this is not the default linkage if only the -mp option is specified on the link line.
You can use an additional memory placement feature for hybrid MPI/OpenMP applications by using the MPI_DSM_PLACEMENT shell variable. Specification of a threadroundrobin policy results in the parent MPI process stack, data, and heap memory segments being spread across the nodes on which the child OpenMP threads are running. For more information, see Chapter 5, “Setting Environment Variables”.
MPI reserves nodes for this hybrid placement model based on the number of MPI processes and the number of OpenMP threads per process, rounded up to the nearest multiple of 4. For example, if 6 OpenMP threads per MPI process are going to be used for a 4 MPI process job, MPI will request a placement for 32 (4 X 8) CPUs on the host machine. You should take this into account when requesting resources in a batch environment or when using cpusets. In this implementation, it is assumed that all MPI processes start with the same number of OpenMP threads, as specified by the OMP_NUM_THREADS or equivalent shell variable at job startup.
 | Note: This placement is not recommended when setting _DSM_PPM to a non-default value (for more information, see pe_environ(5)). Also, if you are using MPI_DSM_MUSTRUN, it is important to also set _DSM_MUSTRUN to properly schedule the OpenMP threads. |
Most techniques and tools for optimizing serial codes apply to message passing codes as well. Speedshop (ssrun) and perfex are tools that work well. The following tips for optimizing are described in this section:
MPI constructs to avoid
How to reproduce timings
How to use MPI statistics
A summary of the profiling tools available and how to get started using them
This section describes certain MPI constructs to avoid in performance critical sections of your application.
The MPI library has been enhanced to optimize certain point-to-point and collective calls. Calls that have not been optimized and should be avoided in critical areas of an application are MPI_Bsend, MPI_Ssend, and MPI_Issend.
The MPI_Bsend call is a buffered send and essentially doubles the amount of data to be copied by the sending process.
The MPI_Ssend and MPI_Issend are synchronous sends that do not begin sending the message until they have received an acknowledgment (ACK) from the destination process that it is ready to receive the message. This significantly increases latency, especially for short messages (less than 64 bytes).
While MPI_Pack and MPI_Unpack are useful for porting PVM codes to MPI, they essentially double the amount of data to be copied by both the sender and the receiver. It is best to avoid the use of these functions by either restructuring your data or using MPI derived data types.
The use of wild cards (MPI_ANY_SOURCE, MPI_ANY_TAG) involves searching multiple queues for messages. While this is not significant for small process counts, for large process counts the cost increases quickly.
One of the most common problems with optimizing message passing codes is achieving reproducible timings from run to run. Use the following tips to reduce runtime variability:
Do not oversubscribe the system. In other words, do not request more CPUs than are available and do not request more memory than is available. Oversubscribing causes the system to wait unnecessarily for resources to become available and leads to variations in the results and less than optimal performance.
Use cpusets to divide the host's CPUs and memory between applications or use the MPI_DSM_CPULIST environment variable on quiet systems to control NUMA placement.
Use a batch scheduler like LSF from Platform Computing or PBSpro from Veridian, which can help avoid oversubscribing the system and poor NUMA placement.
To turn on the displaying of MPI internal statistics, use the MPI_STATS environment variable or the -stats option on the mpirun command. MPI internal statistics are always being gathered, so displaying them simply lets you see them during MPI_Finalize. These statistics can be very useful in optimizing codes in the following ways:
To determine if there are enough internal buffers and if processes are waiting (retries) to aquire them
To determine if single copy optimization is being used for point-to-point or collective calls
In addition to the MPI statistics, users can get additional performance information from several SGI or third party tools, or they can write their own wrappers. For long running codes or codes that use hundreds of processors, the trace data generated from MPI performance tools can be enormous. This causes the programs to run more slowly, but even more problematic is that the tools to analyze the data are often overwhelmed by the amount of data.
A better approach is to use a general purpose profiling tool to locate the problem area and then to turn on and off the tracing just around those areas of your code. With this approach the display tools can better handle the amount of data that is generated. Two third party tools that you can use in this way are Vampir from Pallas (www.pallas.com) and Jumpshot, which is part of the MPICH distribution.
Two of the most common SGI profiling tools are Speedshop and perfex. The following sections describe how to invoke Speedshop and perfex for typical profiling of MPI codes. Performance-CoPilot (PCP) tools and tips for writing your own tools are also included.
You can use Speedshop as a general purpose profiling tool or specific profiling tool for MPI potential bottlenecks. It has an advantage over many of the other profiling tools because it can map information to functions and even line numbers in the user source program. The examples listed below are in order from most general purpose to the most specific. You can use the -ranks option to limit the data files generated to only a few ranks.
General format:
mpirun -np 4 ssrun [ssrun_options] a.out |
Examples:
mpirun -np 32 ssrun -pcsamp a.out # general purpose, low cost mpirun -np 32 ssrun -usertime a.out # general purpose, butterfly view mpirun -np 32 ssrun -bbcounts a.out # most accurate, most cost, butterfly view mpirun -np 32 ssrun -mpi a.out # traces MPI calls mpirun -np 32 ssrun -tlb_hwctime a.out # profiles TLB misses |
You can use perfex to obtain information concerning the hardware performance monitors.
General format:
mpirun -np 4 perfex -mp [perfex_options] -o file a.out |
Example:
mpirun -np 4 perfex -mp -e 23 -o file a.out # profiles TLB misses |
In addition to the tools described in the preceding sections, you can also use the MPI Agent for Performance-CoPilot (PCP) to profile your application. The two additional PCP tools specifically designed for MPI are mpivis and mpimon. These tools do not use trace files and can be used live or can be logged for later replay. For more information about configuring and using these tools, see the PCP tutorial in /var/pcp/Tutorial/mpi.html. Following are examples of the mpivis and mpimon tools.
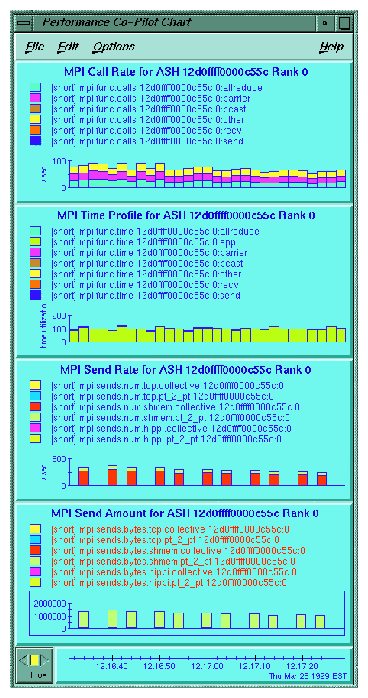
You can write your own profiling by using the MPI-1 standard PMPI_* calls. In addition, either within your own profiling library or within the application itself you can use the MPI_Wtime function call to time specific calls or sections of your code.
The following example is actual output for a single rank of a program that was run on 128 processors using a user-created profiling library that performs call counts and timings of common MPI calls. Notice that for this rank most of the MPI time is being spent in MPI_Waitall and MPI_allreduce.
Total job time 2.203333e+02 sec
Total MPI processes 128
Wtime resolution is 8.000000e-07 sec
activity on process rank 0
comm_rank calls 1 time 8.800002e-06
get_count calls 0 time 0.000000e+00
ibsend calls 0 time 0.000000e+00
probe calls 0 time 0.000000e+00
recv calls 0 time 0.00000e+00 avg datacnt 0 waits 0 wait time 0.00000e+00
irecv calls 22039 time 9.76185e-01 datacnt 23474032 avg datacnt 1065
send calls 0 time 0.000000e+00
ssend calls 0 time 0.000000e+00
isend calls 22039 time 2.950286e+00
wait calls 0 time 0.00000e+00 avg datacnt 0
waitall calls 11045 time 7.73805e+01 # of Reqs 44078 avg datacnt 137944
barrier calls 680 time 5.133110e+00
alltoall calls 0 time 0.0e+00 avg datacnt 0
alltoallv calls 0 time 0.000000e+00
reduce calls 0 time 0.000000e+00
allreduce calls 4658 time 2.072872e+01
bcast calls 680 time 6.915840e-02
gather calls 0 time 0.000000e+00
gatherv calls 0 time 0.000000e+00
scatter calls 0 time 0.000000e+00
scatterv calls 0 time 0.000000e+00
activity on process rank 1
... |