Many programs need data to begin a calculation. After the calculation is completed, often the results need to be printed, displayed graphically, or saved for later use. During execution of a program, sometimes there is a large amount of data produced by one part of the program that needs to be saved for use by another part of the program, and the amount of data is too large to store in variables, such as arrays. Also, the editing capabilities of the data transfer statements for internal files can be used for processing character strings. Each of these tasks is accomplished using Fortran I/O statements described in this chapter.
The I/O statements are as follows:
| READ |
| WRITE |
| OPEN |
| CLOSE |
| INQUIRE |
| BACKSPACE |
| ENDFILE |
| REWIND |
The READ statement is a data transfer input statement and provides a means for transferring data from an external media to internal storage or from an internal file to internal storage through a process called reading. The WRITE and PRINT statements are both data transfer output statements and provide a means for transferring data from internal storage to an external media or from internal storage to an internal file. This process is called writing. The OPEN and CLOSE statements are both file connection statements. The INQUIRE statement is a file inquiry statement. The BACKSPACE, ENDFILE, and REWIND statements are file positioning statements.
The first part of this chapter discusses terms and concepts you need to gain a thorough understanding of all of the I/O facilities. These include internal and external files, formatted and unformatted records, sequential and direct access methods for files, advancing and nonadvancing I/O for the sequential formatted access method, file and record positions, units, and file connection properties. Following the concepts are descriptions of the READ, WRITE, and PRINT data transfer statements and the effect of these statements when they are executed. A model for the execution of data transfer statements and a description of the possible error and other conditions created during the execution of data transfer statements are provided next. Following the model are the descriptions of the OPEN, CLOSE, and INQUIRE statements that establish, respectively, the connection properties between units and files; that disconnect units and files; and that permit inquiry about the state of the connection between a unit and file. Lastly, file position statements are specified, which include the BACKSPACE and REWIND statements, followed by the description of the ENDFILE statement that creates end-of-file records.
The chapter concludes with a summary of the terms, concepts, and statements used for input and output processing and some examples.
Collections of data are stored in files. The data in a file is organized into records. Fortran treats a record, for example, as a line on a computer terminal, a line on a listing, or a logical record on a magnetic tape or disk file. However, the general properties of files and records do not depend on how the properties are acquired or how the files and records are stored. This section discusses the properties of records and files, and the various kinds of data transfer.
A file is a sequence of records. The following section describes the properties of records.
UNICOS physical files and records are described in the UNICOS File Formats and Special Files Reference Manual. If you are using the MIPSpro 7 Fortran 90 compiler, you can assume that standard UNIX file formats are used.
There are two kinds of records: data and end-of-file. A data record is a sequence of values.
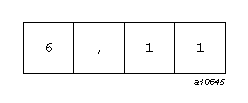
The values in a data record can be represented in one of two ways: formatted or unformatted. Formatted data consists of characters that are viewable on some medium. For example, a record could contain the following four character values:
| 6 |
| , |
| 1 |
| 1 |
These are intended to represent the two numbers 6 and 11. In this case, the record might be represented schematically as shown in Figure 1-1.
Unformatted data consists of values represented just as they are stored in computer memory. For example, if integers are stored using a binary representation, an unformatted record, consisting of two integer values, 6 and 11, might look like Figure 1-2.
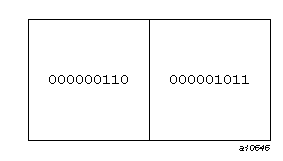
The values in a data record are either all formatted or all unformatted. A formatted record is one that contains only formatted data. It can be created by a person typing at a terminal or by a Fortran program that converts values stored internally into character strings that form readable representations of those values. When a program reads formatted data, the characters must be converted to the computer's internal representation of values. Even character values can be converted from one character representation in the record to another internal representation. The length of a formatted record is the number of characters in it; the length can be zero.
An unformatted record is one that contains only unformatted data. Unformatted records usually are created by running a Fortran program, but they can be created by other means. Unformatted data often requires less space on an external device. Also, it is usually faster to read and write because no conversion is required. However, it is not as suitable for reading by people and usually it is not suitable for transferring data from one computer to another because the internal representation of values is machine-dependent. The length of an unformatted data record depends on the number of values in it, but is measured in bytes; it can be zero. The length of an unformatted record that will be produced by a particular output list can be determined with the INQUIRE statement.
In general, a formatted record is read and written by a formatted data transfer I/O statement, and an unformatted record is read and written by an unformatted data transfer I/O statement.
Another kind of record is the end-of-file record; it has no value and has no length.
On UNICOS and UNICOS/mk systems, certain file structures allow more than one end-of-file record in a file. The COS blocking format is the default file structure for all UNICOS Fortran sequential unformatted files (except tape files). It can have multiple end-of-file records. For general information on records supported on UNICOS and UNICOS/mk systems, see the Application Programmer's I/O Guide.
For UNICOS structures other than COS blocked, and for structures on IRIX systems, an end-of-file record is always the last record of a file. It is used to mark the end of a file. To write it explicitly for files connected for sequential access, use the ENDFILE statement; to write it implicitly, use a file positioning statement (REWIND or BACKSPACE statement), close the file (CLOSE statement), open the file (OPEN statement), or use normal termination of a program.
 | Note: The Fortran standard does not allow for multiple end-of-file records in a file. |
A file can be named. The length of the file name and path name depend on the platform, as follows:
UNICOS and UNICOS/mk systems allow 256 characters for a file name. This file name can include a directory name and 1023 characters for the full path name.
IRIX systems allow 256 characters for a file name. The full path name is limited to 1023 characters.
A distinction is made between files that are located on an external device like a disk, and files in memory accessible to the program. These two kinds of files are as follows:
External files
Internal files
The use of these files is illustrated schematically in Figure 1-3.
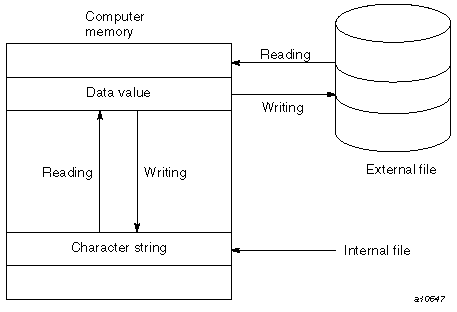
External files are located on external devices such as tapes, disks, or computer terminals. For each external file, there is a set of allowed access methods, a set of allowed forms, a set of allowed actions, and a set of allowed record lengths. These characteristics are determined by a combination of requests by the user of the file and by actions of the operating system. Each characteristic is discussed later in this section.
An external file connected to a unit has the position property. The file is positioned at the current record. In some cases, the file is positioned within the current record.
The contents of internal files are stored as values of variables of type character. You can create the character values by using all the usual means of assigning character values, or you can create them with an output statement that specifies the variable as an internal file. Data transfer to and from internal files is described in “Data Transfer on Internal Files”. Such data transfer to and from an internal file must use formatted sequential access I/O statements, including list-directed data transfer, but not namelist data transfer.
File connection, file positioning, and file inquiry must not be used with internal files. If the variable representing the internal file is a scalar, the file has just one record; if the variable is an array, the file has one record for each element of the array. The order of the records is the order of the elements in the array. The length of each record is the length of one array element.
Certain files are made known to the system for any executing program, and these files are said to exist at the time the program begins executing. A file might not exist because it is not anywhere on the disks accessible to a system or because the user of the program is not authorized to access the file.
In addition to files that are made available to programs for input, output, and other special purposes, programs can create files needed during and after program execution. When the program creates a file, it is said to exist, even if no data has been written into it. A file can cease to exist after it has been deleted. Any of the I/O statements can refer to files that exist for the program at that point during execution. Some of the I/O statements (INQUIRE, OPEN, CLOSE, WRITE, PRINT, REWIND, and ENDFILE) can refer to files that do not exist. A WRITE or PRINT statement can create a file that does not exist and put data into that file, unless an error condition occurs.
An internal file always exists.
Each file being processed by a program has a position. During the course of program execution, records are read or written, causing the file position to change. Also, there are other Fortran statements that cause the file position to change; an example is the BACKSPACE statement. The action produced by the I/O statements is described in terms of the file position, so it is important that file position be discussed in detail.
The initial point is the point just before the first record. The terminal point is the point just after the last record. If the file is empty, the initial point and the terminal point are the same. A file position can become indeterminate, in particular, when an error condition occurs. When the file position becomes indeterminate, the programmer cannot rely on the file being in any particular position.
A file can be positioned between records. In the example pictured in Figure 1-4, the file is positioned between records 2 and 3. In this case, record 2 is the preceding record and record 3 is the next record. Of course, if a file is positioned at its initial point, there is no preceding record, and there is no next record if it is positioned at its terminal point.
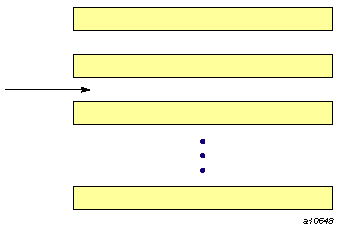
There may be a current record during execution of an I/O statement or after completion of a nonadvancing I/O statement as shown in Figure 1-5 where record 2 is the current record. If the file is positioned within a current record, the preceding record is the record immediately previous to the current record, unless the current record is also the initial record, in which case there is no preceding record. Similarly, the next record is the record immediately following the current record, unless the current record is also the final record, in which case there is no next record.
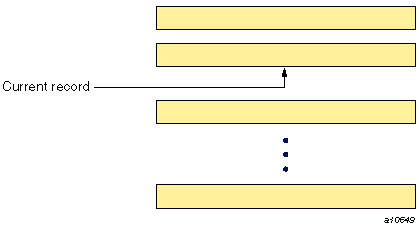
When there is a current record, the file is positioned at the initial point of the record, between values in the record, or at the terminal point of the record.
An internal file is always positioned at the beginning of a record just prior to data transfer.
Advancing I/O is record oriented; completion of such an operation always positions a file at the end of a record or between records, unless an error condition occurs. In contrast, nonadvancing I/O is character oriented; after reading and writing, the file can be positioned between characters within the current record.
While reading a file, the position of a nonadvancing file depends on whether success, data transfer, error, end-of-file, or end-of-record conditions occur while reading the file. The file position is indeterminate following an error condition when reading a file.
While writing a file, the position of a nonadvancing file depends on whether success, data transfer, or error conditions occur while writing the file. The file position is indeterminate following an error condition when writing a file.
When a nonadvancing input operation is performed, the file can be positioned after the last character of the file and before the logical or physical end-of-record. A subsequent nonadvancing input operation causes an end-of-record condition to occur, regardless of whether this record is the last record of the file. If another read operation is executed after the end-of-record condition occurs and the record is the last record of the file, an end-of-file condition occurs.
There are two access file methods:
Sequential access
Direct access
Some files can be accessed by both methods; other files can be restricted to one access method or the other. For example, a magnetic tape can be accessed only sequentially. While each file is connected, it has a set of permissible access methods, which usually means that it can be accessed either sequentially or directly. However, a file cannot be connected for both direct and sequential access simultaneously; that is, if a file is connected for direct access, it must be disconnected with a CLOSE statement and reconnected with an OPEN statement specifying sequential access before it can be referenced in a sequential access data transfer statement, and vice versa.
The actual file access method used to read or write the file is not strictly a property of the file itself, but is indicated when the file is connected to a unit or when the file is created, if the file is preconnected. The same file can be accessed sequentially by a program, then disconnected, and then later accessed directly by the same program, if both types of access are permitted for the file.
Sequential access to the records in the file begins with the first record of the file and proceeds sequentially to the second record, and then to the next record, record-by-record. The records are accessed serially as they appear in the file. It is not possible to begin at some particular record within the file without reading down to that record in sequential order.
When a file is being accessed sequentially, the records are read and written sequentially. For example, if the records are written in any arbitrary order using direct access (see “Direct Access”) and then read using sequential access, the records are read beginning with record number 1 of the file, regardless of when it was written.
An important property of sequential files is that the last record written to the file is always the last record in the file. For example, consider a file with ten records. An application can open the file and read all ten records. If the application subsequently rewinds the file and writes one record, then there is only one record in the file at that time. Each record written to a file truncates any and all records that may have been after it.
When a file is accessed directly, the records are selected by record number. Using this identification, the records can be read or written in any order. Therefore, it is possible to write record number 47 first, then number 13. Reading or writing such records is accomplished by direct access data transfer I/O statements. Either record can be written without first accessing the other.
By default, a formatted file can be created to support sequential or direct access, using the ACCESS specifier on the OPEN statement. A formatted file can support both kinds of access if it is closed and reopened with a different specification and if all records are of equal length. If a file supports both methods of access, the first record accessed sequentially is the record numbered 1 for direct access; the second sequential record is record 2 for direct access, and so on.
While a file is connected for one kind of access (sequential or direct), only I/O statements using that kind of access can be used with the file.
I/O statements refer to a particular file by providing an I/O unit. An I/O unit is either an external unit or an internal unit. An external unit is either a nonnegative integer or an asterisk (*). When an external file is a nonnegative integer, it is called an external file unit. Table 1-1, lists the unit numbers supported by the CF90 and MIPSpro 7 Fortran 90 compilers.
A unit number identifies one and only one external unit in all program units in a Fortran program at a time.
File positioning, file connection, and inquiry statements must use an external unit.
If you are running the CF90 compiler on a UNICOS or UNICOS/mk system, an external_unit_name can be used to designate an external file unit in a data transfer or file positioning statement; if you use an external name, it must be from 1 to 7 characters in length and be enclosed in apostrophes or quotation marks.
| Note: The Fortran standard does not describe the use of external names to designate a unit. |
An internal unit must be a default character variable. The name of an internal file also is called a unit.
The collection of unit numbers that can be used in a program for external files consists of all non-negative integers. These unit numbers are said to exist. I/O statements must refer to units that exist, except for those that close a file or inquire about a unit.
The assignments for unit numbers 100, 101, and 102 cannot be changed, and these numbers cannot appear in an OPEN statement. A CLOSE statement on these units has no effect.
Numbers 0, 5, and 6 are not equivalent to the asterisk, and they can be reassigned.
The following table shows the unit numbers available:
Table 1-1. CF90 and MIPSpro 7 Fortran 90 unit numbers
Unit number | Availability |
|---|---|
0 | Preconnected to the stderr file but available for user reassignment |
1-4 | Available for user specification |
5 | Preconnected to the stdin file but available for user reassignment |
6 | Preconnected to stdout but available for user reassignment |
7-99 | Available for user specification |
100 | Dedicated for use as the stdin file |
101 | Dedicated for use as the stdout file |
102 | Dedicated for system as the stderr file |
103-HUGE(3i) | Available for user specification |
In order to transfer data to or from an external file, the file must be connected to a unit. An internal file is always connected to the unit that is the name of the character variable. There are two ways to establish a connection between a unit and an external file:
Execution of an OPEN statement in the executing program
Preconnection by the operating system
Only one file can be connected to a unit at any given time and vice versa. If the unit is disconnected after its first use on a file, it can be reconnected later to another file or to the same file. A file that is not connected to a unit must not be used in any statement, except the OPEN, CLOSE, or INQUIRE statements.
Some units can be preconnected to files for each Fortran program by the operating system without any action necessary by the program. For example, units 0, 5, and 6 are preconnected to files stderr, stdin, and stdout, respectively. All other available units are, in essence, preconnected to the corresponding fort.n file. For example, unit 9 is preconnected to fort.9 and unit 10 is preconnected to fort.10. You also can use the assign(1) command to preconnect units. In either of these cases, the user program does not require an OPEN statement to connect a file for sequential access; it is preconnected.
Once a file has been disconnected, the only way to reference it is by its name, using an OPEN or INQUIRE statement. There is no means of referencing an unnamed file once it is disconnected.
When a unit is connected, either by preconnection or execution of an OPEN statement, data can be transferred by reading and writing to the file associated with the unit. The transfer can occur to or from internal or external files.
The data transfer statements are the READ, WRITE, and PRINT statements. This section presents the general form of the data transfer statements first, followed by the forms that specify the major uses of data transfer statements.
The READ, WRITE, and PRINT statements are defined as follows:
| read_stmt | is |
| |
|
| or |
| |
| write_stmt | is |
| |
EXT |
| or |
| |
| print_stmt | is |
|
| Note: The Fortran standard does not specify the WRITE format[ , output_item_list] form of the WRITE statement. |
The io_control_spec_list, the input_item_list, the output_item_list, and the format variables are described in subsequent sections. The format item is called a format specifier.
The I/O control specifiers are defined as follows:
| io_control_spec | is |
| |
|
| or |
| |
|
| or |
| |
|
| or |
| |
|
| or |
| |
|
| or |
| |
|
| or |
| |
|
| or |
| |
|
| or |
| |
|
| or |
|
The UNIT= specifier, with or without the keyword UNIT, is called a unit specifier.
The FMT= specifier, with or without the keyword FMT, is called a format specifier.
The NML= specifier, with or without the keyword NML, is called a namelist specifier.
The data transfer statement is called a formatted I/O statement if a format or namelist group name specifier is present; it is called an unformatted I/O statement if neither is present. If a namelist group name specifier is present, it is called a namelist I/O statement. It is called a direct access I/O statement if a REC= specifier is present; otherwise, it is called a sequential access I/O statement.
The I/O control specification list must contain a unit specifier and can contain any of the other I/O control specifiers (but none can appear more than once). An FMT= and an NML= specifier cannot both appear in the same list.
This section describes the form and effect of the control information specifiers that are used in the data transfer statements. The NML=, ADVANCE=, END=, EOR=, REC=, and SIZE= specifiers are each unique to one of the forms of the data transfer statements, whereas the other specifiers are used in more than one form. In particular, NML= is used in the namelist data transfer statement; the ADVANCE=, EOR=, and SIZE= specifiers are used in input data transfer statements to specify nonadvancing formatted sequential data transfer; and the REC= specifier is used for direct access data transfer.
The format of the UNIT= control specifier is as follows:
[ UNIT = ]io_unit |
An io_unit is defined as follows:
| io_unit | is |
| |
|
| or |
| |
|
| or |
| |
EXT |
| or |
| |
| external_file_unit | is |
| |
| internal_file_unit | is |
|
| Note: The Fortran standard does not specify the use of a unit_name. |
If you specify a scalar_int_expr for io_unit, it must be nonnegative and in the range of 0 through HUGE(3i). Units 100 through 103 are reserved. For more information on units, see Table 1-1.
Specifying an asterisk (*) for io_unit indicates a default external unit. It is the same unit number that would be defined if a READ or PRINT statement appeared without the unit number. The io_unit specified by an asterisk can be used only for formatted sequential access. The external unit used for a READ statement without a unit specifier or a READ statement with an asterisk unit specifier need not be the same as that used for a PRINT statement or WRITE statement with an asterisk unit specifier.
If you are using the CF90 compiler on a UNICOS or UNICOS/mk system, specifying an external_unit_name indicates a file name. The name can consist of 1 to 7 left-justified, blank-filled, or zero-filled ASCII characters. The use of uppercase and lowercase is significant for file names.
A unit specifier is required. A unit number identifies one and only one external unit in all program units in a Fortran program.
If the UNIT keyword is omitted, the I/O unit must be first. In this case, the keyword FMT or NML can be omitted from the format or namelist specifier. If the format or namelist specifier appears in the list, it must be the second specifier in the list.
The format of the FMT= control specifier is as follows:
[ FMT = ]format |
The format is defined as follows:
| format | is |
| |
|
| or |
| |
|
| or |
|
Specifying a char_expr, which provides the format specification in the form of a character string, indicates formatted I/O. The character expression must be a valid format specification. If the expression is an array, it is treated as if all elements of the array were concatenated together in array element order and must be a valid format specification.
Specifying a label, which provides the statement label of a FORMAT statement containing the format specification, indicates formatted I/O. The label must be the label of a FORMAT statement in the same scoping unit as the data transfer statement.
Specifying a scalar_default_int_variable, which provides an integer variable that has been assigned the label of a FORMAT statement, indicates formatted I/O. The label value must have been assigned to the integer variable using an ASSIGN statement and must be the label of a FORMAT statement in the same scoping unit as the data transfer statement. For information on the FORMAT statement, see “FORMAT Statement” in Chapter 2.
Specifying an asterisk (*) indicates list-directed formatting.
The keyword FMT= can be omitted if the format specifier is the second specifier in the control information list and if the UNIT keyword was also omitted; otherwise, it is required.
If a format specifier is present, a namelist specifier (NML=) must not be present.
The format of the NML= control specifier is as follows:
[ NML = ]namelist_group_name |
For namelist_group_name, specify the name of a namelist group declared in a NAMELIST statement. The namelist group name identifies the list of data objects to be transferred by the READ or WRITE statement with the NML= specifier.
If a namelist specifier is present, a format specifier must not be present.
The format of the ADVANCE= control specifier is as follows:
ADVANCE = scalar_char_expr |
For scalar_char_expr, specify YES or NO. NO indicates nonadvancing formatted sequential data transfer. YES indicates advancing formatted sequential data transfer.
Trailing blanks in the character expression are ignored. The value of the specifier is without regard to case (upper or lower); that is, the value no is the same as NO.
If an ADVANCE= specifier appears in the control information list, the data transfer must be a formatted sequential data transfer statement connected to an external unit. List-directed and namelist I/O are not allowed.
If the EOR= or SIZE= specifier appears in the control information list, an ADVANCE= specifier must also appear with the value NO.
The format of the END= control specifier is as follows:
END = label |
If an end-of-file condition occurs and no error condition occurs during the execution of the READ statement, the program branches to the label in the END= specifier. The label must be the label of a branch target statement in the same scoping unit as the READ statement.
The END= specifier can appear only in a sequential access READ statement; note that the END= specifier must not appear in a WRITE statement.
If the file is an external file, it is positioned after the end-of-file record.
If an IOSTAT= specifier is present and end-of-file condition occurs, but no error condition occurs, the IOSTAT variable specified becomes defined with a negative value.
The format of the EOR= control specifier is as follows:
EOR = label |
The program branches to the labeled statement specified by the EOR= specifier if an end of record is encountered for a nonadvancing READ statement. The label must be the label of a branch target statement in the same scoping unit as the READ statement.
The EOR= specifier can appear only in a READ statement with an ADVANCE= specifier with a value of NO, that is, a nonadvancing READ statement.
If an end-of-record condition occurs and no error condition occurs during the execution of the READ statement:
The file is positioned after the current record.
The variable given in the IOSTAT= specifier, if present, becomes defined with a negative value.
If the connection has been made with the PAD= specifier of YES, the record is padded with blanks to satisfy both the input item list and the corresponding data edit descriptor if the input item and/or data edit descriptor requires more characters than are provided in the record.
The variable given in the SIZE= specifier, if present, becomes defined with an integer value equal to the number of characters read from the input record; however, blank padding characters inserted because the PAD= specifier is YES are not counted.
Execution of the READ statement terminates, and the program branches to the label in the EOR= specifier.
The format of the ERR= control specifier is as follows:
ERR = label |
If an error condition occurs, the position of the file becomes indeterminate.
The program branches to the label in the ERR= specifier if an error occurs in a data transfer statement. The label must be the label of a branch target statement in the same scoping unit as the data transfer statement.
If an IOSTAT= specifier is also present and an error condition occurs, the IOSTAT variable specified becomes defined with a positive value.
If the data transfer statement is a READ statement, contains a SIZE= specifier, and an error condition occurs, then the variable specified by the SIZE= specifier becomes defined with an integer value equal to the number of characters read from the input record; however, blank padding characters inserted because the PAD= specifier is YES are not counted.
The format of the IOSTAT= control specifier is as follows:
IOSTAT = scalar_default_int_variable |
An integer value is returned in scalar_default_int_variable. The meaning of the return value is as follows:
If scalar_default_int_variable > 0, an error condition occurred.
If scalar_default_int_variable = 0, no error, end-of-file, or end-of-record condition occurred.
If scalar_default_int_variable < 0, an end-of-file or end-of-record condition occurred. The end-of-file negative value is not the same as the negative value indicating the end-of-record condition.
The IOSTAT= specifier applies to the execution of the data transfer statement itself.
The variable specified in the IOSTAT= specifier must not be the same as or associated with any entity in the I/O item list or in the namelist group or with the variable specified in the SIZE= specifier, if present.
If the variable specified in the IOSTAT= specifier is an array element, its subscript values must not be affected by the data transfer, by any implied-DO item or processing, or with the definition or evaluation of any other specifier in the control specifier list.
You can obtain an online explanation of an error identified by the IOSTAT variable value. To do this, join the returned value with its group name, shown in the following list, and use the resulting string as an argument to the explain(1) command. For example:
explain lib-5000 |
Table 1-2. Message number identifiers
Message number | Group name | Source of message | |
1 through 899 | sys | Operating system (UNICOS and UNICOS/mk systems)1 | |
1000 through 1999 | lib | Fortran library (UNICOS and UNICOS/mk systems)1 | |
4000 through 4999 | lib | Fortran library (IRIX systems) | |
5000 through 5999 | lib | Flexible File I/O (FFIO) library | |
90000 through 90500 | None | Tape system (UNICOS and UNICOS/mk systems)1 | |
1 On IRIX systems, see intro(2) for explanations of messages numbered less than 4000 and greater than 89999. | |||
The format of the REC= control specifier is as follows:
REC = scalar_int_expr |
The scalar_int_expr specifies an integer value that indicates the record number to be read or written.
The REC= specifier can appear only in a data transfer statement with a unit that is connected for direct access.
If the REC= specifier is present in a control information list, an END= or format specifier with an asterisk (for list-directed data transfer) must not be specified in the same control information list.
The format of the SIZE= control specifier is as follows:
SIZE = scalar_default_int_variable |
The I/O system returns a nonnegative integer value in scalar_default_int_variable that indicates the number of characters read.
The SIZE= specifier applies to the execution of the READ statement itself and can appear only in a READ statement with an ADVANCE= specifier with the value NO.
Blanks inserted as padding characters when the PAD= specifier is YES for the connection are not counted.
The variable specified in the SIZE= specifier must not be the same as or associated with any entity in the I/O item list or in the namelist group or with the variable specified in the IOSTAT= specifier, if present.
If the variable specified in the SIZE= specifier is an array element, its subscript values must not be affected by the data transfer, by any implied-DO item or processing, or with the definition or evaluation of any other specifier in the control specifier list.
The I/O item list consists basically of a list of variables in a READ statement and a list of expressions in a WRITE or PRINT statement. In addition, in any of these statements, the I/O item list can contain an I/O implied-DO list, containing a list of variables or expressions indexed by DO variables.
The components of the I/O lists are defined as follows:
| input_item | is |
| |
|
| or |
| |
| output_item | is |
| |
|
| or |
| |
| io_implied_do | is |
| |
| io_implied_do_object | is |
| |
|
| or |
| |
| io_implied_do_control | is |
|
The DO variable must be a scalar integer or real variable. If it is real, it must be default real or double-precision real.
| Note: The Fortran standard does not specify real or double-precision DO variables. The CF90 and MIPSpro 7 Fortran 90 compilers support these types as an extension to the Fortran standard. |
Each scalar numeric expression must be of type integer or real. If it is of type real, each must be of type default real or default double precision; the use of such real expressions is considered obsolescent. They need not be all of the same type nor of the type of the DO variable.
The DO variable must not be one of the input items in the implied-DO; it must not be associated with an input item either.
Two nested implied-DOs must not have the same (or associated) DO variables.
An implied-DO object, when it is part of an input item, must itself be an input item; that is, it must be a variable or an implied-DO object whose objects are ultimately variables. Similarly, an implied-DO object, when it is part of an output item, must itself be an output item; that is, it must be an expression or an implied-DO object whose objects are ultimately expressions.
For an I/O implied-DO, the loop is initialized, executed, and terminated in the same manner as for the DO construct. Its iteration count is established at the beginning of processing of the items that constitute the I/O implied-DO.
An array appearing without subscripts in an I/O list is treated the same as if all elements of the array appeared in array-element order. In the following example, assume UP is an array of shape (2,3):
READ *, UP |
The preceding statement is the same as the following code:
READ *, UP(1,1), UP(2,1), UP(1,2), &
UP(2,2), UP(1,3), UP(2,3) |
When a subscripted array is an input item, it is possible that when a value is transferred from the file to the variable, it might affect another part of the input item. This is not allowed. Consider the following READ statements, for example:
INTEGER A(100), V(10) READ *, A(A) READ *, A(A(1):A(9)) ! Suppose V's elements are defined with ! values in the range 1 to 100. READ *, A(V) |
The first two READ statements are not valid because the data values read affect other parts of array A. The third READ statement is allowed as long as no two elements of V have the same value.
Assumed-size arrays cannot appear in I/O lists unless a subscript, a section subscript specifying an upper bound, or a vector subscript appears in the last dimension.
In formatted I/O, a structure is treated as if, in place of the structure, all components were listed in the order of the components in the derived-type definition. In the following statement, assume that FIRECHIEF is a structure of type PERSON:
READ *, FIRECHIEF |
The preceding statement is the same as the following:
READ *, FIRECHIEF%AGE, FIRECHIEF%NAME |
A pointer can be an I/O list item but it must be associated with a target at the time the data transfer statement is executed. For an input item, the data in the file is transferred to the associated target. For an output item, the target associated with the pointer must be defined, and the value of the target is transferred to the file.
On UNICOS and UNICOS/mk systems, the following types of items cannot be used in an I/O list: a structure with an ultimate component that is a pointer, auxiliary variables, or auxiliary arrays.
| Note: The Fortran standard does not specify auxiliary variables or auxiliary arrays. |
A constant or an expression with operators, parentheses, or function references cannot appear as an input list item, but can appear as an output list item. A function reference in an output list must not cause execution of another I/O statement on this same unit.
| Note: The Fortran standard does not allow the execution of another I/O statement on any unit through a function reference in an I/O list. For more information on restrictions, see “Restrictions on I/O Specifiers, List Items, and Statements”. |
An input list item, or an entity associated with it, must not contain any portion of an established format specification.
On output, every entity whose value is to be written must be defined.
For formatted input and output, the file consists of characters. These characters are converted into representations suitable for storing in the computer memory during input and converted from an internal representation to characters on output. When a file is accessed sequentially, records are processed in the order in which they appear in the file.
The explicitly formatted, advancing, sequential access data transfer statements have the following formats:
|
The I/O unit is a scalar integer expression with a nonnegative value, an asterisk (*), or a character literal constant (external name). All three I/O unit forms indicate that the unit is a formatted sequential access external unit.
| Note: The Fortran standard does not specify the use of a character literal constant (external name) as an I/O unit. |
If an ADVANCE= specifier is present, the format must not be an asterisk (*).
When an advancing I/O statement is executed, reading or writing of data begins with the next character in the file. If a previous I/O statement was a nonadvancing statement, the next character transferred may be in the middle of a record, even if the statement being executed is an advancing statement. The essential difference between advancing and nonadvancing sequential data transfer is that an advancing I/O statement always leaves the file positioned at the end of the record.
During the data transfer, data is transferred with editing between the file and the entities specified by the I/O list. Format control is initiated and editing is performed as described in Chapter 2, “Input and Output (I/O) Editing”. The current record and possibly additional records are read or written.
For the data transfer, values can be transmitted to or from objects of intrinsic or derived types. In the latter case, the transmission is in the form of values of intrinsic types to or from the components of intrinsic types, which ultimately comprise these structured objects.
For input data transfer, the file must be positioned so that the record read is a formatted record or an end-of-file record.
For input data transfer, the input record is logically padded with blanks to satisfy an input list and format specification that requires more characters than the record contains, unless the PAD= specifier is specified as NO in the OPEN statement. If the PAD= specifier is NO, the input list and format specification must not require more characters from the record than the record contains.
For output data transfer, the output list and format specification must not specify more characters for a record than the record size; recall that the record size for an external file is specified by a RECL= specifier in the OPEN statement.
If the file is connected for formatted I/O, unformatted data transfer is prohibited.
Execution of an advancing sequential access data transfer statement terminates when one of the following occurs:
Format processing encounters a data or colon edit descriptor, and there are no remaining elements in the input item list or output item list.
On input, an end-of-file condition is encountered.
An error condition is encountered.
Example of formatted READ statements are as follows:
! Assume that FMT_5 is a character string
! whose value is a valid format specification.
READ (5, 100, ERR=99, END=200) &
A, B, (C(I), I = 1, 40)
READ (9, IOSTAT=IEND, FMT=FMT_5) X, Y
READ (FMT="(5E20.0)", UNIT=5, &
ADVANCE="YES") (Y(I), I = 1, KK)
READ 100, X, Y |
Examples of WRITE statements are as follows:
! Assume FMT_103 is a character string with a ! valid format specification. WRITE (9, FMT_103, IOSTAT=IS, ERR=99) A, B, C, S WRITE (FMT=105, ERR=9, UNIT=7) X WRITE (*, "(F10.5)") X PRINT "(A, E14.6)", " Y = ", Y |
For unformatted sequential input and output, the file consists of values stored using an internal binary representation. This means that little or no conversion is required during input and output.
Unformatted sequential access data transfer statements are the READ and WRITE statements with no format specifier or namelist group name specifier. The formats are as follows:
|
Data is transferred without editing between the current record and the entities specified by the I/O list. Exactly one record is read or written.
Objects of intrinsic or derived types can be transferred through an unformatted data transfer statement.
For input data transfer, the file must be positioned so that the record read is an unformatted record or an end-of-file record.
For input data transfer, the number of values required by the input list must be less than or equal to the number of values in the record. Each value in the record must be of the same type as the corresponding entity in the input list, except that one complex value may correspond to two real list entities or two real values may correspond to one complex list entity. The type parameters of the corresponding entities must be the same; if two real values correspond to one complex entity or one complex value corresponds to two real entities, all three must have the same kind type parameter values. If an entity in the input list is of type character, the character entity must have the same length as the character value.
On output, if the file is connected for unformatted sequential access data transfer, the record is created with a length sufficient to hold the values from the output list. This length must be one of the set of allowed record lengths for the file and must not exceed the value specified in the RECL= specifier, if any, of the OPEN statement that established the connection.
Execution of an unformatted sequential access data transfer statement terminates when one of the following occurs:
The input item list or output item list is exhausted.
On input, an end-of-file condition is encountered.
An error condition is encountered.
If the file is connected for unformatted I/O, formatted data transfer is prohibited.
The following are examples of unformatted sequential access READ statements :
READ (5, ERR=99, END=100) A, B, (C(I), I = 1, 40) READ (IOSTAT=IEND, UNIT=9) X, Y READ (5) Y |
The following are examples of unformatted sequential access WRITE statements:
WRITE (9, IOSTAT=IS, ERR=99) A, B, C, S WRITE (ERR=99, UNIT=7) X WRITE (9) X |
If the access is sequential, the file is positioned at the beginning of the next record prior to data transfer and positioned at the end of the record when the I/O is finished, because nonadvancing unformatted I/O is not permitted.
Nonadvancing formatted sequential I/O provides the capability of reading or writing part of a record. It leaves the file positioned after the last character read or written, rather than skipping to the end of the record. Processing of nonadvancing input continues within a current record, until an end-of-record condition occurs. Nonadvancing input statements can read varying-length records and determine their lengths. Nonadvancing I/O is sometimes called partial record or stream I/O. It may be used only with explicitly formatted, external files connected for sequential access.
The formats for the nonadvancing I/O statements are as follows:
|
The I/O unit is a scalar integer expression with a nonnegative value, an asterisk (*), or a character literal constant (external name). The I/O unit forms indicate that the unit is a formatted sequential access external unit.
The format must not be an asterisk (*).
During the data transfer, data is transferred with editing between the file and the entities specified by the I/O list. Format control is initiated and editing is performed as described in Chapter 2, “Input and Output (I/O) Editing”. The current record and possibly additional records are read or written.
For the data transfer, values can be transmitted to or from objects of intrinsic or derived types. In the latter case, the transmission is in the form of values of intrinsic types to or from the components of intrinsic types, which ultimately comprise these structured objects.
For input data transfer, the file must be positioned at the beginning of, end of, or within a formatted record or at the beginning of an end-of-file record.
For input data transfer, the input record is logically padded with blanks to satisfy an input list and format specification that requires more characters than the record contains, unless the PAD= specifier is specified as NO in the OPEN statement. If the PAD= specifier is NO, the input list and format specification must not require more characters from the record than the record contains, unless either the EOR= or IOSTAT= specifier is present. In the exceptional cases during nonadvancing input, the actions and execution sequence are described in “Error and Other Conditions in I/O Statements”.
For output data transfer, the output list and format specification must not specify more characters for a record than the record size; recall that the record size for an external file may be specified by a RECL= specifier in the OPEN statement.
The variable in the SIZE= specifier is assigned the number of characters read on input. Blanks inserted as padding characters when the PAD= specifier is YES are not counted.
The program branches to the label given by the EOR= specifier, if an end-of-record condition is encountered during input. The label must be the label of a branch target statement in the same scoping unit as the data transfer statement.
Execution of a nonadvancing, formatted, sequential access data transfer statement terminates when one of the following occurs:
Format processing encounters a data edit descriptor or colon edit descriptor, and there are no remaining elements in the input item list or output item list.
On input, an end-of-file or end-of-record condition is encountered.
An error condition is encountered.
Unformatted data transfer is prohibited.
In the following statements, assume that N has the value 7:
WRITE (*, '(A)', ADVANCE="NO") "The answer is " PRINT '(I1)', N |
The preceding statements produce the following single output record:
The answer is 7 |
In the following statements, assume that SSN is a rank-one array of size 9 with values (1, 2, 3, 0, 0, 9, 8, 8, 6):
DO I = 1, 3
WRITE (*, '(I1)', ADVANCE="NO") SSN(I)
ENDDO
WRITE (*, '("-")', ADVANCE="NO")
DO I = 4, 5
WRITE (*, '(I1)', ADVANCE="NO") SSN(I)
ENDDO
WRITE (*, '(A1)', ADVANCE="NO") '-'
DO I = 6, 9
WRITE (*, '(I1)', ADVANCE="NO") SSN(I)
ENDDO |
The preceding statements produce the following record:
123-00-9886 |
In direct access data transfer, the records are selected by record number. The record number is a scalar integer expression whose value represents the record number to be read or written. The records can be written in any order, but all records must be of the length specified by the RECL= specifier in an OPEN statement.
If a file is connected using the direct access method, then nonadvancing, list-directed, and namelist I/O are prohibited. Also, an internal file must not be accessed using the direct access method.
It is not possible to delete a record using direct access. However, records may be rewritten so that a record can be erased by writing blanks into it.
For formatted input and output, the file consists of characters. These characters are converted into internal representation during input and are converted from an internal representation to characters on output.
Formatted direct access data transfer statements are READ and WRITE statements with a REC= specifier and a format specifier. The formats for formatted direct access data transfer statements are as follows:
|
The I/O unit is a scalar integer expression with a nonnegative value, an asterisk (*), or a character literal constant (external name). The I/O unit forms indicate that the unit is a formatted sequential access external unit.
The format must not be an asterisk (*).
Note that the above forms are intentionally structured so that the unit cannot be an internal file, and the END=, ADVANCE=, and namelist specifiers cannot appear.
On input, an attempt to read a record of a file connected for direct access that has not previously been written causes all entities specified by the input list to become undefined.
During the data transfer, data is transferred with editing between the file and the entities specified by the I/O list. Format control is initiated and editing is performed as described in Chapter 2, “Input and Output (I/O) Editing”. The current record and possibly additional records are read or written.
For the data transfer, values can be transmitted to or from objects of intrinsic or derived types. In the latter case, the transmission is in the form of values of intrinsic types to or from the components of intrinsic types, which ultimately comprise these structured objects.
For input data transfer, the file must be positioned so that the record read is a formatted record.
For input data transfer, the input record is logically padded with blanks to satisfy an input list and format specification that requires more characters than the record contains, unless the PAD= specifier was specified as NO in the OPEN statement. If the PAD= specifier is NO, the input list and format specification must not require more characters from the record than the record contains.
For output data transfer, the output list and format specification must not specify more characters for a record than the record size; recall that the record size for an external file is specified by a RECL= specifier in the OPEN statement.
If the format specification specifies another record (say, by the use of the slash edit descriptor), the record number is increased by one as each succeeding record is read or written by that I/O statement.
For output data transfer, if the number of characters specified by the output list and format do not fill a record, blank characters are added to fill the record.
Execution of a formatted direct access data transfer statement terminates when one of the following events occurs:
Format processing encounters a data edit descriptor or colon edit descriptor, and there are no remaining elements in the input item list or output item list.
An error condition is encountered.
If the file is connected for formatted I/O, unformatted data transfer is prohibited.
Examples of formatted direct access I/O statements are as follows. In these examples, assume that FMT_X is a character entity:
READ (7, FMT_X, REC=32, ERR=99) A
READ (IOSTAT=IO_ERR, REC=34, &
FMT=185, UNIT=10, ERR=99) A, B, D
WRITE (8, "(2F15.5)", REC = N + 2) X, Y |
For unformatted input and output, the file consists of values stored using a representation that is close to or the same as that used in program memory. This means that little or no conversion is required during input and output.
Unformatted direct access data transfer statements are READ and WRITE statements with a REC= specifier and no format specifier. The formats for unformatted direct access data transfer statements are as follows:
|
The I/O unit is a scalar integer expression with a nonnegative value, an asterisk (*), or a character literal constant (external name). The I/O unit forms indicate that the unit is a formatted sequential access external unit.
Note that the preceding forms are intentionally structured so that the unit cannot be an internal file, and the FMT=, END=, ADVANCE=, and namelist specifiers cannot appear.
On input, an attempt to read a record of a file connected for direct access that has not previously been written causes all entities specified by the input list to become undefined.
The number of items in the input list must be less than or equal to the number of values in the input record.
Data is transferred without editing between the current record and the entities specified by the I/O list. Exactly one record is read or written.
Objects of intrinsic or derived types may be transferred.
For input data transfer, the file must be positioned so that the record read is an unformatted record.
For input data transfer, the number of values required by the input list must be less than or equal to the number of values in the record. Each value in the record must be of the same type as the corresponding entity in the input list, except that one complex value may correspond to two real list entities or two real values may correspond to one complex list entity. The type parameters of the corresponding entities must be the same; if two real values correspond to one complex entity or one complex value corresponds to two real entities, all three must have the same kind type parameter values. If an entity in the input list is of type character, the character entity must have the same length as the character value.
The output list must not specify more values than can fit into the record. If the file is connected for direct access and the values specified by the output list do not fill the record, the remainder of the record is undefined.
Execution of an unformatted direct access data transfer statement terminates when one of the following events occurs:
The input item list or output item list is exhausted.
An error condition is encountered.
If the file is connected for unformatted direct access I/O, formatted data transfer is prohibited.
The following are examples of unformatted direct access I/O statements:
READ (7, REC=32, ERR=99) A READ (IOSTAT=MIS, REC=34, UNIT=10, ERR=99) A, B, D WRITE (8, REC = N + 2) X, Y |
List-directed formatting can occur only with files connected for sequential access; however, the file can be an internal file. The I/O data transfer must be advancing. The records read and written are formatted.
List-directed data transfer statements are any data transfer statement for which the format specifier is an asterisk (*). The formats for the list-directed data transfer statements are as follows:
|
Note that the preceding forms are intentionally structured so that the ADVANCE= and namelist specifiers cannot appear.
During the data transfer, data is transferred with editing between the file and the entities specified by the I/O list. The rules for formatting the data transferred are discussed in “List-directed Formatting” in Chapter 2. The current record and, possibly, additional records are read or written.
For the data transfer, values can be transmitted to or from objects of intrinsic or derived types. In the latter case, the transmission is in the form of values of intrinsic types to or from the components of intrinsic types, which ultimately comprise these structured objects.
For input data transfer, the file must be positioned so that the record read is a formatted record or an end-of-file record.
For output data transfer, one or more records will be written. Additional records are written if the output list specifies more characters for a record than the record size.
If the file is connected for list-directed data transfer, unformatted data transfer is prohibited.
Execution of a list-directed data transfer statement terminates when one of the following conditions occurs:
The input item list or the output item list is exhausted.
On input, an end-of-file is encountered, or a slash (/) is encountered as a value separator.
An error condition is encountered.
The following are examples of list-directed input and output statements:
READ (5, *, ERR=99, END=100) A, B, (C(I), I = 1, 40) READ (FMT=*, UNIT=5) (Y(I), I = 1, KK) READ *, X, Y WRITE (*, *) X PRINT *, " Y = ", Y |
Namelist I/O uses a group name for a list of variables that are transferred. Before the group name can be used in the transfer, the list of variables must be declared in a NAMELIST statement, which is a specification statement. Using the namelist group name eliminates the need to specify the list of variables in the sequence for a namelist data transfer. The formatting of the input or output record is not specified in the program; it is determined by the contents of the record itself or the items in the namelist group. Conversion to and from characters is implicit for each variable in the list.
All namelist I/O data transfer statements use a namelist group name, which must be declared. The format of the namelist group name declaration is as follows:
NAMELIST / namelist_group_name / variable_name[, variable_name] ... [[ , ] / namelist_group_name / variable_name[, variable_name] ... ] ... |
Examples:
NAMELIST /GOAL/ G, K, R NAMELIST /XLIST/ A, B /YLIST/ Y, YY, YU |
Namelist input and output data transfer statements are READ and WRITE statements with a namelist specifier. The formats for namelist data transfer statements are as follows:
|
Note that the preceding forms do not contain the REC=, FMT=, and ADVANCE= specifiers. There must be no input or output item list.
The I/O unit must not be an internal file.
During namelist data transfer, data is transferred with editing between the file and the entities specified by the namelist group name. Format control is initiated and editing is performed as described in “Namelist Formatting” in Chapter 2. The current record and possibly additional records are read or written.
For the data transfer, values can be transmitted to or from objects of intrinsic or derived types. In the latter case, the transmission is in the form of values of intrinsic types to or from the components of intrinsic types, which ultimately comprise these structured objects.
For namelist input data transfer, the file must be positioned so that the record read is a formatted record or an end-of-file record.
For namelist output data transfer, one or more records will be written. Additional records are written if the namelist specifies more characters for a record than the record size; recall that the record size for an external file can be specified by a RECL= specifier in the OPEN statement.
If an entity appears more than once within the input record for a namelist input data transfer, the last value is the one that is used.
For namelist input data transfer, all values following a name= part within the input record are transmitted before processing any subsequent entity within the namelist input record.
Execution of a namelist data transfer statement terminates when one of the following events occurs:
On input, an end-of-file is encountered, or a slash (/) is encountered as a value separator.
On input, the end of the namelist input record is reached and a name-value subsequence has been processed for every item in the namelist group object list.
On output, the namelist group object list is exhausted.
An error condition is encountered.
If the file is connected for namelist data transfer, unformatted data transfer is prohibited.
Examples of namelist data transfer statements are as follows:
READ (NML=NAME_LIST_23, IOSTAT=KN, UNIT=5) WRITE (6, NAME_LIST_23, ERR=99) |
Transferring data from an internal representation to characters or from characters back to internal representation can be done between two variables in an executing program. A formatted sequential access input or output statement, including list-directed formatting, is used for the transfer. The format is used to interpret the characters. The internal file and the internal unit are the same character variable.
With this feature, it is possible to read in a string of characters without knowing its exact format, examine the string, and then interpret it according to its contents.
Formatted sequential access data transfer statements on an internal file have the following formats:
|
Examples of data transfer on internal files are:
READ (CHAR_124, 100, IOSTAT=ERR) MARY, X, J, NAME WRITE (FMT=*, UNIT=CHAR_VAR) X |
The unit must be a character variable that is not an array section with a vector subscript.
Each record of an internal file is a scalar character variable.
If the character variable is an array or an array section, each element of the array or section is a scalar character variable and thus a record. The order of the records is array element order. The length, which must be the same for each record, is the length of one array element.
If the character variable is an array or part (component, element, section, or substring) of an array that has the ALLOCATABLE attribute, the variable must be allocated before it is used as an internal file. It must be defined if it is used as an internal file in a READ statement.
If the character variable is a pointer, it must be associated with a target. The target must be defined if it is used as an internal file in a READ statement.
During data transfer, data is transferred with editing between the internal file and the entities specified by the I/O list. Format control is initiated and editing is performed as described in Chapter 2, “Input and Output (I/O) Editing”. The current record and possibly additional records are read or written.
For the data transfer, values can be transmitted to or from objects of intrinsic or derived types. In the latter case, the transmission is in the form of values of intrinsic types to or from the components of intrinsic types, which ultimately comprise these structured objects.
For output data transfer, the output list and format specification must not specify more characters for a record than the record size. Recall that the record size for an internal file is the length of the scalar character variable or an element in a character array that represents the internal file. The format specification must not be part of the internal file or associated with the internal file or part of it.
If the number of characters written is less than the length of the record, the remaining characters are set to blank.
The records in an internal file are defined when the record is written. An I/O list item must not be in the internal file or associated with the internal file. An internal file also can be defined by a character assignment statement, or some other means, or can be used in expressions in other statements. For example, an array element may be given a value with a WRITE statement and then used in an expression on the right-hand side of an assignment statement.
To read a record in an internal file, the character variable comprising the record must be defined.
Before a data transfer occurs, an internal file is positioned at the beginning of the first record (that is, before the first character, if a scalar, and before the first character of the first element, if an array). This record becomes the current record.
Only formatted sequential access, including list-directed formatting, is permitted on internal files. Namelist formatting is prohibited.
On input, an end-of-file condition occurs when there is an attempt to read beyond the last record of the internal file.
During input processing, all nonleading blanks in numeric fields are treated as if they were removed, right justifying all characters in the field (as if a BN edit descriptor were in effect). In addition, records are blank padded when an end of record is encountered before all of the input items are read (as if PAD=YES were in effect).
For list-directed output, character values are not delimited.
File connection, positioning, and inquiry must not be used with internal files.
Execution of a data transfer statement on an internal file terminates when one of the following events occurs:
Format processing encounters a data or colon edit descriptor, and there are no remaining elements in the input item list or output item list.
If list-directed processing is specified, the input item list or the output item list is exhausted; or on input, a slash (/) is encountered as a value separator.
On input, an end-of-file condition is encountered.
An error condition is encountered.
Sometimes output records are sent to a device that interprets the first character of the record as a control character. This is usually the case with line printers. If a formatted record is transferred to such a device, the first character of the record is not printed, but instead is used to control vertical spacing. The remaining characters of the record, if any, are printed on one line beginning at the left margin. This transfer of information is called printing.
The first character of such a record must be of character type and determines vertical spacing as specified in Table 1-3.
Table 1-3. Interpretation of the first character for printing control
Character | Vertical spacing before printing |
|---|---|
Blank | One line (single spacing) |
0 | Two lines (double spacing) |
1 | To first line of next page (begin new page) |
+ | No advance (no spacing - printing on top of previous line) |
If there are no characters in the record, a blank line is printed. If the first character is not a blank, 0, 1, or +, the character is treated as a blank.
The PRINT statement does not imply that printing actually will occur on a printer, and the WRITE statement does not imply that printing will not occur. Whether printing occurs depends on the disposition of the file connected to the unit number.
You can use the asa(1) command to interpret Fortran carriage control characters.
You can use the BUFFER IN and BUFFER OUT statements to transfer data.
| Note: The Fortran standard does not describe the BUFFER IN or BUFFER OUT statements. |
Data can be transferred while allowing the subsequent execution sequence to proceed concurrently. This is called asynchronous I/O. Asynchronous I/O may require the use of nondefault file formats or FFIO layers, as discussed in the Application Programmer's I/O Guide. BUFFER IN and BUFFER OUT operations can proceed concurrently on several units or files.
BUFFER IN is for reading, and BUFFER OUT is for writing. A BUFFER IN or BUFFER OUT operation includes only data from a single array or a single common block.
Either statement initiates a data transfer between a specified file or unit (at the current record) and memory. If the unit or file is completing an operation initiated by any earlier BUFFER IN or BUFFER OUT statement, the current BUFFER IN or BUFFER OUT statement suspends the execution sequence until the earlier operation is complete. When the unit's preceding operation terminates, execution of the BUFFER IN or BUFFER OUT statement completes as if no delay had occurred.
You can use the UNIT(3i) or LENGTH(3i) intrinsic procedures to delay the execution sequence until the BUFFER IN or BUFFER OUT operation is complete. These functions can also return information about the I/O operation at its termination. On UNICOS and UNICOS/mk systems, you can use the SETPOS(3) library routine with BUFFER IN and BUFFER OUT for random positioning.
The general format of the BUFFER IN and BUFFER OUT statements follows:
EXT | buffer_in_stmt | is |
| |
EXT | buffer_out_stmt | is |
| |
EXT | io_unit | is |
| |
|
| or |
| |
EXT | mode | is |
| |
EXT | start_loc | is |
| |
EXT | end_loc | is |
|
In the preceding definition, the variable specified for start_loc and end_loc cannot be of a derived type if you are performing implicit data conversion. The data items between start_loc and end_loc must be of the same type.
The BUFFER IN and BUFFER OUT statements are defined as follows.
|
| io_unit | An identifier that specifies a unit or a file name. The I/O unit is a scalar integer expression with a nonnegative value, an asterisk (*), or a character literal constant (external name). The I/O unit forms indicate that the unit is a formatted sequential access external unit. | |
| mode | Mode identifier. This integer expression controls the record position following the data transfer. The mode identifier is ignored on files that do not contain records; only full record processing is available. | |
| start_loc, end_loc | Symbolic names of the variables, arrays, or array elements that mark the beginning and ending locations of the BUFFER IN or BUFFER OUT operation. These names must be either elements of a single array (or equivalenced to an array) or members of the same common block. If start_loc or end_loc is of type character, then both must be of type character. If start_loc and end_loc are noncharacter, then the item length of each must be equal. For example, if the internal length of the data type of start_loc is 64 bits, the internal length of the data type of end_loc must be 64 bits. To ensure that the size of start_loc and end_loc are the same, use the same data type for both. |
The mode identifier, mode, controls the position of the record at unit io_unit after the data transfer is complete. The values of mode have the following effects:
Specifying mode≥0 causes full record processing. File and record positioning works as with conventional I/O. The record position following such a transfer is always between the current record (the record with which the transfer occurred) and the next record. Specifying BUFFER OUT with mode≥0 ends a series of partial-record transfers.
Specifying mode < 0 causes partial record processing. In BUFFER IN, the record is positioned to transfer its (n +1)th word if the nth word was the last transferred. In BUFFER OUT, the record is left positioned to receive additional words.
The amount of data to be transferred is specified in words without regard to types or formats. However, the data type of end_loc affects the exact ending location of a transfer. If end_loc is of a multiple-word data type, the location of the last word in its multiple-word form of representation marks the ending location of the data transfer.
BUFFER OUT with start_loc = end_loc + 1 and mode≥0 causes a zero-word transfer and concludes the record being created. Except for terminating a partial record, start_loc following end_loc in a storage sequence causes a run-time error.
Example:
PROGRAM XFR
DIMENSION A(1000), B(2,10,100), C(500)
...
BUFFER IN(32,0) (A(1),A(1000))
...
DO 9 J=1,100
B(1,1,J) = B(1,1,J) + B(2,1,J)
9 CONTINUE
BUFFER IN(32,0) (C(1),C(500))
BUFFER OUT(22,0) (A(1),A(1000))
...
END |
The first BUFFER IN statement in this example initiates a transfer of 1000 words from unit 32. If asynchronous I/O is available, processing unrelated to that transfer proceeds. When this is complete, a second BUFFER IN is encountered, which causes a delay in the execution sequence until the last of the 1000 words is received. A transfer of another 500 words is initiated from unit 32 as the execution sequence continues. BUFFER OUT begins a transfer of the first 1000 words to unit 22. In all cases mode = 0, indicating full record processing.
When a data transfer statement is executed, the following steps are taken:
Determine the direction of data transfer. A READ statement indicates that data is to be transferred from a file to program variables. A WRITE or PRINT statement indicates that data is to be transferred from program variables to a file.
Identify the unit. The unit identified by a data transfer I/O statement must be connected to a file when execution of the statement begins. Note that the file can be preconnected.
Establish the format, if one is specified. If specified, the format specifier is given in the data transfer statement and implies list-directed, namelist, or formatted data transfer.
Position the file prior to transferring the data. The position depends on the method of access (sequential or direct) and is described in “File Position Prior to Data Transfer”.
Transfer data between the file and the entities specified by the I/O item list (if any). The list items are processed in the order of the I/O list for all data transfer I/O statements, except namelist input data transfer statements, which are processed in the order of the entities specified within the input records. For namelist output data transfer, the output items are specified by the namelist when a namelist group name is used.
Determine if an error, end-of-record, or end-of-file condition exists. If one of these conditions occurs, the status of the file and the I/O items is as specified in “Error and Other Conditions in I/O Statements”.
Position the file after transferring the data. The file position depends on whether one of the conditions in step 6 above occurred or if the data transfer was advancing or nonadvancing.
Cause the variables specified in the IOSTAT= and SIZE= specifiers, if present, to become defined. See the description of these specifiers in the READ and WRITE data transfer statements in “I/O Item List”.
If ERR=, END=, or EOR= specifiers appear in the statement, transfer to the branch target corresponding to the condition that occurs. If an IOSTAT= specifier appears in the statement and the label specifier corresponding to the condition that occurs does not appear in the statement, the next statement in the execution sequence is executed. Otherwise, the execution of the program terminates. See the descriptions of these label specifiers in “I/O Item List”.
Data is transferred between records in the file and entities in the I/O list or namelist. The list items are processed in the order of the I/O list for all data transfer I/O statements except namelist data transfer statements. The list items for a namelist formatted data transfer input statement are processed in the order of the entities specified within the input records. The list items for a namelist data transfer output statement are processed in the order in which the data objects (variables) are specified in the namelist group object list.
The next item to be processed in the input or output item list is the next effective item, which is used to determine the interaction between the I/O item list and the format specification.
Zero-sized arrays and implied-DO lists with zero iteration counts are ignored in determining the next effective item.
Before beginning the I/O processing of a particular list item, the compiler first evaluates all values needed to determine which entities are specified by the list item. For example, the subscripts of a variable in an I/O list are evaluated before any data is transferred.
The value of an item that appears early in an I/O list can affect the processing of an item that appears later in the list. In the following example, the old value of N identifies the unit, but the new value of N is the subscript of X:
READ(N) N, X(N) |
The file position prior to data transfer depends on the method of access: sequential or direct.
For sequential access on input, if there is a current record, the file position is not changed; this will be the case if the previous data transfer was nonadvancing. Otherwise, the file is positioned at the beginning of the next record and this record becomes the current record. Input must not occur if there is no next record (there must be an end-of-file record at least) or if there is a current record and the last data transfer statement accessing the file performed output.
If the file contains an end-of-file record, the file must not be positioned after the end-of-file record prior to data transfer. If you are using the CF90 compiler, multiple end-of-file records are permitted for some file structures. The MIPSpro 7 Fortran 90 compiler does not allow multiple end-of-file records, but a REWIND or BACKSPACE statement can be used to reposition the file.
| Note: The Fortran standard does not allow files that contain an end-of-file record to be positioned after the end-of-file record prior to data transfer. |
For sequential access on output, if there is a current record, the file position is not changed; this will be the case if the previous data transfer was nonadvancing. Otherwise, a new record is created as the next record of the file; this new record becomes the last and current record of the file and the file is positioned at the beginning of this record.
For direct access, the file is positioned at the beginning of the record specified. This record becomes the current record.
If an error condition exists, the file position is indeterminate. If no error condition exists, but an end-of-file condition exists as a result of reading an end-of-file record, the file is positioned after the end-of-file record.
If no error condition or end-of-file condition exists, but an end-of-record condition exists, the file is positioned after the record just read. If no error condition, end-of-file condition, or end-of-record condition exists, and the data transfer was a nonadvancing input or output statement, the file position is not changed. In all other cases, the file is positioned after the record just read or written, and that record becomes the preceding record.
In step 6 of the execution model in “Execution Model for Data Transfer Statements”, the data transfer statements admit the occurrence of error and other conditions during the execution of the statement. The OPEN, CLOSE, INQUIRE, and file positioning statements also admit the occurrence of error conditions.
Whenever an error condition is detected, the variable of the IOSTAT= specifier is assigned a positive value, if it is present. Also, if the ERR= specifier is present, the program transfers to the branch target specified by the ERR= specifier upon completion of the I/O statement.
In addition, two other conditions might be detected: end-of-file and end-of-record. For each of these conditions, branches can be provided using the END= and EOR= specifiers in a READ statement to which the program branches upon completion of the READ statement. Also, the variable of the IOSTAT= specifier, if present, is set to a unique negative integer value, indicating which condition occurred.
An end-of-file condition occurs when either an end-of-file record is encountered during a sequential READ statement, or an attempt is made to read beyond the end of an internal file. An end-of-file condition can occur at the beginning of the execution of an input statement or during the execution of a formatted READ statement when more than one record is required by the interaction of the format specification and the input item list.
An end-of-record condition occurs when a nonadvancing input statement attempts to transfer data from beyond the end of the record.
Two or more conditions can occur during a single execution of an I/O statement. If one or more of the conditions is an error condition, one of the error conditions takes precedence, in the sense that the IOSTAT= specifier is given a positive value designating the particular error condition and the action taken by the I/O statement is as if only that error condition occurred.
In summary, an error condition can be generated by any of the I/O statements, and an end-of-file or end-of-record condition can be generated by a READ statement. The IOSTAT=, END=, EOR=, and ERR= specifiers allow the program to recover from such conditions rather than terminate execution of the program. In particular, when any one of these conditions occurs, the CF90 and MIPSpro 7 Fortran 90 compilers take the following actions:
If an end-of-record condition occurs and if the connection has been made with the PAD= specifier of YES, the record is padded, as necessary, with blanks to satisfy the input item list and the corresponding data edit descriptor. For the file position, see “File Position after Data Transfer”.
Execution of the I/O statement terminates.
If an error condition occurs, the position of the file becomes indeterminate; if an end-of-file condition occurs, the file is positioned after the end-of-file record; if an end-of-record condition occurs, the file is positioned after the current record.
If the statement also contains an IOSTAT= specifier, the variable specified becomes defined with a nonzero integer value; the value is positive if an error condition occurs and is negative if either an end-of-file or end-of-record condition occurs.
If the statement is a READ statement with a SIZE= specifier and an end-of-record condition occurs, then the variable specified by the SIZE= specifier becomes defined with an integer value equal to the number of characters read from the input record; blank padding characters inserted because the PAD= specifier is YES are not counted. For the file position, see “File Position after Data Transfer”.
All implied-DO variables in the I/O statement become undefined; if an error or end-of-file condition occurs during execution of a READ statement, all list items become undefined; if an error condition occurs during the execution of an INQUIRE statement, all specifier variables except the IOSTAT= variable become undefined.
If an END= specifier is present and an end-of-file condition occurs, execution continues with the statement specified by the label in the END= specifier. If an EOR= specifier is present and an end-of-record condition occurs, execution continues with the statement specified by the label in the EOR= specifier. If an ERR= specifier is present and an error condition occurs, execution continues with the statement specified by the label in the ERR= specifier.
If none of the preceding cases applies, but the I/O statement contains an IOSTAT= specifier, the normal execution sequence is resumed. If there is no IOSTAT=, END=, EOR=, or ERR= specifier, and an error or other condition occurs, the program terminates execution.
The following program segment illustrates how to handle end-of-file and error conditions:
READ (FMT = "(E8.3)", UNIT=3, IOSTAT=IOSS) X IF (IOSS < 0) THEN ! PERFORM END-OF-FILE PROCESSING ON THE ! FILE CONNECTED TO UNIT 3. CALL END_PROCESSING ELSE IF (IOSS > 0) THEN ! PERFORM ERROR PROCESSING CALL ERROR_PROCESSING END IF |
The procedure END_PROCESSING is used to handle the case where an end-of-file condition occurs and the procedure ERROR_PROCESSING is used to handle all other error conditions, because an end-of-record condition cannot occur.
The OPEN statement establishes a connection between a unit and an external file and determines the connection properties. In order to perform data transfers (reading and writing), the file must be connected with an OPEN statement or be preconnected. It can also be used to change certain properties of the connection between the file and the unit, to create a file that is preconnected, or create a file and connect it.
The OPEN statement can appear anywhere in a program, and once executed, the connection of the unit to the file is valid in the main program or any subprogram for the remainder of that execution, unless a CLOSE statement affecting the connection is executed.
If a file is already connected to one unit, it must not be connected to a different unit.
The OPEN statement connects an external file to a unit. If the file does not exist, it is created. If a unit is already connected to a file that exists, an OPEN statement referring to that unit may be executed. If the FILE= specifier is not included, the unit remains connected to the file. If the FILE= specifier names the same file, the OPEN statement may change the connection properties. If it specifies a different file by name, the effect is as if a CLOSE statement without a STATUS= specifier is executed on that unit and the OPEN statement is then executed. For information on default values for the STATUS= specifier, see “STATUS= Specifier”.
If a unit is preconnected to a file that does not exist, the OPEN statement creates the file and establishes properties of the connection.
Execution of an OPEN statement can change the properties of a connection that is already established. The properties that can be changed are those indicated by BLANK=, DELIM=, PAD=, ERR=, and IOSTAT= specifiers. If new values for DELIM=, PAD=, and BLANK= specifiers are specified, these will be used in subsequent data transfer statements; otherwise, the old ones will be used. However, the values in ERR= and IOSTAT= specifiers, if present, apply only to the OPEN statement being executed; after that, the values of these specifiers have no effect. If no ERR= or IOSTAT= specifier appears in the new OPEN statement, error conditions will terminate the execution of the program.
The OPEN statement and the connection specifier are defined as follows:
| open_stmt | is |
| |
| connect_spec | is |
| |
|
| or |
| |
|
| or |
| |
|
| or |
| |
|
| or |
| |
|
| or |
| |
|
| or |
| |
|
| or |
| |
|
| or |
| |
|
| or |
| |
|
| or |
| |
|
| or |
| |
|
| or |
| |
| file_name_expr | is |
|
A unit specifier is required. If the keyword UNIT is omitted, the scalar integer expression must be the first item in the list. Note that the form * for the unit specifier is not allowed in the OPEN statement. However, in cases where the default external unit specified by an asterisk also corresponds to a nonnegative unit specifier (such as unit numbers 5 and 6 on many systems), inquiries about these default units and connection properties are possible.
A specifier must not appear more than once in an OPEN statement.
The character expression established for many of the specifiers must contain one of the permitted values from the list of alternative values for each specifier described in the following section. For example, OLD, NEW, REPLACE, UNKNOWN, or SCRATCH are permitted for the STATUS= specifier; any other combination of letters is not permitted. Trailing blanks in any specifier are ignored. The value specified can contain both uppercase and lowercase letters.
If the last data transfer to a unit connected for sequential access to a particular file is an output data transfer statement, an OPEN statement for that unit connecting it to a different file writes an end-of-file record to the original file.
The OPEN statement specifies the connection properties between the file and the unit, using keyword specifiers, which are described in this section. Table 1-4 indicates the possible values for the specifiers in an OPEN statement and their default values when the specifier is omitted.
Table 1-4. Values for keyword specifier variables in an OPEN statement
Specifier | Possible values | Default value |
|---|---|---|
ACCESS= | DIRECT, SEQUENTIAL | SEQUENTIAL |
ACTION= | READ, WRITE, READWRITE | File dependent |
BLANK= | NULL, ZERO | NULL |
DELIM= | APOSTROPHE, QUOTE, NONE | NONE |
ERR= | Label | No default |
FILE= | Character expression | fort. is prepended to the unit number |
FORM= | FORMATTED | FORMATTED for sequential access |
| UNFORMATTED | UNFORMATTED for direct access |
| SYSTEM (EXTENSION) |
|
IOSTAT= | Scalar default integer variable | No default |
PAD= | YES, NO | YES |
POSITION= | ASIS, REWIND, APPEND | ASIS |
RECL= | Positive scalar integer expression | File dependent |
STATUS= | OLD, NEW, UNKNOWN, REPLACE, SCRATCH | UNKNOWN |
UNIT= | Scalar integer expression | No default |
| Note: The Fortran standard does not describe the FORM=SYSTEM specifier. |
The UNIT= specifier has the following format:
[ UNIT= ]scalar_int_expr |
The value of scalar_int_expr must be nonnegative.
A unit specifier with an external unit is required. If the keyword UNIT is omitted, the unit specifier must be the first item in the list.
A unit number identifies one and only one external unit in all program units in a Fortran program.
The ACCESS= specifier has the following format:
ACCESS= scalar_char_expr |
For scalar_char_expr, specify either DIRECT or SEQUENTIAL. DIRECT specifies the direct access method for data transfer. SEQUENTIAL specifies the sequential access method for data transfer; SEQUENTIAL is the default.
If the file exists, the method specified must be an allowed access method for the file.
If the file is new, the allowed access methods given for the file must include the one indicated.
If the ACCESS= specifier has the value DIRECT, a RECL= specifier must be present.
The ACTION= specifier has the following format:
ACTION= scalar_char_expr |
Specify one of the following for scalar_char_expr:
| Value | Function | |
| READ | Indicates that WRITE, PRINT, and ENDFILE statements are prohibited | |
| WRITE | Indicates that READ statements are prohibited | |
| READWRITE | Indicates that any I/O statement is permitted |
The default value depends on the file structure.
If READWRITE is an allowed ACTION= specifier, READ and WRITE must also be allowed ACTION= specifiers.
For an existing file, the specified action must be an allowed action for the file.
For a new file, the value of the ACTION= specifier must be one of the allowed actions for the file.
The BLANK= specifier has the following format:
BLANK= scalar_char_expr |
For scalar_char_expr, specify either NULL or ZERO. NULL specifies that the compiler should ignore all blanks in numeric fields; this is the default. ZERO specifies that the I/O library should interpret all blanks except leading blanks as zeros.
A field of all blanks evaluates to zero regardless of the argument specified to BLANK=.
The BLANK= specifier may be specified for files connected only for formatted I/O.
The DELIM= specifier has the following format:
DELIM= scalar_char_expr |
Specify one of the following for scalar_char_variable:
| Value | Function | |
| APOSTROPHE | Use the apostrophe as the delimiting character for character constants written by a list-directed or namelist-formatted data transfer statement. | |
| QUOTE | Use the quotation mark as the delimiting character for character constants written by a list-directed or namelist-formatted data transfer statement. | |
| NONE | Use no delimiter to delimit character constants written by a list-directed or namelist-formatted data transfer statement. This is the default. |
If the DELIM= specifier is APOSTROPHE, any occurrence of an apostrophe within a character constant will be doubled; if the DELIM= specifier is QUOTE, any occurrence of a quote within a character constant will be doubled.
The specifier is permitted only for a file connected for formatted I/O; it is ignored for formatted input.
The ERR= specifier has the following format:
ERR= label |
The program branches to the label in the ERR= specifier if an error occurs in the OPEN statement. The label must be the label of a branch target statement in the same scoping unit as the OPEN statement.
If an error condition occurs, the position of the file becomes indeterminate.
If an IOSTAT= specifier is present and an error condition occurs, the IOSTAT variable specified becomes defined with a positive value.
The FILE= specifier has the following format:
FILE= scalar_char_expr |
For scalar_char_expr, specify the name of the file to be connected. This is called the file name expression.
Trailing blanks in the file name are ignored.
The rules regarding file name lengths and path name lengths depend upon your platform, as follows:
UNICOS and UNICOS/mk systems allow 256 characters for a file name. This file name can include a directory name and 1023 characters for the full path name.
IRIX systems allow 256 characters for a file name. The full path name is limited to 1023 characters.
Example:
FILENM = 'dir/fnam' FNUM = '/subfnum' OPEN (UNIT = 8, FILE = 'beauty') OPEN (UNIT = 9, FILE = FILENM) OPEN (UNIT = 10, FILE = FNAME//FNUM) |
The FILE= specifier must appear if the STATUS= specifier is OLD, NEW, or REPLACE; the FILE= specifier must not appear if the STATUS= specifier is SCRATCH.
If the FILE= specifier is omitted and the unit is not already connected to a file, the STATUS= specifier must have the value SCRATCH and the unit becomes connected to a file with the unit number appended to the fort. string.
The FORM= specifier has the following format:
FORM= scalar_char_expr |
For scalar_char_expr, specify either FORMATTED, UNFORMATTED, or SYSTEM. FORMATTED indicates that all records are formatted. UNFORMATTED indicates that all records are unformatted.
The default value is UNFORMATTED if the file is connected for direct access and the FORM= specifier is absent.
The default value is FORMATTED if the file is connected for sequential access and the FORM= specifier is absent.
A file opened with SYSTEM is unformatted and has no record marks.
If the file is new, the allowed forms given for the file must include the one indicated.
If the file exists, the form specified by the FORM= specifier must be one of the allowed forms for the file.
| Note: The Fortran standard does not define the SYSTEM argument to the FORM= specifier. |
The IOSTAT= specifier has the following format:
IOSTAT= scalar_default_int_variable |
The I/O library will return an integer value in scalar_default_int_variable. If scalar_default_int_variable > 0, an error condition occurred. If scalar_default_int_variable = 0, no error condition occurred. Note that the value cannot be negative.
The IOSTAT= specifier applies to the execution of the OPEN statement itself.
The PAD= specifier has the following format:
PAD= scalar_char_expr |
For scalar_char_expr, specify either YES or NO. YES indicates that the I/O library should use blank padding when the input item list and format specification require more data than the record contains; this is the default. NO indicates that the I/O library requires that the input record contain the data indicated by the input list and format specification.
The PAD= specifier is permitted only for a file connected for formatted I/O; it is ignored for formatted output.
If this specifier has the value YES and an end-of-record condition occurs, the data transfer behaves as if the record were padded with sufficient blanks to satisfy the input item and the corresponding data edit descriptor.
The POSITION= specifier has the following format:
POSITION= scalar_char_expr |
Specify one of the following for scalar_char_expr:
| Value | Function | |
| ASIS | Indicates that the file position is to remain unchanged for a connected file and is unspecified for a file that is not connected. ASIS permits an OPEN statement to change other connection properties of a file that is already connected without changing its position. This is the default. | |
| REWIND | Indicates that the file is to be positioned at its initial point. | |
| APPEND | Indicates that the file is to be positioned at the terminal point or just before an end-of-file record, if there is one. |
The file must be connected for sequential access.
If the file is new, it is positioned at its initial point, regardless of the value of the POSITION= specifier.
The RECL= specifier has the following format:
RECL= scalar_int_expr |
For scalar_int_expr, specify a positive value that specifies either the length of each direct access record or the maximum length of a sequential access record.
If the RECL= specifier is absent for a file connected for sequential access, the default value is 1024 characters for a write operation. For sequential access read operations, the RECL value is automatically increased as the system determines necessary.
The RECL= specifier must be present for a file connected for direct access.
If the file is connected for formatted I/O, the length is the number of characters.
If the file is connected for unformatted I/O, the length is measured in 8-bit bytes.
If the file exists, the length of the record specified must be an allowed record length.
If the file does not exist, the file is created with the specified length as an allowed length.
The STATUS= specifier has the following format:
STATUS= scalar_char_expr |
Specify one of the following for scalar_char_expr:
| Value | Function | |
| OLD | Requires that the file exist. | |
| NEW | Requires that the file not exist. | |
| UNKNOWN | Indicates that the file has an unknown status. This is the default. | |
| REPLACE | Indicates that if the file does not exist, the file is created and given a status of OLD; if the file does exist, the file is deleted, a new file is created with the same name, and the file is given a status of OLD. | |
| SCRATCH | Indicates that an unnamed file is to be created and connected to the specified unit; it is to exist either until the program terminates or a CLOSE statement is executed on that unit. |
Scratch files must be unnamed; that is, the STATUS= specifier must not be SCRATCH when a FILE= specifier is present. The term scratch file refers to this temporary file.
Note that if the STATUS= specifier is REPLACE, the specifier in this statement is not changed to OLD; only the file status is considered to be OLD when the file is used in subsequently executed I/O statements, such as a CLOSE statement.
Executing a CLOSE statement terminates the connection between a file and a unit. Any connections not closed explicitly by a CLOSE statement are closed by the operating system when the program terminates, unless an error condition has terminated the program.
The CLOSE statement is defined as follows:
| close_stmt | is |
| |
| close_spec | or |
| |
|
| is |
| |
|
| or |
| |
|
| or |
|
A specifier must not appear more than once in a CLOSE statement.
A CLOSE statement may appear in any program unit in an executing program.
A CLOSE statement may refer to a unit that is not connected or does not exist, but it has no effect.
If the last data transfer to a file connected for sequential access is an output data transfer statement, a CLOSE statement for a unit connected to this file writes an end-of-file record to the file.
After a unit has been disconnected by a CLOSE statement, it can be connected again to the same or a different file. Similarly, after a file has been disconnected by a CLOSE statement, it can also be connected to the same or a different unit, provided the file still exists. The following examples show these situations:
CLOSE (ERR=99, UNIT=9) CLOSE (8, IOSTAT=IR, STATUS="KEEP") |
The sections that follow describe the components of the close_spec_list in more detail.
The UNIT= specifier has the following format:
[ UNIT= ]scalar_int_expr |
The value of scalar_int_expr must be nonnegative.
A unit specifier is required. If the keyword UNIT is omitted, scalar_int_expr must be the first item in the list.
A unit number identifies one and only one external unit in all program units in a Fortran program.
The ERR= specifier has the following format:
ERR= label |
If an error condition occurs, the position of the file becomes indeterminate.
If an IOSTAT= specifier is present and an error condition occurs, the IOSTAT variable specified becomes defined with a positive value.
The program branches to the label in the ERR= specifier if an error occurs in the CLOSE statement. The label must be the label of a branch target statement in the same scoping unit as the CLOSE statement.
The format of the IOSTAT= specifier is as follows:
IOSTAT= scalar_default_int_variable |
The I/O library returns an integer value in scalar_default_int_variable. If scalar_default_int_variable > 0, an error condition occurred. If scalar_default_int_variable = 0, no error condition occurred. Note that the value cannot be negative.
The IOSTAT= specifier applies to the execution of the CLOSE statement itself.
The format of the STATUS= specifier is as follows:
STATUS= scalar_char_expr |
For scalar_char_expr, specify either KEEP or DELETE. KEEP indicates that the file is to continue to exist after closing the file. DELETE indicates that the file will not exist after closing the file.
If the unit has been opened with a STATUS= specifier of SCRATCH, the default is DELETE. If the unit has been opened with any other value of the STATUS= specifier, the default is KEEP.
KEEP must not be specified for a file whose file status is SCRATCH.
If KEEP is specified for a file that does not exist, the file does not exist after the CLOSE statement is executed.
An inquiry can be made about a file's existence, connection, access method, or other properties. For each property inquired about, a scalar variable of default kind must be supplied; that variable is given a value that answers the inquiry. The variable can be tested and optional execution paths can be selected based on the answer returned. The inquiry specifiers are determined by keywords in the INQUIRE statement. The only exception is the unit specifier, which, if no keyword is specified, must be the first specifier. A file inquiry can be made by unit number, file name, or an output item list. When inquiring by an output item list, an output item list that might be used in an unformatted direct access output statement must be present.
There are three kinds of INQUIRE statements: inquiry by unit, by name, and by an output item list. The first two kinds use the inquire_spec_list form of the INQUIRE statement. The third kind uses the IOLENGTH form. Inquiry by unit uses a unit specifier. Inquiry by file uses a file specifier with the keyword FILE=. These statements are defined as follows:
| inquire_stmt | is |
| |
|
| or |
| |
| inquire_spec | is |
| |
|
| or |
| |
|
| or |
| |
|
| or |
| |
|
| or |
| |
|
| or |
| |
|
| or |
| |
|
| or |
| |
|
| or |
| |
|
| or |
| |
|
| or |
| |
|
| or |
| |
|
| or |
| |
|
| or |
| |
|
| or |
| |
|
| or |
| |
|
| or |
| |
|
| or |
| |
|
| or |
| |
|
| or |
| |
|
| or |
| |
|
| or |
| |
|
| or |
| |
|
| or |
| |
|
| or |
|
An INQUIRE statement with an inquire_spec_list must have a unit specifier or a FILE= specifier, but not both. If the keyword UNIT is omitted, a scalar integer expression must be the first item in the list and must have a nonnegative value.
No specifier can appear more than once in a given inquiry specifier list.
For an inquiry by an output item list, the output item list must be a valid output list for an unformatted, direct-access, output statement. The length value returned in the scalar default integer variable must be a value that is acceptable when used as the value of the RECL= specifier in an OPEN statement. This value can be used in a RECL= specifier to connect a file whose records will hold the data indicated by the output list of the INQUIRE statement.
An INQUIRE statement can be executed before or after a file is connected to a unit. The specifier values returned by the INQUIRE statement are those current at the time at which the INQUIRE statement is executed.
A variable appearing in a specifier or any entity associated with it must not appear in another specifier in the same INQUIRE statement if that variable can become defined or undefined as a result of executing the INQUIRE statement. That is, do not try to assign two inquiry results to the same variable.
Except for the NAME= specifier, character values are returned in uppercase.
If an error condition occurs during the execution of an INQUIRE statement, all the inquiry specifier variables become undefined except the IOSTAT= specifier. The following are examples of INQUIRE statements:
INQUIRE (9, EXIST = EX) INQUIRE (FILE = "T123", OPENED = OP, ACCESS = AC) INQUIRE (IOLENGTH = IOLEN) X, Y, CAT |
This section describes the format and effect of the inquiry specifiers that may appear in the inquiry by unit and file forms of the INQUIRE statement.
The format of the UNIT= specifier is as follows:
[ UNIT= ]scalar_int_expr |
The scalar_int_expr indicates an external unit. The value of scalar_int_expr must be nonnegative.
To inquire by unit, a unit specifier must be present, and a file specifier cannot be present. If the keyword UNIT is omitted, scalar_int_expr must be the first item in the list.
A unit number identifies one and only one external unit in all program units in a Fortran program.
The file is the file connected to the unit, if one is connected; otherwise, the file does not exist.
The format of the ACCESS= specifier is as follows:
ACCESS= scalar_char_variable |
One of the following is returned in scalar_char_variable:
| Value | Function | |
| SEQUENTIAL | Indicates that the file is connected for sequential access | |
| DIRECT | Indicates that the file is connected for direct access | |
| UNDEFINED | Indicates that the file is not connected |
The format of the ACTION= specifier is as follows:
ACTION= scalar_char_variable |
One of the following is returned in scalar_char_variable:
| Value | Function | |
| READ | Indicates that the file is connected with access limited to input only | |
| WRITE | Indicates that the file is connected with access limited to output only | |
| READWRITE | Indicates that the file is connected for both input and output | |
| UNDEFINED | Indicates that the file is not connected |
The format of the BLANK= specifier is as follows:
BLANK= scalar_char_variable |
One of the following is returned in scalar_char_variable:
| Value | Function | |
| NULL | Indicates that null blank control is in effect | |
| ZERO | Indicates that zero blank control is in effect | |
| UNDEFINED | Indicates that the file is not connected for formatted I/O or the file is not connected at all |
See the BLANK= specifier for the OPEN statement in “Connection Specifiers”, for the meaning of null and zero blank control.
The format of the DELIM= specifier is as follows:
DELIM= scalar_char_variable |
One of the following is returned in scalar_char_variable:
| Value | Function | |
| APOSTROPHE | Indicates that an apostrophe is used as the delimiter in list-directed and namelist-formatted output | |
| QUOTE | Indicates that the quotation mark is used as the delimiter in list-directed and namelist-formatted output | |
| NONE | Indicates that there is no delimiting character in list-directed and namelist-formatted output | |
| UNDEFINED | Indicates that the file is not connected or the file is not connected for formatted I/O |
The format of the DIRECT= specifier is as follows:
DIRECT= scalar_char_variable |
One of the following is returned in scalar_char_variable:
| Value | Function | |
| YES | Indicates that direct access is an allowed access method | |
| NO | Indicates that direct access is not an allowed access method | |
| UNKNOWN | Indicates that the system does not know if direct access is allowed |
The format of the ERR= specifier is as follows:
ERR= label |
The program branches to the label in the ERR= specifier if there is an error in the execution of the INQUIRE statement itself. The label must be the label of a branch target statement in the same scoping unit as the INQUIRE statement.
If an error condition occurs, the position of the file becomes indeterminate.
If an IOSTAT= specifier is present and an error condition occurs, the IOSTAT variable specified becomes defined with a positive value. All other inquiry specifier variables become undefined.
The format of the EXIST= specifier is as follows:
EXIST= scalar_default_logical_variable |
The system returns either .TRUE. or .FALSE. in scalar_default_logical_variable. .TRUE. indicates that the file or unit exists. .FALSE. indicates that the file or unit does not exist.
The format of the FILE= specifier is as follows:
FILE= scalar_char_expr |
To inquire by file, a file specifier must be present, and a unit specifier cannot be present.
The value of scalar_char_expr must be an acceptable file name. Trailing blanks are ignored. Both uppercase and lowercase letters are acceptable. The use of uppercase and lowercase is significant for file names.
The file name can refer to a file not connected or to one that does not exist.
The format of the FORM= specifier is as follows:
FORM= scalar_char_variable |
The system returns one of the following in scalar_char_variable:
| Value | Function | |
| FORMATTED | Indicates that the file is connected for formatted I/O | |
| UNFORMATTED | Indicates that the file is connected for unformatted I/O | |
| UNDEFINED | Indicates that the file is not connected |
The format of the FORMATTED= specifier is as follows:
FORMATTED= scalar_char_variable |
The system returns one of the following in scalar_char_variable:
| Value | Function | |
| YES | Indicates that formatted I/O is an allowed form for the file | |
| NO | Indicates that formatted I/O is not an allowed form for the file | |
| UNKNOWN | Indicates that the system cannot determine if formatted I/O is an allowed form for the file |
The format of the IOSTAT= specifier is as follows:
IOSTAT= scalar_default_int_variable |
The I/O library returns an integer value in scalar_default_int_variable. If scalar_default_int_variable > 0, an error condition occurred. If scalar_default_int_variable = 0, no error condition occurred. Note that the value cannot be negative.
The IOSTAT= specifier applies to the execution of the INQUIRE statement itself.
The format of the NAME= specifier is as follows:
NAME= scalar_char_variable |
The I/O library returns either a file name or an undefined value in scalar_char_variable. If the value is a file name, it is the name of the file connected to the unit, if the file has a name. An undefined value indicates that either file does not have a name or no file is connected to the unit.
A name different from the one specified in the FILE= specifier on the OPEN statement may be returned.
The format of the NAMED= specifier is as follows:
NAMED= scalar_default_logical_variable |
The system returns either .TRUE. or .FALSE. in scalar_default_logical_variable. .TRUE. indicates that the file has a name. .FALSE. indicates that the file does not have a name.
The format of the NEXTREC= specifier is as follows:
NEXTREC= scalar_default_int_variable |
The system returns one of the following in scalar_default_int_variable:
| Value | Function | |
| last record number + 1 | Indicates the next record number to be read or written in a file connected for direct access. The value is one more than the last record number read or written. | |
| 1 | Indicates that no records have been processed. | |
| undefined value | Indicates that the file is not connected for direct access or the file position is indeterminate because of a previous error condition. |
This inquiry is used for files connected for direct access.
The format of the NUMBER= specifier is as follows:
NUMBER= scalar_default_int_variable |
The system returns either a unit number or -1 in scalar_default_int_variable. A unit number indicates the number of the unit connected to the file. -1 indicates that there is no unit connected to the file.
The format of the OPENED= specifier is as follows:
OPENED= scalar_default_logical_variable |
The system returns either .TRUE. or .FALSE. in scalar_default_logical_variable. .TRUE. indicates that the file or unit is connected (that is, opened). .FALSE. indicates that the file or unit is not connected (that is, not opened).
The format of the PAD= specifier is as follows:
PAD= scalar_char_variable |
The system returns either NO or YES in scalar_char_variable. NO indicates that the file or unit is connected with the PAD= specifier set to NO. YES indicates that either the file or unit is connected with the PAD= specifier set to YES or that the file or unit is not connected.
The format of the POSITION= specifier is as follows:
POSITION= scalar_char_variable |
The system returns one of the following in scalar_char_variable:
| Value | Function | |
| REWIND | Indicates that the file is connected with its position at the initial point | |
| APPEND | Indicates that the file is connected with its position at the terminal point | |
| ASIS | Indicates that the file is connected without changing its position | |
| UNDEFINED | Indicates that either the file is not connected or it is connected for direct access |
If any repositioning has occurred since the file was connected, the value returned is ASIS. It is not equal to REWIND unless positioned at the initial point, and it is not equal to APPEND unless positioned at the terminal point.
The format of the READ= specifier is as follows:
READ= scalar_char_variable |
The system returns one of the following in scalar_char_variable:
| Value | Function | |
| YES | Indicates that READ is one of the allowed actions for the file | |
| NO | Indicates that READ is not one of the allowed actions for the file | |
| UNKNOWN | Indicates that the action for the file cannot be determined |
The format of the READWRITE= specifier is as follows:
READWRITE= scalar_char_variable |
The system returns one of the following in scalar_char_variable:
| Value | Function | |
| YES | Indicates that READWRITE is an allowed action for the file | |
| NO | Indicates that READWRITE is not an allowed action for the file | |
| UNKNOWN | Indicates that the action for the file cannot be determined |
The format of the RECL= specifier is as follows:
RECL= scalar_default_int_variable |
The system returns either a maximum record length or an undefined value in scalar_default_int_variable. The maximum record length is the record length, if the file is connected for sequential access, or the length of each record, if the file is connected for direct access. An undefined value indicates that the file does not exist.
For a formatted file, the length is the number of characters for all records.
For an unformatted file, the length is in 8-bit bytes.
The format of the SEQUENTIAL= specifier is as follows:
SEQUENTIAL= scalar_char_variable |
The system returns one of the following in scalar_char_variable:
| Value | Function | |
| YES | Indicates that sequential access is an allowed access method | |
| NO | Indicates that sequential access is not an allowed access method | |
| UNKNOWN | Indicates that the access is not known |
The format of the UNFORMATTED= specifier is as follows:
UNFORMATTED= scalar_char_variable |
The system returns one of the following in scalar_char_variable:
| Value | Function | |
| YES | Indicates that unformatted I/O is an allowed form for the file | |
| NO | Indicates that unformatted I/O is not an allowed form for the file | |
| UNKNOWN | Indicates that the form cannot be determined |
The format of the WRITE= specifier is as follows:
WRITE= scalar_char_variable |
The system returns one of the following in scalar_char_variable:
| Value | Function | |
| YES | Indicates that WRITE is an allowed action for the file | |
| NO | Indicates that WRITE is not an allowed action for the file | |
| UNKNOWN | Indicates that the action cannot be determined |
Figure 1-6, summarizes the values assigned to the INQUIRE specifier variables by the execution of an INQUIRE statement.
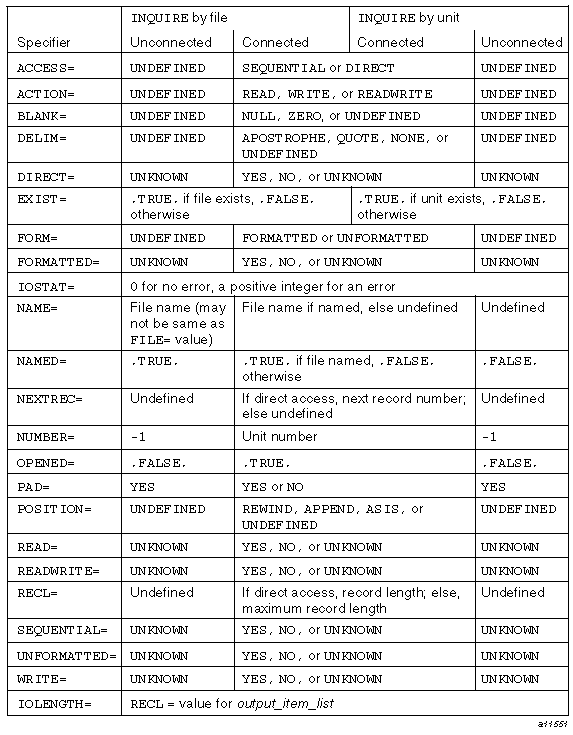
Execution of a data transfer statement usually changes the file position. In addition, there are three statements whose main purpose is to change the file position. Changing the position backwards by one record is called backspacing and is performed by the BACKSPACE statement. Changing the position to the beginning of the file is called rewinding and is performed by the REWIND statement. The ENDFILE statement writes an end-of-file record and positions the file after the end-of-file record. The following are file positioning statements:
BACKSPACE 9 BACKSPACE (UNIT = 10) BACKSPACE (ERR = 99, UNIT = 8, IOSTAT = STATUS) REWIND (ERR = 102, UNIT = 10) ENDFILE (10, IOSTAT = IERR) ENDFILE (11) |
The file positioning statements have common components.
The external_file_unit can be a unit specifier or an external name. If it is a unit specifier, it must have a nonnegative value. See “Units”, for information on units and the external_file_unit.
The position_spec_list is described in “Specifiers for File Position Statements”.
| Note: The Fortran standard does not address using external names as external_file_unit specifiers. |
The following sections describe the BACKSPACE, REWIND, and ENDFILE statements in more detail.
Executing a BACKSPACE statement causes the file to be positioned before the current record if there is a current record, or before the preceding record if there is no current record. If there is no current record and no preceding record, the file position is not changed. If the preceding record is an end-of-file record, the file becomes positioned before the end-of-file record.
If the last data transfer to a file connected for sequential access was an output data transfer statement, a BACKSPACE statement on that file writes an end-of-file record to the file. If there is a preceding record, the BACKSPACE statement causes the file to become positioned before the record that precedes the end-of-file record.
The BACKSPACE statement is defined as follows:
| backspace_stmt | is |
| |
|
| or |
|
The BACKSPACE statement is used only to position external files.
If the file is already at its initial point, a BACKSPACE statement has no effect. If the file is connected, but does not exist, backspacing is prohibited. Backspacing over records written using list-directed or namelist formatting is prohibited.
BACKSPACE ERROR_UNIT ! ERROR_UNIT is an
! integer variable
BACKSPACE (10, & ! STAT is an integer
! variable of
IOSTAT = STAT) ! default type |
A REWIND statement positions the file at its initial point. Rewinding has no effect on the file position when the file is already positioned at its initial point. If a file does not exist, but it is connected, rewinding the file is permitted, but it has no effect.
If the last data transfer to a file was an output data transfer statement, a REWIND statement on that file writes an end-of-file record to the file.
The file must be connected for sequential access.
The REWIND statement is defined as follows:
| rewind_stmt | is |
| |
|
| or |
|
The REWIND statement is used only to position external files.
REWIND INPUT_UNIT ! INPUT_UNIT is an integer
! variable
REWIND (10, ERR = 200) ! 200 is a label of branch
! target in this
! scoping unit |
The ENDFILE writes an end-of-file record as the next record and positions the file after the end-of-file record written. Writing records past the end-of-file record is prohibited, except for certain file structures.
If you are using the CF90 compiler, you can find more information on file structures in the Application Programmer's I/O Guide.
If you are using the MIPSpro 7 Fortran 90 compiler, IRIX record blocking is the default form for sequential unformatted files. Text files are used for all other types of Fortran I/O.
| Note: The Fortran standard does not address writing past an end-of-file record. |
After executing an ENDFILE statement, it is necessary to execute a BACKSPACE or REWIND statement to position the file ahead of the end-of-file record before reading or writing the file. If the file is connected but does not exist, writing an end-of-file record creates the file.
The file must be connected for sequential access.
The ENDFILE statement is defined as follows:
| endfile_stmt | is |
| |
|
| or |
|
The ENDFILE statement is used only to position external files.
! OUTPUT_UNIT is an integer variable.
ENDFILE OUTPUT_UNIT
ENDFILE (10, ERR = 200, IOSTAT = ST)
! 200 is a label of a branch
! target in this scoping unit
! ST is a default scalar integer
! variable |
A file can be connected for sequential and direct access, but not for both simultaneously. If a file is connected for sequential access and an ENDFILE statement is executed on the file, only those records written before the ENDFILE statement is executed are considered to have been written. Consequently, if the file is subsequently connected for direct access, only those records before the end-of-file record can be read.
The position_spec_list is defined as follows (note that no specifier can be repeated in a position_spec_list):
| position_spec | is |
| |
|
| or |
| |
|
| or |
|
The following sections describe the form and effect of the position specifiers that can appear in the file positioning statements.
The format of the UNIT= specifier is as follows:
[ UNIT= ]scalar_int_expr |
The scalar_int_expr specifies an external unit. The value of the scalar_int_expr must be nonnegative.
A unit specifier is required. If the keyword UNIT is omitted, the scalar integer expression must be the first item in the position specifier list. A unit number identifies one and only one external unit in all program units in a Fortran program.
There must be a file connected to the unit, and the unit must be connected for sequential access.
The format of the IOSTAT= specifier is as follows:
IOSTAT= scalar_default_int_variable |
The I/O library returns an integer value in scalar_default_int_variable. If scalar_default_int_variable > 0, an error condition occurred. If scalar_default_int_variable = 0, no error condition occurred. Note that the value cannot be negative.
The IOSTAT= specifier applies to the execution of the file positioning statement itself.
The format of the ERR= specifier is as follows:
ERR= label |
The program branches to the label in the ERR= specifier if there is an error in the execution of the particular file positioning statement itself. The label must be the label of a branch target statement in the same scoping unit as the file positioning statement.
If an error condition occurs, the position of the file becomes indeterminate.
If an IOSTAT= specifier is present and an error condition occurs, the IOSTAT variable specified becomes defined with a positive value.
Any function reference appearing in an I/O statement specifier or in an I/O list must not cause the execution of another I/O statement on the same file or unit; this practice is also known as recursive I/O. Note that such function references also must not have side effects that change any object in the same statement.
WRITE (10, FMT = "(10I5)", REC = FCN(I)) &
X(FCN(J)), I, J |
The function FCN must not contain an I/O statement using unit 10 and must not change its argument because I and J are also output list items.
| Note: The Fortran standard does not permit any recursive I/O operations, even those involving different units. |
A unit or file might not have all of the properties (for example, all access methods or all forms) required for it by execution of certain I/O statements. If this is the case, such I/O statements must not refer to files or units limited in this way. For example, if unit 5 cannot support unformatted sequential files, the following OPEN statement must not appear in a program:
OPEN (UNIT = 5, IOSTAT = IERR, &
ACCESS = "SEQUENTIAL", FORM = "UNFORMATTED") |