This chapter describes the support provided for writing parallel programs on the Origin200 and Origin2000 servers. It assumes that you are familiar with basic parallel constructs.
You can find additional information on parallel programming in Topics in IRIX Programming.
 | Note: The multiprocessing features described in this chapter require support from the MP run-time library ( libmp). IRIX operating system versions 6.3 (and above) are automatically shipped with this new library. If you want to access these features on a system running IRIX 6.2, then contact your local Silicon Graphics service provider or Silicon Graphics Customer Support (1-800-800-4744) for libmp. |
An Origin2000 server provides cache-coherent, shared memory in the hardware. Memory is physically distributed across processors. Consequently, references to locations in the remote memory of another processor take substantially longer (by a factor of two or more) to complete than references to locations in local memory. This can severely affect the performance of programs that suffer from a large number of cache misses. Figure 12-1, shows a simplified version of the Origin2000 memory hierarchy.
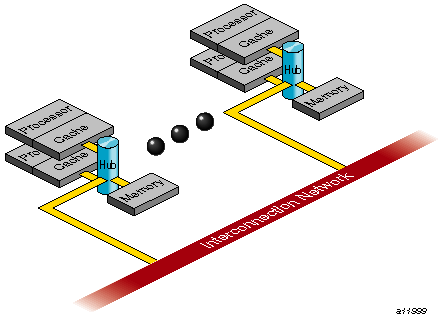
To obtain good performance in such programs, it is important to schedule computation and distribute data across the underlying processors and memory modules, so that most cache misses are satisfied from local rather than remote memory. The primary goal of the programming support, therefore, is to enable user control over data placement and computation scheduling.
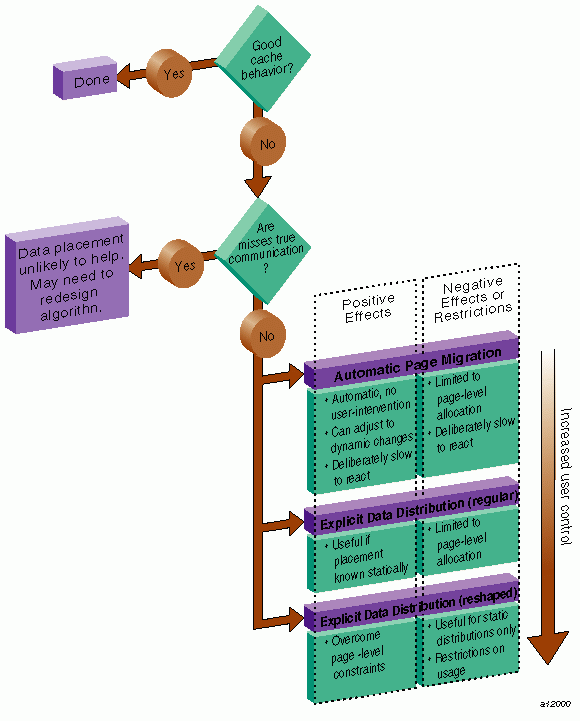
Cache behavior continues to be the largest single factor affecting performance, and programs with good cache behavior usually have little need for explicit data placement. In programs with high cache misses, if the misses correspond to true data communication between processors, then data placement is unlikely to help. In these cases, it may be necessary to redesign the algorithm to reduce inter-processor communication. Figure 12-2, shows this scenario.
If the misses are to data referenced primarily by a single processor, then data placement may be able to convert remote references to local references, thereby reducing the latency of the miss. The possible options for data placement are automatic page migration or explicit data distribution, either regular or reshaped. The differences between these choices are shown in Figure 12-2.
Automatic page migration requires no user intervention and is based on the run-time cache miss behavior of the program. It can therefore adjust to dynamic changes in the reference patterns. However, the page migration heuristics are deliberately conservative, and may be slow to react to changes in the references patterns. They are also limited to performing page-level allocation of data.
Regular data distribution (performing just page-level placement of the array) is also limited to page-level allocation, but is useful when the page migration heuristics are slow and the desired distribution is known to the programmer.
Finally, reshaped data distribution changes the layout of the array, thereby overcoming the page-level allocation constraints; however, it is useful only if a data structure has the same (static) distribution for the duration of the program. Given these differences, it may be necessary to use each of these options for different data structures in the same program.
This section describes the two types of data distribution: regular and reshaped.
The regular data distribution directives try to achieve the desired distribution solely by influencing the mapping of virtual addresses to physical pages without affecting the layout of the data structure. Because the granularity of data allocation is a physical page (at least 16 KB), the achieved distribution is limited by the underlying page granularity. However, the advantages are that regular data distribution directives can be added to an existing program without any restrictions, and can be used for affinity scheduling (see “Affinity Scheduling”).
Similar to regular data distribution, the #pragma distribute_reshape directive specifies the desired distribution of an array. In addition, however, the #pragma distribute_reshape directive declares that the program makes no assumptions about the storage layout of that array. The compiler performs aggressive optimizations for reshaped arrays that violate standard layout assumptions but guarantee the desired data distribution for that array.
The compiler transforms a reshaped array into a pointer to a "processor array." The processor array has one element per processor, with the element pointing to the portion of the array local to the corresponding processor.
Figure 12-3, shows the effect of the #pragma distribute_reshape directive with a block distribution on a one-dimensional array. N is the size of the array dimension, P is the number of processors, and B is the block size on each processor.
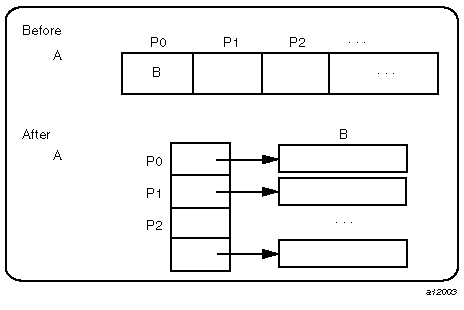
With this implementation, an array reference A[i] is transformed into a two-dimensional reference A[i/B] [i%B], where B, the size of each block, is equal to N/P, rounded up to the nearest integer value (ceiling(N/P)). A[i/B], therefore, points to a processor's local portion of the array, and A[i/B][i%B] refers to a specific element within the local processor's portion.
A cyclic distribution with a chunk size of 1 is implemented as shown in Figure 12-4.
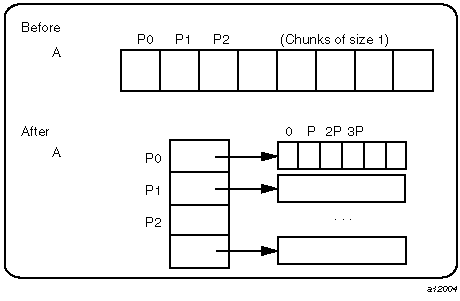
An array reference, A[i], is transformed to A[i%P] [i/P], where P is the number of threads in that distributed dimension.
Finally, a cyclic distribution with a chunk size that is either a constant greater than 1 or a run-time value (also called block-cyclic) is implemented as shown in Figure 12-5.
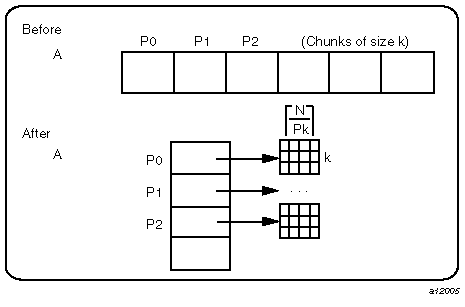
An array reference, A[i], is transformed to the three-dimensional reference A[(i/k)%P] [i/(P*k)] [i%k], where P is the total number of threads in that dimension, and k is the chunk size.
The compiler tries to optimize these divide and modulo operations out of inner loops through aggressive loop transformations such as blocking and peeling.
In summary, consider the differences between regular and reshaped data distribution. The advantage of regular distributions is that they do not impose any restrictions on the distributed arrays and can be freely applied in existing codes. Furthermore, they work well for distributions where page granularity is not a problem. For example, consider a block distribution of the columns of a two-dimensional array of size A[r][c] (row-major layout) and distribution [block][*]. If the size of each processor's portion, ceiling(r/P) ×c×element_size, is significantly greater than the page size (16KB on the Origin2000 server), then regular data distribution should be effective in placing the data in the desired fashion.
However, regular data distribution is limited by page-granularity considerations. For instance, consider a [block][block] distribution of a two-dimensional array where the size of a row is much smaller than a page. Each physical page is likely to contain data belonging to multiple processors, making the data-distribution quite ineffective. (Data distribution may still be desirable from affinity-scheduling considerations.)
Reshaped data distribution addresses the problems of regular distributions by changing the layout of the array in memory so as to guarantee the desired distribution. However, because the array no longer conforms to standard storage layout, there are restrictions on the usage of reshaped arrays.
Given both types of data distribution, you can choose between the two based on the characteristics of the particular array in an application.
For a given data structure in the program, you can choose a data distribution option based on the following criteria:
If the program repeatedly references the data structure and benefits from reuse in the cache, then data placement is not needed.
If the program incurs a large number of cache misses on the data structure, then you should identify the desired distribution in the array dimensions (such as block or cyclic) based on the desired parallelism in the program. For example, the following code suggests a distribution of A[block][*]:
#pragma pfor for(i = 2; i <= n; i++) for(j = 2; j <= n; j++) A[i][j] = 3*i + 4*j + A[i][j-1];
Whereas the next code segment suggests a distribution of A[*][block]:
for(i = 2; i <= n; i++) #pragma pfor for(j = 2; j <= n; j++) A[i][j] = 3*i + 4*j + A[i][j-1];
Having identified the desired distribution, you can select either regular or reshaped distribution based on the size of an individual processor's portion of the distributed array. Regular distribution is useful only if each processor's portion is substantially larger than the page-size in the underlying system (16 KB on the Origin2000 server). Otherwise, regular distribution is unlikely to be useful, and you should use distribute_reshape, where the compiler changes the layout of the array to overcome page-level constraints.
For example, consider the following code:
double A[m][n]; #pragma distribute A[*][block] |
In this example, each processor's portion is approximately (m*n/P) elements (8*(m*n/P) bytes), where P is the number of processors. Due to the row-major layout of the array, however, each contiguous piece is only 8*(n/P) bytes. If n is 1000,000 then each contiguous piece is likely to exceed a page and regular distribution is sufficient. If instead n is small, say 10,000, then distribute_reshape is required to obtain the desired distribution.
In contrast, consider the following distribution:
#pragma distribute A[block][*] |
In this example, the size of each processor's portion is a single contiguous piece of (m*n)/P elements (8*(m*n)/P bytes). So if m is 100, for instance, regular distribution may be sufficient even if n is only 10,000.
As this example illustrates, distributing the outer dimensions of an array increases the size of an individual processor's portion (favoring regular distribution), whereas distributing the inner dimensions is more likely to require reshaped distribution.
Finally, the IRIX operating system on Origin2000 follows a default "first-touch" page-allocation policy; that is, each page is allocated from the local memory of the processor that incurs a page-fault on that page. Therefore, in programs where the array is initialized (and consequently first referenced) in parallel, even a regular distribution directive may not be necessary, because the underlying pages are allocated from the desired memory location automatically due to the first-touch policy.
The goal of affinity scheduling is to control the mapping of iterations of a parallel loop for execution onto the underlying threads. Specify affinity scheduling with an additional clause to a #pragma pfor directive. An affinity clause, if supplied, overrides the schedtype clause.
The syntax of the #pragma pfor directive with the affinity clause is as follows:
#pragma pfor affinity(idx) = data(array(expr)) |
idx is the loop-index variable; array is the distributed array; and expr indicates an element owned by the processor on which you want this iteration executed.
The following code shows an example of data affinity:
#pragma distribute A[block]
#pragma parallel shared (A, a, b) local (i)
#pragma pfor affinity(i) = data(A[a*i + b])
for (i = 0; i < n; i++)
A[a*i + b] = 0; |
The multiplier for the loop index variable (a) and the constant term (b) must both be literal constants, with a greater than zero.
The effect of this clause is to distribute the iterations of the parallel loop to match the data distribution specified for the array A, such that iteration i is executed on the processor that owns element A[a*i + b], based on the distribution for A. The iterations are scheduled based on the specified distribution, and are not affected by the actual underlying data-distribution (which may differ at page boundaries, for example).
In the case of a multi-dimensional array, affinity is provided for the dimension that contains the loop-index variable. The loop-index variable cannot appear in more than one dimension in an affinity directive. For example,
#pragma distribute A[block][cyclic(1)] #pragma parallel shared (A, n) local (i, j) #pragma pfor #pragma affinity (i) = data(A[i + 3, j]) for (i = 0; i < n; i++) for (j = 0; j < n; j++) A[i + 3, j] = A[i + 3, j-1]; |
In this example, the loop is scheduled based on the block distribution of the first dimension. See Chapter 12, “Parallel Programming on Origin Servers”, for more information about distribution directives.
Data affinity for loops with non-unit stride can sometimes result in non-linear affinity expressions. In such situations the compiler issues a warning, ignores the affinity clause, and defaults to simple scheduling.
By default, the compiler assumes that a distributed array is not dynamically redistributed, and directly schedules a parallel loop for the specified data affinity. In contrast, a redistributed array can have multiple possible distributions, and data affinity for a redistributed array must be implemented in the run-time system based on the particular distribution.
However, the compiler does not know whether or not an array is redistributed, because the array may be redistributed in another function (possibly even in another file). Therefore, you must explicitly specify the #pragma dynamic declaration for redistributed arrays. This directive is required only in those functions that contain a pfor loop with data affinity for that array. This informs the compiler that the array can be dynamically redistributed. Data affinity for such arrays is implemented through a run-time lookup.
You can supply a #pragma distribute directive on a formal parameter, thereby specifying the distribution on the incoming actual parameter. If different calls to the subroutine have parameters with different distributions, then you can omit the #pragma distribute directive on the formal parameter; data affinity loops in that subroutine are automatically implemented through a run-time lookup of the distribution. (This is permissible only for regular data distribution. For reshaped array parameters, the distribution must be fully specified on the formal parameter.)
This section discusses how the nest clause interacts with the affinity clause when the program has reshaped arrays.
When you combine a nest clause and an affinity clause, the default scheduling is simple, except when the program has reshaped arrays and is compiled -O3. In that case, the default is to use data affinity scheduling for the most frequently accessed reshaped array in the loop (chosen heuristically by the compiler). To obtain simple scheduling even at -O3, you can explicitly specify the schedtype on the parallel loop.
The following example illustrates a nested pfor with an affinity clause:
#pfor nest(i, j) affinity(i, j) = data(A[i][j]) for (i = 2; i < n; i++) for (j = 2; j < m; j++) A[i][j] = A[i][j] + i * j; |
The programming support consists of extensions to the existing C #pragma directives. Table 12-1, summarizes the new directives. Like the other C directives, these new directives are ignored except under multiprocessor compilation. For detailed information about these directives, see the MIPSpro C and C++ Pragmas
Table 12-1. Loop Nest Optimization Directives Specific to the Origin2000 Server
#pragma | Short Description |
|---|---|
#pragma distribute | Specifies data distribution. |
#pragma redistribute | Specifies dynamic redistribution of data. |
#pragma distribute_reshape | Specifies data distribution with reshaping. |
#pragma dynamic | Tells the compiler that the specified array may be redistributed in the program. |
#pragma page_place | Allows the explicit placement of data. |
#pragma pfor | affinity clause allows data-affinity or thread-affinity scheduling; nest clause exploits nested concurrency. |
You can use the following set of intrinsics to obtain information about an individual dimension of a distributed array. C array dimensions are numbered starting at 0. All routines work with 64-bit integers as shown below, and return -1 in case of an error (except dsm_this_startingindex, where -1 may be a legal return value).
dsm_numthreads: Called with a distributed array and a dimension number, and returns the number of threads in that dimension:
extern long long dsm_numthreads (void* array, long long dim)
dsm_chunksize: Returns the chunk size (ignoring partial chunks) in the given dimension for each of block, cyclic(..), and star distributions:
extern long long dsm_chunksize (void* array, long long dim)
dsm_this_chunksize: Returns the chunk size for the chunk containing the given index value for each of block, cyclic(..), and star. This value may be different from dsm_chunksize due to edge effects that may lead to a partial chunk.
extern long long dsm_this_chunksize (void* array, long long dim, long long index)
dsm_rem_chunksize: Returns the remaining chunk size from index to the end of the current chunk, inclusive of each end point. Essentially it is the distance from index to the end of that contiguous block, inclusive.
extern long long dsm_rem_chunksize (void* array, long long dim, long long index)
dsm_this_startingindex: Returns the starting index value of the chunk containing the supplied index:
extern long long dsm_this_startingindex (void* array, long long dim, long long index)
dsm_numchunks: Returns the number of chunks (including partial chunks) in given dim for each of block, cyclic(..), and star distributions:
extern long long dsm_numchunks (void* array, long long dim)
dsm_this_threadnum: Returns the thread number for the chunk containing the given index value for each of block, cyclic(..), and star distributions:
extern long long dsm_this_threadnum(void* array, long long dim, long long index)
dsm_distribution_block, dsm_distribution_cyclic, and dsm_distribution_star: Boolean routines to query the distribution of a given dimension:
extern long long dsm_distribution_block (void* array, long long dim) extern long long dsm_distribution_cyclic (void* array, long long dim) extern long long dsm_distribution_star (void* array, long long dim)
dsm_isreshaped: Boolean routine to query whether reshaped or not:
extern long long dsm_isreshaped (void* array)
dsm_isdistributed: Boolean routine to query whether distributed (regular or reshaped) or not:
extern long long dsm_isdistributed (void* array)
You can control various run-time features through the following optional environment variables and options. This section describes:
Details about the following multiprocessing environment variables can be found on the pe_environ(5) man page.
_DSM_OFF
_DSM_BARRIER
_DSM_PPM
_DSM_PLACEMENT
_DSM_MIGRATION
_DSM_MIGRATION_LEVEL
_DSM_WAIT
_DSM_VERBOSE
MP_SIMPLE_SCHED
MP_SUGNUMTHD
PAGESIZE_STACK, PAGESIZE_DATA, and PAGESIZE_TEXT
Useful compile-time options include:
| -MP:dsm={on, off} (default on) | |||
All the data-distribution and scheduling features described in this chapter are enabled by default under -mp compilation. To disable all the DSM-specific directives (for example, distribution and affinity scheduling), compile with -MP:dsm=off.
| |||
| -MP:clone={on, off} (default on) | |||
The compiler automatically clones procedures that are called with reshaped arrays as parameters for the incoming distribution. However, if you have explicitly specified the distribution on all relevant formal parameters, then you can disable auto-cloning with -MP:clone=off. The consistency checking of the distribution between actual and formal parameters is not affected by this flag, and is always enabled. | |||
| -MP:check_reshape={on, off} (default off) | |||
Enables generation of the run-time consistency checks across procedure boundaries when passing reshaped arrays (or portions thereof) as parameters. | |||
The examples in this section include the following:
The example below distributes sequentially the rows of a matrix. Such a distribution places data effectively only if the size of an individual row (n) exceeds that of a page.
double A[n][n]; /* Distribute columns in cyclic fashion */ #pragma distribute A [cyclic(1)][*] /* Perform Gaussian elimination across rows The affinity clause distributes the loop iterations based on the row distribution of A */ for (i = 0; i< n; i++) #pragma pfor affinity(j) = data(A[i][j]) for (j = i+1; j < n; j++) ... reduce row j by row i ... |
If the rows are smaller than a page, then it may be beneficial to reshape the array. This is easily specified by changing the keyword from distribute to distribute_reshape.
In addition to overcoming size constraints as shown above, the #pragma distribute_reshape directive is useful when the desired distribution is contrary to the layout of the array. For instance, suppose you want to distribute the columns of a two-dimensional matrix. In the following example, the #pragma distribute_reshape directive overcomes the storage layout constraints to provide the desired distribution:
double A[n][n];
/* Distribute columns in block fashion */
#pragma distribute_reshape A [*][block]
double sum[n];
#pragma distribute sum[block]
/* Perform sum-reduction on the elements of each column */
#pragma pfor local(j) affinity(i) = data(A[j][i])
for (i = 0; i< n; i++)
for (j = 0; j < n; j++)
sum[i] = sum[i] + A[j][i]; |
This example demonstrates regular data distribution and data affinity. This example, run on a four-processor Origin2000 server, uses simple block scheduling. Processor 0 will calculate the results of the first 25,000 elements of A, processor 1 will calculate the second 25,000 elements of A, and so on. Arrays B and C are initialized using one processor; therefore, all of the memory pages are touched by the master processor (processor 0) and are placed in processor 0's local memory.
Using data distribution changes the placement of memory pages for arrays A, B, and C to match the data reference pattern. Thus, the code runs 33% faster on a four-processor Origin2000 than it would run using SMP directives without data distribution.
Without Data Distribution
double a[1000000], b[1000000]; double c[1000000]; int i; #pragma parallel shared(a, b, c) local(i) #pragma pfor for (i = 0; i < 100000; i++) a[i] = b[i] + c[i]; |
With Data Distribution
double a[1000000], b[1000000];
double c[1000000];
int i;
#pragma distribute a[block], b[block], c[block]
#pragma parallel shared(a, b, c) local(i)
#pragma pfor affinity(i) = data(a[i])
for (i = 0; i < 100000; i++)
a[i] = b[i] + c[i]; |
A distributed array can be passed as a parameter to a subroutine that has a matching declaration on the formal parameter:
double A [m][n];
#pragma distribute_reshape A [block][*]
foo (m, n, A);
foo (int p, int q, double A[p][q]){
#pragma distribute_reshape A[block][*]
#pragma pfor affinity (i) = data (A[i][j])
for (i = 0; i < P; i++)
...
} |
Because the array is reshaped, it is required that the #pragma distribute_reshape directive in the caller and the callee match exactly. Furthermore, all calls to function foo() must pass in an array with the exact same distribution.
If the array was only distributed (that is, not reshaped) in the above example, then the subroutine foo() can be called from different places with different incoming distributions. In this case, you can omit the distribution directive on the formal parameter, thereby ensuring that any data affinity within the loop is based on the distribution (at run time) of the incoming actual parameter.
double A[m][n], B[p][q];
double A [block][*];
double B [cyclic(1)][*];
foo (m, n, A);
foo (p, q, B);
...
foo (int s, int t, double X[s][t]) {
#pragma pfor affinity (i) = data (X[i+2][j])
for (i = ...)
} |
This example shows how an array is redistributed at run time:
bar(int n, double X[n][n]) {
...
#pragma redistribute X [*][cyclic(<expr>)]
...
}
foo() {
double LocalArray [1000][1000];
#pragma distribute LocalArray [*][block]
/* the call to bar() may redistribute LocalArray */
#pragma dynamic LocalArray
...
bar(1000, LocalArray);
/* The distribution for the following pfor */
is not known statically */
#pragma pfor affinity (i) = data (LocalArray[i][j])
...
} |
The next example illustrates a situation where the #pragma dynamic directive can be optimized away. The main routine contains a local array A that is both distributed and dynamically redistributed. This array is passed as a parameter to foo() before being redistributed, and to bar() after being (possibly) redistributed. The incoming distribution for foo() is statically known; you can specify a #pragma distribute directive on the formal parameter, thereby obtaining more efficient static scheduling for the affinity pfor. The subroutine bar(), however, can be called with multiple distributions, requiring run-time scheduling of the affinity pfor.
main () {
double A[m][n];
#pragma distribute A [block][*]
#pragma dynamic A
foo (A);
if (...) {
#pragma redistribute A [cyclic(x)][*]
}
bar (A);
}
void foo (double A[m][n]) {
/* Incoming distribution is known to the user */
#pragma distribute A[block][*]
#pragma pfor affinity (i) = data (A[i][j])
...
}
void bar (double A[m][n]) {
/* Incoming distribution is not known statically */
#pragma dynamic A
#pragma pfor affinity (i) = data (A[i][j])
...
} |
The example below consists of a large array that is conceptually partitioned into unequal portions, one for each processor. This array is indexed through an index array idx, which stores the starting index value and the size of each processor's portion.
double A[N];
/* idx ---> index array containing start index into A [idx[p][0]]
and size [idx[p][1]] for each processor */
int idx [P][2];
#pragma page_place A[idx[0][0], idx[0][1]*8, 0)
#pragma page_place A[idx[1][0], idx[1][1]*8, 1)
#pragma page_place A[idx[2][0], idx[2][1]*8, 2)
...
#pragma pfor affinity (i) = thread(i)
for (i = 0; i < P-1; i++)
... process elements on processor i ...
... A[idx[i][0]] to A[idx[i][0]+idx[i][1]] ... |