This chapter provides information on how to run pixie and prof without invoking ssrun. By calling pixie directly, you can generate the following performance data:
An exact count of the number of times each basic block in your program is executed. A basic block is a sequence of instructions that is entered only at the beginning and exits only at the end.
Counts for callers of a routine as well as counts for callees. prof can provide inclusive basic block counting by propagating regular counts to callers of a routine.
For more information on basic block counting and inclusive basic block counting, see Chapter 7, "Analyzing Experiment Results: prof."
This chapter contains the following sections:
Use pixie to measure the frequency of code execution. pixie reads an executable program, partitions it into basic blocks, and writes (instruments) an equivalent program containing additional code that counts the execution of each basic block.
Note that the execution time of an instrumented program is two to five times longer than that of an uninstrumented one. This timing change may alter the behavior of a program that deals with a graphical user interface (GUI), or depends on events such as SIGALRM that are based on an external clock.
The syntax for pixie is
pixie prog_name [options] |
| prog_name | Name of the input program. | |
| options | Zero or more of the keywords listed in Table 8-1. |
Table 8-1 lists pixie options. For a complete list of options, view the pixie reference page.
The pixie command generates a set of files with a .pixie extension. These files are essentially copies of your original executable and any DSOs you specified in the call to pixie with code inserted to enable the collection of performance data when the .pixie version of your program is run.
If you use the -verbose flag with pixie, it reports the size of the old and new code. The new code size is the size of the code pixie will actually execute. It does not count read-only data (including a copy of the original text and another data block the same size as the original text) put into the text section. Calling size on the .pixie file reports a much larger text size than pixie -verbose, because size also counts everything in the text segment.
When you run the .pixie version of your program, one or more .Counts files are generated. The name of an output .Counts file is that of the original program with any leading directory names removed and .Counts appended. If the program executes calls to sproc(), sprocsp() or fork(), multiple .Counts files are generated—one for each process in the share group. In this case, each file will have the process ID appended to its name.
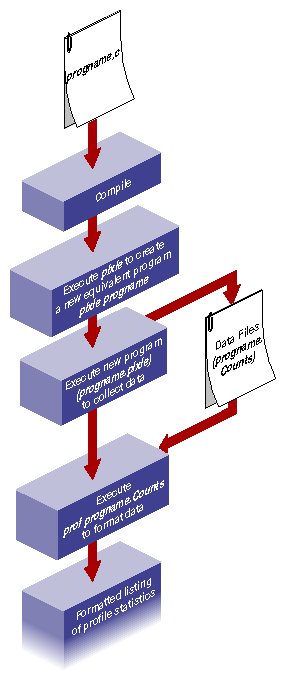
Use this procedure to obtain basic block counts. Also refer to Figure 8-1, which illustrates how basic block counting works.
Compile and link your program. The following example uses the input file myprog.c:
% cc -o myprog myprog.c
The cc compiler compiles myprog.c into an executable called myprog.
Run pixie to generate the equivalent program containing basic-block-counting code.
% pixie myprog
pixie takes myprog and writes an equivalent program, myprog.pixie, containing additional code that counts the execution of each basic block. pixie also writes an equivalent program for each shared object used by the program (in the form: libname.so.pix*), containing additional code that counts the execution of each basic block. For example, if myprog uses libc.so.1, pixie generates libc.so.1.pix*. (The value of * depends on the ABI).
Set the path for your .pixie files. pixie uses the rld search path for libraries (see rld(1) for the default paths). If the .pixie files are in your local directory, set the path as
% setenv LD_LIBRARY_PATH .
Execute the file(s) generated by pixie (myprog.pixie) in the same way you executed the original program:
% myprog.pixie
This program generates a list of basic block counts in files named myprog.Counts. If the program executes fork() or sproc(), a process ID is appended to the end of the filename (for example, myprog.Counts.345) for each process.

Note: Your program may not run as you expect when you invoke it with a .pixie extension. Some programs, uncompress and vi for example, treat their arguments differently when the name of the program changes. You may need to rename the .pixie version of your program back to its original name. To generate a valid .Counts file, your program must terminate normally or with a call to exit(). If it terminates with a signal such as SIGINT, the program must use a signal handler and leave the program through exit().
Run the profile formatting program prof specifying the name of the original program and the .Counts file for the program:
% prof myprog myprog.Counts
prof extracts information from myprog.Counts and prints it in an easily readable format. If multiple .Counts files exist, you can use the wildcard character (*) to specify all of the files.
% prof myprog myprog.Counts*
You can run the program several times, altering the input data, to create multiple profile data files.
The time computation assumes a "best case" execution; actual execution takes longer. This is because the time includes predicted stalls within a basic block, but not actual stalls that may occur entering a basic block. It also assumes that all instructions and data are in cache, that is, it excludes the delays due to cache misses and memory fetches and stores.
The complete output of the –pixie option is often extremely large. Use the –quit option with prof to restrict the size of the report. Refer to Chapter 7, "Analyzing Experiment Results: prof," for details about prof options.
The examples in this section illustrate how to use prof to obtain basic block counting information from a C program, generic.
The partial listing below illustrates the report generated for basic block counts in generic. prof first provides a standard report of basic block counts, then provides a report reflecting any options provided to prof.
% prof -i generic generic.Counts |
Prof run at: Fri May 17 12:39:22 1996
Command line: prof -i generic generic.Counts
2662778530: Total number of cycles
17.75186s: Total execution time
1875323864: Total number of instructions executed
1.420: Ratio of cycles / instruction
150: Clock rate in MHz
R4000: Target processor modelled
---------------------------------------------------------
Procedures sorted in descending order of cycles executed.
Unexecuted procedures are not listed. Procedures
beginning with *DF* are dummy functions and represent
init, fini and stub sections.
---------------------------------------------------------
cycles(%) cum % secs instrns calls procedure(dso:file)
2524610038(94.81) 94.81 16.83 1797940023 1 anneal(generic:/usr/demos/
SpeedShop/generic/generic.c)
135001332( 5.07) 99.88 0.90 75000822 1 slaveusrtime(./dlslave.so:/usr/demos/
SpeedShop/generic/dlslave.c)
1593518( 0.06) 99.94 0.01 1378788 4385 memcpy(/usr/lib32/libc.so.1:
/work/irix/lib/libc/libc_n32_M3/strings/bcopy.s)
735797( 0.03) 99.97 0.00 506627 4123 fread(/usr/lib32/libc.so.1:
/work/irix/lib/libc/libc_n32_M3/stdio/fread.c)
187200( 0.01) 99.98 0.00 124800 1600 next(/usr/lib32/libc.so.1:
/work/irix/lib/libc/libc_n32_M3/math/drand48.c)
136116( 0.01) 99.98 0.00 82498 1 iofile(generic:
/usr/demos/SpeedShop/generic/generic.c)
91200( 0.00) 99.98 0.00 62400 1600 _drand48(/usr/lib32/libc.so.1:
/work/irix/lib/libc/libc_n32_M3/math/drand48.c)
... |
The cycles(%) column reports the number and percentage of machine cycles used for the procedure. For example, 2524610038 cycles, or 94.81% of cycles were spent in the anneal() procedure.
The cum% column shows the cumulative percentage of calls. For example, 99.88% of all calls were spent between the top two functions in the listing: anneal() and slaveusrtime().
The secs column shows the number of seconds spent in each procedure. For example, 16.83 seconds were spent in the anneal() procedure. The time represents an idealized computation based on modelling the machine. It ignores potential floating point interlocks and memory latency time (cache misses and memory bus contention).
The instrns column shows the number of instructions executed for a procedure. For example, there were 1797940023 instructions devoted to the anneal() procedure.
The calls column reports the number of calls to each procedure. For example, there was just one call to the anneal() procedure.
The procedure (dso:file) column lists the procedure, its DSO name and filename. For example, the first line reports statistics for the procedure anneal() in the file generic.c in the generic executable.
The partial listing below illustrates the use of the –i[nvocations] option. For each procedure, prof reports the number of times it was invoked from each of its possible callers and lists the procedure(s) that called it.
---------------------------------------------------------
Procedures sorted in descending order of times invoked.
Unexecuted procedures are not listed.
---------------------------------------------------------
Total number of procedure invocations: 15114
calls(%) cum% size(bytes) procedure (dso:file)
4385(29.01) 29.01 3416 memcpy (/usr/lib32/libc.so.1:
/work/irix/lib/libc/libc_n32_M3/strings/bcopy.s)
4123(27.28) 56.29 1304 fread (/usr/lib32/libc.so.1:
/work/irix/lib/libc/libc_n32_M3/stdio/fread.c)
1600(10.59) 66.88 312 next (/usr/lib32/libc.so.1:
/work/irix/lib/libc/libc_n32_M3/math/drand48.c)
1600(10.59) 77.46 180 _drand48 (/usr/lib32/libc.so.1:
/work/irix/lib/libc/libc_n32_M3/math/drand48.c)
628( 4.16) 81.62 368 __sinf (/usr/lib32/libm.so:
/work/cmplrs/libm/fsin.c)
259( 1.71) 83.33 524 __filbuf (/usr/lib32/libc.so.1:
/work/irix/lib/libc/libc_n32_M3/stdio/_filbuf.c) |
The above listing shows the total procedure invocations (calls) during the run: 12113082.
The calls(%) column reports the number of calls (and the percentage of total calls) per procedure. For example, there were 4385 calls (or 29.01% of the total) spent in the procedure memcpy().
The cum% column shows the cumulative percentage of calls. For example, 56.29% of all calls were spent between memcpy() and fread().
The size(bytes) column shows the total byte size of a procedure. For example, the procedure memcpy() is 3416 bytes.
The procedure (dso:file) column lists the procedure, its DSO name and its filename. For example, the first line reports statistics for the procedure memcpy() in the file bcopy.s in libc.so.
The following partial listing shows the source code lines responsible for the largest portion of execution time produced with the –heavy option.
% prof -heavy generic generic.Counts |
The partial listing below shows basic block counts sorted in descending order of cycles used. The fields in the report are described in section "ideal Experiment Reports" section in Chapter 7, "Analyzing Experiment Results: prof."
---------------------------------------------------------
Lines listed in descending order of cycle counts.
---------------------------------------------------------
cycles(%) cum % times line procedure (dso:file)
2309934120(86.75%) 86.75% 14440000 1465 anneal (generic:/usr/demos/
SpeedShop/generic/generic.c)
207945880( 7.81%) 94.56% 14440000 1464 anneal (generic:/usr/demos/
SpeedShop/generic/generic.c)
81000506( 3.04%) 97.60% 5000000 29 slaveusrtime (dlslave.so:/usr/demos/
SpeedShop/generic/dlslave.c)
54000000( 2.03%) 99.63% 5000000 30 slaveusrtime (dlslave.so:/usr/demos/
SpeedShop/generic/dlslave.c)
6600000( 0.25%) 99.88% 380000 1463 anneal (generic:/usr/demos/
SpeedShop/generic/generic.c)
418380( 0.02%) 99.89% 32981 493 memcpy (/usr/lib32/libc.so.1:
/work/irix/lib/libc/libc_n32_M3/strings/bcopy.s)
418380( 0.02%) 99.91% 32981 494 memcpy (/usr/lib32/libc.so.1:
/work/irix/lib/libc/libc_n32_M3/strings/bcopy.s)
139482( 0.01%) 99.91% 32981 496 memcpy (/usr/lib32/libc.so.1:
/work/irix/lib/libc/libc_n32_M3/strings/bcopy.s)
139460( 0.01%) 99.92% 32981 495 memcpy (/usr/lib32/libc.so.1:
/work/irix/lib/libc/libc_n32_M3/strings/bcopy.s)
130009( 0.00%) 99.92% 10000 1461 anneal (generic:/usr/demos/
SpeedShop/generic/generic.c) |
You can limit the output of prof to collect information on only the most time-consuming parts of the program by specifying the –quit option. You can instruct prof to quit after a particular number of lines of output, after listing the elements consuming more than a certain percentage of the total, or after the portion of each listing whose cumulative use is a certain amount.
Consider the following sample listing:
% prof -quit 4 generic generic.Counts |
Prof run at: Fri May 17 14:09:12 1996
Command line: prof -quit 4 generic generic.Counts
2662778530: Total number of cycles
17.75186s: Total execution time
1875323864: Total number of instructions executed
1.420: Ratio of cycles / instruction
150: Clock rate in MHz
R4000: Target processor modelled
---------------------------------------------------------
Procedures sorted in descending order of cycles executed.
Unexecuted procedures are not listed. Procedures
beginning with *DF* are dummy functions and represent
init, fini and stub sections.
---------------------------------------------------------
cycles(%) cum % secs instrns calls procedure(dso:file)
2524610038(94.81) 94.81 16.83 1797940023 1 anneal(generic:/usr/demos/
SpeedShop/generic/generic.c)
135001332( 5.07) 99.88 0.90 75000822 1 slaveusrtime(./dlslave.so:
/usr/demos/SpeedShop/generic/dlslave.c)
1593518( 0.06) 99.94 0.01 1378788 4385 memcpy(/usr/lib32/
libc.so.1:/work/irix/lib/libc/libc_n32_M3/strings/bcopy.s)
735797( 0.03) 99.97 0.00 506627 4123 fread(/usr/lib32/
libc.so.1:/work/irix/lib/libc/libc_n32_M3/stdio/fread.c) |
Inclusive basic block counting counts basic blocks and generates a call graph. By propagating regular counts to callers of a routine, prof provides inclusive basic block counting. For more information on inclusive basic block counting, see the "ideal Experiment" section in Chapter 4, "Experiment Types."
To see inclusive data, run the profile formatting program prof specifying the name of the original program, the -gprof flag, and the .Counts file for the program.
% prof -gprof myprog myprog.Counts |
prof extracts information from myprog.Counts and prints it in an easily readable format. If multiple .Counts files exist, you can use the wildcard character (*) to specify all of the files.
% prof -gprof myprog myprog.Counts* |
This section contains part of a sample output obtained by using the –gprof option. The fields in the report are explained in detail in the report, but are not provided in this example. For more information on the -gprof option, see Chapter 7, "Analyzing Experiment Results: prof." (The format of the output has been adjusted slightly.)
% prof -gprof generic generic.Counts |
...
Prof run at: Fri May 17 14:42:25 1996
Command line: prof -gprof generic generic.Counts
...
self kids called/total parents
index cycles(%) self(%) kids(%) called+self name index
self kids called/total children
[1] 2662767961 (100.00%) 71( 0.00%) 2662767890(100.00%) 0 __start [1]
44 2662767837 1/1 main [2]
5 0 1/1 __istart[111]
4 0 1/1 __readenv_sigfpe[112]
--------------------------------------------------------------------------------
44 2662767837 1/1 __start [1]
[2] 2662767881(100.00%) 44( 0.00%) 2662767837(100.00%) 1 main [2]
2152 2662764245 1/1 Scriptstring[3]
67 926 1/1 exit [58]
96 309 1/1 _sigset [67]
32 10 1/9 _gettimeofday[68]
-----------------------------------------------------------------------------
... |