Although I/O performance is one of the strengths of supercomputers, speeding up the I/O in a program is an often neglected area of optimization. A small optimization effort can often produce a surprisingly large gain.
The run-time I/O library contains low overhead, built-in instrumentation that can collect vital statistics on activities such as I/O. This run-time library, together with procstat(1) and other related commands, offers a powerful tool set that can analyze the program I/O without accessing the program source code.
A wide selection of optimization techniques are available through the flexible file I/O (FFIO) system. You can use the assign(1) command to invoke FFIO for these optimization techniques. This chapter stresses the use of assign and FFIO because these optimization techniques do not require program recompilation or relinking. For information about other optimization techniques, see the Cray Research publication, Optimizing Code on Cray PVP Systems. For information about optimization techniques on UNICOS/mk systems see “Optimization on UNICOS/mk Systems”. The remainder of the information in this chapter is used primarily on UNICOS systems, and much of the information is not applicable to IRIX systems.
This chapter describes ways to identify code that can be optimized and the techniques that you can use to optimize the code.
I/O can be represented as a series of layers of data movement. Each layer involves some processing. Figure 13-1 shows typical output flow from the UNICOS system to disk.
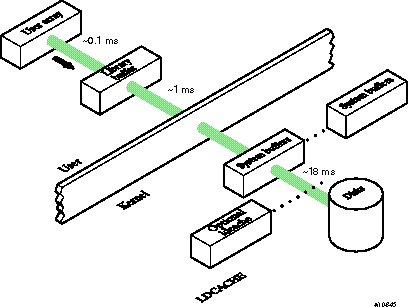
On output, data moves from the user space to a library buffer, where small chunks of data are collected into larger, more efficient chunks. When the library buffer is full, a system request is made and the kernel moves the data to a system buffer. From there, the data is sent through the I/O processor (IOP), perhaps through ldcache, to the device. On input, the path is reversed.
The times shown in Figure 13-1 may not be duplicated on your system because many variables exist that affect timing. These times do, however, give an indication of the times involved in each processing stage.
For optimization purposes, it is useful to differentiate between permanent files and temporary files. Permanent files are external files that must be retained after the program completes execution. Temporary files or scratch files are usually created and reused during the execution of the program, but they do not need to be retained at the end of the execution.
Permanent files must be stored on actual devices. Temporary files exist in memory and do not have to be written to a physical device. With temporary files, the strategy is to avoid using system calls (going to "lower layers" of I/O processing). If a temporary file is small enough to reside completely in memory, you can avoid using system calls.
Permanent files require system calls to the kernel; because of this, optimizing the I/O for permanent files is more complicated. I/O on permanent files may require the full complement of I/O layers. The goal of I/O optimization is to move data to and from the devices as quickly as possible. If that is not fast enough, you must find ways to overlap I/O with computation.
This chapter briefly describes the optimization techniques that are discussed in the remainder of this chapter.
Use the following tools to determine the initial I/O performance and to verify improvements in I/O performance after you try different optimization techniques:
Use the ja(1) command to determine whether significant time is spent on I/O in the program (see “Checking Program Execution Time”, for details).
Use the procstat(1) command and procview(1) command on the program to help you evaluate the I/O information that the I/O library collects (see “Generating an I/O Profile”, for details).
The following types of optimization may improve I/O performance:
Use the type of storage devices that are effective for the types of I/O done by the program. Try the mr or ssd layers (see “The MR Feature”, or “Using MR/SDS Combinations”).
Specify the cache page size so that one or more records will fit on a cache page if the program is using unformatted direct access I/O (see “Using a Cache Layer”, for details).
Use file structures without record control information to bypass the overhead associated with records (see “Using Simpler File Structures”, for details).
Choose file processing with appropriate buffering strategies. The cos, bufa, and cachea FFIO layers implement asynchronous write-behind (see “Using Asynchronous Read-ahead and Write-behind”, for details). The cos and bufa FFIO layers implement asynchronous read-ahead; this is available for the cachea layer through use of an assign option.
Choose efficient library buffer sizes. Bypass the library buffers when possible by using the system or syscall layers (see “Changing Library Buffer Sizes”, for details).
Determine whether the use of striping, preallocation of the file, and the use of contiguous disk space would improve I/O performance (see “User Striping”, for details).
Use the assign command to specify scratch files to prevent writes to disk and to delete the files when they are closed (see “Scratch Files”, for details).
“Enhancing Performance” in Chapter 11, also provides further information about using FFIO to enhance I/O performance.
The following source program changes may affect the I/O performance of a Fortran program:
Use unformatted I/O when possible to bypass conversion of data.
Use whole array references in I/O lists where possible. The generated code passes the entire array to the I/O library as the I/O list item rather than pass it through several calls to the I/O library.
Use special packages such as buffer I/O, random-access I/O, and asynchronous queued I/O.
Overlap CPU time and I/O time by using asynchronous I/O.
I/O optimization can often be accomplished by simply addressing I/O speed. The following UNICOS storage systems are available, ranked in order of speed:
CPU main memory
Optional SSD
Magnetic disk drives
Optional magnetic tape drives
Fast storage systems are expensive and have smaller capacities. You can specify a fast device through FFIO layers and use several FFIO layers to gain the maximum performance benefit from each storage medium. The remainder of this chapter discusses many of these FFIO optimizations. These easy optimizations are frequently those that yield the highest payoffs.
Before you can optimize I/O, you must first identify the activities that use the most time. The most time-intensive I/O activities are the following:
System requests
File structure overhead
Data conversion
Data copying
This section describes different commands you can use to examine your programs and determine how much I/O activity is occurring. After you determine the amount of I/O activity, you can then determine the most effective way to optimize the I/O.
The sections that follow make frequent references to the following sample program:
program t
parameter (nrec=2000, ndim=500)
dimension a(ndim)
do 5 i=1,ndim
a(i) = i
5 continue
istat = ishell('rm fort.1')
call timef(t0)
do 10 i=1,nrec
write(1) a
10 continue
c rewind and read it 3 times
do 30 i=1,3
rewind(1)
do 20 j=1,nrec
read(1) a
20 continue
30 continue
call timef(t1)
nxfer = 8*nrec*ndim*(1+3)
write(*,*) 'unit 1: ',
+ nxfer/(1000*(t1-t0)),
+ ' Mbytes/sec'
stop
end |
The ja(1) command is a job accounting command that can help you determine if optimizing your program will return any significant gain. For complete details about the ja command, see the ja man page.
To use ja(1), enter the following commands:
ja a.out ja -ct |
These commands produce the following program execution summary that indicates the time spent in I/O:
Command Started Elapsed User CPU Sys CPU I/O Wait I/O Wait Name At Seconds Seconds Seconds Sec Lck Sec Unlck ======== ======== =========== ========== ========== ======== ========== a.out 17:15:56 4.5314 0.2599 0.2242 3.9499 0.1711 |
This output indicates that this program has a large amount of I/O wait time. The following section describes how to obtain a profile of the I/O activity in the program.
A significant part of this example program performs I/O; therefore, you can use procstat and related tools to obtain an I/O profile. For complete details about using these tools, see the Cray Research publications, UNICOS Performance Utilities Reference Manual, and the UNICOS User Commands Reference Manual, or the procview(1) man page.
The procstat tool is not available on CRAY T3E systems.
The procstat tool set does not require access to the program source files. The run-time library has built-in I/O data collection that is invoked when a program is run with procstat. The set of statistics generated usually provides enough information to tune I/O in a Fortran program without altering the source code.
The procview tool creates one or more reports from the raw output that the procstat command generates. It may also be run interactively, both in line-mode and by using the X Window System interface. The procview command presents an interactive menu when no command-line report option is included; otherwise, an output option can be specified and the report output can be redirected to a file.
To run the program under procstat, enter the following commands:
procstat -R raw a.out procview -l -Fs raw |
The -l option selects the long form report, and the -Fs option selects Fortran files sorted by maximum file size. The resulting report summaries the I/O activity of each Fortran file in the following format:
======================================================================= Fortran Unit Number 1 File Name fort.1 Command Executed t1 Date/Time at Open 05/31/91 17:00:19 Date/Time at Close 05/31/91 17:00:26 System File Descriptor 4 Type of I/O sequential unformatted File Structure COS blocked File Size 8032256 (bytes) Total data transferred 32129024 (bytes) Fortran I/O Count of Real Statement Statements Time ------------ ---------- -------------- READ 6000 5.3625 WRITE 2000 1.6484 REWIND 3 .0011 CLOSE 1 .0019 4014.6 Bytes transferred per Fortran I/O statement 87.70% Of Fortran I/O statements did not initiate a system request System I/O # of # Bytes # Bytes Wait Time (Clock Periods) Function Calls Processed Requested Max Min Total ------------ ------- --------- --------- --------- --------- --------- Read 738 24096768 24182784 9010627 135443 865007072 Write 246 8032256 8032256 10674103 133840 253750720 Seek 4 n/a n/a 42061 3746 55067 Truncate 1 n/a n/a 17462 17462 17462 System I/O Avg Bytes Percent of Average I/O Rate Function Per Call File Moved (MegaBytes/Second) ------------ ----------- ---------- ------------------- Read 32651.4 300.0 4.643 Write 32651.4 100.0 5.276 Seek n/a n/a n/a Truncate n/a n/a n/a ========================================================================= |
By examining the summary of files examined during a program, you can tell that the following types of files should be optimization targets:
Files with very high activity rates (total bytes transferred is very large); see the # Bytes Processed column in the report.
Files in which a lot of real time is spent in I/O statements; see the Real time and Total column figures.
In a busy interactive environment, queuing for service is time consuming. In tuning I/O, the first step is to reduce the number of physical delays and the queuing that results by reducing the number of system requests, especially the number of system requests that require physical device activity.
System requests are made by the library to the kernel. They request data to be moved between I/O devices. Physical device activity consumes the most time of all I/O activities.
Typical requests are read, write, and seek. These requests may require physical device I/O. During physical device I/O, time is spent in the following activities:
Transferring data between disk and memory.
Waiting for physical operations to complete. For example, moving a disk head to the cylinder (seek time) and then waiting for the right sector to come under the disk head (latency time).
System requests can require substantial CPU time to complete. The system may suspend the requesting job until a relatively slow device completes a service.
Besides the time required to perform a request, the potential for congestion also exists. The system waits for competing requests for kernel, disk, IOP, or channel services. System calls to the kernel can slow I/O by one or two orders of magnitude.
The information in this section summarizes some ways you can optimize system requests.
Main memory is extremely fast. Cray Research provides many ways to use memory to avoid delays that are associated with transfers to and from physical devices.
The mr FFIO layer, which permits files to reside in main memory, is available on all UNICOS and UNICOS/mk systems. If the memory space is large enough, you can eliminate all system requests for I/O on a file. The previous procstat / procview report contains the following information:
The 2000-record file was probably written once and then rewound and read completely three times; this is deduced from the Count of Statements on the report.
The type of I/O was sequential unformatted. The file structure is COS blocked (see File Structure on the report).
Its maximum file size is about 8 Mbytes (see File Size on the report).
To apply 8 Mbytes of memory to this file, use the following assign command and then rerun the job:
assign -F blocked,mr::1961 u:1 |
The maximum size of 1961 is calculated by dividing the file size of 8,032,256 bytes by the sector size of 4096 bytes.
The -F option invokes FFIO. The blocked,mr specification selects the blocked layer followed by the mr layer of FFIO. The u:1 argument specifies unit 1. Figure 13-2 shows I/O data movement when you use the assign command.
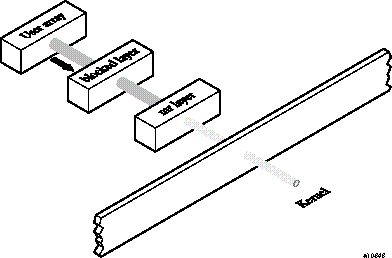
The data only moves to and from the buffer of the mr layer during the operation of the READ, WRITE, and REWIND I/O statements. It gets moved from disk during OPEN processing if it exists and when SCRATCH is not specified. It gets moved to disk only during CLOSE processing when DELETE is not specified. When the program is rerun under procview, the procview report is as follows:
=======================================================================
Fortran Unit Number 1
File Name fort.1
Command Executed a.out
Date/Time at Open 09/04/91 17:29:38
Date/Time at Close 09/04/91 17:29:39
System File Descriptor 4
Type of I/O sequential unformatted
File Structure COS blocked
File Size 8032256 (bytes)
Total data transferred 8032256 (bytes)
Assign attributes -F blocked, mr::1961
Fortran I/O Count of Real
Statement Statements Time
------------ ---------- --------------
READ 6000 .1663
WRITE 2000 .0880
REWIND 3 .0005
CLOSE 1 .9055
1003.7 Bytes transferred per Fortran I/O statement
99.99% Of Fortran I/O statements did not initiate a system request
System I/O # of # Bytes # Bytes Wait Time (Clock Periods)
Function Calls Processed Requested Max Min Total
----------- ------- --------- --------- --------- --------- ---------
Write 1 8032256 8032256 150197242 150197242 150197242
Seek 2 n/a n/a 3655 3654 7309
Truncate 1 n/a n/a 5207 5207 5207
System I/O Avg Bytes Percent of Average I/O Rate
Function Per Call File Moved (MegaBytes/Second)
------------ ----------- ---------- -------------------
Write 8032256.0 100.0 8.913
Seek n/a n/a n/a
Truncate n/a n/a n/a
=========================================================================== |
In the new report, notice the following:
Read time is 0 (no entry for Read exists under System I/O Function). All of the data that was read was moved from the MR buffer to user space. Data transferred is 0; consequently, the time spent in Read is reduced by more than one order of magnitude.
Write time is reduced because the data is moved only to the MR buffer during Fortran write s.
Total write time stays relatively unchanged because the file still has to be flushed to disk at CLOSE processing.
The optional solid-state storage device (SSD) is the fastest I/O device. The SSD stores data in memory chips and operates at speeds about as fast as main memory or 10 to 50 times faster than magnetic disks.
Because SSD capacity is usually much larger than main memory, SSD is used when not enough main memory is available to store all of the possible data.
You can access the SSD through ldcache. The system uses SSD to cache the data from file systems that the system administrator selects. Caching is automatic for files in these file systems and their subdirectories.
You can also access the SSD with the FFIO sds layer. When this layer is present, library routines use the SSD to hold the file between open and close. You should use the FFIO sds layer for files that are larger than the amount of ldcache available for the file.
The SDSLIMIT and SDSINCR environment variables may have significant impact if all subfields are not specified after the SDS keyword (use of these variables is not recommended).
The following timings from a CRAY Y-MP/8 system show the typical effects of optimization on the program used in “The MR Feature”. In that example, the program writes a file and reads it three times. Because it is unnecessary to save the file afterward, the .scr type (scratch file) can be used. See “Scratch Files”, for more information about scratch files. Some of the following commands appear to produce a range because of the fluctuation in results.
| assign command | I/O speed (relative) |
| Default (no ldcache) | 1 |
| Default (ldcache) | 8 |
You can use the sds layer and ldcache in conjunction with the mr layer. For example, to allocate 2048 Mbytes (512 sectors) of main memory for the file, with the remainder on SSD, use the following assign(1) command:
assign -F mr.scr:512:512:0,sds.scr |
The first 512 blocks of the file reside in main memory and the remainder of the blocks reside on SSD.
Generally, the combination of the mr and sds layers makes the maximum amount of high performance storage available to the program. The SSD is typically used in case the file size exceeds the estimated amount of main memory you can access.
The following timings from a CRAY Y-MP/8 system show the typical effects of optimization on the program used in “The MR Feature”. The program writes a file and reads it three times. Because it is not necessary to save the file afterward, you can use the .scr (scratch file) type. See “Scratch Files”, for more information about scratch files.
| Command | I/O speed (relative) |
| (with no ldcache:) |
|
| Default | 1 |
| assign -F sds.scr | 4 |
| assign -F mr.scr:512:512:0,sds.scr | 4 |
| (with ldcache:) |
|
| Default | 1 |
| assign -F cos,sds.scr | 1.2 |
| assign -F mr.scr:512:512:0,sds.scr | 1.2 |
The FFIO cache layer keeps recently used data in fixed size main memory or SDS buffers or cache pages in order to reuse the data directly from these buffers in subsequent references. It can be tuned by selecting the number of cache pages and the size of these pages.
The use of the cache layer is especially effective when access to a file is localized to some regions of the whole file. Well-tuned cached I/O can be an order of magnitude faster than the default I/O.
Even when access is sequential, the cache layer can improve the I/O performance. For good performance, use page sizes large enough to hold the largest records.
The cache layers work with the standard Fortran I/O types and the Cray Research extensions of BUFFER IN/OUT, READMS/WRITMS, and GETWA/PUTWA.
The following assign command requests 100 pages of 42 blocks each:
assign -F cache:42:100 f:filename |
Specifying cache pages of 42 blocks matches the track size of a DD-49 disk.
It is a good idea to preallocate space; this saves system overhead by making fewer system requests for allocation, and may reduce the number of physical I/O requests. You can allocate space by using the default value from the -A and -B options for the mkfs(8) command, or by using the assign(1) command with the -n option, as follows:
assign -n sz[:st] -q ocblks |
The sz argument specifies the decimal number of 512-word blocks reserved for the data file. If this option is used on an existing file, sz 512-word blocks are added to the end of the file. The -qocblks option specifies the number of 512-word blocks to be allocated per file system partition. These options are generally used with the -p option to do user-level striping. The st (stride) argument to the -n option is obsolete and should not be used; it specifies the allocation increment when allocating sz blocks.
 | Note: For immediate preallocation, use the setf(1) command because assign does not preallocate space until the file is opened. |
Use the -c option on the assign or setf command to get contiguous allocation of space so that disk heads do not have to reposition themselves as frequently. It is important to note that if contiguous allocation is unavailable, the request fails and the process might abort also.
Generally, most users should not do user-level striping (the -p option on the assign and setf commands), because it requires disk head seek operations on multiple devices. Only jobs performing I/O with large record lengths can benefit from user-level striping. Large records are those in excess of several times the size of IOS read-ahead/write-behind segments (this varies with the disk device, but it is usually at least 16 sectors), or several times the disk track size (this varies with the disk device). In addition, asynchronous I/O has a much higher payoff with user-level striping than synchronous I/O.
The assign and setf commands have a partition option, -p, that is very important for applications that perform multifile asynchronous I/O. By placing different files on different partitions (which must be on different physical devices), multiple I/O requests can be made from a job, thus increasing the I/O bandwidth to the job. The -c option has no effect without the -n option.
When a file system is composed of partitions on more than one disk, major performance improvements can result from using the disks at the same time. This technique is called disk striping.
For example, if the file system spans three disks, partitions 0, 1, and 2, it may be possible to increase performance by spreading the file over all three equally. Although 300 sequential writes may be required, only 100 must go to each disk, and the disks may be writing simultaneously. You can specify striping in the following two ways, using the assign command:
assign -p 0-2 -n 300 -q 48 -b 144 f:filename assign -p 0:1:2 -n 300 -q 48 -F cos:144 f:filename |
The previous example also specifies a larger buffer size (144), which is three tracks (one per disk) if there are 48 sectors per track.
Using the bufa layer enhances the usefulness of user striping because bufa issues asynchronous I/O system calls, which are handled more efficiently by the kernel for user-striped files. In addition, the double buffering helps load balance the CPU and I/O processing. Using the previous example, better performance could be obtained from the bufa layer by using the following:
assign -p 0-2 -n 1000 -q 48 -F bufa:144:6 |
or
assign -p 0-2 -n 1000 -q 16 -F bufa:48:6 |
See “The bufa and cachea Layers” in Chapter 11, for information about the bufa layers.
Other factors, such as channel capacity, may limit the benefit of striping. Disk space on each partition should be contiguous and preallocated for maximum benefit.
Use striping only for very large records because all of the disk heads must do seeks on every transfer.
Use the df(1) command to list the partitions of a file system. For more information about the df command, see the UNICOS User Commands Reference Manual.
The Fortran standard uses the record concept to govern I/O. It allows you to skip to the next record after reading only part of a record, and you can backspace to a previous record. The I/O library implements Fortran records by maintaining an internal record structure.
In the case of a sequential unformatted file, it uses a COS blocked file structure, which contains control information that helps to delimit records. The I/O library inserts this control information on write operations and removes the information on read operations. This process is known as record translation, and it consumes time.
If the I/O performed on a file does not require this file structure, you can avoid using the blocked structure and record translation. However, if you must do positioning in the file, you cannot avoid using the blocked structure.
The information in this section describes ways to optimize your file structure overhead.
Scratch files are temporary and are deleted when they are closed. To decrease I/O time, move applications' scratch files from user file systems to high-speed file systems, such as /tmp, secondary data segments (SDS), or /ssd.
When optimizing, you should avoid writing the data to disk. This is especially important if most of the data can be held in SDS or main memory.
Fortran lets you open a file with STATUS='SCRATCH'. It also lets you close temporary files by using a STATUS='DELETE'. These files are placed on disk, unless the .scr specification for FFIO or the assign -t command is specified for the file. Files specified as assign -t or .scr are deleted when they are closed. The following assign commands are examples of using these options:
assign -t f:filename assign -F mr.scr f:filename assign -F sds.scr f:filename assign -F cos,sds.scr f:filename |
You can think of the program's file as a scratch file and avoid flushing it at CLOSE by using the following command:
assign -F mr.scr u:1 |
Figure 13-3 shows the program's current data movement:
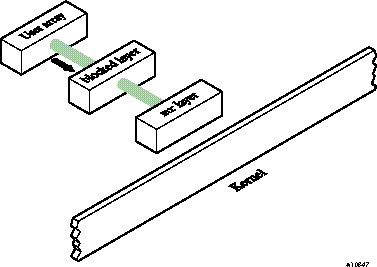
The following procview report shows the difference in I/O times; the last two lines of the report indicate that both the Fortran WRITE statement time and system I/O write () time were reduced to 0.
==================================================================
Fortran Unit Number 1
File Name fort.1
Command Executed a.out
Date/Time at Open 09/04/91 17:31:38
System File Descriptor -1
Type of I/O sequential unformatted
File Structure COS blocked - 'blocked'
Assign attributes -F blocked,mr.scr
Fortran I/O Count of Real
Statement Statements Time
------------ ---------- --------------
READ 6000 .1622
WRITE 2000 .0862
REWIND 3 .0005
CLOSE 1 .0000
0 Bytes transferred per Fortran I/O statement
100% Of Fortran I/O statements did not initiate a system request
==================================================================== |
If unit 1 is declared as a scratch file by using the assign command, fort.1 will no longer exist after program execution.
Because the original procview report indicates that no BACKSPACE was done on the file, the program might not depend on the blocked structure. Perhaps the program reads all of the data that is on every record. If it does, you can avoid using the blocked structure and save more time. Even if you cannot be sure that you do not need the blocked structure, you can still try it by using this command:
assign -F mr.scr u:1 |
The program will probably fail if it does require blocked structure. If it runs successfully, you will notice that it runs faster. The layer of library processing that does the record keeping was eliminated, and the program's memory use now looks like that in Figure 13-4.

The program is now much faster. The time saved by using the assign commands described in this section is as follows:
| Command | Speed | |
| Default | 4.6 Mbyte/s | |
| assign -F blocked,mr::1961 | 27.7 Mbyte/s × 6 speedup | |
| assign -F blocked,mr.scr | 129.3 Mbyte/s × 28 speedup |
Total optimization impact is I/O that is 15 times faster.
You may not see these exact improvements because many variables (such as configurations) exist that affect timings.
When writing a sequential COS blocked file, the library usually waits until its buffer is full before initiating a system request to write the data to the physical device. When the system request completes, the library resumes processing the user request.
The FFIO asynchronous COS layer divides this buffer in half and begins a write operation when the first half is full, but it continues processing the user request in the second half of the buffer while the system is writing data from the first half. When reading, the library tries to read ahead into the second half of the buffer to reduce the time the job must wait while waiting for system requests. This can be twice as fast as sequential I/O requests.
The asynchronous COS layer is specified with the assign -F command, as follows:
assign -F cos.async f:filename assign -F cos.async:96 f:filename |
The second assign command specifies a larger buffer because the library requests (half the specified buffer size) should be the disk track size, which is assumed to be 48 sectors.
Several FFIO layers automatically enhance I/O performance by performing asynchronous read-ahead and write-behind. These layers include:
cos: default Fortran sequential unformatted file. Specified by assign -F cos.
bufa: specified by assign -F bufa.
cachea: default Fortran direct unformatted files. Specified by assign -F cachea. Default cachea behavior provides asynchronous write-behind. Asynchronous read-ahead is not enabled by default, but is available by an assign option.
If records are accessed sequentially, the cos and bufa layers will automatically and asynchronously pre-read data ahead of the file position currently being accessed. This behavior can be obtained with the cachea layer with an assign option; in that case, the cachea layer will also detect sequential backward access patterns and pre-read in the reverse direction.
Many user codes access the majority of file records sequentially, even with ACCESS='DIRECT' specified. Asynchronous buffering provides maximum performance when:
Access is mainly sequential, but the working area of the file cannot fit in a buffer or is not reused frequently.
Significant CPU-intensive processing can be overlapped with the asynchronous I/O.
Use of automatic read-ahead and write-behind may decrease execution time by half because I/O and CPU processing occur in parallel.
The following assign command specifies a specific cachea layer with 10 pages, each the size of a DD-40 track. Three pages of asynchronous read-ahead are requested. The read-ahead is performed when a sequential read access pattern is detected.
assign -F cachea:48:10:3 f:filename |
This command would work for a direct access or sequential Fortran file which has unblocked file structure.
To utilize asynchronous read-ahead and write-behind with ER90 tape files, you can use the bufa and the er90 layers, as in the following example:
assign -F bufa,er90 f:filename |
The bufa layer must be used with the er90 layer because it supports file types that are not seekable. The bufa layer can also be used with disk files, as in the following example:
assign -F bufa:48:10 f:filename |
This command specifies the same buffer configuration as the previous cachea example. The bufa layer uses all its pages for asynchronous read-ahead and write-behind. When writing, each page is asynchronously flushed as soon as it is full.
Marking records incurs overhead. If a program reads all of the data in any record it accesses and avoids the use of BACKSPACE, you can make some minor performance savings by eliminating the overhead associated with records. This can be done in several ways, depending on the type of I/O and certain other characteristics.
For example, the following assign statements specify the unblocked file structure:
assign -s unblocked f:filename assign -s u f:filename assign -s bin f:filename |
When possible, avoid formatted I/O. Unformatted I/O is faster, and it avoids potential inaccuracies due to conversion. Formatted Fortran I/O requires that the library interpret the FORMAT statement and then convert the data from an internal representation to ASCII characters. Because this must be done for every item generated, it can be very time-consuming for large amounts of data.
Whenever possible, use unformatted I/O to avoid this overhead. Do not use edit-directed I/O on scratch files. Major performance gains are possible.
You can explicitly request data conversions during I/O. The most common conversion is through Fortran edit-directed I/O. I/O statements using a FORMAT statement, list-directed I/O, and namelist I/O require data conversions.
Conversion between internal representation and ASCII characters is time-consuming because it must be performed for each data item. When present, the FORMAT statement must be parsed or interpreted. For example, it is very slow to convert a decimal representation of a floating-point number specified by an E edit descriptor to an internal binary representation of that number.
For more information about data conversions, see Chapter 12, “Foreign File Conversion”.
The Fortran I/O libraries usually use main memory buffers to hold data that will be written to disk or was read from disk. The library tries to do I/O efficiently on a few large requests rather than in many small requests. This process is called buffering.
Overhead is incurred and time is spent whenever data is copied from one place to another. This happens when data is moved from user space to a library buffer and when data is moved between buffers. Minimizing buffer movement can help improve I/O performance.
The libraries generally have default buffer sizes. The default is suitable for many devices, but major performance improvements can result from requesting an efficient buffer size.
The optimal buffer size for very large files is usually a multiple of a device allocation for the disk. This may be the size of a track on the disk. The df -p command lists thresholds for big file allocations. If optimal size buffers are used and the file is contiguous, disk operations are very efficient. Smaller sizes require more than one operation to access all of the information on the allocation or track. Performance does not improve much with buffers larger than the optimal size, unless striping is specified.
When enough main memory is available to hold the entire file, the buffer size can be selected to be as large as the file for maximum performance.
The maximum length of a formatted record depends on the size of the buffer that the I/O library uses for a file. The size of the buffer depends on the following:
hardware system and UNICOS level
Type of file (external or internal)
Type of access (sequential or direct)
Type of formatted I/O (edit-directed, list-directed, or namelist)
On UNICOS systems, the RECL parameter on the OPEN statement is accepted by the Fortran library for sequential access files. For a sequential access file, RECL is defined as the maximum record size that can be read or written. Thus, the RECL parameter on the OPEN statement can be used to adjust the maximum length of formatted records that can be read or written for that file.
If RECL is not specified, the following default maximum record lengths apply:
Input | Output | |
|---|---|---|
Edit-directed formatted I/O | 267 | 267 |
List-directed formatted I/O | 267 | 133 |
Namelist I/O | 267 | 133 |
Internal I/O | none | none |
ENCODE/DECODE | none | none |
After a request is made, the library usually copies data between its own buffers and the user data area. For small requests, this may result in the blocking of many requests into fewer system requests, but for large requests when blocking is not needed, this is inefficient. You can achieve performance gains by bypassing the library buffers and making system requests to the user data directly.
To bypass the library buffers and to specify a direct system interface, use the assign -s u option or specify the FFIO system, or syscall layer, as is shown in the following assign command examples:
assign -s u f:filename assign -F system f:filename assign -F syscall f:filename |
The user data should be in multiples of the disk sector size (usually 4096 bytes) for best disk I/O performance.
If library buffers are bypassed, the user data should be on a sector boundary to prevent I/O performance degradation.
There are other optimizations that involve changing your program. The following sections describe these optimization techniques.
When a program produces a large amount of output used only as input to another program consider using pipes. If both programs can run simultaneously, data can flow directly from one to the next by using a pipe. It is unnecessary to write the data to the disk. See Chapter 4, “Tape and Named Pipe Support ”, for details about pipes.
Major performance improvements can result from overlapping CPU work and I/O work. This approach can be used in many high-volume applications; it simultaneously uses as many independent devices as possible.
To use this method, start some I/O operations and then immediately begin computational work without waiting for the I/O operations to complete. When the computational work completes, check on the I/O operations; if they are not completed yet, you must wait. To repeat this cycle, start more I/O and begin more computations.
As an example, assume that you must compute a large matrix. Instead of computing the entire matrix and then writing it out, a better approach is to compute one column at a time and to initiate the output of each column immediately after the column is computed. An example of this follows:
dimension a(1000,2000)
do 20 jcol= 1,2000
do 10 i= 1,1000
a(i,jcol)= sqrt(exp(ranf()))
10 continue
20 continue
write(1) a
end |
First, try using the assign -F cos.async f:filename command. If this is not fast enough, rewrite the previous program to overlap I/O with CPU work, as follows:
dimension a(1000,2000)
do 20 jcol= 1,2000
do 10 i= 1,1000
a(i,jcol)= sqrt(exp(ranf()))
10 continue
BUFFER OUT(1,0) (a(1,jcol),a(1000,jcol) )
20 continue
end |
The following Fortran statements and library routines can return control to the user after initiating I/O without requiring the I/O to complete:
BUFFER IN and BUFFER OUT statements (buffer I/O)
Asynchronous queued I/O statements (AQIO)
FFIO cos blocking asynchronous layer (available on IRIX systems)
FFIO cachea layer (available on IRIX systems)
FFIO bufa layer (available on IRIX systems)
The information in this section describes some optimization guidelines for UNICOS/mk systems. For more information about optimization on UNICOS/mk systems, see the CRAY T3E Fortran Optimization Guide.
Choose the largest possible transfer sizes: Using large transfer sizes alleviates the longer system call processing time.
Check the MAXASYN settings: An application can become limited by the MAXASYN settings on the host machine. The default value of 35 asynchronous I/O structures limits you to 17 outstanding asynchronous I/O requests. The system administrator can view the current settings by using the crash command. The values to be checked are in the var structure; the fields that may need to be changed are v_pbuf, v_asyn, and v_maxasyn. These values can be changed by changing the values for NPBUF, NASYN, and MASAXYN in config.h.
Coordinate PEs performing I/O: When creating files by using a UNICOS/mk application and if raw (unbuffered) I/O performance is expected, you must coordinate the PEs doing the I/O so the write requests are issued sequentially. If the PEs issue the I/O at their own speed, the host will interpret this as a non-sequential extension of a file. When this occurs, the host uses the system buffer cache to zero the space between the old EOF and the new I/O request.
Resequence I/O when converting applications: When converting sequential applications to run on the UNICOS/mk system, resequence the I/O (from a disk perspective) by user striping the file across N tracks with N PEs performing all of the I/O, where a single PE will stride through the file by N records. The following diagram shows how the record numbers are assigned to the disk slices of a filesystem and shows how the PE will be performing the I/O request:
Slice
Slice
~
Slice
A/PE-X
B/PE-Y
C/PE-Z
1
2
N
N+1
N+2
2N
2N+1
2N+2
3N
~
~
~
~
K*N+1
K*N+2
(K+1)*N
Use CF90 and IEEE data conversion facilities: When an unformatted Cray PVP data file is to be read on the Cray MPP system, write a conversion program to run on the Cray PVP system that uses the CF90 compiler and the T3D data conversion layer. For data files that have integer elements, no conversion is necessary. For data files that have real or logical elements, use an assign -N t3d statement for the output data file.