This chapter describes the use of profiling tools to obtain performance information. Compared to the performance analysis of sequential applications, characterizing the performance of parallel applications can be challenging. Often it is most effective to first focus on improving the performance of MPI applications at the single process level.
Profiling tools such as SpeedShop can be effectively used to assess this performance aspect of message passing applications. It may also be important to understand the message traffic generated by an application. A number of tools can be used to analyze this aspect of a message passing application's performance, including Performance Co-Pilot and various third party products. In this chapter, you can learn how to use these various tools with MPI applications.
Two of the most common SGI profiling tools are SpeedShop and perfex. On Altix, profile.pl and histx+ are commonly used. The following sections describe how to invoke these tools. Performance Co-Pilot (PCP) tools and tips for writing your own tools are also included.
| Note: SpeedShop is available on IRIX systems only. |
You can use SpeedShop as a general purpose profiling tool or specific profiling tool for MPI potential bottlenecks. It has an advantage over many of the other profiling tools because it can map information to functions and even line numbers in the user source program. The examples listed below are in order from most general purpose to the most specific. You can use the -ranks option to limit the data files generated to only a few ranks.
General format:
% mpirun -np 4 ssrun [ssrun_options] a.out |
Examples:
% mpirun -np 32 ssrun -pcsamp a.out # general purpose, low cost % mpirun -np 32 ssrun -usertime a.out # general purpose, butterfly view % mpirun -np 32 ssrun -bbcounts a.out # most accurate, most cost, butterfly view % mpirun -np 32 ssrun -mpi a.out # traces MPI calls % mpirun -np 32 ssrun -tlb_hwctime a.out # profiles TLB misses |
For further information and examples, see the SpeedShop User's Guide.
You can use perfex to obtain information concerning the hardware performance monitors.
General format:
% mpirun -np 4 perfex -mp [perfex_options] -o file a.out |
Example:
% mpirun -np 4 perfex -mp -e 23 -o file a.out # profiles TLB misses |
| Note: perfex is available on IRIX systems only. |
On Altix systems, you can use profile.pl to obtain procedure level profiling as well as information about the hardware performance monitors. For further information, see the profile.pl(1) and pfmon(1) man pages.
General format:
% mpirun -np 4 profile.pl [profile.pl_options] ./a.out |
Example:
% mpirun -np 4 profile.pl -s1 -c4,5 -N 1000 ./a.out |
On Altix systems, histx+ is a small set of tools that can assist with performance analysis and bottlenect identification.
General formats for histx (Histogram) and lipfpm (Linux IPF Performance Monitor):
% mpirun -np 4 histx [histx_options] ./a.out |
% lipfpm [lipfpm_options] mmpirun -np 4 ./a.out |
Examples:
% mpirun -np 4 histx -f -o histx.out ./a.out |
% lipfpm -f -e LOADS_RETIRED -e STORES_RETIRED mpirun -np 4 ./a.out |
You can write your own profiling by using the MPI-1 standard PMPI_* calls. In addition, either within your own profiling library or within the application itself you can use the MPI_Wtime function call to time specific calls or sections of your code.
The following example is actual output for a single rank of a program that was run on 128 processors, using a user-created profiling library that performs call counts and timings of common MPI calls. Notice that for this rank most of the MPI time is being spent in MPI_Waitall and MPI_Allreduce.
Total job time 2.203333e+02 sec Total MPI processes 128 Wtime resolution is 8.000000e-07 sec activity on process rank 0 comm_rank calls 1 time 8.800002e-06 get_count calls 0 time 0.000000e+00 ibsend calls 0 time 0.000000e+00 probe calls 0 time 0.000000e+00 recv calls 0 time 0.00000e+00 avg datacnt 0 waits 0 wait time 0.00000e+00 irecv calls 22039 time 9.76185e-01 datacnt 23474032 avg datacnt 1065 send calls 0 time 0.000000e+00 ssend calls 0 time 0.000000e+00 isend calls 22039 time 2.950286e+00 wait calls 0 time 0.00000e+00 avg datacnt 0 waitall calls 11045 time 7.73805e+01 # of Reqs 44078 avg data cnt 137944 barrier calls 680 time 5.133110e+00 alltoall calls 0 time 0.0e+00 avg datacnt 0 alltoallv calls 0 time 0.000000e+00 reduce calls 0 time 0.000000e+00 allreduce calls 4658 time 2.072872e+01 bcast calls 680 time 6.915840e-02 gather calls 0 time 0.000000e+00 gatherv calls 0 time 0.000000e+00 scatter calls 0 time 0.000000e+00 scatterv calls 0 time 0.000000e+00 activity on process rank 1 ... |
SGI provides a freeware MPI profiling library that might be useful as a starting point for developing your own profiling routines. You can obtain this software at http://freeware.sgi.com/index-by-alpha.html.
MPI keeps track of certain resource utilization statistics. These can be used to determine potential performance problems caused by lack of MPI message buffers and other MPI internal resources.
To turn on the displaying of MPI internal statistics, use the MPI_STATS environment variable or the -stats option on the mpirun command. MPI internal statistics are always being gathered, so displaying them does not cause significant additional overhead. In addition, one can sample the MPI statistics counters from within an application, allowing for finer grain measurements. For information about these MPI extensions, see the mpi_stats man page.
These statistics can be very useful in optimizing codes in the following ways:
To determine if there are enough internal buffers and if processes are waiting (retries) to aquire them
To determine if single copy optimization is being used for point-to-point or collective calls
To determine additional resource contention when using GSN networks
For additional information on how to use the MPI statistics counters to help tune the run-time environment for an MPI application, see Chapter 6, “Run-time Tuning”.
In addition to the tools described in the preceding sections, you can also use the MPI agent for Performance Co-Pilot (PCP) to profile your application. The two additional PCP tools specifically designed for MPI are mpivis and mpimon. These tools do not use trace files and can be used live or can be logged for later replay.
For more information about configuring and using these tools, see the PCP tutorial in /var/pcp/Tutorial/mpi.html. Following are examples of the mpivis and mpimon tools.
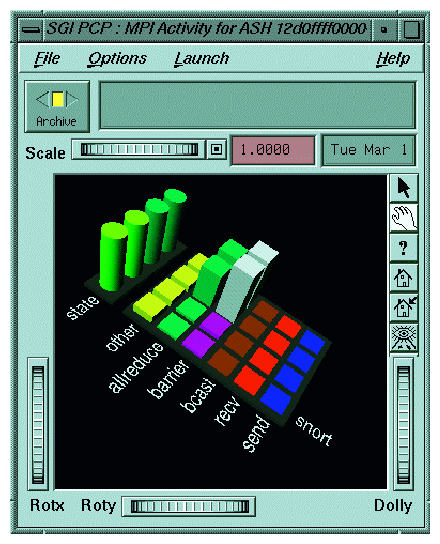
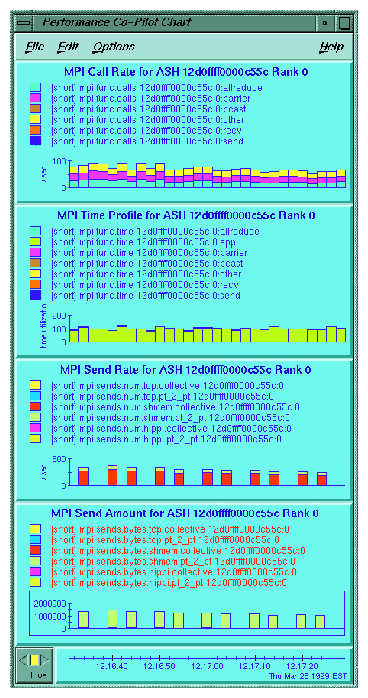
Two third party tools that you can use with the SGI MPI implementation are Vampir from Pallas ( www.pallas.com) and Jumpshot, which is part of the MPICH distribution. Both of these tools are effective for smaller, short duration MPI jobs. However, the trace files these tools generate can be enormous for longer running or highly parallel jobs. This causes a program to run more slowly, but even more problematic is that the tools to analyze the data are often overwhelmed by the amount of data.
A better approach is to use a general purpose profiling tool such as SpeedShop to locate the problem area and then to turn on and off the tracing just around the problematic areas of your code. With this approach, the display tools can better handle the amount of data that is generated.